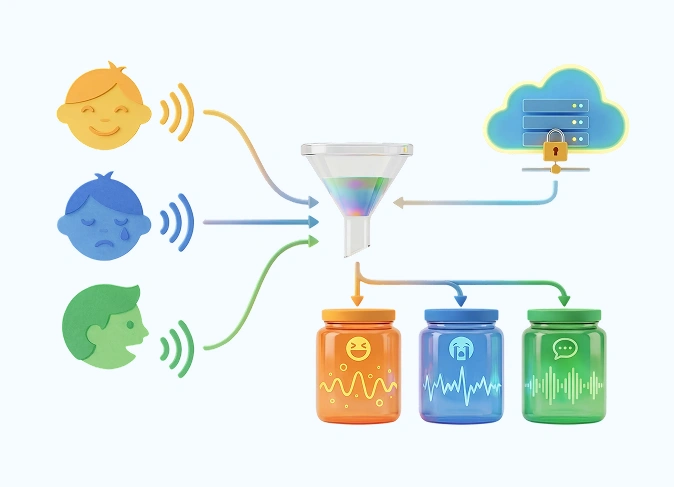
The Task
The client requested the collection of 750 unique audio recordings of children's laughter, crying, and speech within one month. Each child could participate only once, eliminating the possibility of using the same actors multiple times. Strict quality and diversity requirements added complexity to the task.
The Solution
To ensure an efficient data collection process, we divided it into several stages:
Dataset design and methodology:
- Defined the target age range and prioritized ethnic and regional groups
- Developed an age-verification approach combining visual assessment and metadata analysis
- Created clear, standardized instructions for participants and crowd platforms, including capture examples
Data Collection Approach:
- A pilot phase using the Yandex.Toloka platform proved to be too slow.
- We switched to an in-house collection strategy, engaging parents through social media and childcare institutions.
- To verify the authenticity of the audio, we required submissions in video format to confirm that the laughter, crying, and speech genuinely belonged to a child and that there were no repeated participants.
Data collection
- Leveraged established crowd platforms and tested new sources to expand geographic coverage
- Designed simple, engaging tasks to encourage complete and high-quality photo sets
- Provided fair compensation to reduce drop-off and incomplete submissions
- Monitored incoming data in real time to address quality issues early
Validation and quality control
- Combined automated checks with manual expert review to confirm age and photo ownership
- Applied multi-layer validation, with multiple reviewers cross-checking each submission
- Minimized inconsistencies and labeling errors, achieving a very low inaccuracy rate
- Delivered a clean, production-ready dataset suitable for model training and research
| Stage | Input | Workflow Scope | Main Quality Checks |
|---|---|---|---|
| Pilot & Setup | Client requirements for 750 unique child audio recordings | Dataset design, methodology definition, age range targeting, ethnicity and region prioritization, creation of instructions and capture examples | Age verification approach consistency (visual + metadata), clarity of task instructions |
| Participant Onboarding | Parents and childcare institutions via crowd and social channels | Recruitment of participants, onboarding, instruction delivery for recording laughter, crying, and speech | Participant eligibility (child age compliance), instruction comprehension |
| Attack Collection & Iteration | Audio and video submissions from children | Transition from external platform (Yandex.Toloka) to in-house collection, continuous gathering via social media and institutions, ensuring single participation per child | Authenticity of recordings (audio + video confirmation), no participant duplication |
| Monitoring & Reporting | Incoming audio/video dataset | Real-time monitoring of submissions, quality tracking, engagement optimization, ongoing iteration of collection strategy | Data quality consistency, early detection of errors and low-quality submissions |
| Validation & Quality Control | Collected recordings | Automated checks + manual expert review, multi-reviewer cross-checking, dataset cleaning and final curation | Age confirmation accuracy, identity consistency, labeling correctness, dataset integrity |
| Final Dataset Delivery | Validated audio dataset | Preparation of production-ready dataset for training and research use | Dataset completeness, reliability, readiness for model training |
1–2 weeks
Pilot & Setup
2–3 weeks
Participant Onboarding
ongoing
Attack Collection & Iteration
weekly, ongoing
Monitoring & Reporting
The Results
- Achieved high confidence in age accuracy and metadata reliability
- Identified consistent patterns of facial development across diverse ethnic and regional groups
- Enabled training for face recognition, anti-fraud systems, and academic research
The main challenge was not just collecting 750 child recordings, but ensuring each submission was truly unique and trustworthy. Switching from platform-based collection to direct engagement with parents was the turning point that allowed us to meet both scale and quality requirements within a month.

- Lucy Mamedoff
- Data Collection Project Manager