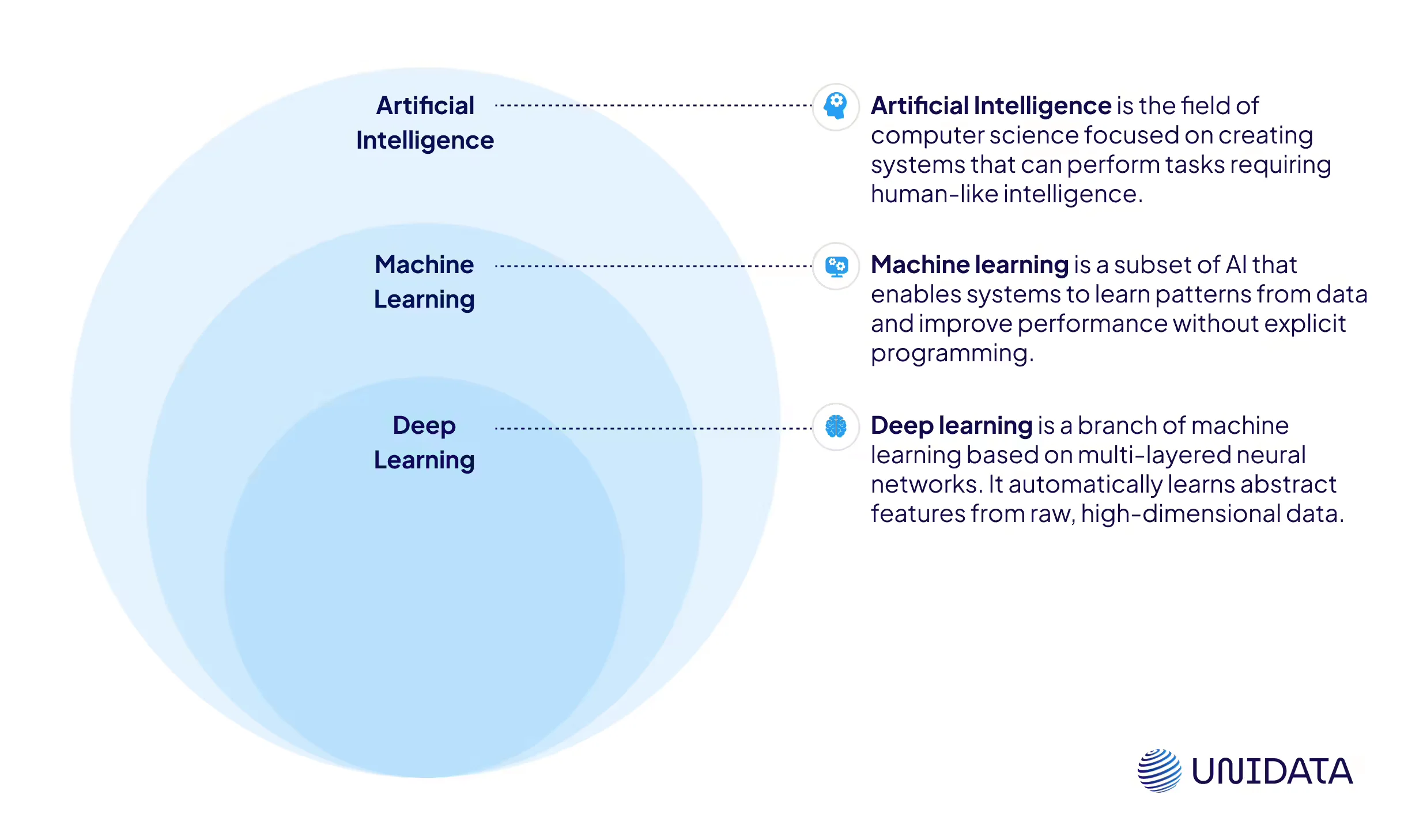
If you’ve read about artificial intelligence, you’ve likely seen the terms machine learning and deep learning used side by side. While they’re closely related, they’re not the same — and knowing the difference can make a real impact in practice.
Machine learning is the broader concept. It includes many kinds of algorithms that learn from data. These models get better as they’re exposed to more examples.
Deep learning is a special kind of machine learning. It uses neural networks with many layers. These models are especially good at complex tasks, like recognizing faces or understanding speech.
In this article, we’ll explain both terms, compare them side by side, and help you decide which one fits your task best.
Key Takeaways
- Training data is the dataset used to teach ML algorithms to recognize patterns — the Unidata team describes it as 'the textbook from which an AI model learns'; in supervised learning it means labeled input-output pairs; in unsupervised learning it's raw data from which the algorithm discovers hidden structures.
- Training data quality determines everything: a Unidata fraud detection project initially reached only 62% accuracy; after auditing, 18% of transactions were found mislabeled with critical features missing — after one month of cleaning and correcting labels (no algorithm change), the same model jumped to 94% accuracy.
- Five quality dimensions are assessed: accuracy (correctness of labels), completeness (no missing values in critical fields), consistency (uniform formats and definitions), relevance (alignment with the actual prediction task), and timeliness (recency for problems where patterns shift over time).
- A medical imaging labeling cost example: 50,000 labeled chest X-rays at $75/hour, 3 minutes per image = $187,500 in labeling costs — more than the entire initial model development budget; semi-supervised learning on 5,000 labeled + 200,000 unlabeled reduced costs by 90% while achieving 92% of fully supervised accuracy.
- The cardinal rule for data splits: test data must remain untouched until final evaluation; the article specifies typical 70/15/15 or 80/10/10 (training/validation/test) splits, k-fold cross-validation for datasets under 1,000 examples, and larger test sets for millions of examples.
- Four learning approaches and their data requirements are tabulated: supervised (large volumes of labeled pairs — highest accuracy for well-defined tasks), unsupervised (unlabeled only — no labeling cost, discovers hidden patterns), semi-supervised (small labeled + large unlabeled — reduces labeling costs), and reinforcement (environment interactions + reward signals — learns through trial and error, no labeled data needed).
Why It Matters
Whether you are building AI solutions or simply exploring what they can do, you will eventually need to decide: should you use machine learning or deep learning? The choice is not always obvious, but it can make or break your project.
That is why understanding the difference is key. It helps you:
- Choose better solutions for your data, goals, and limitations.
- Avoid wasting time and resources on models that are too simple or needlessly complex.
- Build the right team and technical foundation for your needs.
- Plan for growth as your product, data, and use cases evolve.
- Communicate effectively with clients, stakeholders, and technical teams.
What Is Machine Learning?
Imagine you're teaching a child to tell the difference between a cat and a dog. You don’t go into every detail — like “a cat’s ears are more triangular” or “dogs often bark.” Instead, you just show lots of pictures and say, “This is a cat,” “This is a dog.” After seeing enough examples, the child begins to understand. They start picking up on patterns — the shape of the face, the size of the body, the length of the tail.
That kind of learning — not through fixed rules, but through exposure to examples — is essentially how computers learn, too.
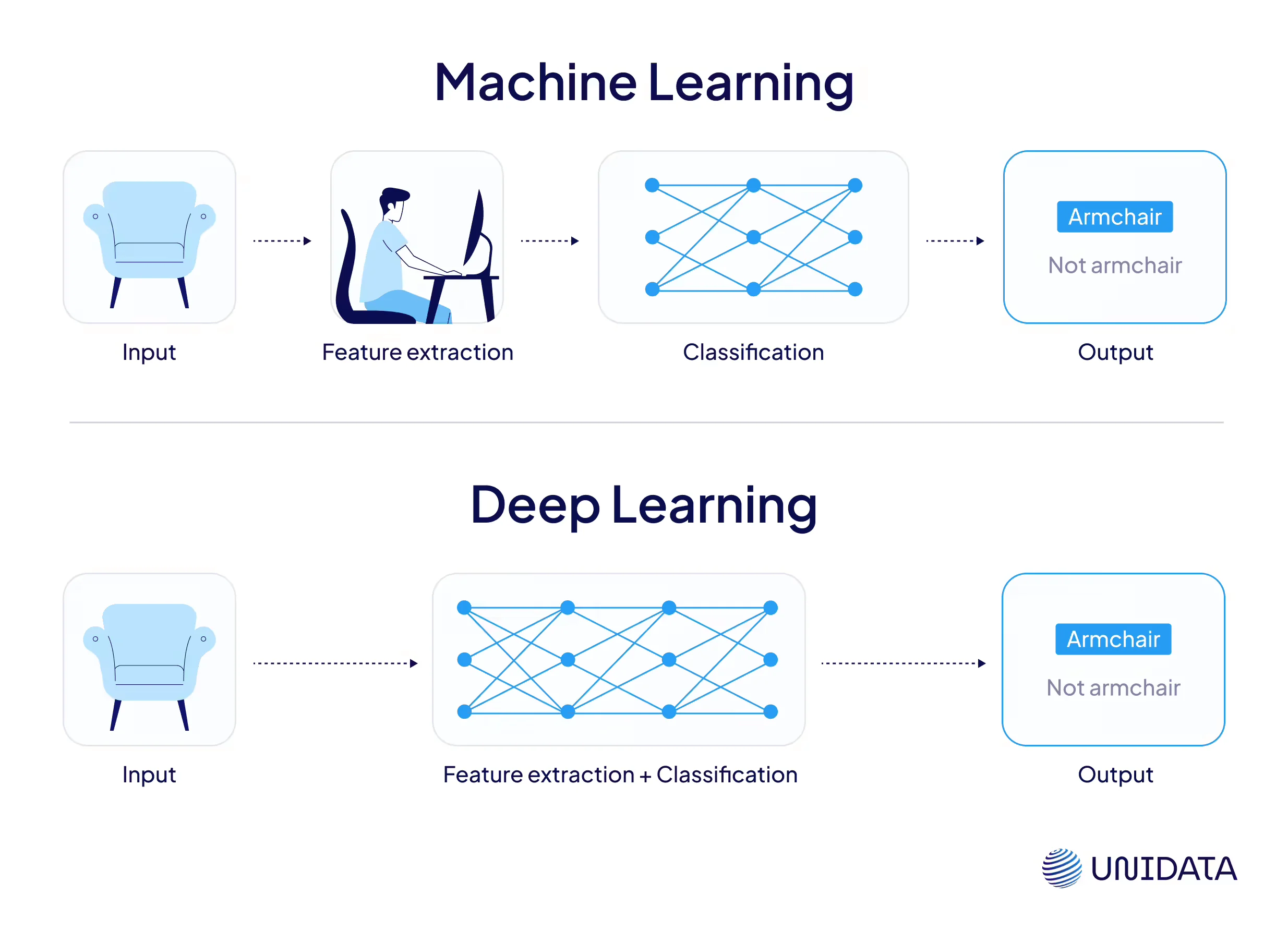
Machine learning, a core part of artificial intelligence (AI), is a method that enables computers to learn from data and gradually improve performance, without being explicitly programmed for each task. Instead of coding a strict set of rules, we provide the model with many examples and let it discover the patterns on its own.
But before a computer can learn, the data needs to be prepared — usually through two key steps: feature engineering and labeling.
In traditional machine learning, people decide which aspects of the data are likely to be useful — a process called feature engineering. Features are measurable properties extracted from raw inputs, like the brightness of an image, the number of words in a sentence, or the average pitch of a sound. Rather than working directly with raw data, the model learns from these simplified, structured signals.
At the same time, we supply the correct answers, known as labels. For example, each image might be tagged as “cat” or “dog.” This approach is called supervised learning, and it’s one of the most widely used forms of machine learning.
With enough labeled examples and well-designed features, the model begins to learn. Over time, it can make predictions on new, unseen data by identifying patterns it has seen before — just like the child in our example.

How Does Machine Learning Work?
Now that we know machine learning lets computers learn from examples instead of hard-coded rules, let’s break down what that process actually looks like — step by step.
Step 1: Collect and Prepare the Data
Everything starts with data. A lot of it. But it's not just about gathering information — the data needs to be relevant, clean, and structured in a way the model can actually interpret.
There are several common ways to source data:
- Buy ready-made datasets from public repositories or commercial providers.
- Collect it internally using your systems, tools, or teams.
- Use crowdsourcing platforms and manage your own data collection workflows with human contributors.
- Generate synthetic data through simulations.
Once the raw data is gathered, it needs to be prepared. This usually involves two essential steps:
- Feature engineering — transforming raw inputs (such as images, text, or numeric values) into meaningful variables that help the model recognize patterns. For example, converting timestamps into time-of-day categories or detecting edges in an image.
- Labeling — when the task involves known outcomes, it's often necessary to assign a correct label to each example. For instance, tagging a product review as either positive or negative.
After that comes preprocessing: handling missing or noisy values, standardizing formats, scaling numerical values, and balancing class distributions to reduce bias.
Finally, the dataset is divided into training and test sets, and often a validation set as well.
Step 2: Choose and Configure a Model
A model is a mathematical system that maps inputs to outputs. The type of model you choose depends on the task — for instance, logistic regression for classification, decision trees for rule-based decisions, or linear regression for capturing linear relationships.
You may also need to tune hyperparameters — settings like maximum tree depth or learning rate that influence how the model learns and adapts during training.
Step 3: Train the Model
This is where learning takes place. The model receives the training data and starts making predictions. Early on, those predictions may be inaccurate or even entirely random.
After each prediction, the model compares its output to the correct answer and measures the difference, a value known as loss. Based on that loss, it updates its internal rules to improve future predictions. This process runs thousands of times, gradually boosting the model’s accuracy.
Some models, like decision trees, refine their structure by splitting data based on the most useful features. Others, like linear models, tweak their coefficients to reduce overall error. The goal is straightforward: minimize the loss and get more accurate with every iteration.
Step 4: Test and Evaluate
Once the model is trained, it’s time to test it on new, unseen data. This reveals how well it generalizes to real-world inputs.
If performance is poor, the model might be underfitting (too simple) or overfitting (too closely tailored to the training set). Evaluation metrics help identify and address these issues.
Step 5: Deploy and Improve
Once your model has been trained and tested, it’s ready to be used in the real world. But as conditions shift, the model may need updates. Retraining it with fresh data helps maintain accuracy over time.
Types of Machine Learning
Machine learning methods can be grouped in different ways. Below are four core types that represent the majority of real-world applications.
| Type | What It Means | Typical Use Cases |
|---|---|---|
| Supervised Learning | The model learns from examples that include both inputs and their correct outputs (labels). It uses these examples to make predictions on new, unseen data | Email spam detection, medical diagnosis, loan approval |
| Unsupervised Learning | The model analyzes unlabeled data to discover hidden patterns or natural groupings — without being told what to look for. It's useful for data exploration and insight discovery | Customer segmentation, topic modeling, anomaly detection |
| Semi-Supervised Learning | This approach combines a small amount of labeled data with a large volume of unlabeled data. It’s helpful when labeling is costly or time-consuming | Sentiment analysis, image classification in healthcare |
| Reinforcement Learning | The model (agent) learns by interacting with an environment, receiving rewards or penalties based on its actions. It doesn’t rely on labeled data and, while similar in some ways to unsupervised learning, it’s a distinct type focused on learning through trial and error over time | Game AI, robotics, autonomous vehicles |
Note: Since deep learning is a subset of machine learning, these types also apply to deep learning models.
What Is Deep Learning?
As machine learning progressed, researchers began to ask a new question: What if models could go beyond using predefined features — and actually learn to create those features themselves?
That idea led to deep learning — a powerful subset of machine learning that allows models to handle more of the work automatically.
Deep learning relies on artificial neural networks — layers of interconnected mathematical units known as “neurons.” These networks are loosely inspired by the human brain, but built entirely from code and mathematics. When the networks grow deep (i.e., contain many layers), they can learn complex patterns directly from raw data — like images, audio, or text — without requiring humans to define what to extract.
Example:
In traditional machine learning, if you wanted to classify animals in images, you’d manually design features like fur texture, ear shape, or color.
In deep learning, you simply feed the model the raw image, and it figures out on its own that ears, eyes, and fur are useful for the task.

How Does Deep Learning Work?
Deep learning is built on the same core principle as traditional machine learning: learning from data. But the process is more demanding — it requires more data, more computing power, and deeper layers of abstraction. Here’s how it works:
Step 1: Collect and Prepare the Data
As with any machine learning approach, everything starts with data, but in deep learning, you typically need far more of it.
Since these models learn directly from raw inputs like images, audio, or text, the dataset needs to be large, varied, and often precisely labeled. For image classification, that might mean manually tagging thousands — or even millions of examples.
Preprocessing still matters, but it’s less about hand-engineering features. Instead, you might resize images, normalize pixel values, or tokenize and vectorize text so it can be processed by the model.
And just like in standard ML, the dataset is typically divided into training, validation, and test sets to support learning and evaluation.
Step 2: Choose and Configure a Neural Network
Instead of selecting from models like decision trees or linear regressors, deep learning begins by choosing a neural network architecture.
You might use a Convolutional Neural Network (CNN) for image data, a Recurrent Neural Network (RNN) for sequential inputs, or a Transformer for language-related tasks.
These architectures also come with hyperparameters — like the number of layers, learning rate, batch size, and activation functions — that shape how the network learns and adapts.
Step 3: Train the Model
This is where deep learning sets itself apart from traditional machine learning.
The raw input passes through multiple layers of artificial neurons. The early layers pick up on simple patterns — like edges — while deeper layers detect more abstract features, such as shapes or objects.
After each prediction, the model compares its output to the correct answer and calculates the error, known as loss. Through backpropagation, it updates the weights — the internal parameters that shape learning — to minimize that error.
This cycle of prediction, error, and adjustment repeats across many training epochs — often millions of examples. The result is a finely tuned, multilayered system that learns directly from raw data.
Step 4: Test and Evaluate
Once training is complete, the model is evaluated on data it has never seen — to assess how well it generalizes.
Deep learning models are especially prone to overfitting on small datasets, so close monitoring on a validation set remains critical.
Typical metrics include accuracy, precision, recall, and loss curves for classification, and Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE) for regression.
Step 5: Deploy and Improve
If the model performs well, it can be deployed in real-world systems — from recommendation engines and diagnostic tools to autonomous vehicles.
As with traditional machine learning, deep learning models can drift as real-world conditions shift. Regular retraining on fresh data helps preserve performance over time.
Types of Deep Learning Models
| Model Type | What It Does | Typical Use Cases |
|---|---|---|
| CNN (Convolutional Neural Network) | Designed for visual data; uses filters to recognize features such as edges, shapes, and textures | Image classification, object detection, medical imaging |
| RNN (Recurrent Neural Network) | Built for sequential inputs; captures context by remembering previous steps to predict what comes next | Speech recognition, time-series forecasting |
| LSTM / GRU (Long Short-Term Memory / Gated Recurrent Unit) | An improved form of RNNs, better equipped to model long-term dependencies in sequences | Chatbots, language modeling, music generation |
| Transformers | Uses attention mechanisms to analyze entire sequences in parallel; well-suited for language understanding and generation | Machine translation, AI chatbots, large language models (e.g., GPT) |
| Autoencoder | Learns to encode input into a compact representation and then reconstruct it — preserving essential features | Anomaly detection, noise removal, dimensionality reduction |
| GANs (Generative Adversarial Networks) | Trains two models — a generator and a discriminator — to generate new, realistic data based on training examples | Image synthesis, deepfakes, data augmentation |
Machine Learning vs. Deep Learning: Key Differences
Machine learning and deep learning both help computers learn from data — but they take different approaches, work best in different situations, and require different levels of resources.
Learning Approach
In machine learning, models typically depend on features that are selected manually. A human expert identifies which aspects of the data are relevant — such as age, weight, or number of clicks — and the algorithm learns to make predictions based on those inputs. Common ML algorithms for classification include decision trees, logistic regression, and random forests. For regression problems, techniques like linear regression and boosting methods are often used. In deep learning, models learn which features matter on their own. Neural networks take in raw data — like images or audio — and uncover meaningful patterns through multiple layers of processing. This ability to extract structure directly from complex, unstructured data makes deep learning especially powerful.
Data Requirements
Machine learning performs well on small to medium-sized datasets, particularly when the data is structured — such as spreadsheets or database tables.
Deep learning, by contrast, typically depends on large amounts of data. The more it receives, the more it improves — especially in tasks like image recognition, speech transcription, or text generation.
Technical Complexity
ML models are generally lighter and faster to train, and they often run efficiently on standard computers.
DL models are more computationally intensive and typically require specialized hardware such as GPUs. Training deep networks can take hours — or even days — depending on the dataset size and network depth.
Interpretability
Machine learning models are generally more transparent. It is often possible to trace how a decision tree or regression model arrived at a specific result.
Deep learning models, by contrast, are often viewed as black boxes. Although they can achieve high accuracy, explaining their decision-making process is challenging, which raises concerns in sensitive fields like healthcare and finance.
| Aspect | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|
| Definition | A field of AI where algorithms learn from data to make decisions or predictions | A subfield of ML that uses multi-layer neural networks to learn directly from raw data |
| Feature selection | Features are selected manually by human experts | Features are learned automatically from raw data |
| Data Requirements | Works well with small to medium datasets | Requires large volumes of data to perform effectively |
| Training Time | Fast training; works on standard hardware | Slow training; needs specialized hardware (GPUs/TPUs) |
| Performance | Effective on structured/tabular data and simpler tasks | Excels on complex tasks with unstructured data (e.g., images, text, audio) |
| Interpretability | Often easy to interpret and explain (e.g., decision trees, regressions) | Often considered a black box; difficult to explain predictions |
| Examples | Spam filters, churn prediction, credit scoring | Face recognition, voice assistants, language models, self-driving |
In short, machine learning is efficient, fast, and easier to interpret, while deep learning is more powerful but requires more data, computation, and care.
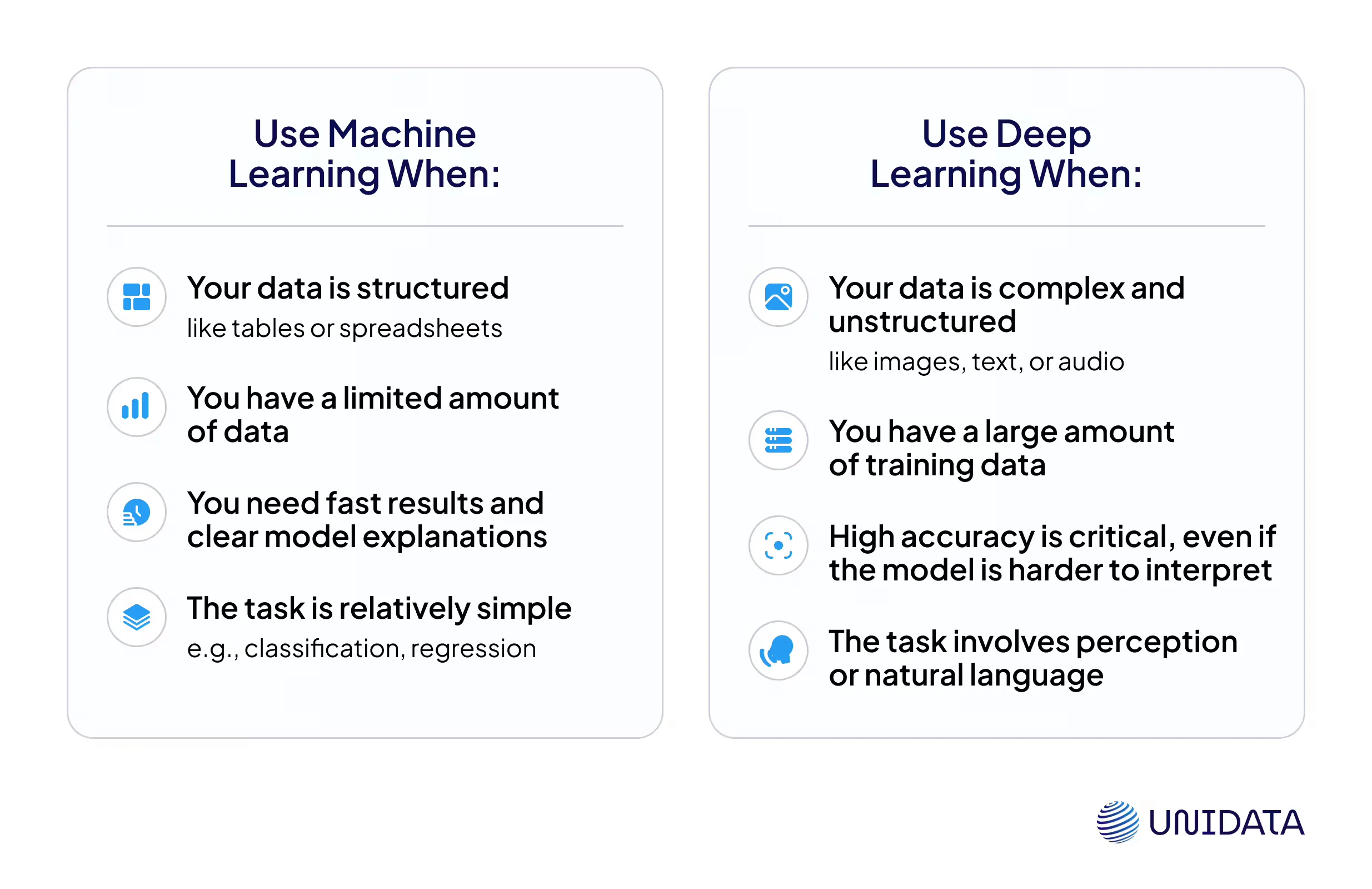
Which One to Choose — and When?
Here’s a quick side-by-side guide to help you decide which approach fits your task best.
Conclusion
Machine learning and deep learning are two fundamental approaches in modern artificial intelligence. Both enable systems to learn from data, but they differ in how they process information and in what they need to perform well.
Machine learning depends on human-engineered features and performs best with structured data in tasks like classification, regression, or predictive analytics. It is lightweight, interpretable, and well-suited for situations with limited data.
Deep learning, on the other hand, leverages deep neural networks to learn directly from raw, unstructured data, such as images, audio, or natural language. It requires more data and computational power but excels at complex tasks like image recognition, speech-to-text, or language modeling.
Knowing the strengths and trade-offs of each approach helps you choose the right one — or combine them — to solve real-world, data-driven challenges more effectively.
- AI Training
- Robotics
- Data Annotation
- Python
- AWS

Frequently Asked Questions (FAQ)
Machine learning is a broad field of AI where algorithms learn from data to make predictions or decisions — relying on human-engineered features and performing well on structured, tabular datasets. Deep learning is a specialized subset of machine learning that uses multi-layer neural networks to learn features automatically from raw, unstructured data like images, audio, or text. In short: deep learning is a more powerful but more resource-intensive form of machine learning, excelling at complex tasks where traditional ML reaches its limits.
Machine learning works in five key steps:
- Collect and prepare data, including feature engineering — selecting relevant variables — and labeling examples with correct outputs;
- Choose and configure a model suited to the task, such as a decision tree or logistic regression;
- Train the model by feeding it data, measuring prediction errors (loss), and iteratively adjusting internal rules to improve accuracy;
- Test the model on unseen data to evaluate how well it generalizes;
- Deploy the model and retrain it as real-world conditions shift over time.
Machine learning performs well on small to medium-sized, structured datasets and can run efficiently on standard computers.
Deep learning requires significantly larger volumes of data — the more it receives, the better it performs — and typically requires specialized hardware such as GPUs or TPUs for training.
The main deep learning architectures include:
- CNNs (Convolutional Neural Networks) for image-related tasks like object detection and medical imaging;
- RNNs (Recurrent Neural Networks) for sequential data like speech recognition;
- LSTMs/GRUs for modeling long-term dependencies in sequences, used in chatbots and language modeling;
- Transformers (e.g., BERT, GPT) for language understanding and generation;
- Autoencoders for anomaly detection and noise removal;
- GANs (Generative Adversarial Networks) for generating realistic synthetic images or data.
Not always — it depends on the task and data. Deep learning excels on complex, unstructured data (images, speech, text) and typically outperforms traditional ML when large datasets are available. Machine learning models often perform equally well or better on structured, tabular data and smaller datasets, and are generally faster to train and easier to interpret. For simpler tasks like churn prediction or fraud detection on tabular data, ML models such as random forests or gradient boosting often deliver strong performance with far less computational cost.
Choose machine learning when your dataset is small to medium-sized and structured, training time and computational resources are limited, interpretability of results is important, or the task is relatively straightforward (e.g., spam detection, credit scoring, churn prediction).
Choose deep learning when you have large volumes of data, the input is unstructured (images, audio, video, or raw text), the task is complex (e.g., facial recognition, speech-to-text, language modeling), and you have access to GPU infrastructure. In many real-world systems, both approaches are combined.