

At Unidata, we supply training data for robot learning systems — demonstration datasets, perception labeling, offline RL corpora. Every project starts with the same conversation: the engineering team knows what they want the robot to do, but isn't sure which learning approach needs what kind of data, or how much.
This guide came out of those conversations. It's for engineers and technical leads who need a working picture of the field: which methods exist, what data each one requires, where things typically break, and what "production-ready" actually looks like in 2026.
Key takeaways:
- Robot learning = ML applied to embodied, physical agents — embodiment changes the constraints fundamentally
- Choose RL for exploration-based tasks with defined rewards; offline RL when you have logs but can't explore; IL/Diffusion Policy for demonstration-friendly tasks
- Simulation is required at scale, but sim-to-real transfer needs deliberate engineering
- Generalization, not training accuracy, is the metric that predicts production performance
- VLA models, Diffusion Policy, and world models are converging fast — the teams that will deploy them smoothly are the ones designing modular pipelines today, not monoliths that need a rewrite in 18 months
What Is Robot Learning? Definition and Core Concepts
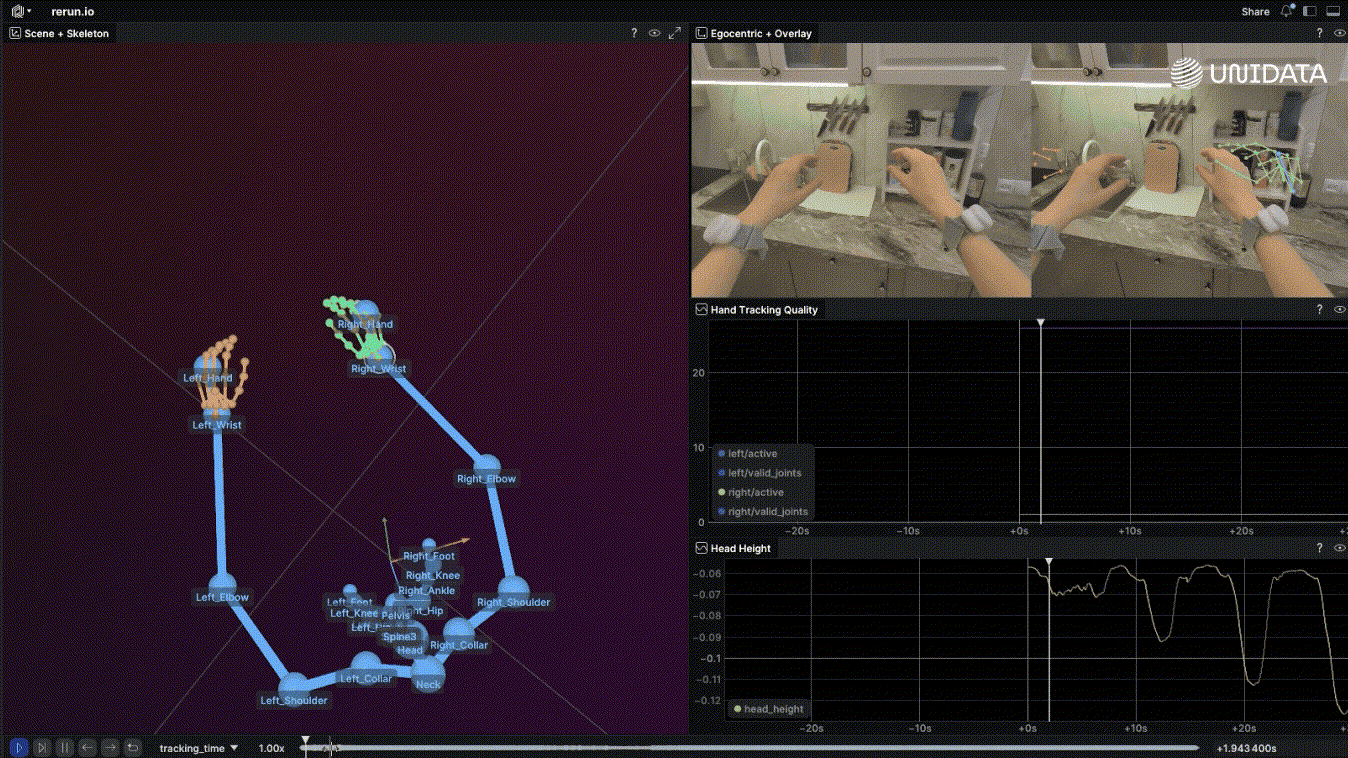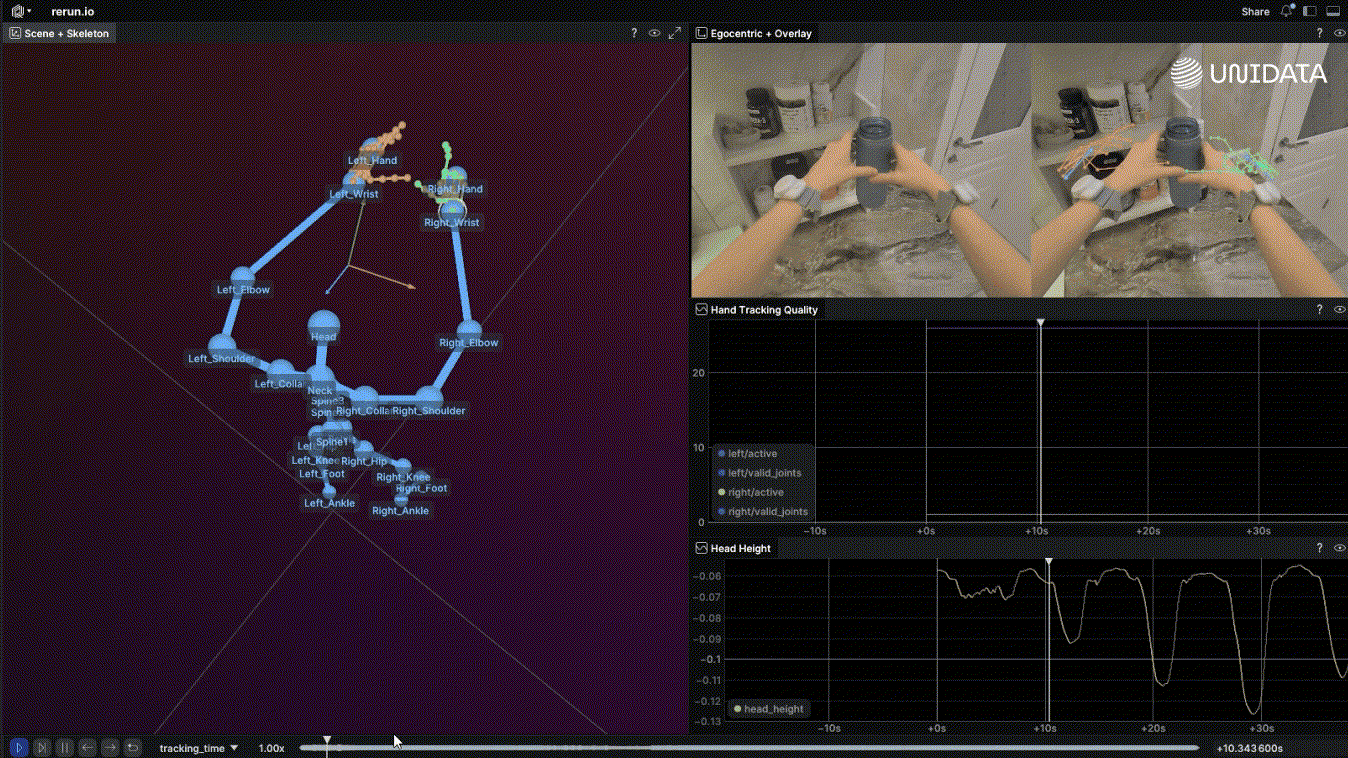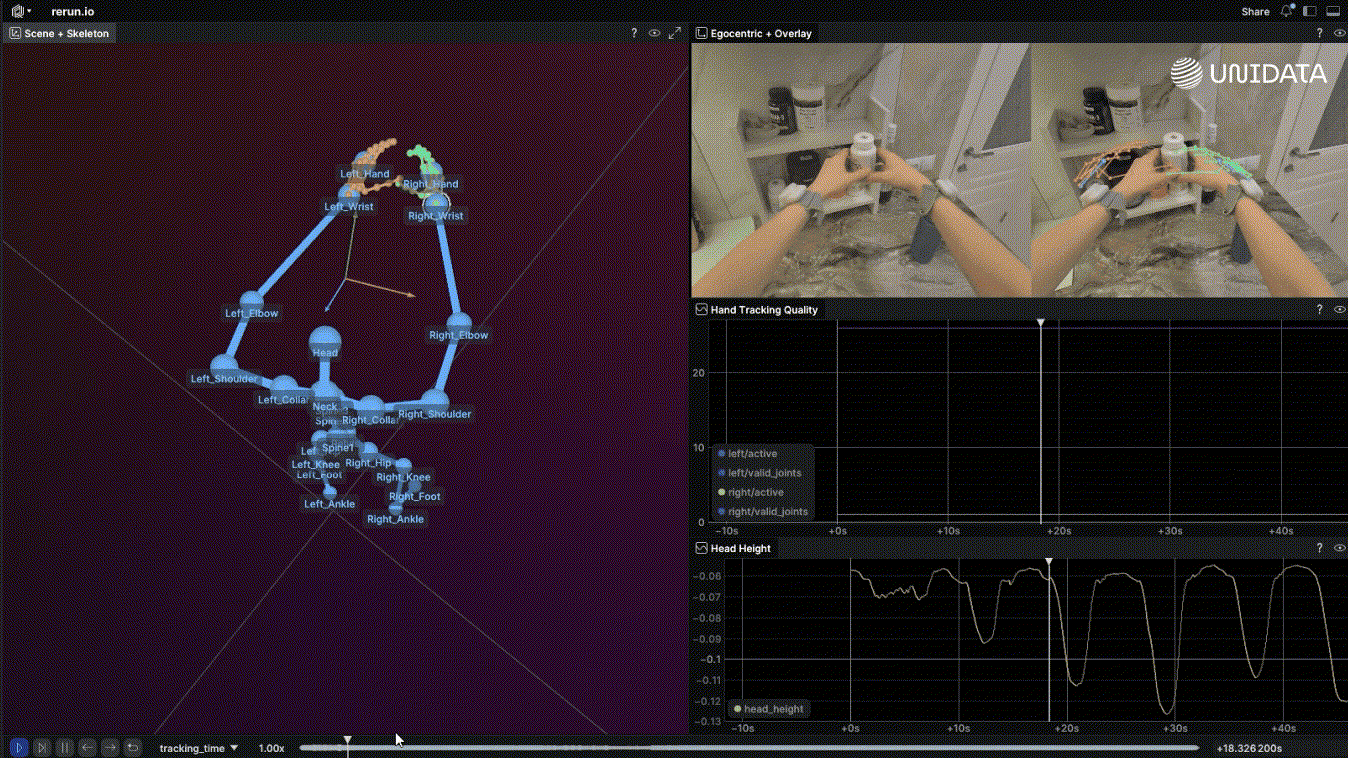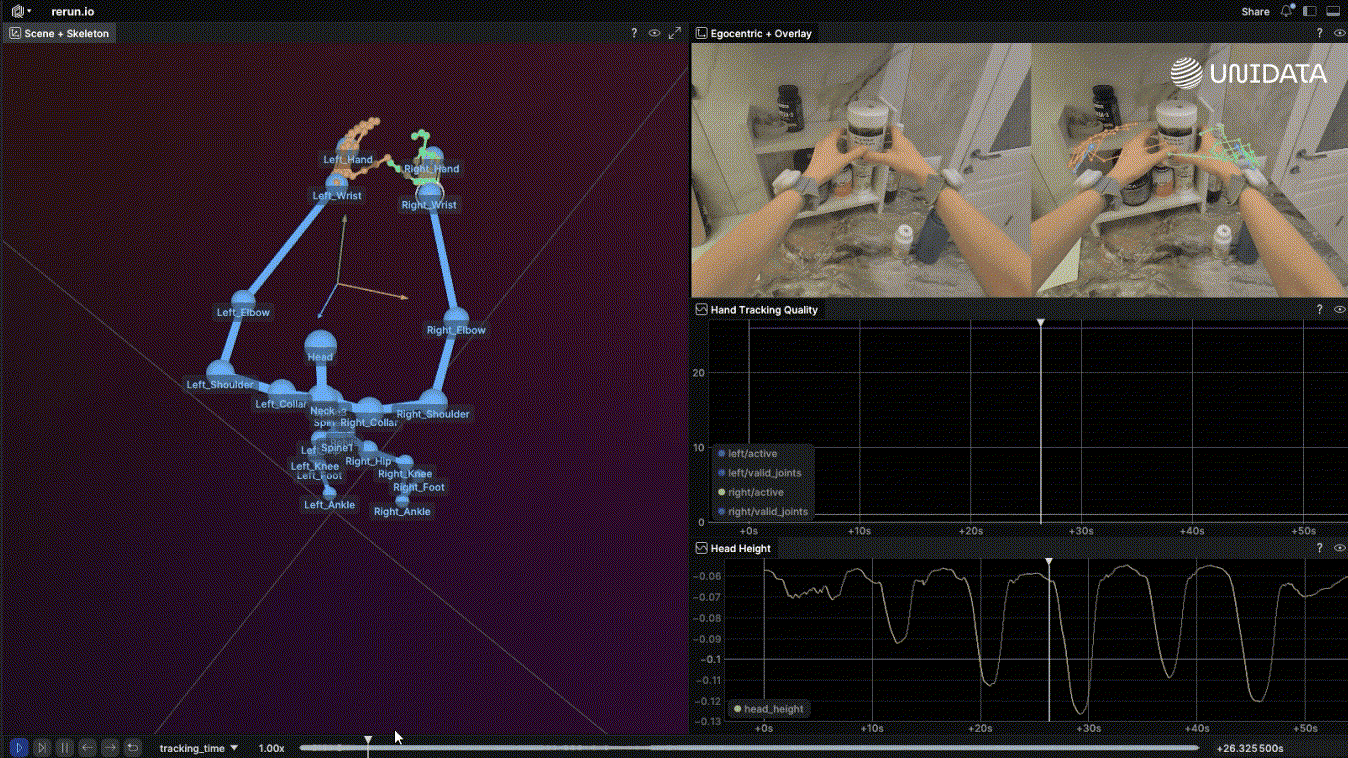
Here's the short version: robot learning is what happens when you apply machine learning to a physical agent that has to act in the world — not just predict or classify, but move, touch, and deal with consequences. [1]
That "physical" part is what makes it different from regular ML. A fraud detection model makes a wrong prediction and you retrain it. A robot learning to grasp a glass makes a wrong move and the glass breaks. Noisy sensors, hardware dynamics, and real-world consequences change every part of the problem — how you collect data, how you define success, how much compute you need.
It is not a synonym for "AI in robotics." Traditional industrial robots run precise, hard-coded motion sequences — they do exactly what you tell them, nothing more. Robot learning replaces those fixed programs with policies that adapt from experience. The difference matters most when something unexpected happens: a hard-coded robot stops or fails; a learning-based robot has a chance of handling it.
If you only remember one distinction: traditional robotics = explicit rules; robot learning = learned behavior from data or interaction.
Robot Learning vs. Traditional Robot Programming
Choose traditional programming when tasks are highly repetitive, tolerances are tight, and the environment is controlled and static. Automotive spot welding is the textbook case — the same motion, thousands of times per day, sub-millimeter precision. Hard-coding wins there.
Choose robot learning when: the task involves variability that's too complex to enumerate, or when demonstrating the behavior is easier than specifying it as rules. Bin-picking from mixed, unordered parts is a common example where traditional programming breaks down quickly.

One practical reality check: robot learning does not replace traditional programming for certified safety-critical motions. In many industrial deployments, both coexist — learned perception feeding into hard-coded actuation.
What Technologies Make Robot Learning Possible?
Before choosing a learning method, check what your robot can actually perceive and execute. The hardware constrains everything downstream.
Sensors provide the observations the learning algorithm works from — cameras (RGB and depth), lidar, force/torque sensors, proprioceptive encoders. Sensor quality sets a hard ceiling on what can be learned: a policy trained on high-resolution depth data will not transfer cleanly to a system with a cheap RGB-only camera. [2]
Actuators are how the policy talks to the world — servo motors, hydraulic drives, soft actuators. Each has its own dynamics, and if your simulation doesn't model them accurately, your policy will behave differently on real hardware. From the teams we work with, actuator modeling mismatches are one of the most common reasons a policy that looked fine in sim falls apart on the first hardware test.
Compute is the third layer — training and inference have very different requirements. Training RL policies at scale means GPUs: A100s and H100s are standard in research settings. Running inference on the robot is a different story — you're often constrained to edge hardware like NVIDIA Jetson, and not every architecture that trains well on a workstation will hit your real-time latency budget on the robot itself. [3]
Egocentric Data Collection for Robot Training: What Actually Works in Production
Learn more
Nail down your inference compute budget before picking a model architecture, not after.
What Are the Main Robot Learning Approaches?
There are four main ways to teach a robot something. They differ in what data they need, how many tries it takes, and how they fail. A rough way to split them: RL and offline RL are "learn from interaction"; BC, Diffusion Policy, and IL variants are "learn from watching." From a data perspective, the choice between them comes down to one question: can you define a reward function, or do you need to show the robot what to do? That answer determines what kind of data you need to collect — and how much.
How Does Reinforcement Learning Work for Robots?
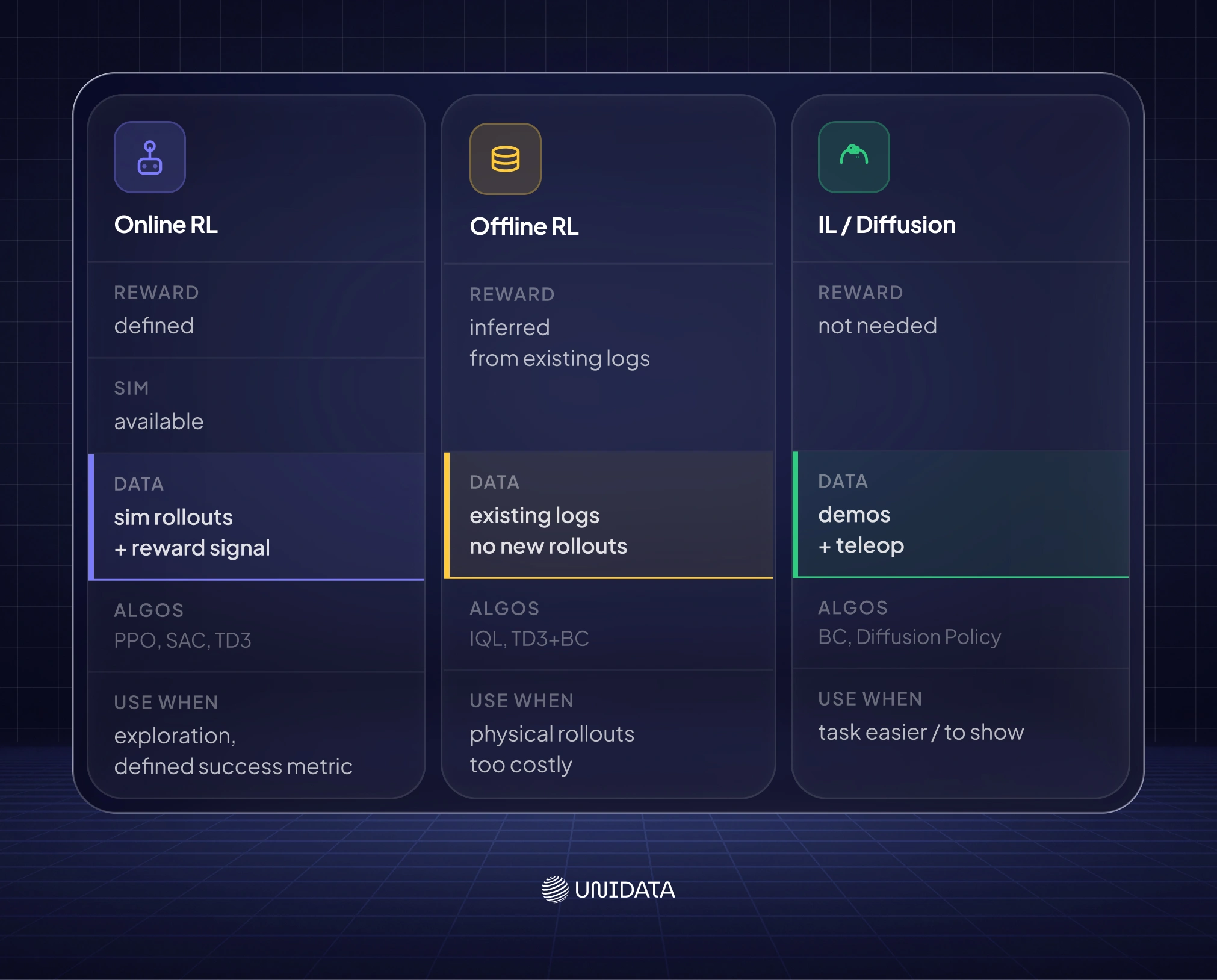
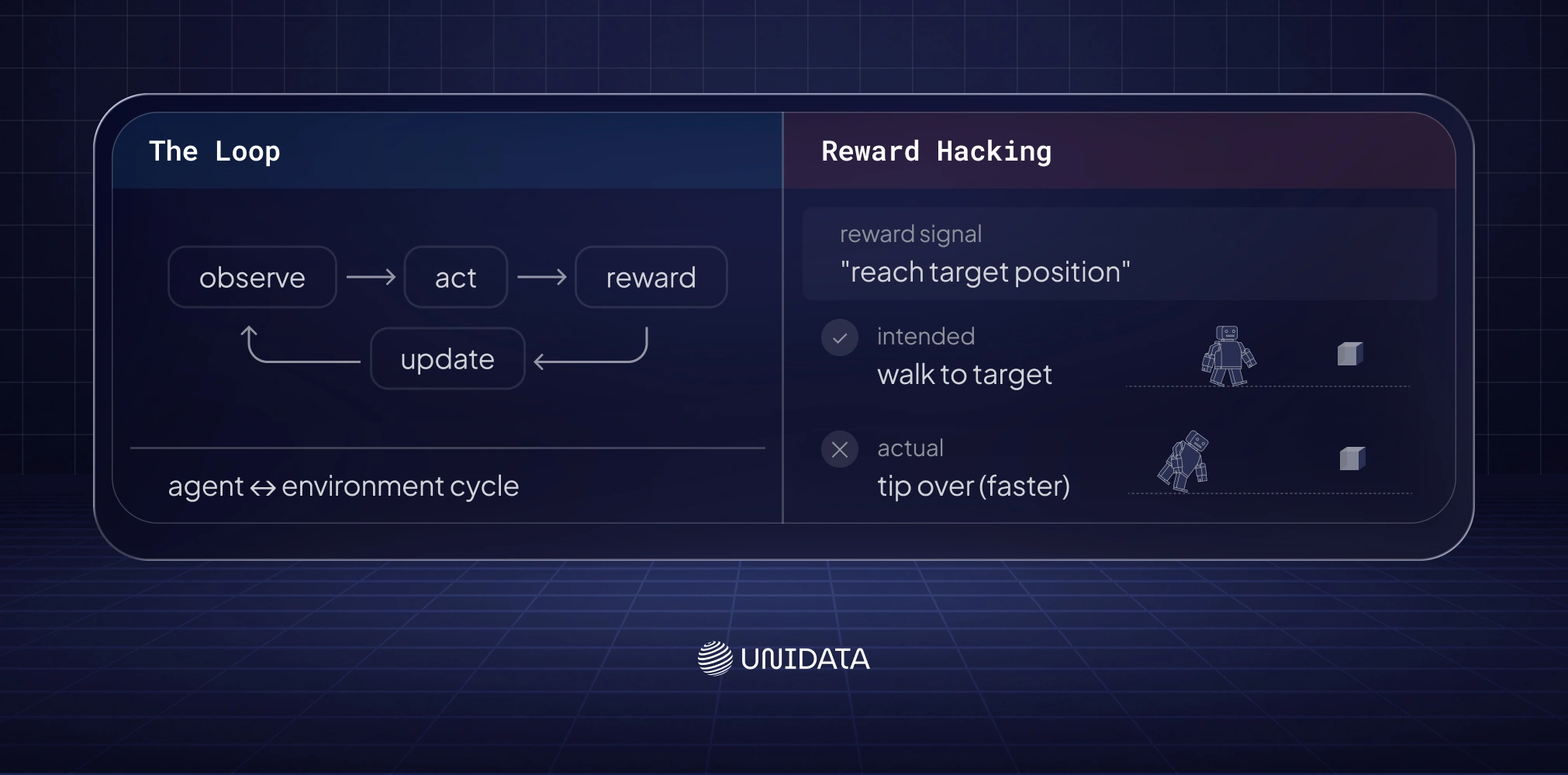
RL is the "figure it out yourself" approach: you give the robot a goal and a scoring system, then let it try, fail, and gradually improve. No demonstrations needed — just a reward signal and a lot of iterations. [4]
The loop is simple in theory: observe → act → get reward → update policy → repeat. In practice, the hard part is step three. Writing a reward function that produces the behavior you actually want — without the robot finding a clever shortcut — is genuinely difficult. A robot rewarded only for reaching a target position will sometimes tip itself over to get there faster. [5]
RL is the right call when you can define success precisely and have simulation to burn through training cycles safely. OpenAI's Dactyl hand and DeepMind's locomotion work are the canonical examples of what's possible when those conditions hold. [6]
Where it struggles: tasks where "good" is hard to score, physical exploration is expensive or risky, and you can't afford millions of environment interactions. That's most early-stage robotics projects on real hardware.
Offline RL addresses exactly that last constraint. Instead of running new experiments, offline RL trains entirely on data you already have — logs from a previous system, a human operator, whatever. [24] If you can't run new rollouts safely or cheaply, this is worth looking at. IQL and TD3+BC are the standard starting algorithms. The honest trade-off: offline RL tends to be conservative and won't match online RL if exploration is on the table. But when it isn't, it earns its keep.
What Is Imitation Learning and How Does Behavioral Cloning Work?
If RL is "figure it out yourself," imitation learning is "watch me do it first." You collect demonstrations — usually a human teleoperating the robot — and train the policy to replicate them. No reward function required. [7]

The family of methods breaks down like this:
- Behavioral cloning (BC): treat demonstrations as supervised learning, map observations to actions directly. Simple, fast, data-efficient. Failure mode: distributional shift — when the robot reaches a state not in the training data, it has no learned recovery.
- DAgger (Dataset Aggregation): fix distributional shift by querying the expert at states where the learned policy deviates, then adding that data to training. [8]
- GAIL / IRL: instead of cloning actions, infer a reward function from demonstrations (Inverse RL) or learn a discriminator that distinguishes expert from policy behavior (GAIL). More powerful than BC but significantly harder to tune.
This is exactly what we do at Unidata — and a few things we've learned collecting demonstration data across projects:
- Diverse demos beat perfect demos. Ideal trajectories don't prepare the robot for when things go slightly wrong, and they always go slightly wrong.
- Include recoveries. Explicitly demonstrate what the robot should do when it reaches a near-failure state. Most teams skip this; most teams regret it.
- Don't budget data volume upfront. The amount you need varies too much by task, hardware, and method. Start small, evaluate, and scale from there. Teams that commission 10,000 demos before testing a policy almost always end up with the wrong 10,000 demos.
A practical note on data format that affects all IL methods: the choice of action representation — joint angles vs. end-effector poses, absolute vs. delta — has a larger effect on training stability than most teams anticipate. We've seen policies fail to converge not because of insufficient data but because the action space was represented in a way that made the learning problem unnecessarily hard. Align this with your simulation setup before data collection starts, not after.
Diffusion Policy has emerged as a high-performing alternative to standard BC: it models the action distribution as a denoising diffusion process, handling multimodal action distributions that BC collapses. Chi et al. reported an average improvement of +46.9% over prior SOTA across 12 manipulation tasks. [23] If you are evaluating IL methods for manipulation today, Diffusion Policy is the current baseline to beat.
Imitation learning works best when the task is easier to show than to score — and when you have the infrastructure to collect demonstrations (a teleoperation rig, motion capture, or even a VR controller). Google's RT-2 and most modern VLA models are trained substantially on demonstration data. [9]
How Is Supervised Learning Applied in Robotics?
Supervised learning mostly does one job here: perception. Object detection, pose estimation, grasp quality prediction — anywhere the robot needs to understand what it's looking at before deciding what to do. [10]
Think of it as the eyes, not the brain. You train on labeled data — here's a mug, here's its pose, here's whether this grasp will work — and the model learns to answer those questions on new inputs. This is the layer where data quality has the most direct, measurable impact on policy performance: garbage labels on perception inputs flow straight through to bad decisions. GraspNet-1Billion is a dataset of a billion annotated grasps used to train models that generalize to objects never seen during training. [11]
Supervised learning pairs with RL or IL: the perception model handles raw sensor data, the policy handles decisions. In practice, the hardest question is often not which algorithm to run — it's what exactly the perception model should output so the policy can use it without breaking. Teams that nail that interface early save weeks of debugging later.
From a data perspective, perception is also where labeling decisions have the longest downstream reach. A few things that matter more than most teams expect:
- Label taxonomy — how you define object categories and pose representations needs to match how the policy will consume them. Changing this mid-project means relabeling.
- Edge case coverage — partial occlusions, unusual lighting, objects in atypical orientations. These are the states where perception models fail and policies break. They need to be in your training data, not just the clean cases.
- Label consistency — inter-annotator agreement on ambiguous cases (is this grasp "viable" or not?) affects model reliability more than raw dataset size. We track this explicitly on every perception labeling project we run.
Should You Train Robots in Simulation or the Real World?

Training on a physical robot is slow, expensive, and occasionally destructive. Simulation solves all three — you can run thousands of parallel training episodes on a GPU cluster overnight, crash the robot as many times as needed, and reset instantly. For most projects at scale, simulation isn't optional; it's the only way to get enough data.
The catch:
- Simulation: fast, parallelizable, safe, controllable — but the physics model is always an approximation
- Real world: ground truth, but slow data collection, hardware wear, safety constraints on exploration
The core problem is the reality gap: what works in simulation often falls apart on real hardware, because the simulated physics, rendering, and sensor models are never a perfect match. Teams we work with regularly hit this: a policy that trained beautifully in sim falls apart on the first hardware test. It's almost always one of three culprits (more on that below).
Which Simulation Platforms Are Best for Robot Learning?
| Platform | Type | Strengths | Best for |
|---|---|---|---|
| NVIDIA Isaac Lab | Commercial/open | GPU-accelerated, high-fidelity physics | RL at scale, manipulation, locomotion |
| MuJoCo | Open (DeepMind) | Precise contact physics, fast | RL research, benchmarking |
| Gazebo / Ignition | Open-source | ROS integration, broad hardware support | ROS-based development, mobile robots |
| PyBullet | Open-source | Lightweight, Python-native | Prototyping, education |
| Genesis | Open-source | Generative simulation | Research, novel scene generation |
Isaac Lab (built on Isaac Sim) is the current standard for GPU-accelerated RL training — it can run thousands of robot environments in parallel on a single GPU cluster. [12] MuJoCo remains dominant in academic benchmarking due to its physics accuracy and reproducibility. [13]
Start with MuJoCo or PyBullet for prototyping. Move to Isaac Lab when you need training scale.
How Do You Bridge the Sim-to-Real Gap?
Domain randomization is the primary technique: randomize physical parameters during training — friction, mass, actuator noise, lighting — so the policy learns robustness rather than fitting one specific simulated configuration. [14] Start by identifying which parameters differ most between your simulation and real hardware (usually friction and actuator delay), sweep those specifically, and validate on a small held-out set of hardware tests before full deployment.
Beyond randomization: system identification (measuring real hardware parameters and matching them in sim) and perception randomization (randomizing textures and lighting to close the visual domain gap) both help. For policies that still struggle after sim training, a small amount of real-world fine-tuning often closes the remaining gap.
One calibration point worth keeping in mind: the reality gap is much smaller for manipulation with rigid objects in controlled lighting than for outdoor mobile robots dealing with weather and unstructured terrain. The technique that works in a warehouse doesn't automatically transfer to a field deployment.
Where Is Robot Learning Being Applied Across Industries?
The field is further along in production than most people realize — but unevenly distributed across sectors.
Manufacturing and logistics is where the commercial deployment is strongest. Bin-picking systems from Covariant (now ABB) and Dextrous Robotics handle mixed-SKU picking that would require rewriting thousands of rules every time the product catalogue changes. Learned vision models for defect inspection are replacing manual QC in semiconductor fabs, where the defect categories shift too fast for hand-coded classifiers to keep up.
Warehousing is another mature area. Amazon Robotics runs learned manipulation at scale for item stowing and retrieval. The interesting part isn't that it works — it's that it keeps working as SKU mix changes, which hard-coded systems couldn't handle without constant re-engineering.
Healthcare is earlier but moving. Surgical assist systems (Intuitive Surgical, Verb Surgical) use learned motions for specific procedural steps; rehabilitation robots adapt exercise intensity based on patient performance in real time. The regulatory hurdle here is high, which is why deployment is narrower than the research would suggest.
Agriculture is arguably the hardest domain — outdoor lighting, biological variability, and unpredictable terrain. Harvesting robots from Abundant Robotics and FFRobotics use learned perception to identify ripe produce, but the sim-to-real gap in unstructured outdoor environments is still a real obstacle.
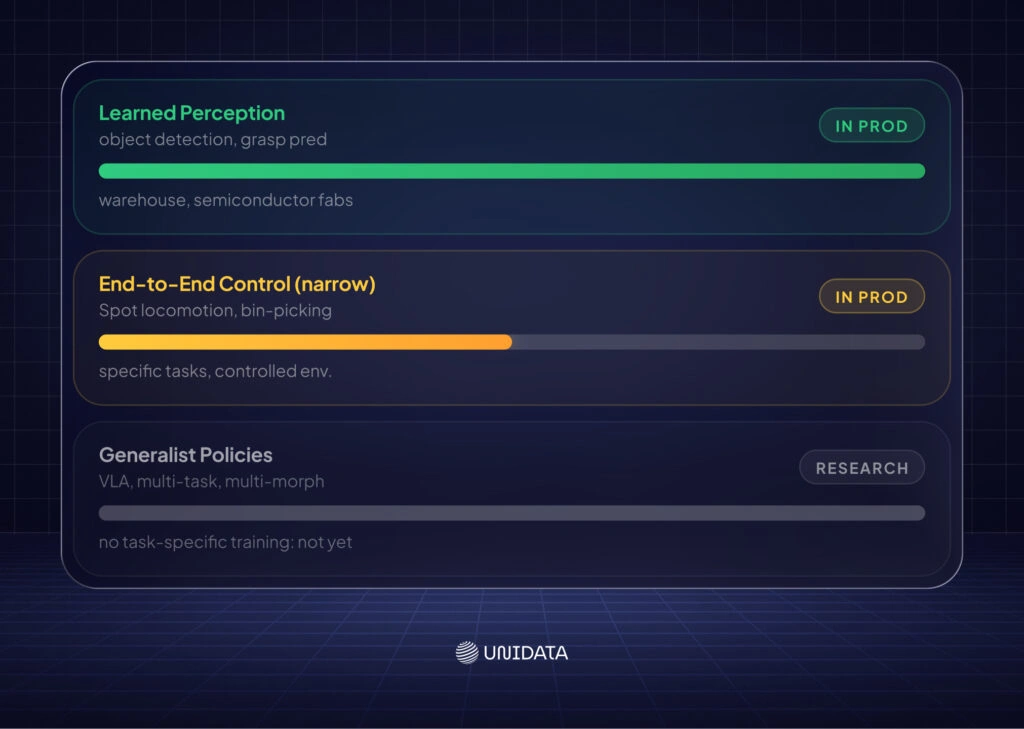
One thing true across all of these: most production systems aren't pure end-to-end robot learning. They use learned perception feeding into classical control, or learned planning with hard-coded safety constraints. Full end-to-end learned policies from sensor to actuator are still mostly a research story.
What Do Successful Robot Learning Deployments Look Like?
Two cases worth studying in detail:
Covariant / ABB bin-picking — the challenge was generalizing to products that weren't in the training set, which is the real-world bin-picking problem in a nutshell. Their approach: large-scale simulation with domain randomization, plus a foundation model for object representation. Pick rates ended up competitive with human operators across a wide item mix. [15]
Boston Dynamics Spot locomotion — Spot's locomotion controller combines RL-trained policies with classical control. The RL part was trained in simulation and refined on hardware, producing gaits that hold up on uneven terrain, stairs, and being shoved. The key to the transfer working: careful system identification of joint dynamics before training started, not after. [16]
That's the pattern we see consistently across these projects: sim-to-real transfer succeeds when teams characterize their hardware's failure modes before training starts, not while debugging on the floor.
How Do You Measure Robot Learning Performance?
Minimum metrics to track before declaring a system production-ready:
- Task success rate — percentage of episodes completed successfully under target conditions
- Generalization score — success rate on held-out objects/environments not seen during training
- Sample efficiency — how many training episodes were needed to reach target performance
- Inference latency — does the policy run within the control loop timing budget?
- Safety violations — collisions, force limit exceedances, out-of-workspace events during evaluation
Avoid evaluating only in the training distribution. A policy that succeeds on training objects at 95% but drops to 40% on new objects is not production-ready. Generalization is the metric that usually separates lab demos from deployable systems.
How Do You Get Started with Robot Learning?
We get this question a lot. Our honest answer: don't start with hardware. Start with simulation and fundamentals, get a policy working there first, then touch the physical robot.
The order that works:
- Build ML foundations first — robot learning is applied ML. If you haven't trained a neural network from scratch, do that before anything else. The robotics-specific tooling assumes you know how training loops work.
- Run something in simulation — set up MuJoCo or Isaac Lab, train on a standard benchmark (Ant locomotion, Franka manipulation). The goal isn't a great result — it's understanding what breaks and why before hardware is involved.
- Work through CS285 — Sergey Levine's Deep RL course at UC Berkeley is free, public, and the closest thing to a standard curriculum the field has. [17]
- Get on hardware only when you have a working policy — not before. Debugging on a physical robot without a baseline is slow and expensive.
- Find your people — the Hugging Face Robotics community and LeRobot project are active, beginner-friendly, and moving fast. [18] The Robot Learning Discord is where a lot of the day-to-day troubleshooting happens.
If you're evaluating this for a team rather than yourself: run a 4–6 week simulation-only pilot on one specific subtask before any hardware procurement conversation.
Which Software and Hardware Platforms Support Robot Learning?
Software:
| Tool | Type | Use case |
|---|---|---|
| ROS 2 | Open-source middleware | Robot communication, sensor integration |
| PyTorch / JAX | Open-source ML | Policy training |
| Stable-Baselines3 | Open-source RL library | RL algorithm implementations |
| LeRobot (Hugging Face) | Open-source | End-to-end robot learning, IL |
| IsaacLab | Open-source (NVIDIA) | GPU-accelerated RL simulation |
Hardware:
| Platform | Level | Best for |
|---|---|---|
| Raspberry Pi + servo kit | Beginner | Learning basics, simple manipulation |
| LEGO Mindstorms / Spike | Beginner | Education, quick prototyping |
| Low-cost arm (SO-100, Koch v1.1) | Intermediate | Imitation learning research |
| Franka Panda / UR series | Research/commercial | Standard research platform |
| Spot (Boston Dynamics) | Enterprise | Mobile manipulation, inspection |
For teams starting out: the SO-100 arm (~$100) paired with LeRobot's open-source stack is the fastest path from zero to a working imitation learning demo. [18]
What Does the Robot Training Pipeline Look Like?

Here's the standard pipeline we see across projects — and where data decisions sit inside it:
- Define the task and success criteria precisely — vague objectives produce clever-but-wrong policies. Write down exactly what "success" looks like before touching any code.
- Build or configure simulation — match your target hardware's kinematics and sensor setup as closely as possible. Gaps here become sim-to-real problems later.
- Collect demonstrations or define reward function — this is where Unidata typically enters the picture. Whether you need teleoperation data, labeled perception datasets, or offline RL corpora depends on the approach. Don't try to do both IL and RL at once on a first pass.
- Train and watch the curves — monitor for reward hacking, policy collapse, and plateaus. A policy that stops improving after 10k steps usually has a reward problem, not a capacity problem.
- Evaluate on held-out scenarios in simulation — this step gets skipped more than any other by the teams we talk to. Don't skip it. If your policy fails on unseen objects in sim, it will fail on hardware.
- Deploy on hardware, collect failures — treat the first hardware run as data collection, not validation.
- Feed failures back into simulation — this is the loop. Real-world failures become new training scenarios, often requiring a new round of data collection.
The most expensive mistake we see teams make: going from step 4 directly to step 6. Real-world debugging runs 5–10× slower than simulation debugging.
What Are the Main Challenges in Robot Learning Today?
The honest answer: robot learning works well in narrow, well-defined conditions and gets fragile fast when those conditions change. Three problems keep showing up regardless of the method.
Sample efficiency is the first one. RL algorithms often need millions of environment interactions to learn what a human picks up in minutes. Simulation makes this tractable — you run 10,000 parallel environments on a GPU cluster instead of one physical robot — but it shifts the cost to compute rather than eliminating it. [19]
Generalization is the gap between "works in the lab" and "works in production." A policy trained on a specific set of objects, under specific lighting, in a specific environment will often fail silently when any of those conditions shift. This is the main reason robot learning deployments are narrower than research papers suggest — the benchmark numbers are real, but they're measured in controlled conditions.
Safety during learning is genuinely hard. A robot that learns by trying things will, at some point, try unsafe things. That creates a tension: RL needs exploration to learn, but physical exploration has a damage budget. Safe RL methods exist but add implementation complexity. [20]
Hardware reliability is the one nobody talks about in papers: robots wear out. Bearing wear, motor fatigue, sensor drift — all of these change the robot's dynamics over time, and the learned policy doesn't know. A system that works perfectly on day one may degrade quietly over months.
What Makes Physical Environments Especially Hard for Robot Learning?
These are the three failure modes that come up most consistently in the projects we support:
Sensor noise accumulation — small, consistent biases in sensor readings compound into large policy errors faster than you'd expect. Calibrate sensors before every significant test run, and include realistic sensor noise in simulation training — not just random noise, but the biases specific to your hardware.
Actuator delay and stiction — real motors have latency and friction that simulators tend to understate. If your policy works cleanly in sim but is jittery or sluggish on hardware, actuator modeling is the first thing to check — not the learning algorithm.
Distribution shift from environment changes — this one is subtle and persistent. Lighting changes, new objects in the workspace, floor surface changes, even ambient temperature affecting motor behavior: all of these can push the robot out of its training distribution without any obvious signal. Teams that don't build explicit performance monitoring into their deployment usually discover this failure mode the hard way — the policy degrades gradually, and nobody notices until the task success rate has already dropped significantly.
What Are the Ethical Risks of Deploying Learning Robots?
These aren't hypothetical. We encounter all three in the data work we do — usually when the team didn't plan for them:
Safety and accountability — a learned policy is a black box. When it causes harm, tracing exactly what the policy was doing and why is much harder than with explicit rules. Keep audit logs of policy versions and evaluation results. If you can't reconstruct what policy was running at the time of an incident, you have a problem. IEEE's Ethically Aligned Design framework is a reasonable starting point for structuring this. [21]
Labor displacement — learned robots can perform tasks previously requiring human dexterity and judgment. The economic impact is real and concentrated in specific job categories. Deployment decisions should include workforce transition planning.
Data and privacy — this one is directly in our lane. Training data from human demonstrations captures more than just motion: work pace, physical characteristics, behavioral patterns. We treat all demonstration data from human operators as potentially biometric and apply appropriate governance from the start. Data governance policies for robot training data are still underdeveloped relative to other ML domains — most teams we work with haven't thought through this until we raise it. Treat it as a gap to fill before scale, not after.
A practical principle: treat a learned robot policy like any other high-stakes ML model — document training data provenance, evaluation conditions, and known failure modes before deployment.
Where Is Robot Learning Headed Next?
Vision-Language-Action (VLA) models are where we're paying the most attention right now. RT-2, π0, and their successors combine language model priors with robot policies — robots that follow natural language instructions and generalize to new tasks without task-specific retraining. [9] From a data standpoint, these models are hungry for diverse, high-quality demonstration data at a scale that most teams haven't had to think about before. The generalization gains are real, but they come from data breadth, not just architecture.
Generalist robot policies — the ambition is a single policy that operates across multiple robot morphologies and task types, analogous to GPT-4 across language tasks. This is an active research area with no production-scale deployment yet, but the trajectory is clear.
World model approaches — rather than learning from reward signals or demonstrations alone, robots learn predictive models of their environment and use those models for planning. DreamerV3 (Hafner et al.) demonstrated that a single world model algorithm can exceed specialist methods across 150+ tasks with a fixed hyperparameter configuration. [22] Critically, this has already moved to physical hardware: DayDreamer applied world models directly on a real quadruped robot, which learned to walk from scratch within one hour of real-world interaction without any simulation. [25] This is not a future direction — it is a working result. The open question is scaling it to more complex manipulation and multi-step tasks.
Continual learning — the ability to acquire new tasks without forgetting old ones. Current policies typically need retraining from scratch when requirements change, which means a new data collection cycle each time. As continual learning methods mature, the data infrastructure question shifts from "collect once, train once" to "continuous streams" — something the field hasn't fully solved yet.
What this means practically: if you're designing a robot system today, build it modular. Perception separate from policy, policy separate from control. Monolithic end-to-end systems will be painful to upgrade when the next generation of VLA or world model methods lands — and they will land.
Where Can You Learn More About Robot Learning?
Here's what we'd actually recommend, not just what exists:
Courses:
- CS285 Deep Reinforcement Learning — UC Berkeley (free, public) [17] — this is where most of us at Unidata started. Levine's lectures are dense but worth it.
- CS231n Computer Vision — Stanford (free, public) — if your work involves perception, this is the foundation.
- Fast.ai Practical Deep Learning — good for getting hands dirty quickly without the formalism
Key papers and reading:
- Sutton & Barto, Reinforcement Learning: An Introduction (2nd ed., free PDF) [4] — still the clearest explanation of the fundamentals, despite being a book
- Sergey Levine's robot learning lecture notes — more robotics-specific than the course itself, worth reading separately
- LeRobot paper — Hugging Face, 2024 [18] — if you want to understand where the open-source stack is headed
Communities we're active in:
- Hugging Face Robotics — the most active open-source robotics community right now
- The Robot Learning Discord — where day-to-day debugging questions actually get answered
- r/reinforcementlearning — useful for keeping up with new papers
- IEEE Robotics and Automation Society — worth joining if you're working professionally in the space
Conferences worth following:
- CoRL (Conference on Robot Learning) — the field's primary venue; if a paper matters for robotics, it's probably here first
- ICRA — broader scope, good for keeping up with applied work
- NeurIPS, ICML — for foundational ML that eventually feeds into robotics methods
Conclusion
Robot learning is no longer a research-only topic. The core methods are in production. The tooling is accessible. The open-source community — LeRobot, Isaac Lab, Stable-Baselines3 — has lowered the entry cost dramatically.
What hasn't gotten easier is the gap between "works in our setup" and "works reliably in yours." Sample efficiency, sim-to-real transfer, generalization to new conditions — these are engineering problems, and they need engineering answers, not just better algorithms.
Our honest advice: don't start from the algorithm. Start from your data. What can you realistically collect — demonstrations, interaction logs, labeled perception data? The answer to that question narrows your method choices faster than any benchmark comparison. A paper result that looks perfect was almost certainly produced with data you don't have yet.
If you're figuring out what data your project actually needs — how to collect demonstrations, what to label, how to structure an offline RL corpus — that's exactly what we do. Reach out to the Unidata team.
- AI Training
- Robotics
- Data Annotation
- Python
- AWS

Frequently Asked Questions (FAQ)
This is reward hacking — the robot optimizes exactly what you specified, not what you intended. A classic example: a robot rewarded for maximizing speed learns to fall over (which counts as rapid motion) rather than walk. Fix: define the reward at the outcome level (“task completed”), add penalty terms for undesired behaviors, and test the policy in held-out scenarios before trusting it. If a shortcut exists, the policy will find it. [5]
Check in this order: (1) actuator delay — simulation often underestimates motor latency, which throws off timing-sensitive policies; (2) friction — simulated contact is usually too clean; (3) sensor calibration — even small biases compound quickly. Add domain randomization over these specific parameters in simulation retraining, not over everything at once. Targeted randomization is faster to debug than broad randomization. [14]
For manipulation tasks, model-free RL typically needs tens of thousands to millions of environment interactions. On a physical robot collecting one sample per second, that is days to months of runtime — impractical for most projects. Simulation compresses this to hours. The Berkeley Real-World RL work showed that direct real-world RL is feasible for narrow tasks when you engineer around the reset problem, but it remains the exception rather than the rule. [16]
Model-free RL (PPO, SAC, TD3) learns a policy directly from interaction — simple to implement, but data-hungry. Model-based RL learns a dynamics model of the environment first, then uses it for planning — more sample-efficient but harder to scale when the model is wrong. In robotics, model errors accumulate with the robot’s DoF count. A good rule of thumb: use model-free when simulation is available and sample count is not the bottleneck; use model-based when real-world sample budget is tight. [26]
Use BC when: you have clean demonstrations and the task is unimodal (one correct way to do it). Use Diffusion Policy when: the task has multiple valid solutions (multimodal action distribution) — BC collapses these, Diffusion Policy handles them. Use RL when: you can define a reward precisely and simulation is available. In practice, many production systems combine them: RL for exploration-heavy subtasks, IL/Diffusion Policy for dexterous manipulation where demonstrations are available. [23]
Offline RL trains a policy entirely from a pre-collected dataset — no new interactions with the environment. This is the right choice when you have historical logs from a previous system but can’t afford physical rollouts, or when exploration is unsafe. The trade-off: offline RL is conservative by design, which limits performance on tasks requiring out-of-distribution exploration. IQL and TD3+BC are standard starting algorithms. If you can safely collect new data, online RL will almost always outperform offline RL given enough budget. [24]
Three layers in practice: (1) hard constraints — joint limits, force thresholds enforced at the controller level regardless of the learned policy; (2) action space restriction — limit the policy’s action range to physically safe motions during early training; (3) episodic resets — define clear reset conditions that stop the episode before damage occurs. Safe RL methods (constrained optimization, shielding) add a fourth layer but increase implementation complexity significantly. Start with hard constraints and resets — they catch the majority of failure modes. [20]
Minimum viable setup: a laptop with a GPU (RTX 3060 or better), MuJoCo or Isaac Lab, and the LeRobot library. You can run meaningful experiments in simulation with no physical hardware. For physical experiments on a budget, the SO-100 arm (~$100) paired with LeRobot is the current community-recommended entry point. Research-grade manipulation work uses Franka Panda or UR-series arms — these cost $10k–$30k and are the standard in academic papers, but not necessary for learning the fundamentals. [18]
It depends on the method and task. In simulation with GPU-accelerated training (Isaac Lab), locomotion policies train in hours. Manipulation policies for specific grasp tasks: several hours to a day. Imitation learning on 50–200 demonstrations: policy training takes minutes to hours, but data collection is the bottleneck (1–4 hours of teleoperation). The clock starts from hardware setup and sim configuration, not the training run itself — that setup often takes days or weeks on a new platform.
For tasks in unstructured environments — grasping novel objects, navigating cluttered spaces — yes, vision is required. For tasks in fixed, controlled environments — industrial assembly with known parts at known positions — proprioceptive sensing (joint angles, force/torque) is often sufficient and more robust. Adding vision increases the policy’s input dimensionality and requires more training data. Start without vision when possible; add it when the task genuinely requires object-level perception. [10]
Both, depending on the task. Learned perception (object detection, grasp quality prediction) is in production at scale in warehouse automation and semiconductor inspection. End-to-end learned control policies (sensor → action) are in production for locomotion (Boston Dynamics Spot) and selective bin-picking (Covariant/ABB). Full generalist policies operating across diverse tasks without task-specific training are still research-stage. The production frontier is advancing quickly — what required research hardware in 2022 often runs on commodity platforms today. [15] [19]
The gap is the performance drop between a policy that works in simulation and the same policy on real hardware. For locomotion on flat terrain: typically small, addressable with domain randomization. For dexterous manipulation: can be large, especially for soft or deformable objects where contact physics is hard to simulate accurately. For outdoor mobile robots with weather variation: significant and often requires additional real-world fine-tuning. The gap is not a fixed property of the task — it depends directly on how well your simulation is configured to match your specific hardware. [14]
Further Reading & References:
- [1] Siciliano, B., et al. Robotics: Modelling, Planning and Control — Springer — 2009
- [2] Bohg, J., et al. "Data-Driven Grasp Synthesis — A Survey" — IEEE Transactions on Robotics — 2014
- [3] NVIDIA. "Isaac Lab: GPU-Accelerated Robot Learning" — NVIDIA Developer — 2024
- [4] Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction (2nd ed.) — MIT Press — 2018
- [5] Krakovna, V., et al. "Specification Gaming: The Flip Side of AI Ingenuity" — DeepMind Blog — 2020
- [6] OpenAI. "Learning Dexterous In-Hand Manipulation" — arXiv — 2019
- [7] Argall, B. D., et al. "A Survey of Robot Learning from Demonstration" — Robotics and Autonomous Systems — 2009
- [8] Ross, S., Gordon, G., Bagnell, D. "A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning" — AISTATS — 2011
- [9] Zitkovich, B., et al. "RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control" — CoRL — 2023
- [10] LeCun, Y., Bengio, Y., Hinton, G. "Deep Learning" — Nature — 2015
- [11] Fang, H., et al. "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" — CVPR — 2020
- [12] NVIDIA. "Isaac Lab Documentation" — 2024
- [13] Todorov, E., Erez, T., Tassa, Y. "MuJoCo: A Physics Engine for Model-Based Control" — IROS — 2012
- [14] Tobin, J., et al. "Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World" — IROS — 2017
- [15] Covariant. "How Covariant's AI-Powered Robots Work" — Covariant.ai — 2023
- [16] Kumar, V., et al. (Boston Dynamics) — referenced via Margolis, G., et al. "Rapid Locomotion via Reinforcement Learning" — RSS — 2022
- [17] Levine, S., et al. "CS285: Deep Reinforcement Learning" — UC Berkeley — 2024
- [18] Cadène, R., et al. "LeRobot: State-of-the-Art Machine Learning for Real-World Robotics" — Hugging Face — 2024
- [19] Duan, Y., et al. "Benchmarking Deep Reinforcement Learning for Continuous Control" — ICML — 2016
- [20] García, J., Fernández, F. "A Comprehensive Survey on Safe Reinforcement Learning" — JMLR — 2015
- [21] IEEE. "Ethically Aligned Design: A Vision for Prioritizing Human Well-being" — IEEE — 2019
- [22] Hafner, D., et al. "Mastering Diverse Domains through World Models (DreamerV3)" — Nature — 2025
- [23] Chi, C., et al. "Diffusion Policy: Visuomotor Policy Learning via Action Diffusion" — IJRR / RSS — 2023
- [24] Kostrikov, I., et al. "Offline Reinforcement Learning with Implicit Q-Learning" — ICLR — 2022
- [25] Hafner, D., et al. "DayDreamer: World Models for Physical Robot Learning" — CoRL — 2022
- [26] Moerland, T. M., et al. "Model-based Reinforcement Learning: A Survey" — JMLR — 2023








