
Data labeling and data annotation might sound similar, but they play different roles in making smart computer programs. In this easy guide, we'll explore what each term means, how they differ, and why they're important for creating AI. Get ready to understand all of these key steps thoroughly.
There is often confusion around the terms annotation, tagging, categorization, labeling, and marking in modern AI and machine learning domains.
Let’s see the differences between the terms to eliminate the confusion:
| Term | Definition | Primary use case | Key features |
|---|---|---|---|
| Annotation | Adding metadata to data, such as highlighting or marking specific elements | Used in detailed data preparation for ML models | Involves providing additional context or information to data |
| Labeling | Assigning specific labels or tags to data points for classification | Essential for supervised learning in ML models | Directly assigns labels that are used in training ML algorithms |
| Tagging | Attaching descriptive keywords or labels to data items | Used for quick identification and organization of data | Focuses on assigning keywords or tags for easier retrieval |
| Categorization | Organizing data into predefined categories or classes | Used for sorting and classifying data based on shared traits | Involves grouping data into distinct classes or categories |
| Marking | Highlighting or identifying specific regions or elements within a dataset | Often used in image or video data processing | Can involve drawing boundaries or marking areas of interest |
A good example of this can be seen with two tools widely used in computer vision: CVAT and Label Studio. On their official websites, CVAT describes itself as an annotation tool, while Label Studio calls itself a labeling tool, even though their functionalities are very similar and differ only in minor details.
Without laying out the context, it can be extremely difficult to understand what these terms refer to. For example, the term "segmentation" can have completely different meanings depending on the task. Here are some of the meanings that it can take up:
- Marking objects with polygons.
- Segmenting each object separately and assigning it a class.
- Segmenting, or classifying the entire image.
- Labeling objects as entities (e.g., determining whether an object is grass or a group of people).
Data Labeling vs. Data Annotation: Key Differences
While both data labeling and data annotation play crucial roles in preparing datasets for machine learning models, understanding their key differences, particularly in goals and applications, is essential for using them effectively.


Goals
Labeling has the goal of assigning an identifier to a dataset, essentially providing a high-level classification. This helps guide machine learning models in autonomously recognizing and categorizing data.
e.g., tagging an entire image as "cat" or a text document as "email". Or finding a car plate in the image with a car
Labeling helps in tasks like differentiating between different objects or themes within datasets by attaching one or more labels that best describe the overall content or nature of the data.
Labeling tasks often boil down to simple questions like "Is there an object in the image?". In other words, these are always straightforward tasks of categorization or object identification.
On the contrary, the goal of annotation involves adding additional information and context to the data, which might include marking up specific elements within the data.
e.g. drawing bounding boxes around objects, segmenting regions, or marking key points in images.
e.g. marking the zone for the cat’s tail
e.g. marking the numbers and region code on the car plates
The annotating process often supports more detailed and nuanced understanding and analysis by delineating boundaries, identifying key points, or providing detailed classifications within data segments.
This detailed guidance allows models to not only recognize what is present but also understand the location, dimensions, and other specifics that are critical for more complex interpretations and decisions.
Understanding the distinctions and applications of labeling and annotation can significantly impact the effectiveness of your machine-learning models. Let’s see the cases and situations where either labels or annotations can be a preferred choice.
| Data annotation vs data labeling: use cases | |
|---|---|
| Use data labeling for: - Broad categorization - Simpler models with less granularity - Early stages of model training | Use data annotation for: - Detailed analysis and decision-making - Natural Language Processing (NLP) - Advanced computer vision projects |
When to Use Labeling
Picking the right data handling approach depends on the project's goals, the complexity of the task, and the level of detail required in the analysis. Here are the cases when you'd better use labeling over annotation.
- Broad categorization: Where the key requirement is to distinguish data at a fundamental level, for example, identifying whether an image has a cat or a dog.
- Simpler models with less granularity: In scenarios where the model does not need to understand the intricate details within the data to make accurate predictions.
- Early stages of model training: When introducing the basic concepts to a model before it advances to analyze more detailed and nuanced information.

When to Use Annotation
- Detailed analysis and decision-making: Annotation is vital for tasks requiring an understanding of intricate details, such as facial recognition or autonomous vehicle navigation, where exact positioning, dimensions, and identities of multiple objects are crucial.
- Natural Language Processing (NLP): Applications like sentiment analysis or entity recognition in texts, where specific parts of the data need to be identified and understood in context.
- Advanced computer vision projects: Including object detection, segmentation, and tracking in images or videos, where the precise locations, shapes, and interaction of elements are essential for the model’s performance.

Both processes are integral to the development of sophisticated, reliable AI models, each serving its unique purpose in the broader context of machine learning and AI development.
Applications
Both data labeling and data annotation are integral to the development and enhancement of machine learning and artificial intelligence models, but they find their specific applications in different contexts:
Labeling Applications
- Image classification: Assigning a single label to an entire image, such as "dog" or "cat". This application is widespread in sorting visual content for e-commerce or social media platforms.
- Email filtering: Labeling emails as "spam" or "not spam" helps email services automatically filter out unwanted messages, improving user experience.
- Sentiment analysis: In natural language processing (NLP), texts (reviews, comments, etc.) are labeled based on their sentiment (positive, negative, neutral) to estimate public opinion or customer satisfaction.
- Voice command recognition: Labeling audio data to train virtual assistants and voice-controlled devices to understand and respond to spoken commands accurately.
Annotation Applications
- Object detection and segmentation: Annotating images with bounding boxes around specific objects (detection) or outlining the exact shape of objects (segmentation). Used in autonomous vehicle technology for identifying obstacles, in medical imaging for tumor detection, or agricultural drones identifying crop health.
- Facial recognition: Annotating facial features using keypoint or landmarks for applications in security (e.g., surveillance cameras) or technology (unlocking smartphones).
- Pose estimation: Annotating human figures with key points to understand body posture and movement. Applications include sports analytics for improving athletes' performances, physical therapy, and enhancing interactive gaming experiences.

- NLP for advanced contextual understanding: Deep linguistic annotation in texts for tasks like machine translation, where context, syntax, and semantic roles need to be understood precisely. This is critical in developing AI that can understand and generate human-like responses or translations.
| Data labeling vs data annotation: practical applications | |
|---|---|
| Use data labeling in: - Image classification - Email filtering - Sentiment analysis - Voice command recognition | Use data annotation in: - Object detection and segmentation (automotive, healthcare, and agriculture) - Facial recognition (security and high tech) - Pose estimation (games, sports, healthcare) - NLP for advanced contextual understanding |
Techniques and Methods
There are two basic techniques for realizing the process of data labeling:
- Manual labeling: requires human reviewers to label the data as per the defined categories and guidelines. This method is useful with ambiguous and context-dependant categories where labels require human judgment.
- Automated labeling: requires trained algorithms and pre-labeled data to accelerate the process. Automation is relevant for text categorization, image segmentation, and such cases where the label is obvious and non-subjective.
Here are the basic techniques used for data annotation.
- Bounding boxes: This is used for object detection tasks and the process is like drawing a rectangle around an object in an image to mark its location. Bounding boxes are useful in recognizing simple object locations of images, however, it doesn’t capture the exact object shape.

- Polygon segmentation: This technique is used for more precise object outlining. Each corner point of a polygon is marked, and the lines connecting these points define the object’s boundary. Most commonly, polygon segmentation is used for satellite image interpretation or medical imaging.

- Keypoint annotations: It involves identifying specific points of interest on an object within an image. For example, when working with images of people, key points might be placed on the elbows, knees, tips of the ears, and eyes to map the posture and movements of the human body.
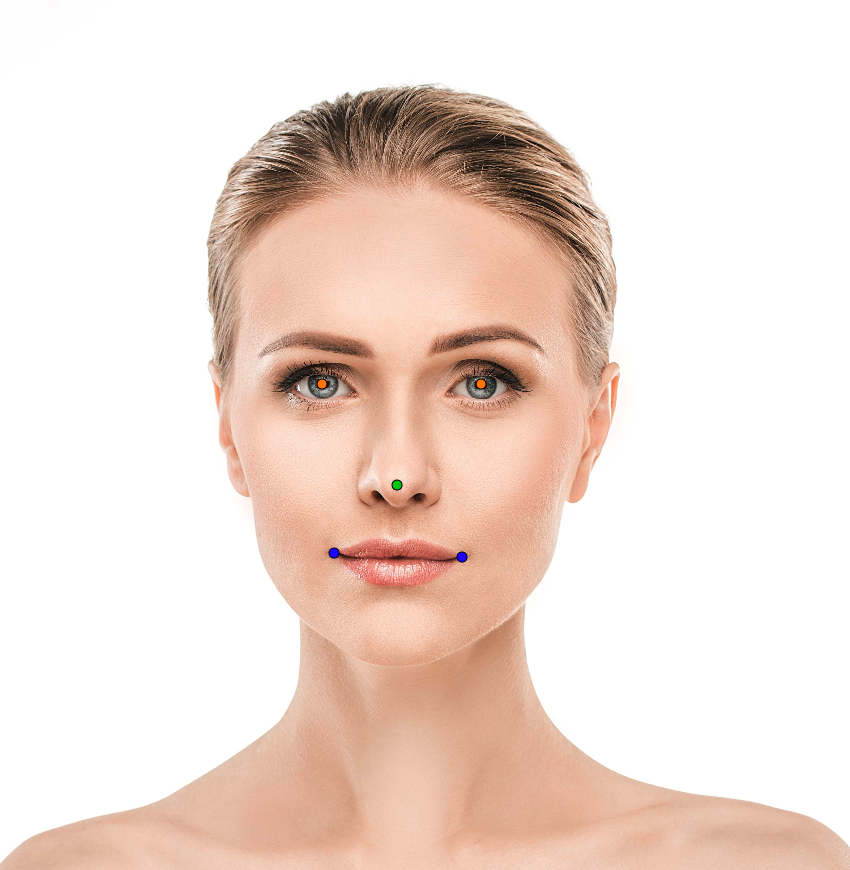
Although an effective and crucial process in handling data, adding labels brings about several challenges and limitations to machine learning practices.
For Manual Data Labeling
- Human error: With manual adding labels, the human error factor can lead to inaccuracies.
- Inconsistency: Creating a unified approach across all practices can be a challenge when dealing with larger task volumes.
- Scalability issues: The dataset growth requires more effort and cost especially with large-scale AI applications.
- The need for expertise: In certain data types in medical and legal contexts, you will need domain experts to ensure accuracy.
- Sensitive data: Dealing with private and sensitive information poses security concerns, especially under regulations like GDPR.
Automated Data Annotation – Complete Guide
Learn more
For Automated Data Labeling
- Accuracy: Despite being faster and less resource-intensive might produce less accurate labels leading to poor model performance.
- Evolving categories: Categories change over time and require adjustments in the pre-defined labels for automation algorithms.
- Ethical concerns: The risk of unethical use of biased models, especially in sensitive areas like facial recognition or predictive policing, is a significant concern.
- Lack of ready-made models for specific tasks: The absence of pre-built models for highly specialized tasks means that additional resources and time are needed to develop customized solutions. This can slow down the implementation process and increase costs.
For Data Annotation
Alongside its benefits, data annotation poses some limitations in machine learning. In the list below we have described the common limitations and complexities you should consider/
- Quality assurance: Consistency and quality across annotations particularly with a large team of annotators is a challenge to handle carefully.
- Time and budget consumption: Annotating requires a significant amount of human labor therefore it makes the process quite costly.
- Subjectivity: Some tasks are subjective, leading to variability in the labels which can affect model training.
- Data privacy: As in labeling, this one also poses security limitations when handling personal details and privacy regulations.
- Expertise: Some level of technical expertise is often required to annotate accurately, especially for more complex tasks like semantic segmentation.
Industries
Labeling finds its application across various sectors:
- retail, where it helps in product categorization
- healthcare for identifying types of diseases based on symptoms
- autonomous vehicles for recognizing traffic signals.
Annotating, on the other hand, is significant in industries requiring precision and detail; for example,
- healthcare for annotating medical images (like MRIs for tumor detection)
- automotive for developing advanced driver-assistance systems (ADAS)
- technology for enhancing AI-driven applications like virtual assistants.

Image Annotation for Construction and Heavy Machinery
- Construction & Infrastructure
- 5,000 images
- 5 days
Tools
A variety of tools exist to streamline these processes, each offering unique features tailored to specific types of data-handling tasks. Here's a roundup of popular data labeling and data annotation tools:
- LabelBox: A universal platform that supports labeling for various data types, including images, videos, and text. It offers a collaborative interface, making it easier for teams to work together efficiently.
- Amazon SageMaker ground truth: Part of the AWS ecosystem, this service helps build highly accurate training datasets for machine learning quickly. It offers both automated and manual labeling features, along with built-in workflows for common tasks.
- DataTurks: A platform that provides labeling tools for images, text, and tabular data. It's known for its simplicity and effectiveness in handling classification and entity extraction tasks.
- Figure Eight (now Appen): Offering both software and access to a crowd of workers, it's ideal for tasks that require human judgment across data types such as text, image, audio, and video.
- VGG Image Annotator (VIA): A simple and standalone annotation software for image, audio, and video. VIA is highly customizable and works in a browser without the need for server-side processing or storage.
- Prodigy: A scriptable annotation tool that supports active learning, allowing users to train a statistical model in the loop. It's particularly effective for text data, offering rapid capabilities for a variety of NLP tasks.
- LabelMe: A web-based tool for image annotation that allows researchers to label images with polygons and store them in XML format. It's widely used in computer vision research.
- MakeSense.ai: A free, easy-to-use online tool for annotating images that doesn't require any setup or installation. Supports various types, including bounding boxes, polygons, and keypoints.
- CVAT (Computer Vision Annotation Tool): An open-source tool designed for annotating digital images and videos for computer vision algorithms. It supports several methods, including object detection, image segmentation, and classification.
Human Input in Labeling and Annotation
Human input crucial role in the development of machine learning models by labeling and annotating data, tasks that require precision, understanding, and often, domain-specific knowledge. Human contributions ensure the high quality of data that AI systems rely on to learn and make accurate predictions. Humans can assist machine learning in the following activities:
- Understanding complex contexts
The human ability to identify nuances, cultural specifications, and other contextual features allows them to label and annotate data with a level of understanding that is currently beyond AI capabilities.
- Making judgments on ambiguous data
In ambiguous situations, human annotators use their judgment to categorize or annotate it appropriately. This is particularly important in subjective areas like sentiment analysis or when dealing with complex, domain-specific content.
- Ensuring quality and consistency
Humans are responsible for maintaining the quality and consistency of labeled and annotated data. They review the work for errors or inconsistencies and validate the accuracy of annotations, ensuring that the final dataset is reliable for training machine learning models.
- Providing detailed annotations
Annotating often requires detailed work, such as drawing precise boundaries around objects in an image or marking specific features within a dataset.
- Implementing domain-specific knowledge
Humans with expertise in specific fields, like medicine, law, or biology, provide invaluable insights that greatly enhance the quality and relevance of the labeled and annotated data.
Required Human Skills and Expertise
Core Differences in Human Skill Requirements
Data labeling and data annotation are both essential tasks in machine learning models, but they require different skill sets and expertise from human annotators.
- Data labeling is assigning labels or tags to data points, such as categorizing images or texts. It requires attention to detail, accuracy, and familiarity with specific labeling guidelines. Annotators need to be precise and consistent in their labeling to ensure the quality of the final dataset.
- On the other hand, data annotation entails adding additional information or context to the data, such as highlighting key features or marking relationships between data points. Annotation requires a deeper understanding of the data and often involves more complex analytical skills. Annotators must be able to interpret the data and make informed judgments to provide meaningful annotations.
Although both data labeling and data annotation require attention to detail and analytical skills, data labeling focuses on categorizing and organizing data, while data annotation involves adding context and meaning to the data. Annotators working on these tasks may need different levels of domain-specific knowledge and expertise to perform their roles effectively.
Automation Prospects
The automation of labeling and annotation stands at the forefront of transforming how data is prepared for artificial intelligence (AI) and machine learning (ML) development.
Leveraging advancements in automation will help enhance efficiency and accuracy, and reduce the manual labor traditionally associated with labeling large datasets.
Key prospects include:
- Semi-automated tools, blend human insight with machine learning algorithms to refine and accelerate the process.
- Active learning techniques prioritize instances that would most benefit from human annotation, optimizing the allocation of human resources.
- The adoption of pre-trained models offers another avenue for automation. These models, already trained on extensive datasets, can perform initial annotations with minimal human intervention.
- Synthetic data generation is a novel approach to creating automatically annotated data, tailor-made for specific AI applications.
However, these automation prospects are not without challenges. Ensuring the quality of automatically generated labels and annotations, addressing domain-specific nuances that require expert knowledge, managing ethical concerns and biases in training data, and maintaining adaptability to new requirements are crucial considerations.
As the sector progresses, the synergy between automated systems and human oversight will be greatly valued. Balancing the scalability and speed of automation with the nuanced understanding and judgment of humans will be key to utilizing the full potential of data labeling and annotation for AI's future.










