
At Unidata, we collect egocentric data in production for robot learning teams — across warehouses and dark kitchens. Before we settled on what works, we tested every major dataset type and ran our own capture campaigns.
The problem every manipulation team hits eventually: the robot trains well, evaluates well, then fails in the real environment. Not because the algorithm is wrong — because the training data was captured from a viewpoint the robot's sensor never sees. That distribution gap is the manipulation policy's single biggest silent killer, and closing it starts with how you collect data.


This guide covers what we learned: which dataset types actually work, what hardware matters, how to annotate at scale, and where the honest gaps still are.

About the author: Kirill Meshyk
Head of AI Data Collection at Unidata. Designs and runs egocentric capture pipelines for robot manipulation clients — from scenario scripting through annotation delivery.
Key Takeaways
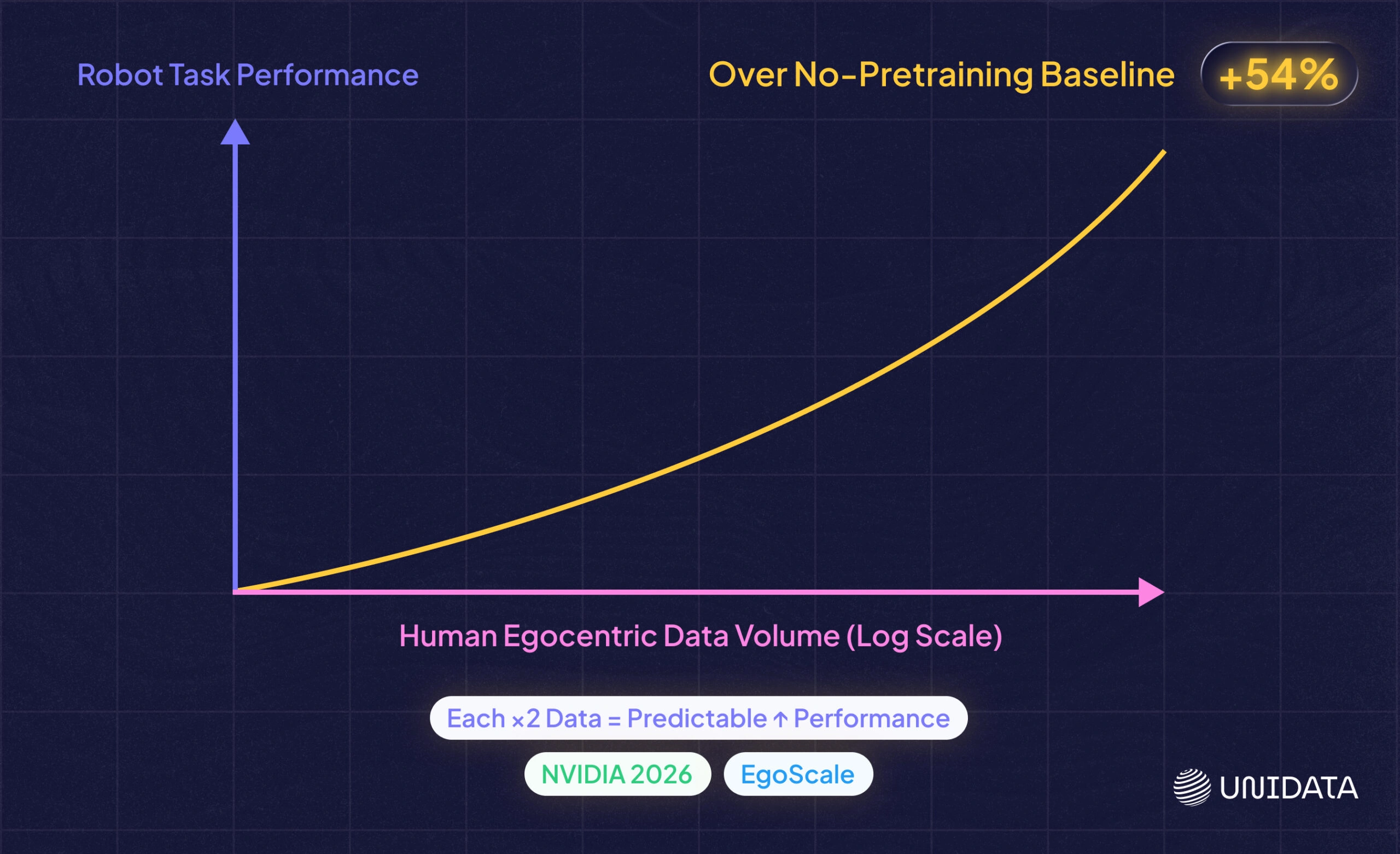
Human egocentric data is a multiplier, not a substitute. EgoMimic, EgoDex, and EgoScale demonstrate that properly collected human egocentric data boosts robot policy performance at scale. NVIDIA's EgoScale found a log-linear scaling law: every doubling of human egocentric video hours produces a predictable gain in downstream task success.
"Robot-ready" data requires deliberate design. Five properties matter: camera FOV matched to the robot's onboard sensor, multimodal synchronization (RGB + depth + IMU + skeleton), per-joint hand pose annotations, scripted scenario coverage of failure and recovery cases, and temporal segmentation at sub-action granularity — not just segment-level action labels.
Annotation depth separates trainable data from footage that just looks right. Bounding boxes are insufficient. Manipulation policies need per-joint keypoints at grasp closure, contact point labels, object state changes, and failure flags — annotation complexity that most pipelines underestimate at project start.
Three challenges appear in every production project. Hand occlusion degrades tracking quality at the most critical moment (grasp closure); operator fatigue after 3–4 hours produces biased movements; and first-person video is biometric data under GDPR, requiring written consent and environment preparation before capture begins.
Simulation without real-scan geometry has a gap inside the pipeline. A 3D scan of the real capture environment — not a generic scene — concentrates the remaining sim-to-real problem on object dynamics and material properties, not scene structure.
Force data is the next frontier. Video captures what the hand looks like. It cannot capture how hard a grasp is or when slip is imminent. Motor signals and gripper force data are absent from every publicly available egocentric dataset — and for deformable objects, force feedback is the primary signal a policy needs.
Why Do Most Egocentric Datasets Fall Short for Robot Manipulation?
Most egocentric datasets were built for action recognition — classifying what is happening. Manipulation policy training needs something different: predicting what to do next, at 10–30 Hz (higher for high-dynamic tasks such as catching objects or precision assembly), from a viewpoint that matches the robot's end-effector camera. Same footage, fundamentally different data requirements.
Ego4D and EPIC-Kitchens: Strengths and Limitations
Use these datasets for evaluating perception components — hand-object detection models, action forecasters. Do not use them as the primary training data source for a manipulation policy. Each was built for first-person understanding, not for teaching a robot what to do next.
Ego4D (Meta AI, 2021) is the largest first-person video dataset available — 3,670 hours across 74 locations in nine countries, with benchmarks for episodic memory, forecasting, and hand-object interaction. [1] The limitation for manipulation: head-mounted capture, a daily-life action vocabulary, and no per-joint hand pose as a primary deliverable.
EgoExo4D (Meta AI, 2023) adds synchronized egocentric and exocentric video — the same action from head-mounted and fixed third-person cameras simultaneously. [2] Useful for teleoperation research that needs to compare perspectives. The sensor geometry still does not match a wrist-mounted end-effector camera.
EPIC-Kitchens is the standard benchmark for kitchen activity recognition — 100 hours of cooking, well-annotated for action segments. [4] Manipulation relevance is limited to kitchen tasks, and the distribution is built around consumer GoPros, not robot-matched sensor geometry.
Project Aria (Meta AI) is a research-grade glasses-form-factor sensor platform with eye tracking, spatial audio, and IMU. [3] Designed for fundamental perception research, not production-scale manipulation capture.
Distribution Gap Between Human Capture and Robot Sensors
Camera placement is the mismatch teams underestimate most. A policy trained on head-mounted footage sees hands entering the frame from below. A wrist-mounted end-effector camera sees the workspace from 15–30 cm above the object, looking roughly downward. These are not similar viewpoints — and a policy trained on one will fail consistently on fine manipulation tasks when evaluated on the other.

Three hardware mismatches that cause the most policy degradation:
- Mounting position: head vs. wrist vs. chest changes the perspective angle, the hand-object geometry, and what goes in and out of frame during reach
- Field of view: camera FOV must match the robot's onboard camera. Standard action cameras run wide (GoPros at 110°+); many robot wrist cameras are also wide-angle or fisheye. The mismatch that degrades policy performance is not wide vs. narrow per se — it is any FOV difference between training and deployment. A policy trained on footage from a lens the robot's camera never replicates will over-fit to visual context that disappears at inference time
- Depth: most public egocentric datasets are RGB-only; robot policies that use depth inputs need depth-synchronized training data
If the observation space at training time differs from inference time, the policy is generalizing from day one — and not in a controlled way. [5]
EgoMimic, EgoDex, and EgoScale and the Value of Human Egocentric Data
The three most significant results from 2024–2026 shift how to think about the ROI of human egocentric data — not as a cheaper substitute for robot data, but as a multiplier that amplifies the value of whatever robot demonstrations you already have.
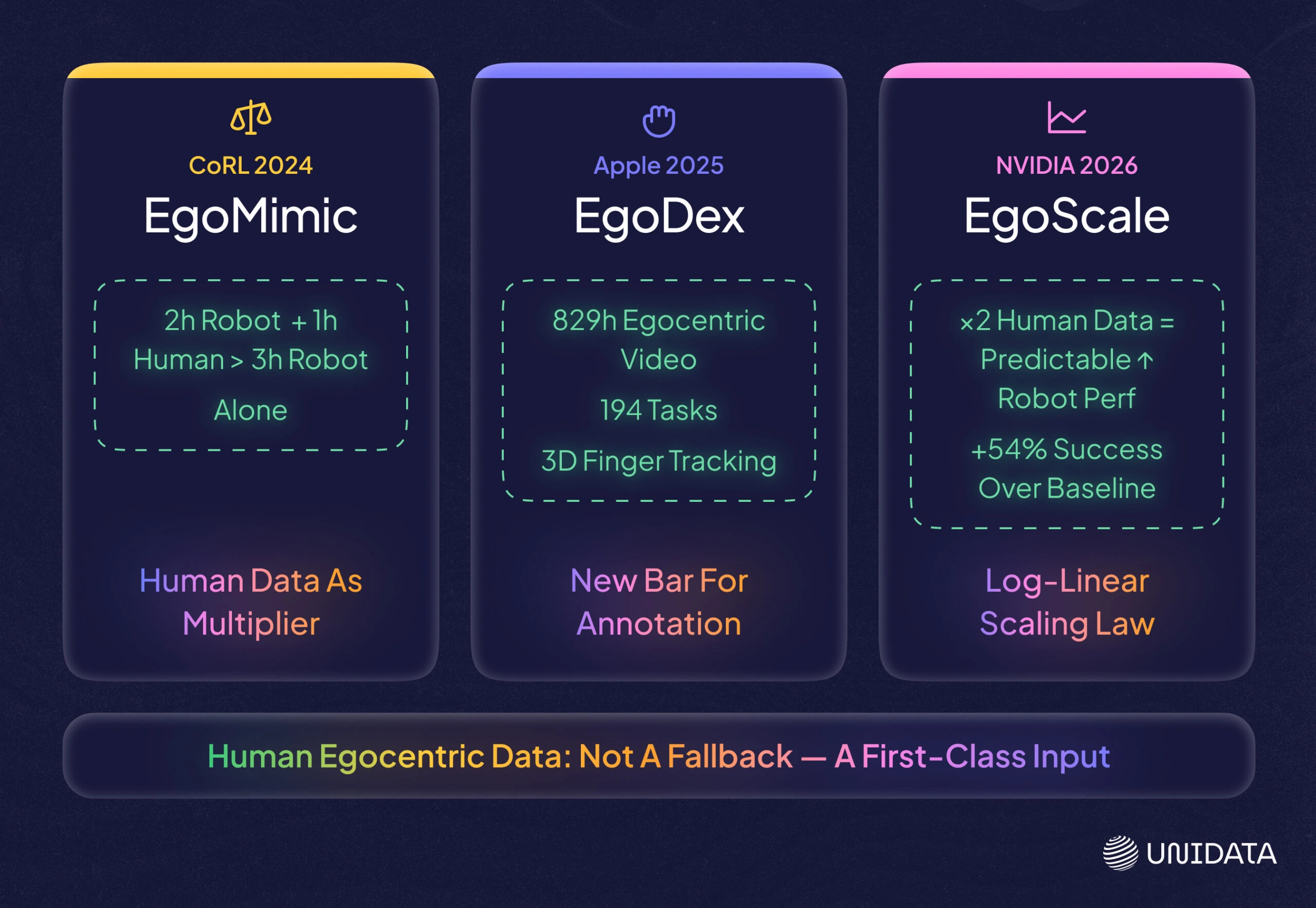
EgoMimic (Georgia Tech / Stanford, CoRL 2024) co-trained a manipulation policy on human egocentric data alongside robot demonstrations. The key finding: 1 hour of human egocentric hand data — collected with Meta Project Aria glasses — contributed more to policy performance than 1 additional hour of robot teleoperation data. [20] The human data was collected with the same glasses worn by the robot during deployment, deliberately closing the visual domain gap at the hardware level.
EgoDex (Apple, 2025) is the largest dexterous manipulation dataset to date: 829 hours of egocentric video with paired 3D hand and finger joint tracking across 194 tabletop tasks, captured with Apple Vision Pro and on-device SLAM. [21] The scale and joint-tracking precision of EgoDex set a new bar for what fine-grained manipulation data looks like — and for what annotation pipelines need to produce to be useful at this level.
EgoScale (NVIDIA, 2026) pretrained a VLA on 20,000+ hours of action-labeled human egocentric video and discovered a log-linear scaling law: each doubling of human egocentric data hours produces a predictable improvement in downstream robot task performance. [22] The average success rate improvement over a no-pretraining baseline was 54% on a 22-DOF robotic hand.
The practical implication for data strategy: these results establish human egocentric data as a first-class training input, not a fallback. The question is no longer whether human data transfers — it is how much, and what quality it needs to be.
Egocentric vs. Third-Person vs. Simulation vs. State-Based Datasets
| Dataset type | Collection difficulty | Per-joint hand pose | Sensor alignment | Manipulation suitability | Real-world transfer |
|---|---|---|---|---|---|
| Egocentric (head-mounted, human) | Medium | Varies | Low–medium | Low–medium | Poor without camera matching |
| Egocentric (wrist/robot-native) | High | Possible | High | High | High |
| Third-person teleoperation | Medium | Medium | Low | Medium | Medium |
| Simulation-generated | Low | High | Configurable | Medium–high | Depends on sim fidelity |
| State-based (proprioception only) | Low | N/A | N/A | Low for novel objects | High in controlled settings |
Robot-native egocentric — data captured from a sensor mounted at or near the robot's end-effector position — is the highest-value input for manipulation policy training. It is also the hardest to collect at scale, which is why the gap exists. Simulation fills volume but requires accurate environment geometry and object models to close the sim-to-real gap. Use synthetic data to expand scenario coverage; use real egocentric capture as the distribution anchor.
What Does "Robot-Ready" Egocentric Data Actually Require?
Five properties separate data that will train a manipulation policy from data that just looks like the right thing. Two are hardware decisions made before the first recording session. Three are data design decisions that determine what you actually capture and label.
The hardware decisions: the training camera FOV must match the robot's onboard camera — a 15° mismatch changes the apparent size and position of grasped objects enough to matter for precise manipulation. And RGB frames alone are insufficient — footage synchronized with IMU, depth, and skeleton data gives the policy temporal context it cannot recover from video alone.
The data design decisions are where most teams underinvest.
The Annotation Gap: Per-Joint Pose and Contact Points
Bounding boxes tell a policy a hand is present. Per-joint keypoints tell it which fingers are flexed, what the grip aperture is, how the wrist is oriented at grasp closure — the configuration the policy needs to replicate. Policies trained on per-joint data generalize better to novel object shapes; policies trained on bounding boxes do not. [6]
Contact point annotations go one level deeper: which part of the hand is touching which part of the object, at what moment in the grasp sequence. This is not standard in any public egocentric dataset at production quality — and it is not yet standard in most commercial annotation pipelines either, including ours; we are currently in testing. It is also where the gap between "egocentric footage" and "robot-ready egocentric data" is widest — and the hardest property to retrofit onto a dataset collected without it.
Imitation Learning: From Basic Concepts to Advanced Implementation
Learn more
Scenario Structure Determines Whether Your Data Covers the Hard Cases
Unstructured "natural activity" footage clusters around common actions and produces almost nothing of the edge cases your policy will fail on. [7] Systematic variation across object types, approach angles, surface heights, lighting conditions, and — critically — failure and recovery sequences does not happen organically. It has to be designed.
We build scripted scenarios specifically to cover failure modes first. Our current scenario base has 12,000 scripted scenarios — a designed library that will expand, each scenario built to answer a specific question about how a policy should behave, not to capture "realistic" activity.
How Is Our Collection Pipeline Built, and Why in Stages?
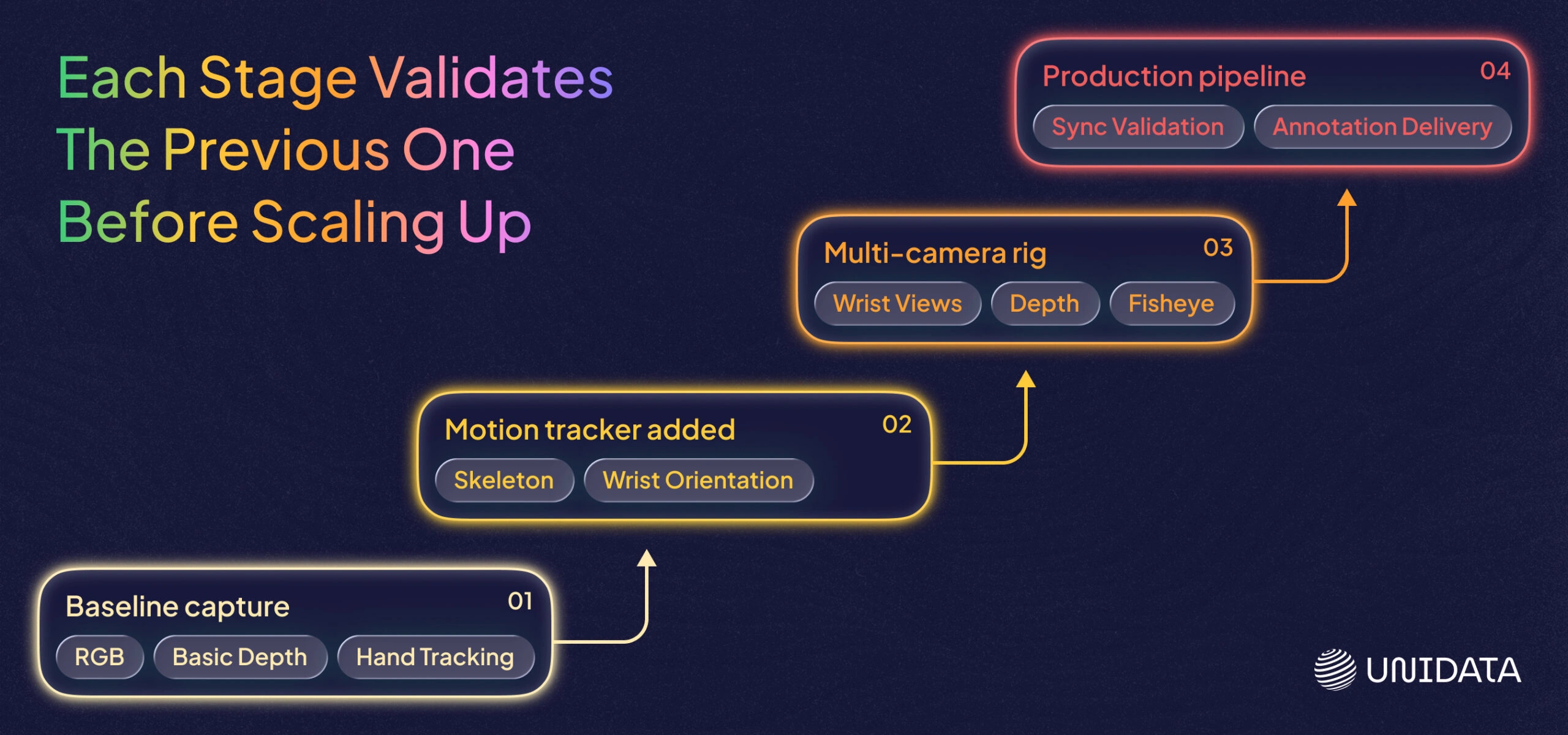
We built the pipeline in stages because starting with the full rig is how you spend six months debugging hardware before collecting any useful data. [8] Each stage runs in production before the next is added — every layer is validated against real manipulation learning outcomes, not hardware specs.
Baseline Capture with VR Headsets: What It Gives You and Where It Stops
The entry point for most projects: a Pico 4 Ultra passthrough VR headset. The Pico 4 Ultra's built-in cameras provide first-person RGB video and basic stereo depth at close range, with on-device hand tracking available as an additional signal. [9]
Where it stops: hand pose tracking from on-device cameras degrades when hands are occluded by objects, and depth quality is insufficient for precise object localization. The FOV does not match most robot wrist cameras. In practice we get 3–4 hours of usable content per operator per working day before session quality drops — headset weight and scripted scenario demands accumulate, and fatigue remains the most honest source of low-quality segments in baseline capture.
Use baseline capture to build your first scenario library, test annotation workflows, and validate that your scripting produces the variance you need. Do not use it as the primary source for a wrist-camera manipulation policy.
Adding a Motion Tracker: What Changes and What Constraints Remain
The main addition is wrist and elbow orientation data throughout the full manipulation sequence — not just at keyframes. We use the Pico motion tracker alongside the headset. [10] You get full-body skeleton capture at joint level, plus velocity and acceleration signals that encode the dynamics of the grasp, not just its endpoint.
What published research shows: a policy trained on skeleton-plus-video input achieves better wrist orientation estimates during occluded phases than one trained on video alone. The motion tracker fills in temporal context between frames that video cannot provide on its own. The constraint it does not solve is finger-level occlusion — that is covered in the Challenges section.
Multi-Camera Rig: Matching Robot Sensor Geometry

The next stage in our pipeline is the ZED — a multi-camera configuration we are currently developing as an addition to the Pico + Motion Tracker setup. The ZED adds three cameras from Stereolabs to the existing headset: a ZED X Mini stereo camera on the head for depth perception, a ZED X One S Fisheye on the head for panoramic coverage, and a ZED X One S on each wrist — all managed by a ZED Box embedded computer that records and synchronizes the streams.
Fisheye at head level (204° H × 137° V) captures the full hand-workspace geometry from the operator's perspective — the approach trajectory, object position, and hand entry are all visible within a single wide frame. The extreme field of view is not accidental: many robot prototypes use fisheye optics for exactly this reason, and matching that geometry at training time is the point.
Wrist cameras place the lens close to the object during grasp — the same working distance and perspective as a wrist-mounted end-effector camera. The distribution gap narrows to hardware-to-hardware differences between our capture rig and the robot's specific sensor, rather than a fundamental perspective mismatch.
ZED X Mini stereo provides depth from 0.1 to 8 m at the head position, giving the capture rig a structured understanding of the workspace geometry that complements the egocentric video.
The trade-off: rig complexity increases significantly compared to baseline Pico capture. [11] The ZED Box needs to be carried or mounted, cables connect to each camera, and integration requires careful calibration. We are building toward this setup incrementally — not deploying it on all projects from the start.
Hardware Options for Egocentric Collection
| Device | FOV | Weight | Pose data | Best for | Approx. cost |
|---|---|---|---|---|---|
| GoPro Hero 12 (head mount) | 155° wide | ~135 g | None native | Low-friction scenario prototyping | ~$400 |
| Pico 4 Ultra | ~105° per eye | 580 g | Hand tracking (on-device) | Stereo baseline, passthrough recording, hand pose | ~$700 |
| Pico motion tracker (body) | N/A | ~100 g per unit | Full-body skeleton | Skeleton-synchronized capture with Pico | ~$300 |
| Meta Ray-Ban smart glasses | ~60° | ~50 g | None | Lightweight naturalistic scenarios | ~$300 |
| Project Aria (Meta, research) | Wide multimodal | ~75 g | Eye tracking, IMU | Research-grade perception research | Not commercially sold [3] |
| ZED X One S Fisheye (head/wrist) | 204° H × 218° D | 36 g | IMU 200 Hz | Fisheye capture, wrist-view data collection | ~€478 |
| ZED X Mini stereo (head) | 110° H × 120° D | 150 g | Stereo depth + IMU + skeleton | Depth 0.1–8 m, 3D workspace geometry | ~€549 |
Smart glasses (Ray-Ban, Aria) are the form factor to watch for naturalistic egocentric capture at scale — low weight, minimal operator fatigue, increasingly capable sensors. [12] They do not yet match the data quality of a multi-camera rig for precision manipulation, but the gap is closing.
How Do We Annotate Egocentric Data for Manipulation — and Synchronize the Streams?
Annotation and synchronization are where most egocentric pipelines lose quality without realizing it. The hardware gets the footage. These two steps determine whether that footage is actually trainable.
Why Manipulation Annotation Differs from Action Recognition
Standard action recognition labeling produces segment-level labels: "start time, end time, action class." That is sufficient for classifying what happened. It is not sufficient for training a manipulation policy.
What a manipulation annotation schema needs at minimum:
- Temporal segmentation at sub-action granularity: reach, pre-grasp shape, contact, lift, transport, release — each as a labeled segment with precise boundaries
- Per-joint hand pose at key frames: especially at contact onset and grasp close
- Object state changes: before and after contact — is the object picked up, repositioned, or released?
- Failure flags: segments where the intended action was not completed, and why
This annotation depth is where most in-house pipelines run into trouble — and where the gap between "ideal manipulation schema" and "what is actually delivered" tends to widen project by project. What we deliver today with Pico + Motion Tracker capture is temporal action segmentation: timestamps for the start and end of each action segment, labeled by action name using a templated naming structure. This is the foundation layer. The richer schema elements — per-joint hand pose, contact type, failure flags — represent the direction annotation pipelines evolve toward as capture hardware and client requirements mature. The schema complexity is consistently underestimated at the start of projects; annotation rules tend to grow in scope as real data surfaces edge cases. [7]
What Multimodal Signals Matter — and How Do You Synchronize Them?
Synchronization is harder than most teams expect. A 50-millisecond offset between RGB and IMU is invisible in the raw data and catastrophic in policy training — in training, it corrupts the signal: the spatial context and the motion signal describe different moments.
Signals and their sync tolerances:
- RGB (wrist + fisheye): the primary observation input; must be the reference clock all other streams align to
- Depth map: object localization and contact distance; synchronized within 1 frame of RGB
- IMU (wrist): wrist velocity and acceleration; fills in the action signal during occluded grasp phases
- Full-body skeleton: end-effector trajectory context; synced to within 20 ms
Practical approach: hardware-triggered capture where possible; software sync with NTP + hardware timestamps where not. Per-stream timestamp drift is one of the harder quality issues to catch after the fact — multimodal dataset delivery with per-session sync validation is the standard we are building toward as our capture pipeline scales.
[Wrist RGB] ──────────┐
[Fisheye RGB] ─────────┤── Reference clock (hardware trigger)
[Depth map] ──────────┤── Sync within 1 frame
[Wrist IMU] ──────────┤── Sync within 20ms
[Body skeleton] ──────┤── Sync within 20ms
3D Environment Scanning and Egocentric Data for Simulation
If your simulation geometry does not match the real environment where your egocentric data was captured, you have a distribution gap problem inside your own pipeline — separate from the sensor mismatch problem described above. We offer 3D environment scanning as a service alongside egocentric data collection: using the XGrids PortalCam (a 3D Gaussian Splatting system), we can scan the capture environment and deliver the geometry alongside the footage, so the simulation your team builds shares the same spatial structure as the real workspace.
Why Does Robot Simulation Quality Depend on Real-World Scan Data?
A simulation environment built from a LiDAR scan of the real workspace has the right shelf heights, surface angles, and occlusion geometry. [12] The policy trained there starts from a matched initial distribution rather than a generic scene, which concentrates the remaining sim-to-real problem on object dynamics and material properties — a much narrower target.
Synthetic data complements real egocentric data rather than replacing it. [13] The combination that practitioners describe: real egocentric capture covers the long tail of object interactions and human motion variation; simulation built from real scans handles high-volume RL exploration in a controlled environment. Neither does the other's job well. We provide the real scan data that makes this combination possible — building simulation environments from that data is the client's domain.
What Does 3D Environment Scanning Produce — and Where Object Quality Still Falls Short?
A scan-to-sim pipeline for a dark kitchen automation client — a fully operational commercial kitchen running delivery-only food service — is our most advanced active engagement in this area. The project is in early stages; our observations here are based on scanning work done to date and the technical characteristics of the equipment, not a completed delivery.
What 3DGS scanning produces well: room geometry, fixed equipment surfaces, shelf layouts, counter positions. The spatial fidelity for static environments is high enough that simulation environments built from these scans should faithfully represent the real workspace geometry — concentrating the remaining sim-to-real problem on object dynamics and material properties rather than scene structure.
Where current limits are honest: 3D object scan quality is still a work in progress. Small, shiny, or transparent objects — exactly the things manipulation policies struggle with — produce incomplete or noisy meshes from current 3DGS capture. Cups, bottles, packaging with reflective surfaces: the point cloud has gaps that require manual cleanup or replacement with CAD models. Manual mesh cleanup is a service we can provide, though it adds time and the result is not always a photorealistic match to the physical object. This is a current technical limitation across the 3D scanning industry, not a solved problem we are downplaying.
Challenges in Egocentric Data Collection
Three challenges come up in every production egocentric project: hand occlusion, operator fatigue, and privacy. Each has real solutions — none of them is "just use more data."
How Does Hand Occlusion Affect Tracking Quality — and What Are the Workarounds?

Occlusion degrades hand pose tracking quality because the fingers disappear from the camera exactly when their configuration is most informative — at contact and grasp closure. [14]
Three practical mitigations, in order of effectiveness:
- Multi-camera angles. Bilateral wrist cameras capture grip configuration from two sides; even when the palm occludes one camera, the other often sees finger position. This is the most reliable fix, at the cost of rig complexity.
- Pose prior interpolation with quality flagging. Tracking models fill in occluded joints using learned pose priors — this is better than nothing, but the filled estimates should be flagged as low-confidence rather than delivered as clean data. Building this flagging into the annotation pipeline is a quality standard we are working toward.
- Scenario redesign based on location. Before capture begins, we review the physical environment and scenario set for configurations where occlusion is likely to be severe — different approach angles or grip types can often achieve the same manipulation task with significantly less occlusion. This review is practical rather than algorithmic: it is based on reading the space.
What does not work: trying to track through occlusion with better algorithms alone. Current state-of-the-art pose estimation still produces visibly wrong estimates during severe occlusion. Acknowledge the constraint; design around it.
How Do You Maintain Data Quality at Scale Without Burning Out Operators?
Fatigue is the most consistent source of degraded footage we see — and the one teams plan for least. The pattern is predictable: the first 45 minutes produce clean, deliberate movements; the last 30 minutes of a long session bring faster shortcuts, sloppy object placement, and missed steps in scripted sequences.
Session design that works in production:
- 3–4 hours of recorded content per working day — not a continuous block, but spread across sessions with rest breaks between them. Operator endurance on feet with the headset on is the primary constraint.
- Scenario rotation — alternating between fine motor tasks and gross motor tasks reduces localized fatigue faster than breaks alone
- Per-session quality review before the operator leaves the capture environment; catches systematic errors (camera drift, tracker disconnections, sync failures) before they compound across a full day
- Operator warm-up sequences — 5 minutes of unscored practice at the start of each session before logging begins; the first-attempt variance is much higher than trained operators on familiar tasks
Beyond operator fatigue, equipment reliability is the other honest source of degraded footage: motion trackers can disconnect mid-session, leaving footage that has video but no skeleton data. Building in per-session equipment checks before and after each block reduces the rate of unusable recordings. Operator incentives also matter. Rushed capture to hit daily footage quotas produces footage that does not pass annotation QC. Tracking usable content volume rather than total recording time surfaces quality problems faster.
What Privacy and Consent Protocols Apply to First-Person Video Collection?
First-person video captures personally identifiable environments — workspaces, faces of colleagues in the background, identifying objects in the scene. This is not hypothetical risk; it is the default output of egocentric capture. [15]
Under GDPR and equivalent frameworks, this footage is biometric data. [16] Three things that should be in every egocentric data collection protocol before capture starts:
- Explicit written consent from operators covering the capture purpose, data use, storage, and retention period. This is not implied by employment. The footage contains biometric data (motion patterns, possibly voice and face).
- Environment consent. If the capture environment is a workplace, all people who may incidentally appear on camera need to be informed and consent obtained. In a fully controlled studio environment this is manageable; in a real kitchen or warehouse, it requires advance coordination.
- Environment preparation before capture. Rather than anonymizing footage after the fact, we prepare the capture environment before recording begins: removing photographs, identifying documents, personal items, and other attributes that could reveal individuals' identities. This approach prevents most privacy issues from entering the footage in the first place, which is simpler and more reliable than post-processing blur.
Where Is Egocentric Robotics Data Headed?
The two shifts that will change what "good egocentric data" means over the next 18–24 months: the scale requirements of foundation models, and the missing force signal that video will never capture.
Foundation Models for Embodied AI: Training Data Requirements
Foundation models for embodied AI require diverse, large-scale egocentric data at volumes most teams have not had to plan for yet. [17] RT-2 and its successors demonstrate that policies which generalize across tasks benefit from breadth of training data — not just more examples of the same tasks, but diverse manipulation contexts, varied environments, different object categories. [18]
What that means for data strategy: industry practice for task-specific policies typically involves hundreds to low thousands of demonstration episodes for a single task — sufficient for training a specialized policy. Foundation model training operates at a completely different scale: one large robotics consortium we are aware of planned for 100,000 hours of egocentric video for a single project in 2026. The data scale for foundation models is four to five orders of magnitude larger than per-task corpora.
The economic case for investing in that scale is now empirically grounded. EgoScale's log-linear scaling law means data volume converts directly and predictably into policy performance — the same relationship that justified compute scaling in LLMs now applies to egocentric data for robots. [22] That makes large-scale human egocentric corpora a strategic infrastructure investment, not a research experiment.
We are planning an open dataset release — a publicly available egocentric manipulation corpus with multimodal annotations. The exact scope of scenarios and environments will be shaped by client demand and our collection capabilities across locations; the timing is not committed. The direction is clear: foundation model training at scale needs open egocentric data that no single lab will produce on its own.
Why Are Motor Signals and Gripper Data the Next Frontier?
Video-based egocentric data captures what the hand looks like during manipulation. It does not capture how hard the grasp is, what force is being applied, or whether the grip is on the verge of slipping.
Motor signals encode the force applied during manipulation in a way the camera cannot observe — and capturing them requires dedicated tactile or force-torque hardware that few egocentric pipelines include. [19] For tasks involving deformable objects — food, fabric, compliant packaging — force feedback is not optional; it is the primary signal for determining whether a grasp is working.
One direction we are exploring: integrating a gripper-like end-effector device — shaped similarly to a robot gripper rather than a human hand — equipped with a camera and motor sensors that record force data during manipulation. The device would allow an operator to interact with objects using an end-effector that closely resembles what a robot actually uses, while recording not just what the gripper looks like but what forces it applies. This is a hypothesis at this stage: no device exists yet, implementation would take months at minimum, and the engineering challenges around synchronization and natural grip behavior are substantial. We include it here because it represents the logical next step in closing the gap between human demonstration data and robot-native manipulation data.
Frequently Asked Questions (FAQ)
Egocentric data collection is the capture of video and sensor data from a first-person perspective — typically head-mounted or wrist-mounted cameras that record what a person (or robot) sees while performing tasks. In robotics, it refers specifically to data captured from a viewpoint matching the robot’s onboard camera position, making the training distribution as close as possible to the robot’s deployment perspective.
A robot policy learns to predict actions from the observations it will see at deployment. If the training data was captured from a different perspective — head-mounted versus wrist-mounted, for example — the policy is doing out-of-distribution inference from the first frame. Sensor-matched egocentric data reduces this distribution gap, which is the primary reason policies trained on it generalize better to real hardware than policies trained on third-person or mismatched egocentric footage.
Third-person datasets capture manipulation from an external fixed camera — useful for some perception tasks but missing the hand-object contact geometry that the robot’s own camera will see. Egocentric data captures the workspace from approximately the robot’s perspective, so the spatial relationship between hand, object, and surface matches what the robot observes. Third-person footage also tends to have better background visibility and worse close-range hand detail — the inverse of what manipulation policy training needs.
Baseline: a head or chest-mounted camera (GoPro, iPhone, Pico 4 Ultra) captures first-person RGB at low hardware complexity. Intermediate: adding a body motion tracker (Xsens or similar) provides skeleton and wrist orientation data. Advanced: a multi-camera rig with wrist-mounted cameras, a fisheye chest camera, depth sensor, and synchronized IMU array matches robot sensor geometry and captures the signals needed for dexterous manipulation learning. Match the hardware to your policy’s input requirements, not to the most capable setup available.
The main publicly available general-purpose datasets are Ego4D (Meta AI, ~3,670 hours of daily activity), EPIC-Kitchens (100 hours of cooking, with action annotations), and EgoExo4D (synchronized ego-exo video for skilled activities). None were designed for manipulation policy training specifically — they are useful for training perception components but should not be the primary data source for a wrist-camera manipulation policy. For manipulation-focused datasets, EgoDex (Apple, 2025 — 829 hours with 3D finger tracking) and the work behind EgoScale (NVIDIA, 2026 — 20,000+ hours of action-labeled video) represent the current state of the art, though neither is fully publicly released at production scale.
Manipulation annotation requires more granularity than standard action recognition labeling. A usable schema includes: temporal segmentation at sub-action level (reach, pre-grasp, contact, lift, release), per-joint hand pose at key frames, object state changes (picked up, repositioned, released), contact type (pinch, power grasp, precision grip), and failure flags for incomplete attempts. Standard segment-level action labels — “start, end, action class” — are insufficient for training a policy that needs to predict actions at 10–30 Hz.
The sim-to-real gap is the performance drop when a policy trained in simulation is deployed on real hardware. Egocentric data captured in the real deployment environment — especially when the environment is also 3D-scanned for simulation import — reduces the gap by providing both a real-distribution training signal and accurate scene geometry for simulation. Policies that fail in sim-to-real transfer are often missing real-distribution data for the specific workspace geometry and object types they will encounter; robot-native egocentric data fills that gap directly.
The three that appear in every production project: hand occlusion degrades per-joint tracking quality at the moments of grasp and contact; operator fatigue over long sessions produces lower-quality movements that bias the training distribution; and privacy compliance for first-person video requires consent protocols and anonymization that most teams underplan for. Each has mitigations — multi-camera rigs, structured session design, and built-in anonymization pipelines — but none of them resolves the underlying constraint completely.
Wrist and hand pose tracking in egocentric setups typically combines camera-based keypoint detection with IMU data from wrist sensors. Camera models (MediaPipe, model-specific variants) detect 21-point hand skeletons per frame; IMU fills in the wrist orientation during occluded phases. The primary failure mode is occlusion during grasp closure — when the hand wraps around an object, fingers disappear from view and the model falls back on pose priors. Multi-camera setups reduce occlusion by capturing grip geometry from multiple angles simultaneously.
Robot-native egocentric data is footage captured from a sensor mounted at or near the robot’s end-effector position — replicating as precisely as possible the observation the robot will receive at deployment. It differs from human-worn egocentric data in that the camera position, field of view, and mounting angle are deliberately matched to the robot’s hardware rather than optimized for human comfort. It is the highest-value data type for manipulation policy training and the hardest to collect at scale.
Three practices that preserve quality at scale: structured scenario scripting (not open-ended capture) so annotation ground truth is known and coverage is deliberate; session length limits with per-session quality review before data leaves the capture environment; and usable-minutes-per-hour as the primary production metric rather than total footage volume. High-volume capture without these controls produces datasets where 30–40% of footage fails annotation QC — a slower way to reach your target dataset size than controlled capture from the start.
First-person video is biometric data under GDPR and equivalent frameworks. The minimum required: written consent from operators covering capture purpose and retention, environment consent from others who may appear on camera, and face/background anonymization before the dataset leaves the collection facility. Most robot training data workflows have not developed formal governance for this — treat it as a compliance gap to close before scale, not a detail to handle later. Once footage is captured and distributed without proper consent records, there is no retroactive fix.
Further Reading & References:
- [1] Grauman, K., et al. "Ego4D: Around the World in 3,000 Hours of Egocentric Video" — CVPR — 2022
- [2] Grauman, K., et al. "EgoExo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives" — CVPR — 2024
- [3] Meta AI. "Project Aria: A New Tool for Egocentric Multi-Modal AI Research" — Meta AI — 2021
- [4] Damen, D., et al. "Scaling Egocentric Vision: The EPIC-Kitchens Dataset" — ECCV — 2018
- [5] Argall, B. D., et al. "A Survey of Robot Learning from Demonstration" — Robotics and Autonomous Systems — 2009
- [6] Hadjivelichkov, D., et al. "Point Policy: Unifying Observations and Actions with Key Points for Robot Manipulation" — arXiv — 2025
- [7] Mandlekar, A., et al. "What Matters in Learning from Offline Human Demonstrations for Robot Manipulation" — CoRL — 2021
- [8] Khazatsky, A., et al. "DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset" — RSS — 2024
- [9] PICO. "PICO 4 Ultra Technical Specifications" — PICO — 2024
- [10] PICO. "Pico Motion Tracker" — PICO — 2024
- [11] Meta. "Ray-Ban Meta Smart Glasses" — Meta — 2024
- [12] Li, H., et al. "INDOOR-LiDAR: Bridging Simulation and Reality for Robot-Centric 360° Indoor LiDAR Perception" — arXiv — 2025
- [13] Tobin, J., et al. "Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World" — IROS — 2017
- [14] Lugaresi, C., et al. "MediaPipe: A Framework for Building Perception Pipelines" — CVPR Workshop — 2019
- [15] Grauman, K., et al. "Ego4D: Data Ethics and Privacy" — Meta AI / Ego4D Documentation — 2022
- [16] European Commission. "Regulation (EU) 2016/679 (GDPR)" — Official Journal of the European Union — 2016
- [17] Zitkovich, B., et al. "RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control" — CoRL — 2023
- [18] Black, K., et al. "π0: A Vision-Language-Action Flow Model for General Robot Control" — Physical Intelligence — 2024
- [19] Chen, Z., et al. "Training Tactile Sensors to Learn Force Sensing from Each Other" — Nature Communications — 2026
- [20] Kareer, S., et al. "EgoMimic: Scaling Imitation Learning via Egocentric Video" — CoRL — 2024
- [21] Xu, R., et al. "EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video" — Apple Research — 2025
- [22] NVIDIA Research. "EgoScale: Scaling Egocentric Human Video for Robot Dexterity" — 2026








