1. Introduction: What is Text Annotation?
Ever tried reading an ancient script with no translation? The symbols look interesting, but you have no clue what they mean. That’s exactly how AI feels when it encounters raw text without text annotation—just a flood of words with no direction.
Text annotation is like a decoder key for AI. It adds labels, structure, and meaning, helping machines understand words, emotions, and intent. This is what makes chatbots smarter, search engines more accurate, and customer service AI actually helpful.
Without annotation, AI is just making wild guesses. Let’s explore why this process is so essential.
2. Why is Text Annotation Important?
Language never stays still. New slang pops up daily. Industry terms evolve. Even emojis change meaning. Without updates, your AI model might think "fire" only means flames, missing that it’s also a compliment. That’s why text annotation is crucial—it keeps AI sharp, informed, and useful.
Why Does Text Annotation Matter?
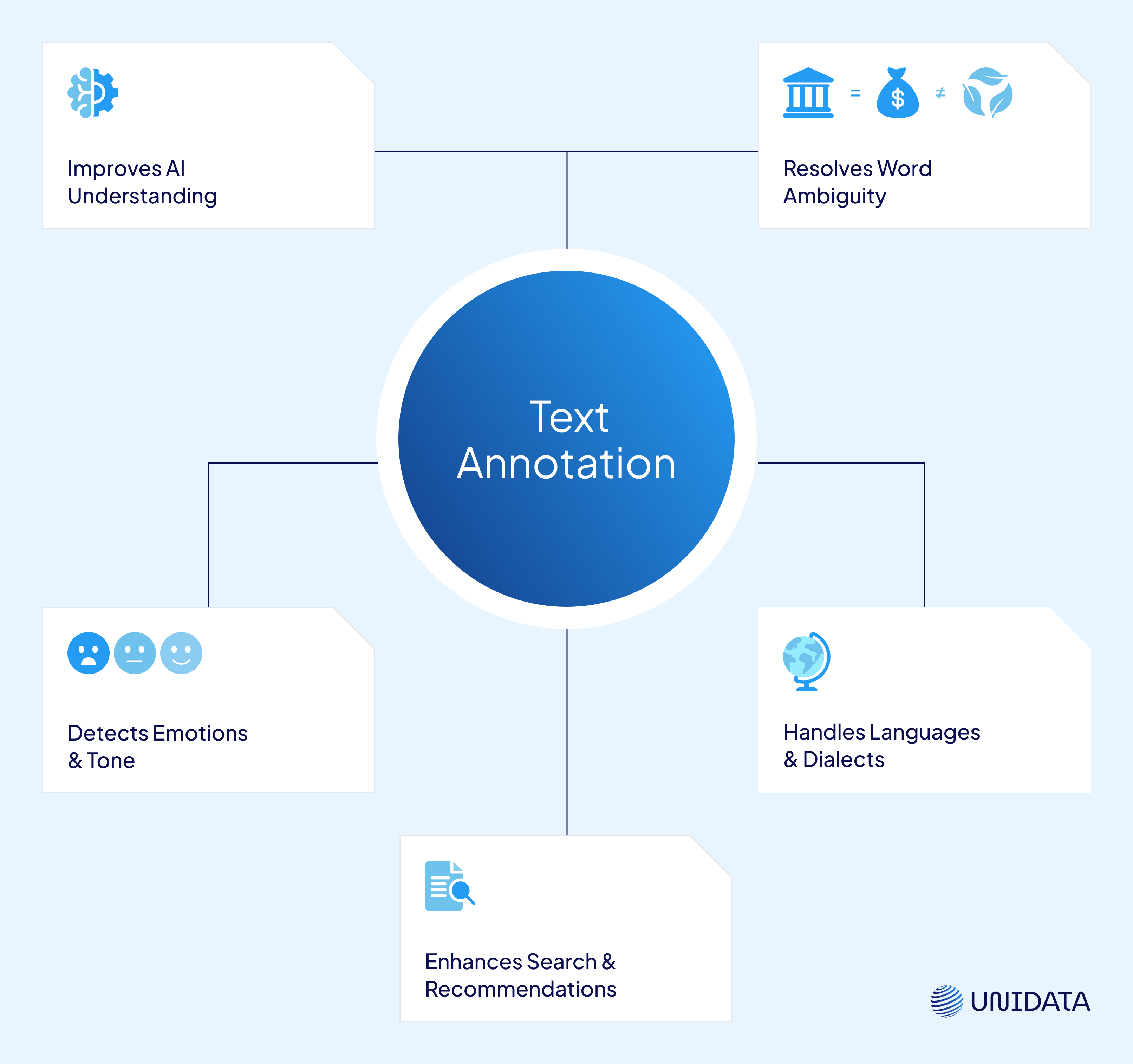
- Boosts NLP Model Performance
AI doesn’t “read” like we do. It finds patterns in data. If a chatbot needs to understand customer intent, it must be trained on labeled examples like “billing issue,” “refund request,” or “technical support.” The more precise the labels, the smarter the AI. Without proper annotation, the chatbot might mix up a refund request with a technical issue, leading to frustrated customers and ineffective support.
- Eliminates Confusion
Words can be tricky. Does “bank” refer to a financial institution or the edge of a river? Without labeled data, AI won’t know. Annotation helps by clearly defining meanings. Even more, some words change meaning over time. "Cool" used to mean low in temperature, but now it can also mean stylish or impressive. Annotation ensures AI stays updated with how language evolves
- Understands Emotions & Sentiments
A phrase like “This game is sick!” could mean it’s amazing or awful. Without annotation, AI might assume it’s negative. Sentiment tagging helps AI detect emotions correctly, whether in customer reviews, social media, or emails. This is especially important for brands that rely on AI to monitor public sentiment. Imagine a company misunderstanding customer feedback and thinking everything is positive when complaints are actually piling up!
- Handles Multiple Languages & Dialects
Languages aren’t straightforward. A simple word like “hello” is different in English (“hello”), Spanish (“hola”), and Japanese (“こんにちは”). AI needs annotations to recognize translations, dialects, and cultural nuances. Some words have entirely different meanings depending on the region. For example, "football" refers to soccer in most of the world, but in the U.S., it means American football. Text annotation ensures AI understands these differences.
- Improves Search & Recommendations
Ever searched for “best vegan pasta” and got unrelated results? Annotation helps search engines and recommendation systems match queries to relevant content. Without it, AI struggles to deliver useful results. Annotated text allows search engines to identify user intent better, improving the relevance of search results and recommendations. This applies to streaming services, e-commerce platforms, and even medical research databases.
Text annotation isn’t just helpful—it’s essential for making AI work the way we expect it to.
But how exactly do we annotate text? Let’s break it down by type.
3. Types of Text Annotation
Not all text annotations are the same. AI needs different types of labeling depending on the task. Some focus on spotting names, while others classify emotions or entire documents. Let’s look at the most common types and why they matter.
1. Named Entity Recognition (NER)

This helps AI identify and categorize names, locations, brands, and even numbers. It’s key for news filtering, finance, and legal documents.
“Apple announced a partnership with Goldman Sachs in New York.”
Apple → Organization
Goldman Sachs → Organization
New York → Location
A more advanced version of this links relationships between entities. For example, AI can learn that Tim Cook is the CEO of Apple, making it easier to connect facts across different documents.
2. Sentiment Annotation

AI needs to grasp emotions to understand opinions. Sentiment annotation labels text as positive, negative, or neutral, making it vital for brand monitoring, product reviews, and social media analysis.
"This phone is amazing!" → Positive
"Worst service ever." → Negative
It can go beyond basic labels, detecting sarcasm, excitement, or frustration. This helps businesses analyze customer feedback more accurately.
3. Intent Annotation

AI doesn’t just need to read—it needs to know what users want. Intent annotation labels requests so AI can answer correctly in chatbots, virtual assistants, and customer service.
"How do I reset my password?" → Support Request
"Cancel my order." → Order Modification
More advanced models pick up multiple intents in one request, like: “Cancel my order and refund my payment.” AI then recognizes two separate actions.
A Case in Our Practice
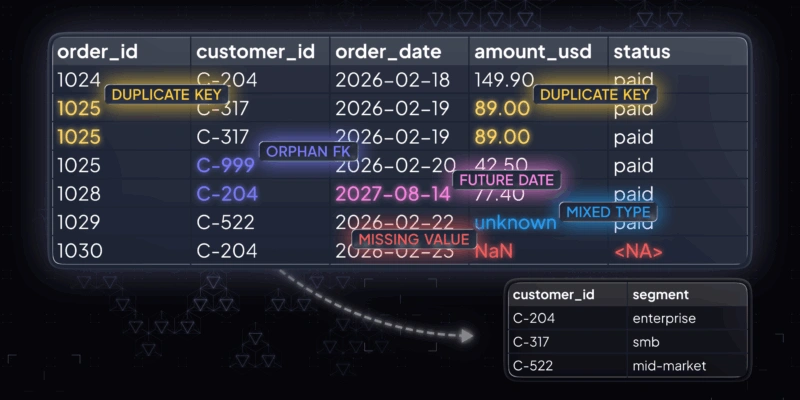
For example, a client asked us to annotate documents. There was no technical specification at the start, so we kicked things off with a small test batch of 10 documents to get alignment.
Soon after, the scope grew to over 1,000 documents—but without a defined annotation logic, things got tricky. Some documents had errors, and even the client’s templates didn’t always follow the same rules. On top of that, annotation was happening inside their setup using a free version of Label Studio, which made version control difficult. Any assessor could accidentally overwrite previous work, and validation was hard to manage.
To bring structure to the process, we created clear internal rules, applied consistent logic, and ran our own QA to keep quality high. Even without a detailed spec, we worked closely with the client to interpret intent and refine the annotation logic as we went.
The result was a process that felt smooth and controlled, even in a tricky setup. We delivered a clean, structured dataset and helped the client move forward with a stronger data foundation.
4. Part-of-Speech (POS) Tagging

Grammar matters. POS tagging labels words by their grammatical roles, helping AI with translation, text generation, and speech recognition.
"The cat sleeps."
The → Determiner
Cat → Noun
Sleeps → Verb
More advanced versions go beyond single words, identifying verb tenses, noun phrases, and sentence structure to improve AI’s ability to process complex text.
5. Text Classification

This type of annotation sorts whole texts into predefined categories. It’s essential for spam filters, content moderation, and news categorization.
Spam vs. Not Spam (email filtering)
News Topics (Sports, Politics, Tech, etc.)
Product Reviews (Positive, Neutral, Negative)
Some AI models go even further, detecting subcategories within topics. For instance, a sports news classifier can tell football from basketball, even though both belong under the broader sports category.
4. How is Text Annotated: NLP Text Annotation Process
Annotating text isn’t just about putting labels on words. It’s a step-by-step process that requires clear planning, attention to detail, and quality control. Here’s how it works:
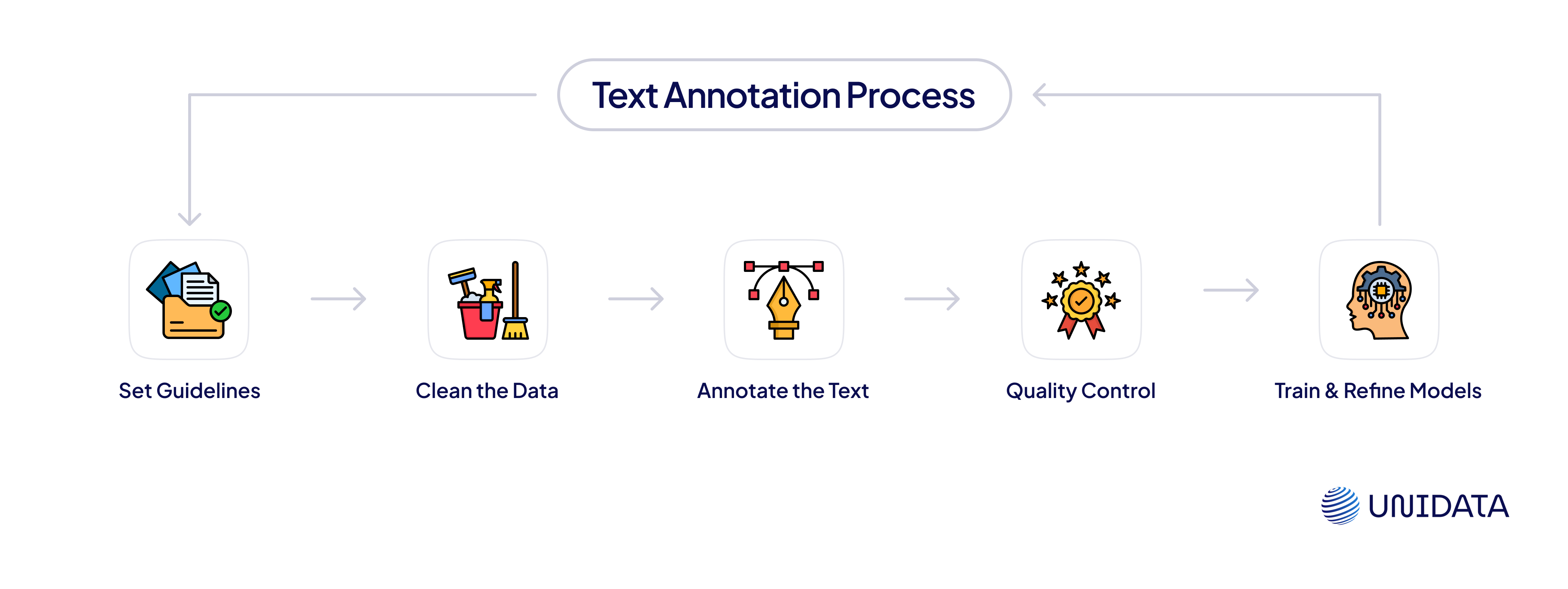
Step 1: Set Annotation Guidelines
Before annotation begins, there need to be clear rules. These rules define what gets labeled, how to label it, and how to handle tricky cases. Without clear guidelines, annotations can be all over the place, making the data unreliable.
Define what needs tagging (e.g., names, locations, emotions, categories)
Clarify sentiment labels (e.g., happy, frustrated, neutral)
Ensure consistency by using the same format across all data
Step 2: Clean and Prepare the Data
Raw text can be messy. It’s often filled with typos, unnecessary words, and irrelevant content. Cleaning it up makes annotation easier and improves AI accuracy. Here’s what happens in this step:
Removing duplicate content to avoid repetition
Fixing typos and grammar mistakes
Splitting text into sentences or words (a process called tokenization)
Filtering out unimportant words like "the," "and," or "is"
Converting file formats (e.g., turning PDFs into plain text for easy annotation)
Step 3: Apply Human or AI Annotation
Now, the actual labeling begins. Annotation can be done in different ways:
Manual annotation – Humans go through the text and carefully label everything. It’s accurate but takes time.
AI-assisted annotation – AI suggests labels, and humans verify them. This is a great mix of speed and accuracy.
Fully automated annotation – AI applies labels on its own. This works well for massive datasets but often needs human review.
Step 4: Quality Control & Error Checking
Bad labels mean bad AI predictions. That’s why quality control is critical. A few ways to ensure accuracy:
Multiple annotators label the same text to compare results
Inter-annotator agreement scores measure how often annotators agree
Automated checks flag potential errors and inconsistencies
If disagreements happen, a review process helps update annotation rules so the model keeps learning correctly.
Step 5: Training and Refining AI Models
Once the text is labeled, it’s used to train AI models. But the process doesn’t stop there. AI performance is tested and improved over time.
Finding weak spots where the model struggles
Re-labeling tricky cases to provide better training data
Updating annotation rules to improve accuracy
This cycle of annotation, training, testing, and refining makes AI more reliable and smarter over time. The better the annotation, the better the AI model performs!
Product Grouping for E-commerce
- Major online classifieds platform
- 20,000 listings annotated for product model identification
- 8 weeks
5. Our Use Cases
Teaching AI to Read Between the Lines in Biomedical Research
The Challenge: An AI-focused pharmaceutical company needed to train a model that could identify real, evidence-based connections between genes and diseases. The data source? Thousands of peer-reviewed scientific abstracts.
But this wasn’t a simple keyword-matching task. Their BERT-based model needed help understanding whether a gene and a disease were truly related in context—not just mentioned in the same sentence. The challenge was to create reliable annotations that reflected actual scientific claims, not surface-level patterns.
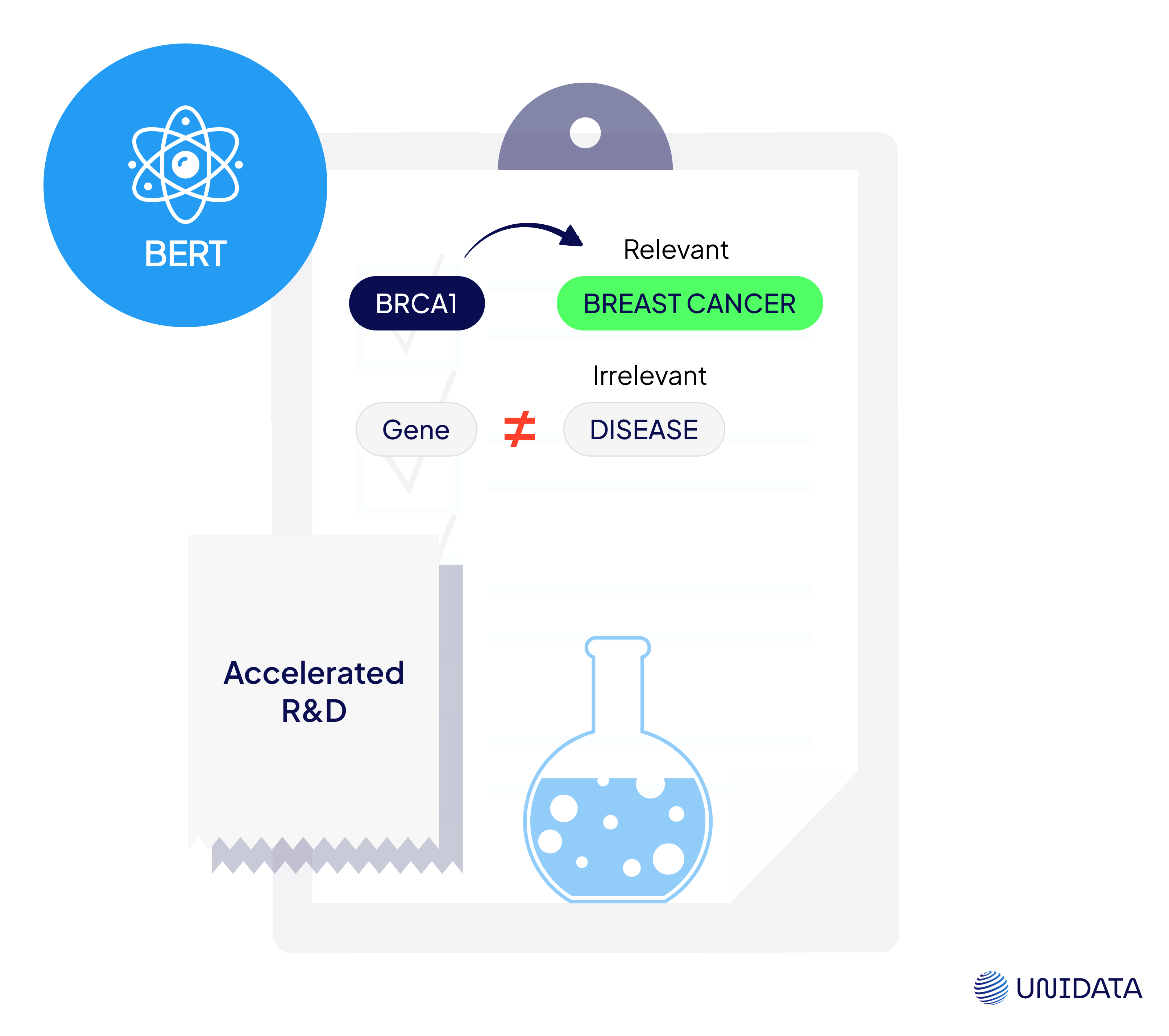
Our Solution: We built a custom annotation pipeline designed specifically for this use case.
The first step was relevance tagging—determining if an article meaningfully discussed a gene or disease. Then we used Label Studio to annotate both entities and their relationships. Equally important, we marked examples where entities co-occurred without a real link, helping the model learn what not to flag. Every task went through a two-annotator review process to ensure consistency and precision.
The Impact: The annotated dataset trained a high-performing model that could accurately detect gene–disease associations. It was successfully deployed in real-world pharma R&D pipelines. The result? A new drug was brought to market in under a year—a timeline cut dramatically shorter than traditional development cycles.
Making Sense of Messy Delivery Reviews with Smart Text Labeling
The Challenge: A national grocery chain wanted to get serious about delivery feedback. They had a growing collection of free-text customer reviews and needed a way to extract actionable insights—especially around product quality issues.
But the reviews were messy, unstructured, and emotional. Customers might say “they brought me squashed bananas” or “the apples were fresh and perfect,” but there was no consistent format. To improve service, the company needed to know:
- What product was mentioned?
- What condition was it in?
- Was the feedback positive or negative?
Their goal was to analyze complaints and compliments at scale—automatically and accurately.
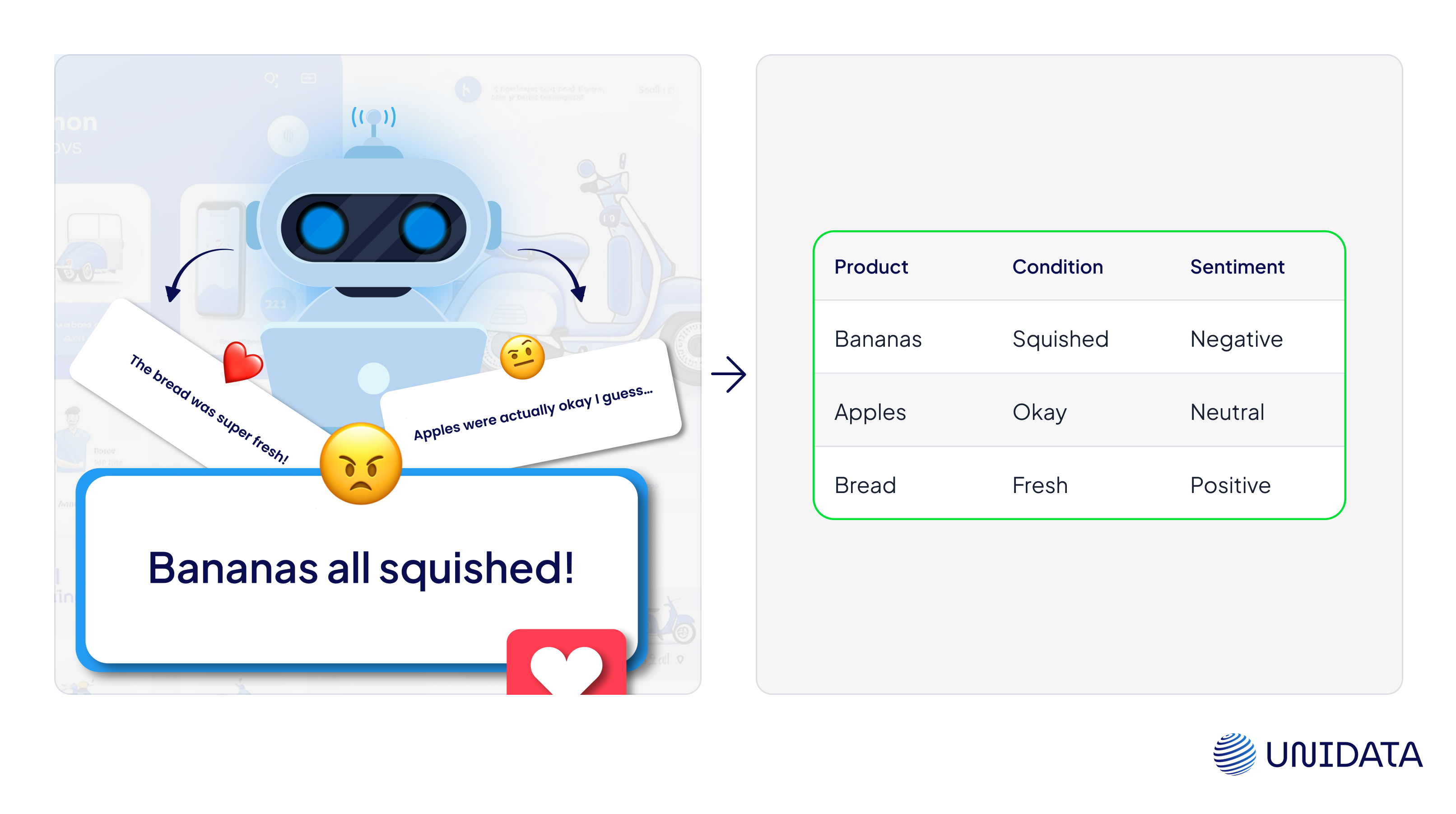
Our Solution: We set up a full annotation workflow using Label Studio, built specifically for feedback on grocery delivery.
Our team labeled three key components in each review:
- Product type – like tomatoes, bananas, or bread.
- Condition – fresh, damaged, moldy, etc.
- Sentiment – positive or negative, based on how the product was described in the comment.
For example, in the sentence “They delivered rotten tomatoes,” the system would extract:
- Product: tomatoes
- Condition: rotten
- Sentiment: negative
This combination of NER and sentiment annotation helped the client’s analytics pipeline transform raw reviews into structured, searchable data. The Impact: Thanks to this custom annotation effort, the grocery chain was able to pinpoint exactly which product categories were driving complaints, and how often. The result? Faster issue detection, fewer repeat complaints, and happier customers who felt heard—all powered by high-quality annotated data.
Making Sense of Customer Sentiment with Simple, Accurate Labels

The Challenge: A client needed help sorting through a steady stream of customer feedback. The task? Label each review as negative (-1), neutral (0), or positive (1). Sounds simple on the surface—but sentiment is rarely black and white.
Short comments like “it’s okay” or “not bad” can be hard to categorize. Tone and phrasing matter. The model needed help understanding subtle emotional cues in short, often informal texts.
Our Solution: We built a clear, consistent sentiment annotation workflow in Label Studio. Our team labeled thousands of customer reviews, using the client’s 3-point system. Every review was analyzed not just for keywords, but for overall tone and intent.
To ensure consistency, we aligned with the client on edge cases—like passive-aggressive phrasing or vague positives. This helped create a reliable dataset that would train the model to classify sentiment as a human would.
The Impact: The client now has a clean, trustworthy training set. Their sentiment model delivers faster and more accurate classification, powering real-time feedback analysis and helping teams spot patterns in customer satisfaction early.
Beyond the Words: Teaching AI to Read the Emotional Tone of News
The Challenge: A media analytics company wanted to analyze 10,000 news articles and sort them by sentiment. The goal was to label each article as positive or negative—whether it was about politics, sports, or current events.
But news isn’t always emotional on the surface. The tone is subtle. A political report might sound neutral but carry a strongly negative slant. Sports news might mix celebration with criticism. The model needed examples that reflected real-world nuance, not just obvious language.
Our Solution: Using Label Studio, we set up a sentiment annotation pipeline for long-form news. Each article was labeled by sentiment based on overall narrative tone, not just word-by-word analysis. Annotators were trained to read contextually and assess sentiment holistically—especially in sensitive or complex reporting.
We also made sure to balance different categories (e.g., politics vs. sports) so the model didn’t pick up topic-based bias when learning.
The Impact: The annotated dataset gave the client a powerful training base for sentiment tracking at scale.
Conclusion
AI isn’t born smart—it learns from data. And that data needs to be annotated. Without text annotation, AI wouldn’t understand words, emotions, or user intent.
From chatbots to search engines, from medical AI to customer service, text annotation makes AI work the way we expect it to. It’s the invisible force behind most of the AI-powered tools we use daily.
Next time you interact with AI, remember—it’s only as smart as the data it has been trained on. And that data? It’s all thanks to text annotation.
Frequently Asked Questions (FAQ)
Text annotation is the process of labeling and structuring raw text data so machines can understand meaning, intent, and context. In NLP, text annotation adds tags such as sentiment, entities, or intent, turning unstructured text into training data for AI models like chatbots, search engines, and recommendation systems.
To annotate text, you first define clear annotation guidelines, then clean and prepare the data through tokenization and preprocessing. After that, labels are applied manually or with AI assistance, followed by quality control checks and continuous refinement to ensure accurate and consistent annotations for machine learning models.
Text annotation is essential for NLP because it directly impacts model accuracy and performance. Without labeled data, AI cannot distinguish meanings, detect sentiment, or understand user intent, leading to poor predictions and irrelevant outputs in real-world applications.
The most common types of text annotation include named entity recognition (NER), sentiment annotation, intent annotation, part-of-speech tagging, and text classification. Each type serves a specific purpose, from identifying key entities to understanding emotions and categorizing entire documents.
Quality control ensures that annotations are accurate, consistent, and reliable. Techniques like inter-annotator agreement, validation workflows, and automated error detection help prevent mislabeled data, which could otherwise degrade machine learning model performance.
Text annotation can be partially or fully automated using AI models, but human review is still critical for maintaining accuracy. AI-assisted annotation combines speed with precision, where algorithms suggest labels and human annotators validate them to produce high-quality training datasets.