Client Request
Every day, thousands of buyers ask the same questions — and sellers can’t always keep up.
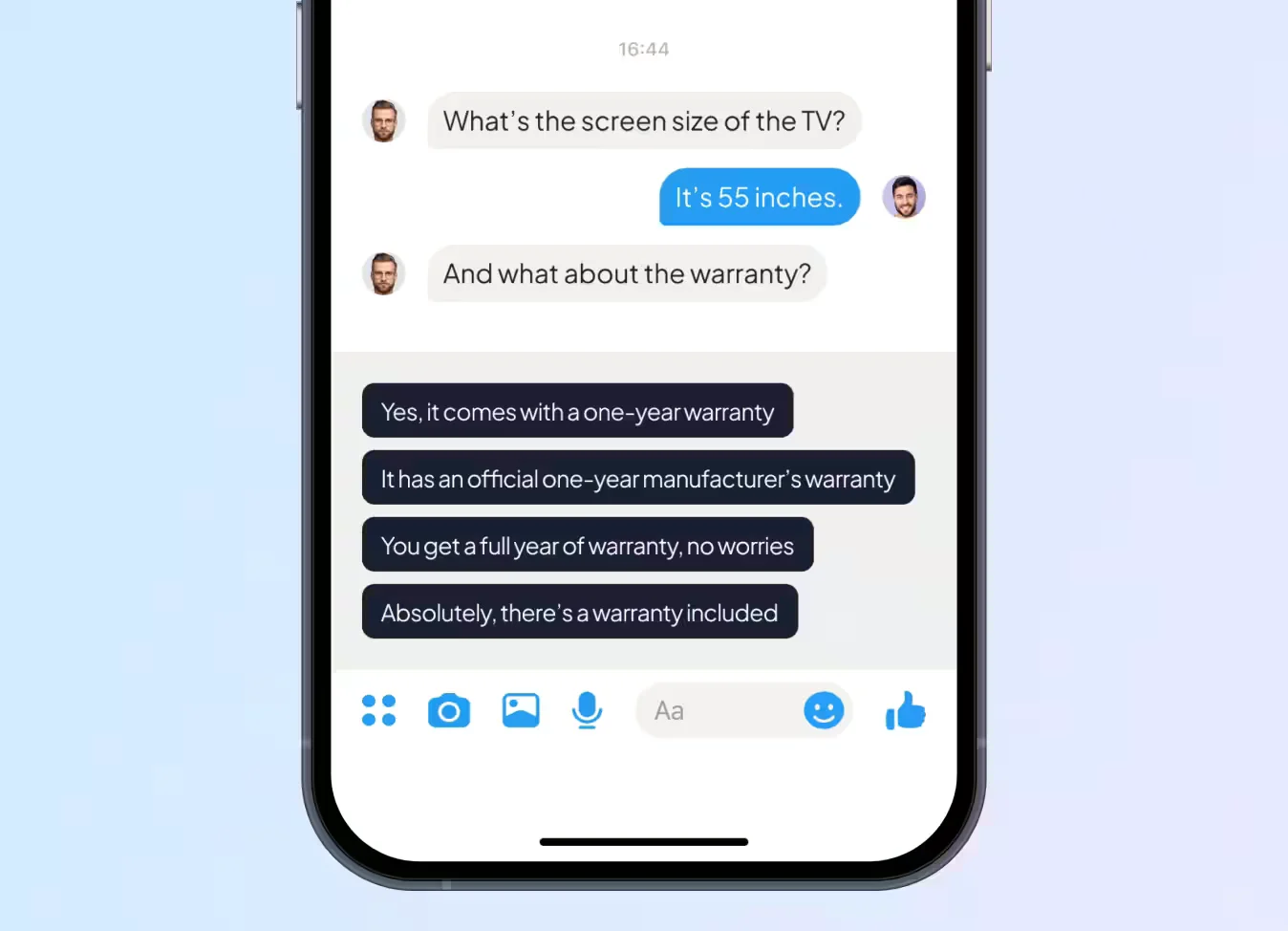
To automate these routine conversations without losing the human touch, a major classified platform turned to Unidata. The client aimed to develop an AI-powered system capable of predicting suggested replies in user-to-user chats. The goals were to:
- Streamline conversations between sellers and buyers
- Improve message relevance and clarity
- Reduce the risk of inappropriate or offensive messages
Unidata was engaged to provide high-quality data annotation for training the model. After reviewing and refining the client’s technical documentation, we initiated the project.
Our Approach
Technical Scope and Pilot Phase
The client supplied detailed guidelines outlining annotation requirements. Our team reviewed the instructions and proposed clarifications to better align the process with linguistic and contextual nuances.
During the pilot phase, we focused on:
- Addressing questions related to linguistic accuracy and stylistic tone
- Ensuring text suggestions reflected correct grammar and spelling
- Maintaining a conversational, informal style appropriate for peer-to-peer messaging
- Aligning all outputs with the norms of Russian language usage and the expectations of the platform’s user base
Annotation and Review Process
Our annotation team evaluated and labeled each suggested reply based on the following key criteria:
- Relevance to the user’s message
- Absence of provocative or offensive content
- Contextual accuracy within the flow of conversation
- Grammatical and stylistic correctness, including informal phrasing typical for chat communication
This required attention to detail across tone, punctuation, and naturalness of expression.
Validation Workflow
To ensure the highest accuracy, each batch of annotated suggestions underwent mandatory validation. Our validation process included:
- Selecting representative data samples for quality control
- Actively raising clarification requests and edge cases with project leads
- Sharing productivity and quality statistics per annotator with team managers
We placed particular emphasis on validator performance by:
- Involving the training team to improve validator skill levels
- Providing targeted learning resources and quality feedback loops
| Stage | Input | Workflow Scope | Main Quality Checks |
|---|---|---|---|
| Project Setup | Client guidelines & chat data | Instruction review, clarification, tone alignment | Guideline clarity / linguistic consistency |
| Pilot Phase | Sample conversations | Testing annotation logic, resolving edge cases | Tone accuracy / ambiguity reduction |
| Annotation | Chat messages & reply suggestions | Labeling relevance, safety, tone, grammar | Context alignment / toxicity filtering |
| Linguistic Control | Annotated responses | Informal style, natural phrasing validation | Fluency / conversational realism |
| Validation & QA | Annotated batches | Sampling, validator review, escalation of edge cases | Accuracy / policy compliance |
| Feedback Loop | QA results | Performance tracking, annotator feedback | Error reduction / consistency |
| Training & Support | Validators | Ongoing training, targeted improvements | Validator accuracy |
| Final Delivery | Validated dataset | Packaging and handoff | Dataset readiness / deployment quality |
The Results
- The model trained on the annotated dataset was successfully deployed.
- Internal client testing was conducted using real-time user dialogs to assess the accuracy and appropriateness of predicted replies. Early results showed high-quality, context-aware suggestions, no inappropriate topics or formulations, and natural tone suited for real conversations
- In a dedicated testing session, the client team manually evaluated the model’s responses in a live test environment. The system returned neutral, context-appropriate suggestions that avoided escalation or policy violations.
In conversational AI, the hardest part isn’t detecting toxicity. It’s generating responses that are neutral, context-aware, and still sound human. That balance only comes from carefully annotated real dialogue.

- Vladislav Barsukov
- Head of SLM&LLM Annotation