

When an AI system learns a task through trial and error, training can take weeks or even months before the model reaches reliable performance. In such situations, imitation learning, in which the model learns from expert demonstrations, can be a faster and more practical approach.
This guide explains how to choose the right training method, avoid common production pitfalls, and evaluate whether your model works in the real world instead of only performing well on training data.
Introduction to Imitation Learning
Imitation learning (IL) teaches an AI system by showing it how a task should be performed. Unlike reinforcement learning, where an agent gradually improves by receiving rewards or penalties, imitation learning allows the model to learn directly from expert behavior. Instead of discovering successful strategies on its own, the system starts with examples of decisions that already produce the desired outcome.
The time savings can be substantial. Rather than spending weeks or months exploring possible actions, an imitation learning system begins with examples of successful behavior. Research suggests that IL can require substantially fewer interactions with the environment than reinforcement learning to reach comparable performance, often improving sample efficiency by one or more orders of magnitude [1]. For a physical robot, that difference can determine whether a project is feasible within a practical development timeline or becomes an expensive, resource-intensive effort.
The process itself is straightforward. An expert, such as a surgeon, driver, or factory worker, performs the task while a recording system captures each step. Every recorded example includes the situation the expert observed and the action they chose in response. The model then studies these examples and learns to make similar decisions in comparable situations. By learning directly from demonstrated behavior, the system can acquire useful policies without extensive exploration of the environment.
How Does the Imitation Learning Framework Work?
Every IL system has four interconnected components. Miss any of them and the others don't help much.
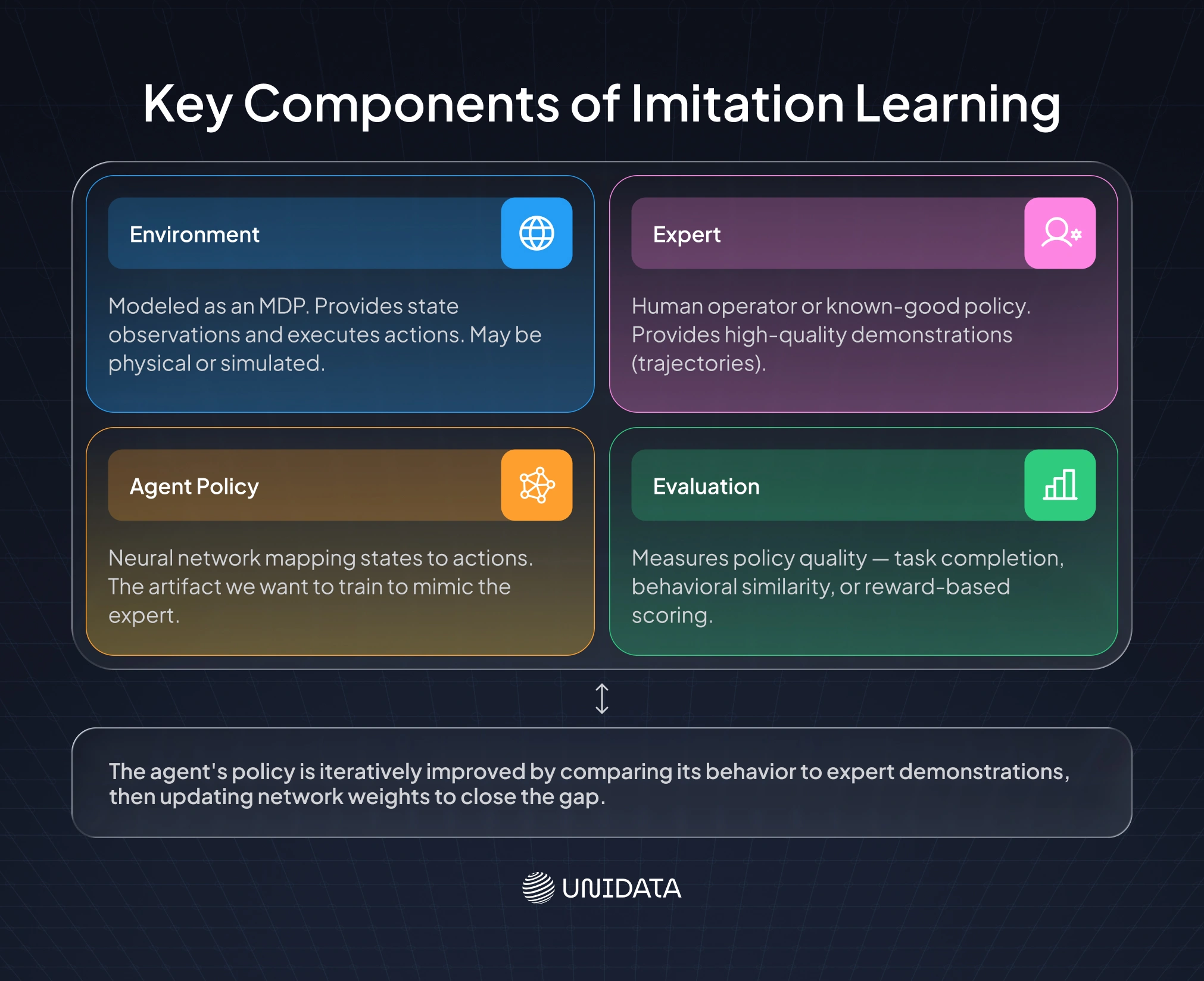
Environment. Modeled as a Markov decision process: states, actions, transitions, rewards. The environment receives actions and returns observations. Whether it is a simulation or a physical robot arm does not change the underlying structure, though it changes everything in practice.
Expert. The source of demonstrations. This could be a human using a teleoperation interface, a domain specialist, or an existing algorithm that already works. What matters is that the expert produces trajectories — sequences of state-action pairs recorded while performing the task competently.
Agent policy. Usually, a neural network maps observations to actions. Unlike reinforcement learning (RL), where the network learns from reward signals, IL learns by comparing its predicted actions with what the expert actually did.
Evaluation. This is where many IL projects mislead themselves. Accuracy on held-out demonstrations is easy to measure and tells you almost nothing about whether the deployed agent will actually work. Real evaluation requires task-completion metrics in actual or simulated environments - not just how well the network fits the demonstration dataset.
Why Use Imitation Learning Instead of Reinforcement Learning?
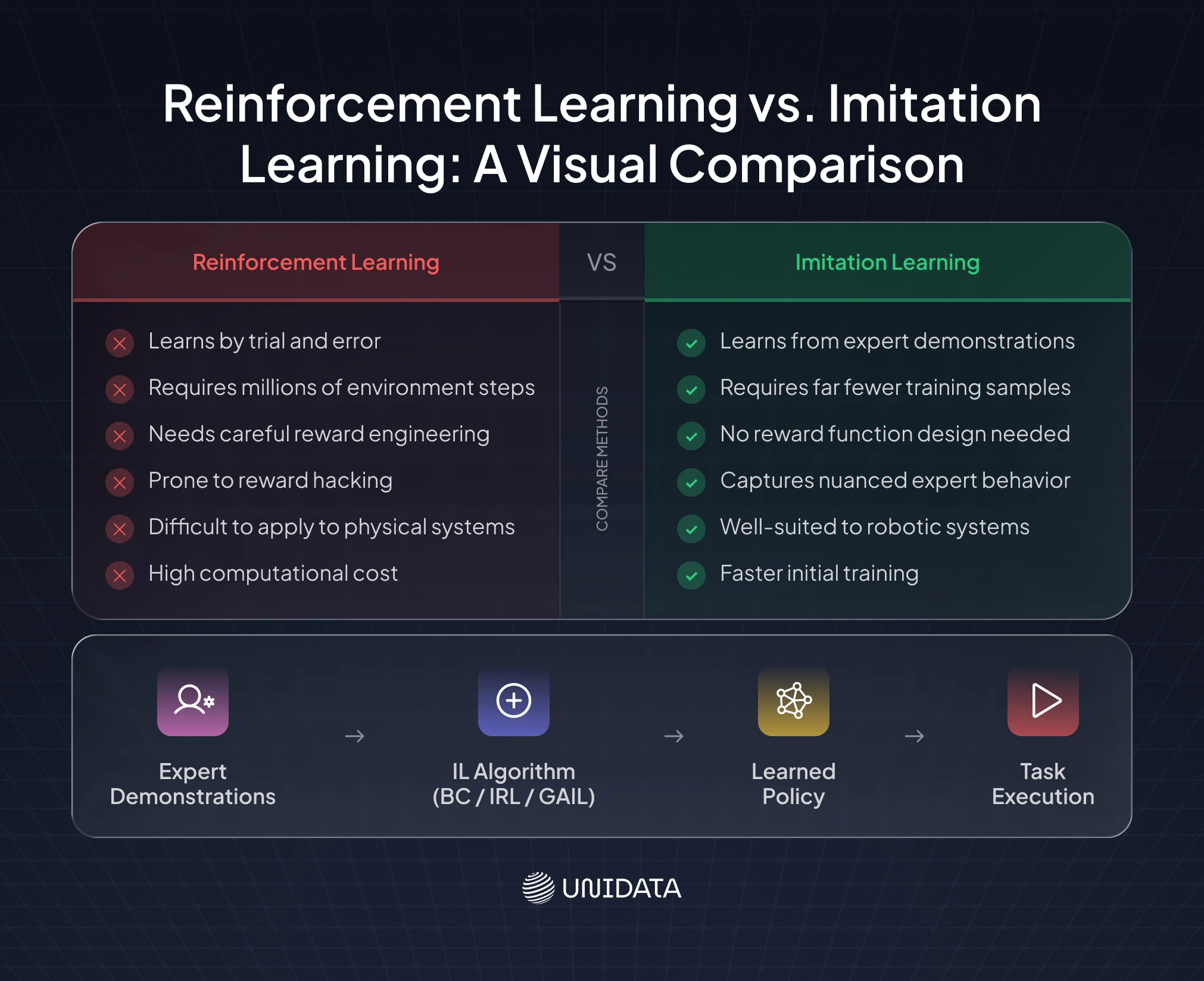
Reinforcement learning can produce impressive results, but it often comes with a major cost: data efficiency. An RL agent learns through trial and error, which means it may need millions of interactions with an environment before discovering a reliable strategy. In simulated environments, this can already be expensive. In the physical world, such as robotics, autonomous driving, or industrial systems, those failed attempts translate into wasted time, damaged hardware, safety risks, and high operating costs.
Imitation learning offers a more direct alternative. Instead of learning from random exploration, the model starts with examples of successful behavior from a human expert. This dramatically reduces the amount of training data and experimentation required to achieve useful performance.
Imitation learning is especially valuable when:
- Expert demonstrations are available
- Exploration is expensive or dangerous
- Tasks require human-like behavior
- Reward functions are difficult to design
- Fast deployment matters more than discovering entirely new strategies
Reinforcement learning still plays an important role, particularly when superhuman optimization or long-term planning is needed. In practice, many modern systems combine both approaches: imitation learning provides a strong starting point, and reinforcement learning fine-tunes performance afterward.
Which Imitation Learning Approach Fits Your Problem?
Imitation learning encompasses a family of methods that share the same goal - learning from expert demonstrations, but differ substantially in how they approach that goal. None of them is universally best. The right choice of method depends on the budget, whether you can query an expert during training, and how much generalization you need.
Behavioral Cloning: The Direct Approach
Behavioral cloning (BC) is the simplest and most widely used form of imitation learning. It frames the problem as straightforward supervised learning: given a dataset of state-action pairs from expert demonstrations, train a neural network to predict the expert's action from the current state. The implementation is familiar to any machine learning practitioner - collect data, define a loss function (typically mean squared error for continuous actions or cross-entropy for discrete ones), and minimize it with gradient descent.
Algorithm: Behavioral Cloning
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
class BCPolicy(nn.Module):
def __init__(self, obs_dim: int, act_dim: int, hidden: int = 256):
super().__init__()
self.net = nn.Sequential(
nn.Linear(obs_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, hidden),
nn.ReLU(),
nn.Linear(hidden, act_dim),
)
def forward(self, obs: torch.Tensor) -> torch.Tensor:
return self.net(obs)
def train_bc(policy, demos, epochs=100, lr=1e-3, val_split=0.1, batch_size=256):
states = np.concatenate([d.states for d in demos])
actions = np.concatenate([d.actions for d in demos])
obs_mean = states.mean(0)
obs_std = states.std(0) + 1e-8
states = (states - obs_mean) / obs_std
split = int(len(states) * (1 - val_split))
tr_data = TensorDataset(
torch.FloatTensor(states[:split]),
torch.FloatTensor(actions[:split]),
)
val_data = TensorDataset(
torch.FloatTensor(states[split:]),
torch.FloatTensor(actions[split:]),
)
optimizer = torch.optim.AdamW(policy.parameters(), lr=lr, weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, epochs)
loss_fn = nn.MSELoss()
best_val, best_state = float("inf"), None
for epoch in range(epochs):
policy.train()
for obs_b, act_b in DataLoader(tr_data, batch_size=batch_size, shuffle=True):
optimizer.zero_grad()
loss = loss_fn(policy(obs_b), act_b)
loss.backward()
optimizer.step()
scheduler.step()
policy.eval()
with torch.no_grad():
val_loss = 0.0
n = 0
for o, a in DataLoader(val_data, batch_size=batch_size):
batch_loss = loss_fn(policy(o), a).item()
val_loss += batch_loss * len(o)
n += len(o)
val_loss /= max(n, 1)
if val_loss < best_val:
best_val = val_loss
best_state = {k: v.clone() for k, v in policy.state_dict().items()}
if best_state is not None:
policy.load_state_dict(best_state)
return policy, obs_mean, obs_std
BC works well on short tasks with plenty of data. It falls apart on anything long. The reason is compounding error. If the policy makes a mistake with probability ε per step, the expected divergence from the expert's distribution grows as O(T²ε)over a horizon of T steps [2]. That is quadratic. A policy that's 99% accurate per step can fail badly on tasks requiring more than a few dozen decisions, which covers most interesting tasks.
The underlying mechanism is a distribution shift. The agent's own mistakes push it into states the expert never visited. The policy has seen nothing like those states, so it usually guesses badly. The bad guess leads to a worse state. Errors cascade.
Behavioral Cloning: Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Simple to implement — standard supervised learning pipeline, familiar tooling | Vulnerable to compounding errors — small mistakes accumulate in long sequences |
| Fast training — no environment interaction required during learning | Distribution shift fragility — fails in states outside the demonstration distribution |
| Works well on short-horizon tasks — errors don't have time to compound | Ignores causal structure — treats each timestep independently |
| Effective with large datasets — performance scales with demonstration quantity | Requires expert-quality data — sub-optimal demonstrations directly impair the policy |
Direct Policy Learning via Interactive Demonstration
Direct policy learning (DPL) methods, most notably DAgger (Dataset Aggregation) [2], were designed to solve a common problem in imitation learning called distribution shift. This happens when a model performs well on training examples but struggles in real use because it encounters situations that were never included in the demonstration data.
DAgger addresses this by training the model on the situations it actually reaches during execution, including its mistakes. Instead of learning only from clean expert demonstrations, the model repeatedly interacts with the environment while the expert provides the correct action for the states the model visits.
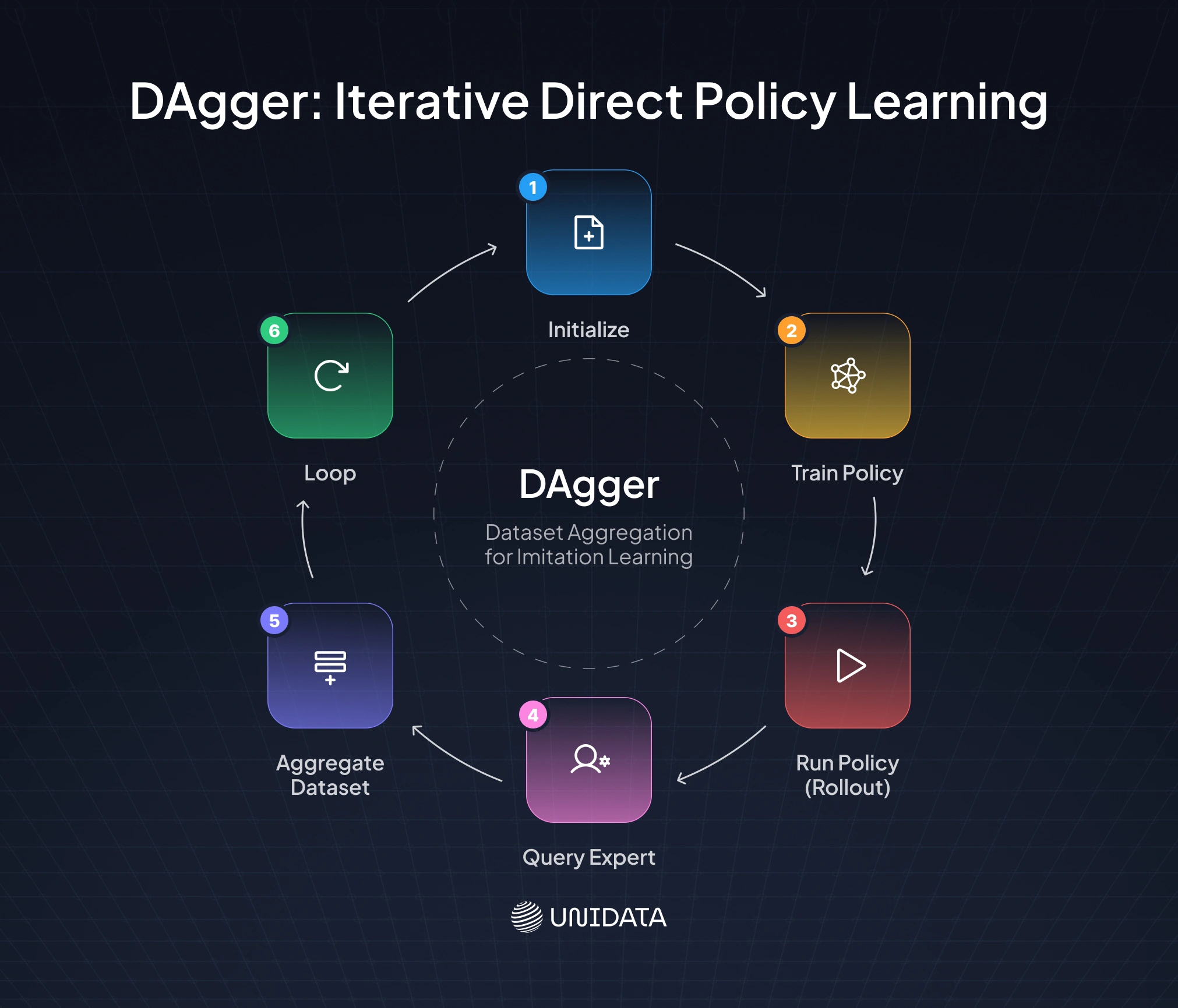
- Initialize: Start with an initial dataset $$D$$ of state-action pairs $$(o, a)$$ collected from an expert, and an initial policy $$\pi_1$$.
- Train Policy: Train the current policy $$\pi_i$$ (often a neural network) on the collected dataset $$D$$.
- Run Policy (Rollout): Run the trained policy $$\pi_i$$ in the environment to collect new states, creating a new trajectory of observations.
- Query Expert: For every state $$o_t$$ visited by the policy, ask the expert (human or controller) for the correct action $$a_t^*$$.
- Aggregate Dataset: Add the new expert-labeled observations to the dataset: $$D \leftarrow D \cup {(o_t, a_t^*)}$$.
- Loop: Repeat from Step 2 until the policy performs well.
By repeating this cycle, the model gradually learns how to recover from its own errors and handle more realistic scenarios. This makes DAgger far more reliable on long tasks where small mistakes can accumulate over time.
import numpy as np
import torch
def train_dagger(env, policy, expert, train_bc_fn, n_iterations=10, rollout_steps=1000):
aggregated_states = []
aggregated_actions = []
for _ in range(n_iterations):
obs = env.reset()
visited_states = []
for _ in range(rollout_steps):
with torch.no_grad():
obs_tensor = torch.FloatTensor(obs).unsqueeze(0)
action = policy(obs_tensor).squeeze(0).cpu().numpy()
next_obs, _, done, _ = env.step(action)
visited_states.append(obs)
obs = next_obs
if done:
obs = env.reset()
expert_actions = [expert(s) for s in visited_states]
aggregated_states.extend(visited_states)
aggregated_actions.extend(expert_actions)
demos = type("Demos", (), {})()
demos.states = np.array(aggregated_states)
demos.actions = np.array(aggregated_actions)
policy, _, _ = train_bc_fn(policy, [demos])
return policy
The main drawback is that the expert must stay involved during training. Someone needs to review the model’s behavior and provide correct actions at every iteration. Methods such as SafeDAgger reduce this workload by only asking for expert input when the model is uncertain. In some systems, a pretrained oracle model is used instead of a human expert.
Inverse Reinforcement Learning
Inverse reinforcement learning (IRL) takes a fundamentally different approach to imitation. Rather than directly learning to copy expert actions, IRL asks: what reward function is the expert implicitly optimizing? Once that reward function is inferred, standard reinforcement learning can be used to derive a policy that optimizes it — possibly outperforming the expert in the process.
This framing has roots in optimal control theory, where the problem of inferring objectives from observed behavior has a long history. In the machine learning context, IRL was formalized by Ng and Russell [3] and later extended by Abbeel and Ng [4] under the name apprenticeship learning.
Collect Expert Demonstrations
Record trajectories of the expert operating in the environment.
Define Reward Function Parameterization
Choose a family of reward functions, such as linear combinations of state features or a neural network.
Initialize Reward Parameters
Start with a random or zero reward function.
Solve the RL Problem
Use reinforcement learning to find the optimal policy under the current reward function.
Compare Feature Expectations
Measure the gap between the expert's feature expectations and the current policy's feature expectations.
Update Reward Parameters
Adjust the reward function to better explain the expert's behavior using a gradient step or quadratic program.
Iterate Until Convergence
Repeat steps 4–6 until the policy matches the expert behavior.
The key advantage of IRL over behavioral cloning is generalization. A learned reward function captures the intent behind expert behavior, not just its surface manifestation. A policy trained on that reward function can generalize to new environments, new starting conditions, and new task variations in ways that direct policy cloning cannot. This is particularly valuable in autonomous driving, where the space of possible road conditions vastly exceeds what any demonstration dataset can cover.
Egocentric Data Collection for Robot Training: What Actually Works in Production
Learn more
IRL faces a fundamental challenge: reward ambiguity. Many different reward functions can explain the same observed behavior. An expert who always drives in the center lane might be optimizing safety, comfort, convenience, or any combination of these. Maximum Entropy IRL [5] addresses this by choosing the reward function that makes the expert’s behavior as probable as possible while remaining maximally uncertain about unobserved behaviors, a principled information-theoretic solution.
import torch
import torch.nn as nn
class RewardNetwork(nn.Module):
def __init__(self, obs_dim, act_dim, hidden=128):
super().__init__()
self.net = nn.Sequential(
nn.Linear(obs_dim + act_dim, hidden),
nn.Tanh(),
nn.Linear(hidden, hidden),
nn.Tanh(),
nn.Linear(hidden, 1),
)
def forward(self, obs, act):
return self.net(torch.cat([obs, act], dim=-1)).squeeze(-1)
def maxent_irl_step(reward_net, expert_obs, expert_acts, policy_obs, policy_acts, optimizer):
expert_reward = reward_net(expert_obs, expert_acts).mean()
policy_reward = reward_net(policy_obs, policy_acts).mean()
loss = -(expert_reward - policy_reward)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
The main practical drawback of IRL is computational cost. Each iteration of the IRL loop requires solving a full RL problem, which is itself expensive. In high-dimensional continuous environments like robotics, this can make IRL prohibitively slow. Researchers have developed approximations—including neural network reward functions trained with gradient descent—that substantially reduce this cost, but IRL remains more expensive than behavioral cloning for equivalent problems.
IRL is the method of choice when: the reward function is genuinely unknown or hard to specify, generalization to new scenarios is critical, and sufficient computation is available.
Advanced Methods and Recent Innovations
Three approaches from the last several years have pushed performance beyond what BC and IRL can achieve — each borrowing from a different corner of deep learning.
Generative Adversarial Imitation Learning (GAIL)
Generative Adversarial Imitation Learning (GAIL), introduced by Ho and Ermon [6], draws on the generative adversarial network (GAN) framework. GAIL trains two networks simultaneously: a policy, the generator, that tries to produce behavior indistinguishable from the expert, and a discriminator that tries to distinguish the policy’s behavior from the expert’s. This adversarial setup enables GAIL to match the entire distribution of expert state-action pairs, not just individual transitions. GAIL consistently outperforms behavioral cloning in benchmarks involving complex locomotion and manipulation tasks, particularly when demonstrations are limited.
Decision Transformer
Decision Transformer [7] reframes imitation learning as sequence modeling. It treats the entire trajectory — states, actions, and returns — as a sequence and uses a transformer to generate actions conditioned on the desired future return. This approach scales with data and computation the way large language models do. It has been applied to offline RL benchmarks, including the D4RL suite, and is used in multi-task pretraining pipelines at research labs, including Google Brain and Meta AI.
Diffusion Policy
Diffusion Policy [8] applies diffusion models — the architecture behind image generation systems like Stable Diffusion — to action prediction. Rather than outputting a single action, Diffusion Policy models the distribution of expert actions conditioned on the current state and generates actions by iteratively denoising from a noise distribution. This approach handles multimodal action distributions naturally, since the same state might call for very different actions depending on context, and produces smooth, high-quality trajectories. Diffusion Policy has achieved state-of-the-art results on robotic manipulation benchmarks and is gaining significant traction in the robotics research community, for example, in dexterous hand manipulation tasks at Stanford and MIT and in bimanual assembly tasks with the ALOHA robot platform. [12]
Comparison of Imitation Learning Methods Across Key Dimensions
| Method | Sample Efficiency | Generalization | Computational Cost | Implementation Complexity | Best For |
|---|---|---|---|---|---|
| Behavioral Cloning | Medium | Low | Low | Low | Short-horizon tasks, large datasets |
| DAgger / DPL | High | Medium | Medium | Medium | When an interactive expert is available |
| Inverse RL | Medium | High | High | High | Unknown reward, cross-domain transfer |
| GAIL | High | High | High | High | Complex distributions, limited demos |
| Decision Transformer | High | High | Medium | Medium | Offline RL, large-scale pretraining |
| Diffusion Policy | High | High | Medium | Medium | Robotic manipulation, multimodal actions |
As a rule of thumb: start with Behavioral Cloning for speed and simplicity. Move to DAgger when the distribution shift is the primary failure mode. Choose IRL or GAIL when generalization across environments matters most. Diffusion Policy and Decision Transformer are worth considering once you have a working baseline and want to further improve performance.
Where Is Imitation Learning Already Delivering Results?
Manufacturing: Teaching Robots from Worker Demonstrations
Industrial robots are good at repeating fixed tasks but struggle with variation. IL changes the collection mechanism — a technician performs the task using a teleoperation interface, and the demonstrations capture force corrections, speed adjustments, and recovery moves.
Kernbach et al. [13] demonstrated behavioral cloning for automotive connector insertion — a contact-rich manipulation task that has resisted conventional programming due to tight tolerances and variable connector geometries. Using up to 300 human demonstrations collected via SpaceMouse teleoperation on a UR5e robot, the resulting BC system achieved an overall insertion success rate of over 90% across five different connector geometries and varying connector poses.
Manufacturing results [13]:
- Task completion rate: >90% across 5 connector geometries
- Demonstrations required: up to 300 per task variant
- Method: behavioral cloning with force-torque sensing + fixed-position camera
Autonomous Vehicles: Capturing Human Driving Judgment
Driving involves thousands of judgment calls that nobody has ever explicitly written down. Appropriate following distance in rain. How much to yield to a cyclist who's wobbling slightly? When a pedestrian on the curb is actually about to step out. Rule-based systems hit a wall on this.
Companies such as Waymo, Tesla, and others use imitation-learning-inspired approaches as part of their training pipelines, leveraging large volumes of human driving data to train driving policies. The problem is that pure BC fails on rare scenarios — the unusual intersection geometry, the unexpected pedestrian — that are underrepresented even in massive datasets.
Bi-level imitation models split the problem: high-level route planning trained on extensive GPS route data, and low-level control trained on detailed sensor recordings from specifically collected challenging scenarios. Simulation environments like CARLA and SUMO fill rare-scenario gaps synthetically, reducing real-world data requirements by an order of magnitude [9].
Healthcare: Surgical Robotics from Expert Surgeon Recordings
The stakes here are higher than anywhere else IL is deployed. The ORBIT-Surgical benchmark provides a simulation environment specifically for training surgical robots via IL, and studies using it show that IL-trained policies can replicate needle handling and suture tying within the tolerances needed for real procedures [10].
Mahler et al. [14] applied imitation learning to the peg transfer subtask in laparoscopic surgery training on a da Vinci Research Kit. By combining a coarse open-loop policy with a learned visual-servo correction policy trained on 180 demonstrations, the system achieved success rates of 99.2% to 100% across instruments with differing cable dynamics — a substantial improvement over the 31% to 73% baseline.
Gaming: Human-like AI from Player Recordings
Games are where IL research does most of its benchmarking. Controlled, repeatable, fast to simulate. But commercial game development has genuine deployment interest too — rule-based NPCs are predictable in ways that players eventually learn to exploit.
AlphaGo [11] is the canonical example of IL bootstrapping RL. Its architecture uses two deep networks: a policy network trained first by supervised learning on human expert games, and a value network trained by RL self-play combined with Monte Carlo Tree Search (MCTS). The supervised learning initialization gave the policy network a starting point that made subsequent self-play RL tractable — without it, the RL training would have been computationally out of reach.
Simulation environments like MuJoCo and Isaac Gym are widely used as IL testbeds because they support DAgger’s iterative data collection at scale, running far faster than equivalent physical systems.
What Challenges Should Practitioners Anticipate Before Deploying Imitation Learning?
Data Quality and Diversity
The expert demonstrations set the ceiling. Behavioral cloning cannot exceed the quality of its training data, unlike RL, which can discover better-than-expert behavior through exploration. If the demonstrations are mediocre, the policy is mediocre.
Diversity is where most teams underinvest. Research on data quality in imitation learning [15] shows, both theoretically and empirically, that dataset coverage matters more than raw size: a smaller dataset spanning edge cases and the realistic range of variation consistently produces more robust policies than a larger dataset concentrated in a narrow distribution.
Three ways to address limited data:
• Teleoperation — joystick, VR, or physical guidance interfaces keep per-demonstration expert burden low
• Simulation-based collection — fast and scalable; sim-to-real transfer requires domain randomization to prevent the policy from overfitting to simulation physics
• Synthetic augmentation — mirroring, noise injection, and domain randomization can multiply effective dataset size without any additional expert time
Compounding Errors and Distribution Shift
The math here is unforgiving. The O(T²ε) bound from Ross et al. [2] means that error accumulation is quadratic in horizon length. In practice, even small per-step errors can accumulate surprisingly quickly on long-horizon tasks. As task length increases, the agent is increasingly likely to encounter states that were not represented in the demonstration data, causing performance to degrade over time. Most real manipulation and navigation tasks require hundreds of steps, making this a fundamental obstacle for pure BC on long-horizon tasks.
The mechanism is simple: each small mistake moves the agent to a state the expert never visited. The policy has no experience there. The next prediction is less reliable. That unreliable prediction leads to a worse state. The divergence compounds.
A concrete example: a highway driving policy trained with behavioral cloning handles most situations correctly. Then it misjudges a lane change by half a meter. It's now in a lateral position that the expert never demonstrated. The next steering command overcorrects. The overcorrection puts it into oncoming traffic. The whole cascade took four seconds.
Mitigation options:
- DAgger — builds the training set from states the deployed policy actually visits
- Perturbation augmentation — adds demonstrations near (but not on) the expert's trajectory, explicitly teaching recovery behavior
- Noise injection during training — similar effect without requiring additional expert time
- Robust IL — adversarial training that optimizes for graceful degradation under perturbation
Safety and Robustness in Physical Systems
No neural network policy comes with formal stability guarantees equivalent to classical control methods. You cannot run a Lyapunov analysis on a transformer. A policy that works on 99.9% of test cases may still behave unpredictably on the remaining 0.1%, and in autonomous vehicles or surgical robots, that 0.1% matters.
Standard practice for safety validation:
- Extensive simulation testing with adversarial scenario generation
- Domain randomization to surface failure modes before real-world deployment
- Runtime distribution shift monitoring with a conservative fallback when the agent enters unfamiliar states
- Safety constraints baked into training to keep actions within a certified safe set. ISO 26262 (automotive) and IEC 62304 (medical devices) provide validation frameworks, though neither was designed with learned policies in mind. Active work is underway to extend both standards to cover neural network components.
- ISO 26262 (automotive) and IEC 62304 (medical devices) provide validation frameworks, though neither was designed with learned policies in mind. Active work is underway to extend both standards to cover neural network components.
How to Implement Imitation Learning Systems?
Data Collection and Processing
Data collection is the phase most likely to determine whether the project succeeds. The architecture decisions matter, but a good model trained on poor data won't save you.
Three collection approaches worth knowing:
- Teleoperation — the default for robotic systems. Stanford's ALOHA system — open-source, bimanual, relatively low cost — has enabled high-quality manipulation demonstrations at a scale that was previously impractical [13]
- Simulation-based collection — fast to scale; domain randomization is required to prevent the policy from memorizing simulation-specific artifacts
- Motion capture — useful when sub-millimeter precision is needed, and teleoperation jitter would corrupt the signal
Five preprocessing steps that consistently improve policy quality:
- Temporal alignment of sensor streams
- State normalization to zero mean and unit variance
- Action filtering to remove high-frequency noise from teleoperation inputs
- Trajectory segmentation into task-coherent episodes
- Quality filtering — remove any demonstration where the task was not actually completed
Libraries: Robosuite for robotic simulation, D3RLPy for offline RL and IL; both have built-in preprocessing pipelines.
Model Selection and Training
Architecture depends on what the inputs look like and whether history matters:
- Visual inputs — CNNs or Vision Transformers; ResNet encoders pretrained on ImageNet are a practical starting point that reduces data requirements
- History-dependent tasks — LSTM, GRU, or transformer sequence models; if the right action depends on what happened two steps ago, a stateless policy won't capture it
- High-dimensional continuous actions — Diffusion Policy is the current state of the art for manipulation tasks when you have more than a few hundred demonstrations
Training Details That Actually Matter:
- Small learning rate with warmup — reduces overfitting to the specific trajectories in the training set
- L2 regularization or dropout — prevents the network from memorizing individual demonstrations
- Early stopping on held-out demonstration loss
- Avoid batch normalization in robot control networks — batch statistics behave differently at inference time and can cause instability
- Use Optuna for hyperparameter search when you have the compute budget
Evaluation Metrics
Held-out demonstration loss is easy to compute and the wrong thing to optimize. It measures how well the network fits the training distribution — not whether the agent completes the task.
| Category | Metric | When to use |
|---|---|---|
| Behavioral fidelity | Action distribution KL divergence | Model selection and debugging |
| Task performance | Task success rate | Primary deployment metric |
| Task performance | Time to completion vs. expert | Operational assessment |
| Robustness | Perturbation success rate | Safety validation |
| Robustness | OOD scenario performance | Generalization check |
| Safety | Constraint violation rate | Safety-critical deployments |
Run all three: in-distribution tests, out-of-distribution tests, and perturbation tests. Use expert demonstration performance as the ceiling and a simple heuristic as the floor. If the policy can't beat the heuristic, something is wrong.
Deployment and Monitoring
Real environments are harder than test environments. Sensors are noisier. Environmental conditions drift. A policy that passed all your pre-deployment tests can still fail six months later on inputs that look slightly different from anything it was trained on.
Distribution shift detection — non-negotiable for any production IL deployment:
- Track prediction uncertainty — high uncertainty is the clearest signal that the agent is in unfamiliar territory
- Monitor input statistics — shifts in observation distributions precede performance degradation
- Log cases where the policy's output deviates from a backup heuristic — these are likely edge cases worth collecting
- When any of these signals fire, fall back to the conservative policy or flag for human review
Deployment Сhecklist
Validate on held-out scenarios not used in training
Implement OOD detection
Define explicit fallback behavior for low-confidence states
Set up monitoring with alerting thresholds
Establish a re-training protocol when a distribution shift is confirmed
Document known failure modes and the system's operating envelope
Assign clear human oversight responsibilities
Conclusion
Imitation learning is a practical tool, not a silver bullet. It works well when expert knowledge is available, when the task is too complex for manual rule specification, and when you can't afford the exploration cost of RL. In those conditions, IL typically outperforms RL in the early phases of development by a wide margin.
For practitioners starting, begin with behavioral cloning. It's fast to implement, easy to evaluate, and will tell you quickly whether your data collection setup is working. When BC fails — and on long-horizon tasks it will — the failure mode itself guides you toward DAgger or IRL.
The field is moving fast. Cross-embodiment transfer, vision-language-action models, and diffusion-based action generation are all producing results that would have seemed optimistic two years ago. The underlying idea — that the easiest way to teach an AI system is to show it what to do — is probably going to remain central to robotics and embodied AI for a long time.
- AI Training
- Robotics
- Data Annotation
- Python
- AWS

Frequently Asked Questions (FAQ)
Imitation learning (IL) trains AI systems using expert demonstrations. The model learns by copying successful actions instead of discovering them through trial and error. Reinforcement learning (RL) relies on exploration and reward signals, often requiring far more interactions with the environment. Many modern systems use IL for initial training and RL for later optimization.
An imitation learning system consists of four core components: the environment, the expert, the agent policy, and evaluation. The environment provides observations, the expert supplies demonstrations, the policy learns to map observations to actions, and evaluation measures real-world task performance rather than training accuracy alone.
Choose imitation learning when expert demonstrations are available, exploration is costly or unsafe, reward functions are difficult to design, or rapid deployment is important. Reinforcement learning is often better suited for tasks that require long-term planning or discovering strategies beyond human performance.
Behavioral cloning (BC) treats imitation learning as a supervised learning problem by training a model on expert state-action pairs. Its main limitation is compounding error: small mistakes can accumulate over time, causing the agent to drift into situations not represented in the training data. BC works best for shorter tasks with high-quality demonstrations.
DAgger (Dataset Aggregation) improves behavioral cloning by collecting data from states visited by the policy itself, including mistakes. The expert labels these states, and the new examples are added to the training set. This helps the model learn recovery behaviors and perform more reliably in real-world conditions.
These are advanced imitation learning methods. GAIL uses adversarial training to match expert behavior, Decision Transformer applies transformer-based sequence modeling to decision-making, and Diffusion Policy generates actions using diffusion models. They often outperform behavioral cloning on complex tasks or limited datasets.
Further Reading & References:
- [1] Osa, T., et al. (2018). An Algorithmic Perspective on Imitation Learning. Foundations and Trends in Robotics, 7(1–2), 1–179
- [2] Ross, S., Gordon, G., & Bagnell, D. (2011). A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. AISTATS 2011
- [3] Ng, A. Y., & Russell, S. (2000). Algorithms for Inverse Reinforcement Learning. ICML 2000, 663–670
- [4] Abbeel, P., & Ng, A. Y. (2004). Apprenticeship Learning via Inverse Reinforcement Learning. ICML
- [5] Ziebart, B. D., et al. (2008). Maximum Entropy Inverse Reinforcement Learning. AAAI 2008, 1433–1438
- [6] Ho, J., & Ermon, S. (2016). Generative Adversarial Imitation Learning. NeurIPS 2016
- https://arxiv.org/abs/2106.01345
- [8] Chi, C., et al. (2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. RSS 2023
- [9] Codevilla, F., et al. (2019). Exploring the Limitations of Behavior Cloning for Autonomous Driving. ICCV 2019
- [10] Yu, Q., Moghani, M., Dharmarajan, K., et al. (2024). ORBIT-Surgical: An Open-Simulation Framework for Learning Surgical Augmented Dexterity. ICRA 2024
- [11] Silver, D., et al. (2016). Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature, 529, 484–489
- [12] Zhao, T.Z., Kumar, V., Levine, S., & Finn, C. (2023). Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (ALOHA). RSS 2023
- [13] Kernbach, A., et al. (2026). Behavioral Cloning for Robotic Connector Assembly: An Empirical Study
- [14] Mahler, J., et al. (2021). Intermittent Visual Servoing: Efficiently Learning Policies Robust to Instrument Changes for High-precision Surgical Manipulation. ICRA 2021
- [15] Belkhale, S., et al. (2023). Data Quality in Imitation Learning. NeurIPS 2023








