Artificial Intelligence (AI) is rapidly transforming industries, offering businesses powerful tools to enhance decision-making, automate processes, and create innovative products. But behind every AI breakthrough is a critical process: AI model training. Understanding how AI models are trained and how to optimize this process is essential for leveraging AI’s potential.
In this article, we will cover everything you need to know about AI model training, from the basics to advanced techniques, as well as how to select the right training tools to maximize success. Let's begin by laying the foundation for AI, Machine Learning (ML), and Deep Learning (DL), followed by insights into the entire training process.

What Is AI Model Training?
AI model training refers to the process of teaching an AI model to perform tasks by feeding it data, enabling it to learn patterns, make predictions, or classify information. The goal of training is to adjust the model’s parameters until it can make accurate predictions on new, unseen data. AI model training is at the heart of machine learning and deep learning, as it allows systems to improve their performance autonomously by learning from experience.
In simple terms, AI training is similar to how humans learn—by exposure to examples, trial and error, and refinement over time. The more accurate the data and the better the training process, the better the AI model will perform in real-world applications.
Concepts of AI vs. ML vs. DL
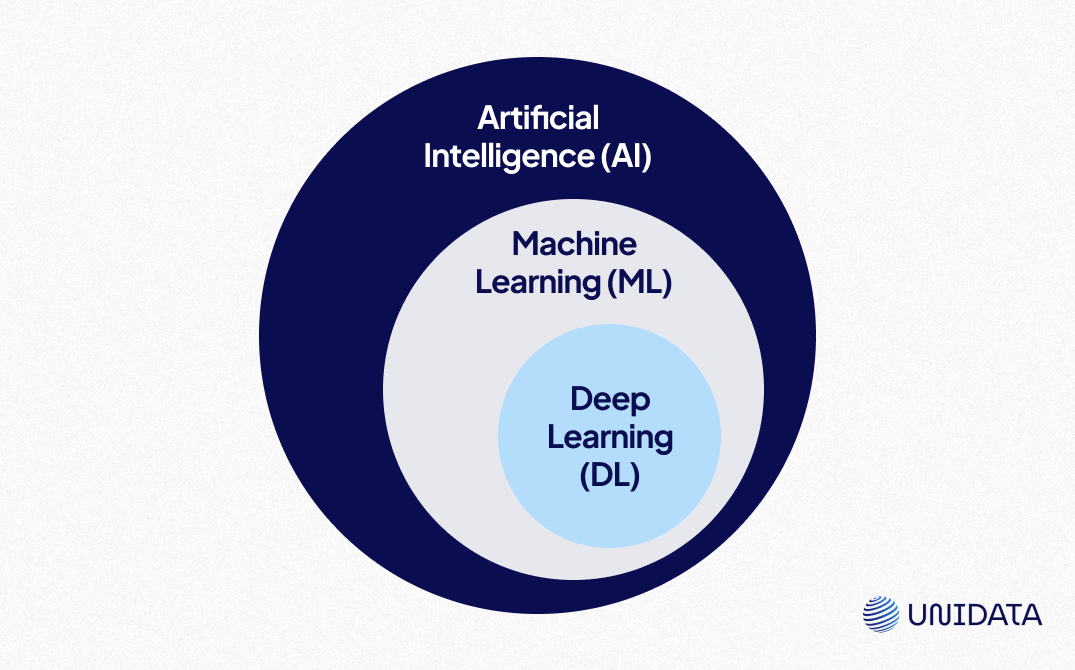
Understanding the distinctions between Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) is crucial in the AI model training process.
Artificial Intelligence (AI)
AI is the umbrella term that includes all technologies that aim to simulate human intelligence. It encompasses everything from basic automation to complex decision-making systems. AI models are designed to mimic human cognitive functions such as problem-solving, reasoning, and learning.
Machine Learning (ML)
Machine learning is a subset of AI that involves algorithms that allow computers to learn from data without being explicitly programmed. ML models improve their performance by identifying patterns in the data and making predictions based on them. ML is broadly classified into supervised learning, unsupervised learning, and reinforcement learning.
Deep Learning (DL)
Deep learning is a subset of ML that uses artificial neural networks to model complex patterns in large datasets. DL has become the go-to technique for tasks like image recognition, natural language processing, and voice recognition due to its ability to handle vast amounts of data and learn from it at scale. Deep learning models, particularly deep neural networks, can automatically extract features from raw data and improve their accuracy over time.
What Is an AI Model?
An AI model is a mathematical construct or algorithm that learns from data to make predictions or decisions without human intervention. It is the result of training an algorithm using specific datasets, and it can be fine-tuned to perform various tasks such as classification, regression, recommendation, or anomaly detection.
AI models are typically built on neural networks, decision trees, or other machine learning algorithms. They can be used to perform real-world tasks like predicting customer behavior, diagnosing diseases, or recommending products.
The Value of AI Models in Business
AI models offer immense value to businesses across various industries by enabling more informed decision-making, enhancing productivity, and driving innovation. Here are a few key benefits:
- Improved Decision-Making: AI models can process vast amounts of data quickly and provide insights that might be missed by human analysts. For instance, AI models in finance can predict stock trends, and AI in healthcare can help doctors diagnose diseases more accurately.
- Cost Savings: By automating repetitive tasks, AI models reduce labor costs and streamline operations. In sectors like manufacturing and customer service, AI-powered robots and chatbots can handle routine tasks, allowing human workers to focus on more complex problems.
- Personalization: AI models enable hyper-targeted personalization. For example, AI in marketing uses customer data to create personalized recommendations, improving customer experience and driving sales.
- Scalability: AI models can process vast amounts of data quickly, making it easier to scale operations and implement automation across large organizations.
Types of AI Training Methods
Training an AI model involves teaching it to learn patterns from data. Depending on the type of data and the problem being solved, different training methods can be employed. Here are the primary types:
1. Supervised Learning
Supervised learning uses labeled datasets where each input has a corresponding output. The model learns by comparing its predictions to the known labels and adjusting accordingly. It is commonly used for:
- Classification: Identifying categories, such as spam detection in emails.
- Regression: Predicting numerical values, like forecasting house prices.
What is Supervised Learning?
Learn more
2. Unsupervised Learning
Unsupervised learning deals with unlabeled data. The model identifies patterns, clusters, or structures within the dataset on its own. Applications include:
- Clustering: Grouping similar data points, such as customer segmentation.
- Dimensionality Reduction: Simplifying data while retaining important features.
3. Reinforcement Learning
Reinforcement learning (RL) involves training a model to make decisions through trial and error in an environment. The model receives rewards or penalties based on its actions, learning to maximize rewards over time. RL is widely used in:
- Robotics: Training robots for complex tasks.
- Gaming: Teaching AI agents to excel in games like chess or Go.
- Autonomous Vehicles: Enabling cars to make real-time decisions.
Steps of AI Model Training
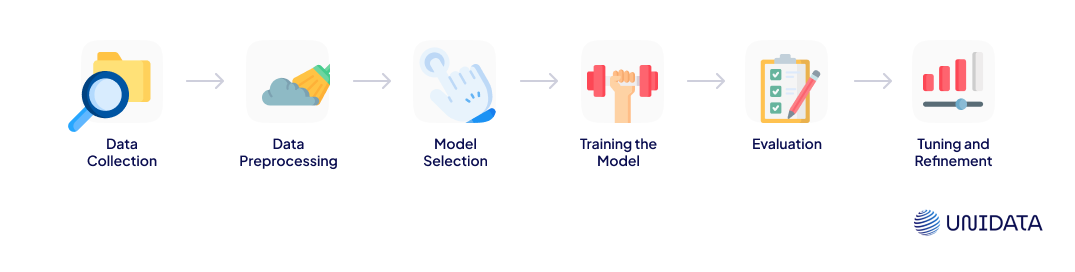
The AI model training process can be broken down into several key steps. Each stage is crucial in ensuring the model performs optimally:
1. Data Collection
The first step in training an AI model is collecting relevant data. The quality and quantity of data directly impact the model’s performance. It’s essential to gather a diverse dataset that covers all possible scenarios to avoid bias and underfitting.
2. Data Preprocessing
Once data is collected, it must be cleaned and transformed. This process includes handling missing values, normalizing data, encoding categorical variables, and dealing with outliers. Preprocessing ensures that the data is in a format that the model can understand and learn from.
3. Model Selection
After preprocessing, the next step is choosing the right algorithm for the task at hand. For example, for classification tasks, decision trees, support vector machines, or neural networks might be used. For regression tasks, linear regression or random forests may be chosen. The model selection depends on the data type, size, and the problem being solved.
4. Training the Model
With the data prepared and the model selected, the next step is to train the model. This involves feeding the training data to the model and adjusting the model’s parameters through a process called optimization. This step involves minimizing the error between the model’s predictions and the actual results using techniques like gradient descent.
5. Evaluation
After training, the model’s performance is evaluated using testing data. This ensures that the model can generalize to new, unseen data. Evaluation metrics such as accuracy, precision, recall, and F1-score are used to assess the model’s effectiveness.
6. Tuning and Refinement
If the model's performance isn’t satisfactory, fine-tuning may be necessary. This could involve adjusting hyperparameters (e.g., learning rate, regularization) or using advanced techniques like cross-validation to improve model generalization.
Best Practices for Model Training
To ensure successful AI model training, it’s important to follow best practices that optimize performance:
- Ensure High-Quality Data: Data quality is paramount. Ensure that your data is accurate, relevant, and representative of real-world scenarios. One effective approach is to invest in data curation — the process of organizing, validating, and enriching raw data before training.
- Avoid Overfitting: Use techniques such as cross-validation to prevent the model from memorizing training data, which can reduce its ability to generalize.
- Use Feature Engineering: Feature selection and engineering help improve model performance by identifying the most important variables that affect the target outcome.
- Hyperparameter Tuning: Fine-tuning model hyperparameters can significantly improve performance. Use techniques like grid search or random search for optimal hyperparameter selection.
Role of Data in AI Model Training
Data is the lifeblood of AI model training. Without data, AI models cannot learn or make predictions. The better the data—clean, labeled, and diverse—the more accurate the model will be.
Key considerations for data in AI training include:
- Data Labeling: For supervised learning, labeled data is necessary for training. Inaccurate labels can lead to poor model performance.
- Data Diversity: The more diverse the dataset, the better the model will perform on real-world data. Ensure the data covers all edge cases to avoid bias.
- Data Quality: High-quality data is essential for accurate predictions. Clean the data by removing noise, correcting errors, and dealing with missing values.
Challenges in AI Model Training
Training AI models comes with its share of challenges. These include:
- Data Limitations: Insufficient or poor-quality data can prevent models from learning accurately. Additionally, unbalanced datasets may lead to biased results.
- Computational Costs: Training large models requires significant computational resources. Cloud-based solutions can help mitigate costs, but they still require careful management of resources.
- Model Complexity: As models grow more complex, understanding and interpreting them becomes more difficult. This can affect transparency and trust in AI decision-making.
Most Popular Frameworks for AI Model Training

AI model training requires robust frameworks that streamline the development process and enable efficient learning from data. Here are some of the most popular frameworks for AI model training, known for their capabilities and community support:
1. TensorFlow
Developed by Google, TensorFlow is one of the most widely used frameworks for AI and deep learning. It offers:
- Scalability: Supports distributed training and deployment across multiple platforms.
- Flexibility: Provides tools for beginners and advanced users, including Keras for easy model building.
- Community and Support: A vast ecosystem of libraries and active community support.
2. PyTorch
Favored by researchers and developers, PyTorch (developed by Facebook) is known for its:
- Dynamic Computation Graphs: Allows flexibility during model training.
- Ease of Use: Simple syntax makes it beginner-friendly.
- Integration: Works seamlessly with Python libraries.
3. Scikit-learn
Ideal for beginners and traditional machine learning tasks, Scikit-learn provides:
- Wide Range of Algorithms: Supports classification, regression, and clustering.
- Ease of Implementation: User-friendly API for data preprocessing and model training.
- Integration: Works well with NumPy, SciPy, and pandas.
4. Keras
A high-level API for building and training neural networks, Keras is:
- User-Friendly: Simplifies model building with minimal code.
- Built on TensorFlow: Provides the best of TensorFlow's backend power.
- Suitable for Beginners: Easy to prototype and experiment.
Conclusion
AI model training is a complex but rewarding process that is at the core of all AI-driven innovations. By understanding the concepts of AI, ML, and DL, and following best practices in data collection, model selection, and training, businesses can harness the full potential of AI to drive decision-making, improve efficiency, and create personalized experiences. While challenges such as data limitations and computational costs exist, careful planning and the right tools can overcome these hurdles. With AI continuing to evolve, mastering model training is a valuable skill for any data-driven organization.