
Trying to train a model when your data lives in ten systems is like cooking dinner while each ingredient sits in a different fridge across town. You can still eat, but you waste time, and the taste changes every time.
Data integration fixes that. It brings data together, lines it up, and makes it consistent. That consistency is what lets ML teams ship models that behave the same in training and in production.
This guide explains what data integration means for ML, the main patterns (ETL, ELT, batch, streaming), the tools teams use, the problems that break pipelines, and a simple blueprint you can reuse.
What Data Integration Means in an AI Project

Data integration is the process of combining data from many sources into a unified format for use in analytics and operations.
In machine learning, “unified” does not mean “one database.” It means you can trust joins, meanings, and transformations. Your model should see the same “customer,” “order,” or “session” no matter where the data came from.
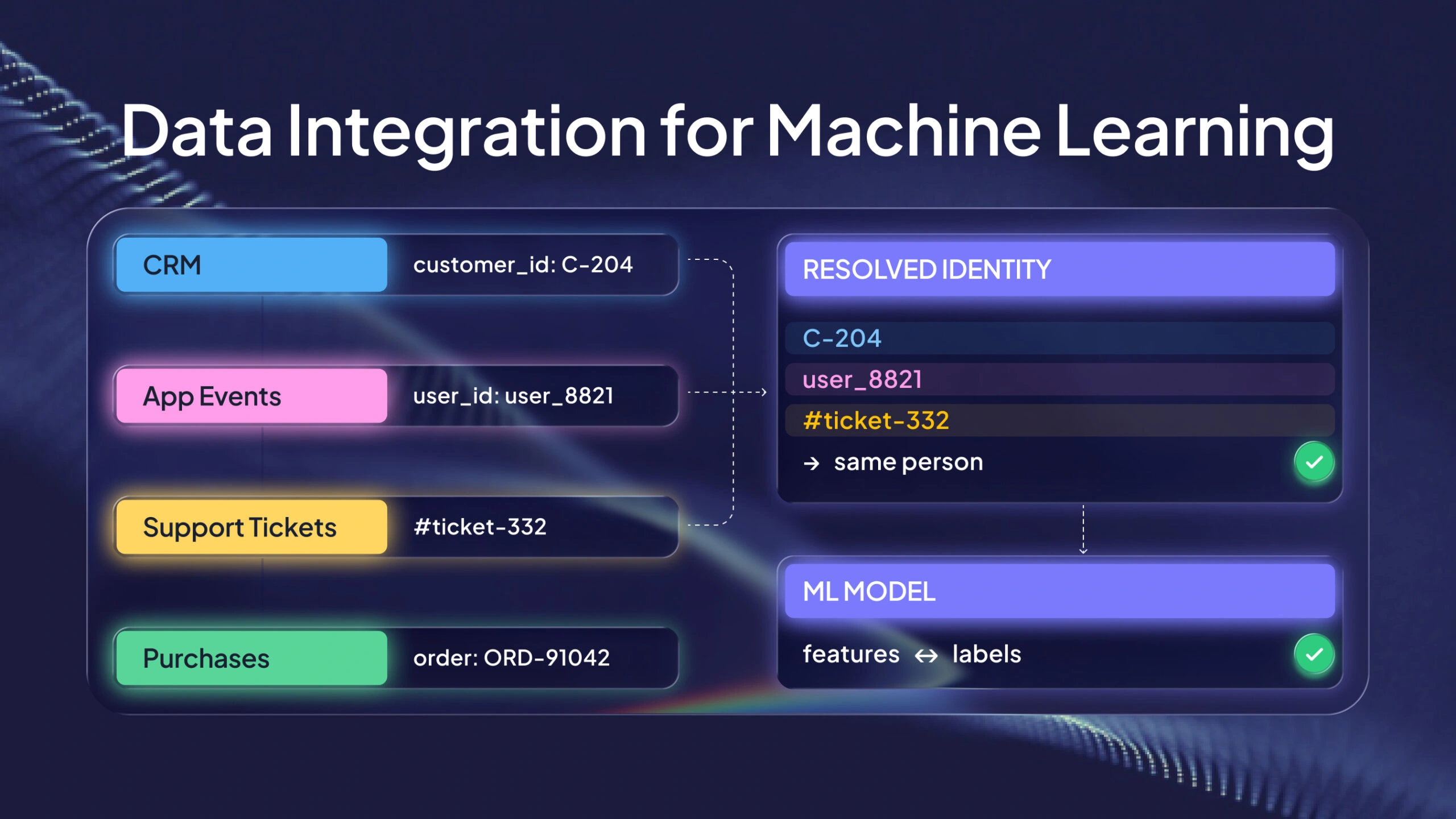
A common case is linking a CRM customer ID with app events, purchases, and support tickets. If those records do not match cleanly, your features describe one person and your label describes another. The model learns noise, not signal.
Data integration also includes the day-to-day work that turns raw inputs into datasets that pipelines can use:
- Extract data from each source system.
- Transform it into a shared schema and shared definitions.
- Load it into a target store where other jobs can read it.
That target store might be a data lake, a warehouse, a lakehouse, a feature store, or several of these. The point is simple: downstream users know where the data is and what it means.
Why Data Integration Matters for ML
Most “model bugs” start upstream. If your input data is missing, late, or inconsistent, the model cannot fix it. A fancier architecture will not repair broken joins or shifting definitions.
Good integration helps in three practical ways.
Better model quality. When you join more of the real picture, you reduce blind spots. Your training set becomes closer to what the model will face in production. That makes evaluation more honest and reduces nasty surprises.
More stable production behavior. Training and inference must compute features the same way. If training uses one definition and production uses another, your model runs on different inputs than you tested. That often looks like “drift,” but it can be a pipeline mismatch.
Faster iteration. When datasets and transformations are reusable, each new experiment starts with a stable base. Your team spends less time rebuilding the same joins and filters.
Two widely cited points show where the space is heading and why compute choices matter.
| Figure | What it refers to | Why you care |
|---|---|---|
| 2027 and 60% | Gartner states that by 2027, AI assistants and AI-enhanced workflows within data integration tools will reduce manual effort by 60%. Gartner | Automation helps most when you already have clear rules, owners, and shared definitions. |
| Up to 100× | Spark’s processing speeds are reported as up to 100× faster than MapReduce for smaller workloads. IBM | Faster processing can turn “overnight rebuilds” into jobs you can run during a workday. |
The Integration Patterns You Will Actually Use
There is no single “right” approach. Most teams mix patterns. They use batch pipelines for stable training sets and add incremental updates when they need fresher signals. Some also build a separate path for unstructured data.
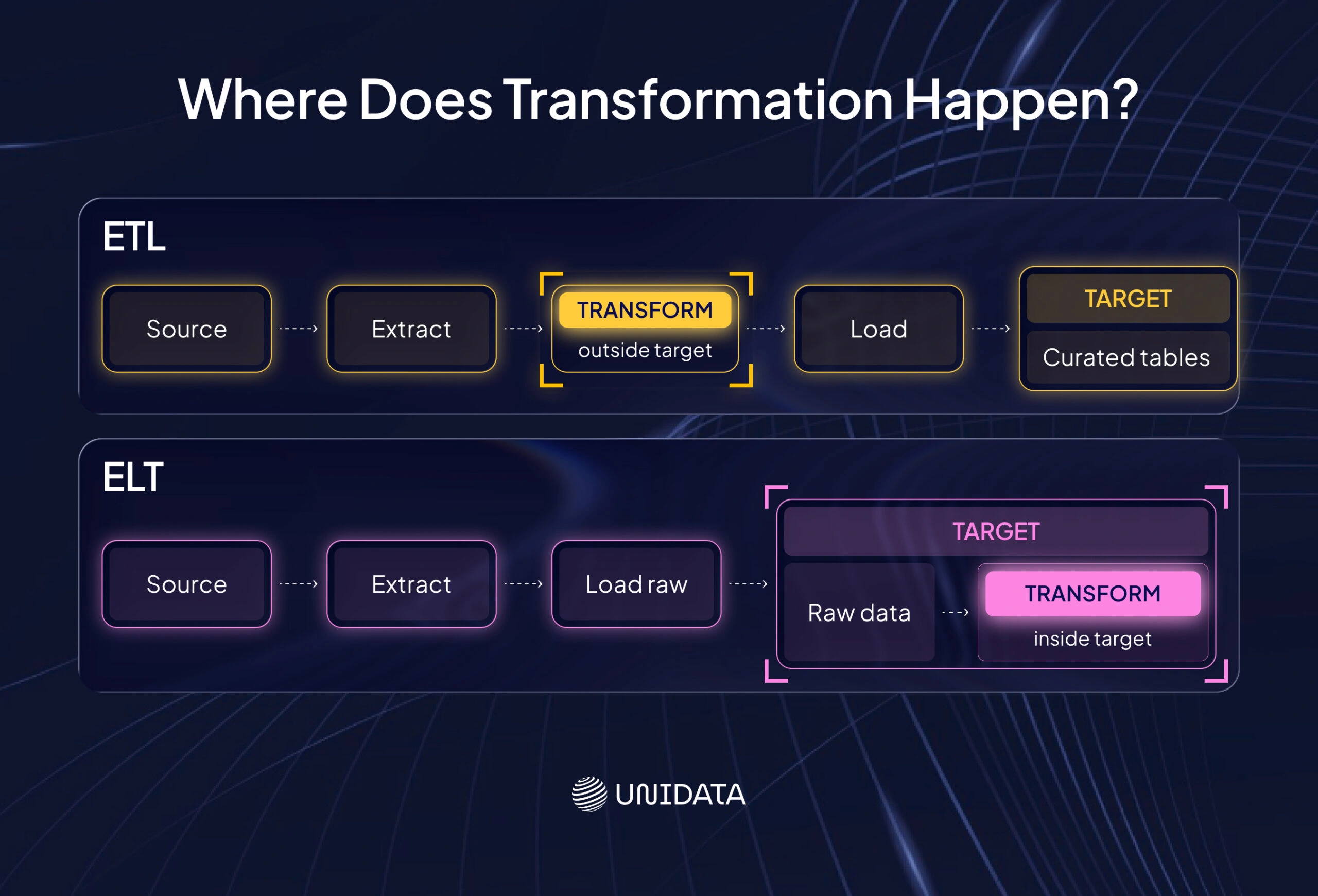
ETL: transform before you load
ETL means extract, transform, load. You pull data from sources, transform it in a processing layer, then load a curated result into the target system.
ETL works well when you want tight control over transforms and stable outputs. It is also easier to audit. You can trace what came in, what rules ran, and what ended up in the curated tables.
The trade-off is speed of change. If every new feature needs a new curated table and a full rebuild, iteration slows down.
ELT: load raw, then transform in the target
ELT means extract, load, transform. You load raw data into the target first, then run transformations inside that system. In ELT, the destination owns the most compute. IBM
ELT fits cloud warehouses and lakehouse platforms well. It can speed up experimentation because raw data stays available. You can add new transforms without re-extracting from the source.
The main risk is disorder. If every team writes its own “truth” in SQL, you end up with conflicting definitions. ELT needs shared transformation rules and basic governance.
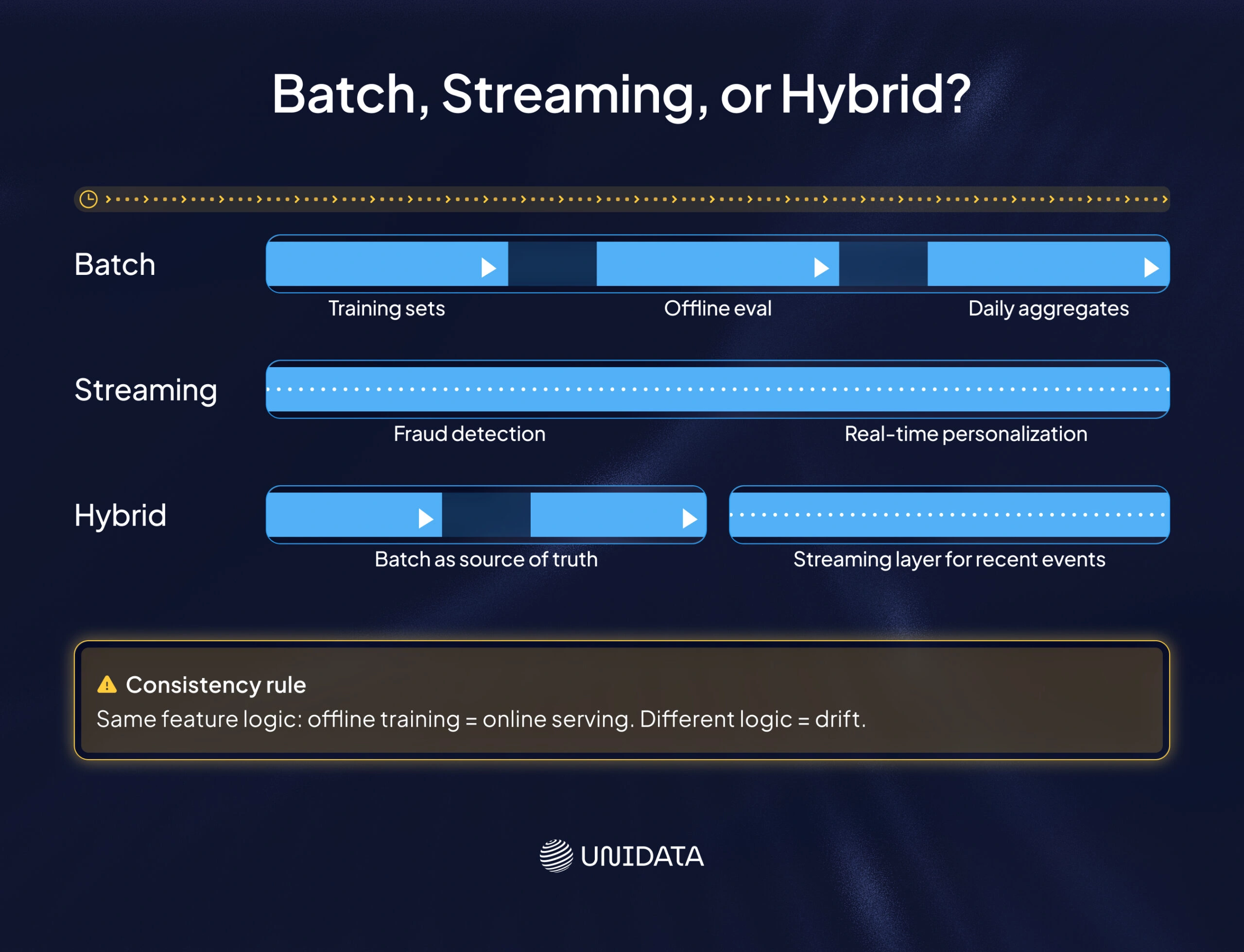
Batch integration: build in chunks on a schedule
Batch integration processes data in chunks, often on a set schedule. For many ML workflows, batch is enough:
- Training datasets.
- Offline evaluation.
- Feature backfills.
- Daily or hourly aggregates.
Batch is also easier to debug. When a job fails, you know the exact input window. You can rerun it and compare outputs.
Streaming integration: process events as they arrive
Streaming integration handles events continuously. It matters when latency changes decisions. Common examples include fraud detection, near-real-time personalization, and IoT monitoring.
Streaming adds complexity you must plan for:
- Events can arrive late or out of order.
- Duplicates happen.
- Schemas evolve.
- Backpressure can slow consumers.
If you do not need these properties, batch or micro-batch is often the calmer choice.
Hybrid pipelines: common in production
Many teams run hybrid pipelines. They keep batch as the “source of truth” for training and reporting, then add a streaming path for recent events.
The big rule is consistency. If you compute the same feature two different ways (offline and online), you will get drift between training and serving. That makes incidents harder to explain and fixes harder to validate.
A Simple Example: the Same Loop in Batch and Streaming
A small Spark batch job shows the integration loop clearly: read raw data, apply transforms, then write a standard output.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("ETLJob").getOrCreate()
# Extract: read raw data (batch)
df = spark.read.csv("s3://my-bucket/raw/data.csv", header=True)
# Transform: filter and aggregate
clean_df = (
df.filter(df["status"] == "active")
.groupBy("category")
.count()
)
# Load: write integrated output (batch)
clean_df.write.mode("overwrite").parquet("s3://my-bucket/processed/summary.parquet")
If you move this to streaming, the steps look similar, but the guarantees change. You read from an event stream, keep state for aggregates, and push updates to a serving store. The hard part is not the transform code. The hard part is correctness over time: late arrivals, duplicates, and schema versions.
This is why streaming should be a business decision, not a style choice.
Tools and Frameworks for ML-ready Integration
Integration is rarely a single product. It is a stack. You need ingestion, compute, orchestration, transformations, quality checks, and storage. What matters is clear ownership of each layer.
Orchestration and scheduling
Orchestrators manage task order, retries, schedules, and run history. Apache Airflow models workflows as DAGs: tasks with clear dependencies that run on a schedule. Apache Airflow
In ML projects, this helps because integration is a chain. You ingest data, validate it, transform it, publish curated outputs, and sometimes backfill older windows. Orchestration makes that chain visible and repeatable.
Distributed processing and transformation
When data volume grows, you often need distributed compute for joins, aggregates, and feature calculations. Spark is a common choice for large batch transforms.
The key question is practical. Do your jobs finish fast enough to support iteration? If a feature pipeline takes twelve hours, you cannot test changes quickly.
Streaming and event infrastructure
Streaming stacks are built around event logs and consumers. Kafka is a common pattern: producers write events, consumers read them, and the log stays as a durable record.
Use streaming when “freshness” changes the action you take. If the action can wait, do not pay the streaming tax.
Managed integration services
Cloud providers offer managed services that handle connectors, scaling, and scheduling. Examples include AWS Glue and Azure Data Factory.
Managed services reduce ops work, but they do not solve definition drift. You still need shared schemas and shared transformation logic.
Data quality checks
Data quality is part of integration, not a separate phase. Frameworks like Great Expectations let you validate data against explicit expectations.
Even basic checks catch many failures:
- Schema checks and type checks.
- Null limits on key columns.
- Uniqueness rules for identifiers.
- Range checks for critical numeric fields.
The goal is to fail early and explain the failure clearly.
A simple way to think about the stack
It helps to group tools by responsibility instead of vendor.
| Layer | What it owns | Typical examples |
|---|---|---|
| Ingestion | Pulling data from sources reliably | connectors, CDC, batch exports |
| Storage | Keeping raw and curated data accessible | data lake, warehouse, lakehouse |
| Transformation | Turning raw data into standard datasets | Spark jobs, SQL models, warehouse transforms |
| Orchestration | Schedules, dependencies, retries, lineage | Airflow, managed schedulers |
| Streaming | Low-latency event delivery and processing | event logs, stream processors |
| Quality and observability | Catching drift and silent failures | validation frameworks, monitoring |
How Integration Needs Change by Industry
The core steps stay the same: ingest, standardize, join, validate, and publish. What changes is the set of constraints that shape your pipeline. In some domains, privacy and traceability matter more than speed. In others, timing and alignment are the hard part.
Healthcare
Healthcare data is often split across systems: electronic health records, lab systems, wearables, and patient apps. Integration has to respect privacy rules and access control. It also needs careful identity management, because the same person can appear under different identifiers in different systems.
For ML, “one dataset” is rarely enough. Clinical pipelines often need strict provenance, so you can trace where each field came from and how it was transformed. They also tend to use conservative transforms, because small definition changes can alter downstream meaning. Operations models often work with aggregated or de-identified signals, where the goal is pattern detection without exposing sensitive details.
The practical decision here is not ETL vs ELT first. It is how you will enforce identity, permissions, and traceability across the full pipeline.
Finance
Finance pipelines often join internal transaction data with external feeds. Some use cases are latency-sensitive, such as fraud detection. Many also require strong audit trails.
That mix pushes two requirements. First, you need traceability from model outputs back to source data and transform steps. Second, you need a clear plan for fresh signals versus stable datasets. A common setup splits paths: streaming for time-sensitive features and batch for reconciliation and offline evaluation.
The key decision is whether speed changes the action you take. If it does, streaming earns its place. If it does not, batch keeps the system easier to control and audit.
Manufacturing and IoT
IoT data often arrives as high-volume, time-stamped signals. Integration tends to blend streaming ingestion with time-series storage. It also needs enrichment from maintenance logs and production schedules, because raw sensor values rarely explain themselves.
Alignment is the hardest part. If timestamps, machine IDs, and maintenance events do not line up, models learn the wrong relationships. Predictive maintenance is a classic example of this failure mode. The model looks “smart” in training, then misses real faults because the history was stitched together incorrectly.
In this domain, the main decision is how you handle time and identity at scale, not which storage product you pick.
The Problems That Break Integration for ML

Once you start integrating sources, issues stop being isolated. A small mismatch in one system can distort joins across the pipeline. The good news is that most failures repeat. If you design for them early, you avoid long debugging cycles later.
Data silos and unclear ownership
Silos are often not a connector issue. They are a definition issue. Different teams define the same entity in different ways, and systems store it differently.
Integration needs shared identifiers and shared meaning. It also needs clear owners for key datasets, so someone is responsible for changes, access rules, and downstream impact. Without ownership, pipelines drift into “works for my team” logic, which breaks reuse.
Schema drift and changing sources
Schemas change. Fields appear, types shift, and event payloads evolve. If you do not detect drift, models can start training on different inputs without anyone noticing.
You do not have to block change. You need to control it. Version schemas, validate inputs, and make breaking changes loud. That way, failures happen at the boundary, not weeks later in model behavior.
Latency pressure that the use case does not need
Real-time pipelines are costly to build and run. Many use cases only need “fresh enough.”
A helpful test is simple: does a short delay change the decision you make? If not, batch or micro-batch is often the better tool. It is easier to debug, easier to backfill, and easier to keep consistent with training datasets.
Data quality and consistency problems
When you join sources, you amplify inconsistencies. Duplicates, missing values, and conflicting timestamps become visible because they break joins and shift labels.
In ML, this shows up as unstable training, misleading evaluation, and production drift. Basic validation helps you catch these issues before they reach models. The goal is not perfect data. The goal is predictable data with known constraints.
Security, privacy, and compliance risks
Integration moves and copies data. That increases both security risk and compliance burden. Access control, encryption, and audit logs are baseline needs in sensitive domains.
A useful mindset is to treat integrated datasets as products. Give them owners, access rules, and change control. That keeps “who can use this” and “what changed” from becoming last-minute questions right before a release.
A Blueprint for Scalable Integration in AI Systems
Scalability is not only about volume. It is also about change: more sources, more models, more teams, and more rules. A scalable pipeline makes change safe.

Build a modular pipeline
Split your pipeline into clear stages: ingest raw, validate, transform, and publish curated outputs. Then serve features from a defined store.
Modularity helps you isolate failures and run backfills without rewriting everything. It also makes it easier to add new sources, because ingestion can evolve while downstream contracts stay stable.
Use distributed compute where it removes bottlenecks
Distributed compute matters when joins and feature jobs exceed single-machine limits or when runtimes slow down your team.
The goal is not to adopt a specific engine. The goal is to keep pipeline runtime aligned with your delivery cadence. If data prep takes too long, model work slows down even when the modeling code is fine.
Orchestrate and version the pipeline
ML pipelines have too many moving parts for manual runs. Orchestration gives you schedules, retries, and traceable runs.
Versioning matters because transforms are part of your model input. When a transformation changes, the training data effectively changes too. Treat transform code like product code so changes are reviewable and reversible.
Monitor change, not only crashes
Logs tell you what happened. Monitoring tells you what changed. Change is often the first hint of trouble.
Useful signals include volume spikes, schema changes, null rate jumps, and shifts in feature distributions. You do not need perfect monitoring at the start. You need enough to catch silent failures early, while the root cause is still close.
Design for safe retries
Failures will happen. Pipelines should be able to retry without duplicating outputs or corrupting state.
Idempotent writes, checkpoints, and clear reprocessing rules keep recovery simple. They also make incident response faster, because “rerun safely” becomes a normal operation, not a risky bet.
A simple orchestration skeleton
This Airflow example shows the shape: small tasks with clear dependencies and a daily schedule.
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
"daily_feature_pipeline",
start_date=datetime(2025, 1, 1),
schedule_interval="@daily",
catchup=False,
) as dag:
extract_transactions = BashOperator(
task_id="extract_transactions",
bash_command="python extract_transactions.py",
)
transform_features = BashOperator(
task_id="transform_features",
bash_command="python spark_submit_job.py --job feature_etl.py",
)
load_feature_store = BashOperator(
task_id="load_feature_store",
bash_command="python load_features.py",
)
extract_transactions >> transform_features >> load_feature_store
In production, teams usually add validation, metrics, and versioned outputs. The idea stays the same: define contracts, enforce order, and make failures visible.
LLMs and RAG Add a New Integration Target

Large language models add a new consumer of integrated data: retrieval systems that fetch context at query time. In retrieval-augmented generation (RAG), the system retrieves relevant content and passes it to the model so answers stay grounded.
For integration teams, this adds another pipeline. You ingest unstructured sources, clean and chunk them, then index them. Many systems store embeddings in a vector database for retrieval.
Two implications matter:
- Integration moves closer to serving. If your index is stale, responses will be stale.
- Keeping the index up to date becomes a pipeline job. Streaming can help, but only when the use case needs near-real-time context. Confluent
- The discipline is familiar: ingest, transform, validate, and serve. The inputs are different, but the pipeline rules are the same.
Conclusion: Choose the Simplest Pipeline that Meets the Need
Data integration is not a warm-up step before modeling. It is the system that makes ML repeatable and safe to run.
A practical rule is to match the integration pattern to the real latency need, then keep feature logic consistent between training and production. When the data stops shifting under your feet, debugging becomes faster and model work becomes more predictable.
Frequently Asked Questions (FAQ)
Data integration in machine learning means taking data from many sources and making it work as one dataset. That dataset is what a machine learning model uses for training data and evaluation. Integration usually covers ingestion, joining records with stable IDs, and making schemas match. It also means cleaning obvious breakpoints, like missing keys, mixed time zones, or category names that do not line up. The goal is straightforward: features and labels should describe the same real-world users, orders, or events.
Teams use data integration to build data pipelines that produce ML-ready tables. That often means joining app events with transactions, adding CRM fields to usage logs, or linking tickets to customer profiles. The output becomes a feature table for feature engineering and model training. In production, integration keeps production data aligned with the training data logic. If the pipeline changes the meaning of a feature, you get a mismatch between offline training and online inference.
There is rarely one tool. Data integration for AI is usually a small stack, because each step needs a different strength.
- Apache Airflow: runs and schedules data pipelines.
- Apache Spark: transforms data at scale (joins, aggregates, feature prep).
- Apache Kafka: moves event data for streaming and real-time pipelines.
- AWS Glue / Azure Data Factory: managed connectors and ETL/ELT workflows.
- Great Expectations: data quality checks (schema, nulls, ranges).
Teams choose based on batch vs streaming, and on where data lives (a data lake or data warehouse). If you serve features online, a feature store can sit at the end of the pipeline.
No. ETL is one way to do data integration, but it is not the whole thing. ETL is “extract, transform, load.” Integration can also use ELT, where you load raw data first and transform it in the target system. Integration also includes schema alignment, entity matching, and data quality rules. For ML, it includes one extra requirement: the same feature logic for offline training and online inference. You can run ETL jobs and still have weak integration if IDs do not match or definitions differ across pipelines.








