Introduction to Data Annotation
Data annotation is one of the greatest achievements in machine learning (ML) as of late. It's a process of annotating data with relevant tags to make it more comprehensive for computers. Data annotation transforms unorganized data into structured input, paving the way for machine learning and AI.
Processing this data is often time-consuming and takes a toll on the workload. It was carried out manually for a long time until data annotation automation was developed. Automatic annotation has significantly changed how companies handle and analyze vast datasets. This leap forward is about enhancing speed and unlocking new possibilities in data processing and model training, setting the stage for more sophisticated and capable AI systems.
Let's dive deeper into the world of automatic data annotation to find out what tasks you can automate and what should be left to human annotators. We’ll also discuss the best tools and techniques for auto-annotating as well as specific industries where automatic annotation is being successfully employed.
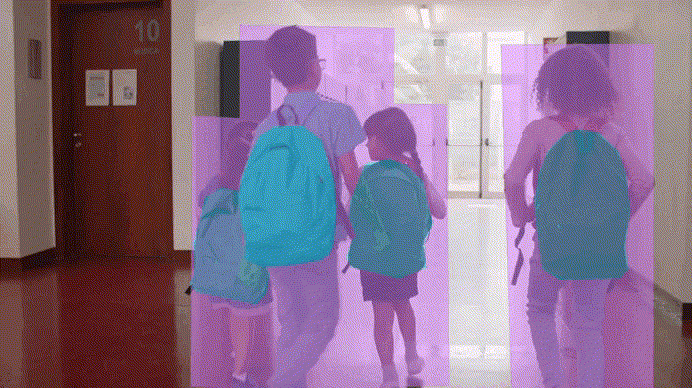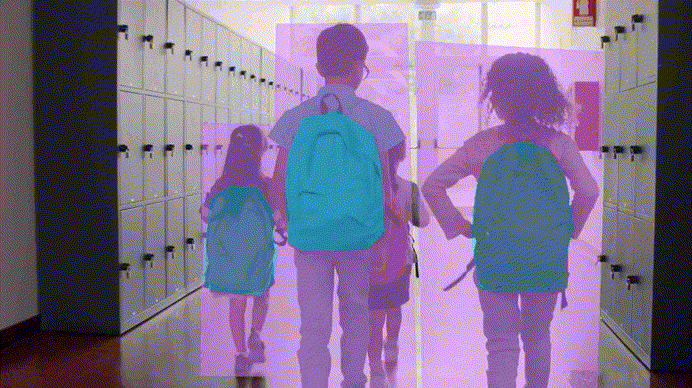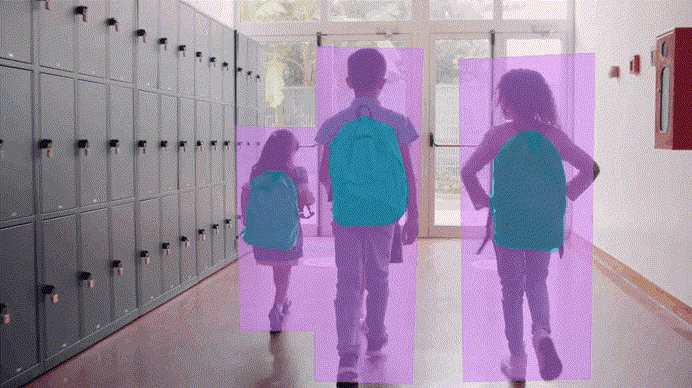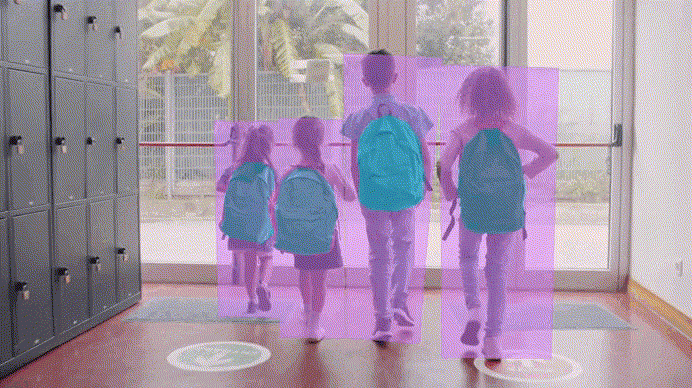
The Process of Data Annotation
Data annotation consists of the following steps:
- Сollection of raw, unstructured data and its preparation.
- Annotation – markings are added to the data to indicate the features or outcomes that the model should learn.
- Quality Control – annotated data is checked for accuracy and consistency.
- Data Splitting – the annotated data is divided into training, validation, and test datasets for machine learning model development.
- Iteration – data annotation is revisited and refined based on model performance and feedback.
Types of Data Annotation
Data annotation comes in many forms, adjusted for specific AI needs:
Image Annotation
This type of annotation is key to computer vision projects. It's used to annotate elements within photos, like objects and shapes. This allows models to read and assess visual data accurately.
Text Annotation
During this process, written data gets tagged for sentiment analysis, entity recognition, and more. Text annotation sets the stage for NLP models to understand and replicate human language effectively.
Audio Annotation
This involves annotating audio data via transcripts, speaker IDs, and specific sound types. It's used extensively for voice recognition and audio analysis applications.
Video Annotation
Video annotating is a mix of sound and image annotation. It includes marking objects, tracking their movement across frames, recognizing actions or events, and annotating specific attributes or actions of subjects within the video.
Manual VS Automatic Data Annotation
| Feature | Manual Data Annotation | Semi-Automatic Data Annotation |
|---|---|---|
| Accuracy | High, especially with expert annotators for complex tasks | May be lower than manual but can be improved with AI advancements. A system for continuous model retraining is essential to improve accuracy. This allows algorithms to learn from their mistakes and gradually enhance their performance over time |
| Speed | Slow due to the need for human effort | Fast – machines can process large datasets quickly |
| Cost | High due to labor costs | The cost varies depending on the data scale and involves the one-time cost of automation model creation, maintenance, and support expenses |
| Scalability | Limited by human resources available | Highly scalable in case of simple tasks such as classification or annotation with binary questions like “Yes or No” |
| Flexibility | High – humans can adapt to complex and nuanced tasks | Lower – it depends on predefined algorithms and models. The introduction of AI increases the flexibility and adaptability of automatic annotation (e.g., ChatGPT). |
| Consistency | Can vary due to human factors | High |
| Feedback Loop | Can be slow – involves retraining or rebriefing human annotators | Quick – algorithms can be adjusted and immediately applied |
| Data Security | Potential risk with sensitive data handled by humans | Reliable |
How is Data Annotation Done Manually?
Manual data annotation takes careful work. Human annotators go through each piece of data, marking it one by one. Manual work is excellent for making accurate, consistent tags, especially for tricky cases that computers might miss. The downside? It's slow, costly, and challenging to scale, especially for large datasets.

So when choosing between manual vs automatic annotation, it is important to weigh out all the pros and cons for a specific use case. For example, in medical use cases primarily in MRIs and CT scans, manual annotation can save lives. Medical diagnostics heavily rely on manual human interpretation and annotation to ensure accuracy.
Test data annotation is another use case, where manual annotation will help more than automation. These data will be used to train ML algorithms, and if the test data is inaccurately annotated or contains errors, the ML models’ performance will also be inaccurate, leading to imprecise predictions.
How Does Automatic Data Annotation Work?
Automatic annotation involves using AI-powered tools to streamline the data annotation process. This method enhances manual efforts by providing preliminary annotations to datasets.
It is important to note that fully automatic data annotation is a rare and currently ineffective approach; human involvement in validating annotations and refining the auto-annotation model is crucial. Therefore, in this article, we will primarily mean semi-automatic annotation when we refer to automatic annotation.

The Benefits of Automatic Annotation
Speed
The main advantage of automation is the ability to analyze large amounts of data in a short time. Automatic annotation expedites business processes, alleviates the workload, and facilitates rapid scale-up. Automated tools can accelerate data annotating by 40-60%, reducing project timelines significantly for companies developing complex ML models.
An observation from Unidata projects shows that in object detection tasks, automatic annotation has doubled the speed of annotation compared to manual methods.
Cost-effectiveness
Automatic data annotation cuts costs spent on manual labor. In projects that require specialized experts to annotate data, teams can cut costs by 50-70%.
However, if it's a small data sample and a small dataset, then it may not be cost-effective. For image classification, manual annotation can be feasible for 10,000 images, while implementing automated annotations for 10 million images is a smarter choice.
It's important to understand that the cost-effectiveness of both manual and automated annotation should be considered for each use case individually.
Automated data annotation costs involve:
- The auto-annotation tool developer
- The validator
- Tasks related to refining the model
You can always compare this with manual annotation, where only annotators are involved, and calculate the cost of annotating one image with and without automation, taking into account the rates of the people involved in the annotation process.
Consistency
When using manual data annotation, one can't eliminate the "human factor" – human annotators tend to make mistakes and carry out inconsistent tagging. The great benefit of an automated solution is that it generates the same tags given the same data. This ensures a more dependable, trustworthy annotation process.
Of course, the cost can be minimized by having the same data annotated by ten different annotators and then aggregating the results. However, this approach will take longer and be more expensive.
A significant advantage of an automated solution is that it generates consistent tags based on the same data, ensuring a more reliable and accurate annotation process.
Automatic models may make mistakes in complex cases, while humans may make errors not only in difficult situations but also due to fatigue and inattentiveness (the human factor).
The process typically involves automatically annotating the data, sending it for manual validation, identifying where the model makes errors, refining the model's algorithms, and then repeating the automatic annotation. This cycle continues iteratively.
Auto Annotation Challenges
It's important to note that automatic annotation is not without its drawbacks. Here are the main challenges with auto-annotation:
An Automated Annotation Model Creation Costs
developing the initial model for automatic annotation is time-consuming and expensive. Complex LLM (Large Language Models) require hundreds of thousands of hours of training. In contrast, tasks for training a simple classification model, such as distinguishing between cats and dogs, are typically completed in about a day. The project scale directly impacts the project costs.
A Specific Model for Each Dataset
When using automatic annotation, the quality of annotations depends on the compatibility of an existing model with the data you want to annotate. If your dataset significantly differs from the one the model was trained on, the annotation quality may be reduced.
Maintenance Costs
In case your auto annotation model needs customization to match the dataset you need to annotate, you will need to factor in additional spending. You may need to either update the model to match the requirements or add manual labor to edit the annotations.
Accuracy
All automation models are prone to making mistakes. To effectively use any auto-annotation system, the involvement of manual validators is important. The more complex the automatic annotation models we have, the higher the quality and the longer the validation process needs to be to identify errors.
All in all, the choice between manual and automated annotation depends on the project itself. While manual annotation offers unmatched accuracy for complicated tasks, auto annotation offers scalability and efficiency essential for handling large datasets. The best approach, covering all the issues that might arise, combines both manual labor and automated solutions.
Auto Annotation Processes
There are many approaches to building automatic data annotation processes. Below you can find the main ones.
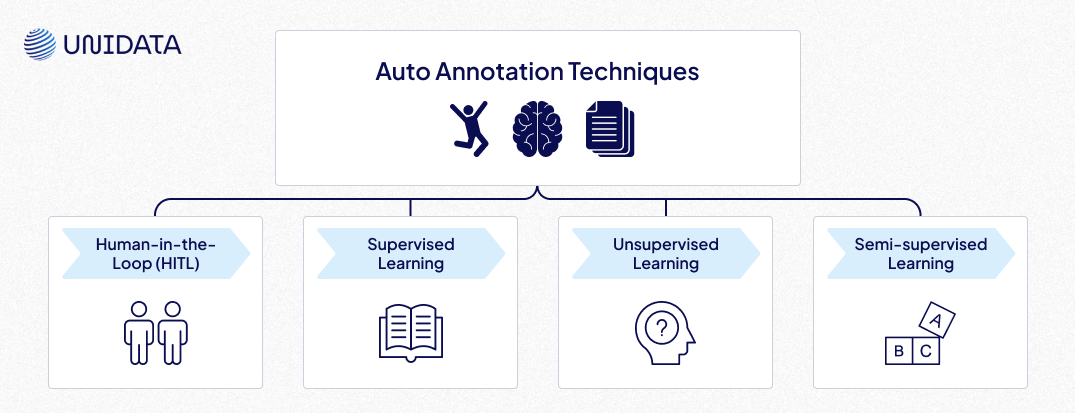
Human-in-the-Loop (HITL)
HITL introduces a collaborative framework between human annotators and AI systems to enhance the annotation process. HITL is practically identical to semi-automated data annotation. The model is initially trained on an annotated dataset and then used to annotate new data. Then human annotators review the results, correct errors, and offer detailed insights that fully automated systems might overlook. This process continues, improving the model's performance.
HITL is used in complicated annotation projects like sentiment analysis or medical image annotation, where human expertise is essential for providing accuracy and credibility.
This method continuously upgrades the model’s accuracy and the quality of annotation, combining human intuition and knowledge with the scalability that machine learning models offer.
HITL is very time-consuming and costly due to human involvement. Moreover, it’s highly dependent on the expertise and availability of human annotators, which can often be tricky.
Supervised Learning
This is one of the basic types of HITL as it entails human involvement and a feedback loop. This method is widely acknowledged as the most popular auto annotation technique. It depends heavily on annotated datasets to train models. It learns from a set of given examples, meaning the data needs to be high-quality and perfectly tagged.
During the process of supervised learning, individuals working as image, video, or text annotators are responsible for assigning specific markings or categories to the data based on what it represents. For instance, in a task involving image annotation, each image receives a tag corresponding to its classification, such as "house," "car", "cat", and so forth. This meticulous annotation process supports the algorithm in understanding how to correctly match data features with suitable categories.
It's great for projects where the link between the input data and the output tags is well-defined – such as image classification and speech recognition.
Supervised learning offers high accuracy when trained with a sufficiently extensive dataset and a clear understanding and control over the learning process.
The tricky part is that it requires large-scale and accurate data annotation, which can be time-consuming and expensive. Moreover, a model's accuracy highly depends on the manual work done by human annotators, the quality, and the quantity of annotated data.
Unsupervised Learning
Unsupervised learning is about exploring raw data to find hidden patterns or relationships within. It doesn't rely on already annotated data – instead, it identifies structures, patterns, and features within the given data itself.
Unsupervised Learning is based on grouping similar data points through clustering (e.g., K-means, hierarchical clustering) and association (e.g., Apriori, FP-growth).
Currently, this method allows for achieving greater accuracy due to the availability of large volumes of data. Unsupervised learning has access to vast amounts of data, while supervised learning is limited to a smaller dataset.
Supervised learning can achieve high accuracy on a limited dataset. For example, to reach a certain level of accuracy with supervised learning, you might need 1 million labeled images. To achieve similar accuracy with unsupervised learning, you might require 1 billion images.
It’s suitable for grouping similar data points or reducing the number of variables in a dataset. Unsupervised learning is particularly valuable for exploratory data analysis, anomaly detection, and grouping data when no tags are available – e.g.in customer segmentation or gene sequence analysis.
Unsupervised learning eliminates the need for manual data annotation, cutting costs significantly. This technique can also discover unexpected patterns or relationships within the data that were not previously considered by human annotators.
At the same time, since there are no predefined tags to guide the process, the results might come off as ambiguous and hard to interpret.
Semi-supervised Learning
This technique is a combination of supervised and unsupervised learning. It uses a minimal amount of annotated data alongside a larger pool of raw data.
Semi-supervised learning is also related to the HITL as it contains a feedback loop and manual validation of the automated labels. The model is initially trained on annotated data, then it’s asked to make predictions on raw datasets. These predictions, along with confidence scores, are used to gradually expand the annotated dataset and, simultaneously, improve the model.
Semi-supervised learning is usually employed when data annotation appears to be expensive or time-consuming, as this method can significantly reduce the need for extensively annotated datasets. It’s often used in image recognition or natural language processing tasks.
As mentioned, semi-supervised learning requires fewer annotated examples, which reduces the cost and time spent on manual work. Also, the use of both raw and tagged data can help improve the accuracy of models.
The drawback of this method is the fact that its accuracy depends on the small annotated dataset and there’s a risk of reinforcing incorrect predictions in a model.
For example, we have 1 billion images, and 1 million of them are already annotated. We train an automatic annotation model based on the 1 million annotated images. Using the trained model, we predict (automatically annotate) another 1 million images from the remaining dataset. After that, we validate the automatically annotated images, further train the annotation model, check its accuracy, and continue refining it as needed.
Since we don’t have independently, manually annotated data of our own, there’s a risk that the auto-annotation model might perform worse because it is trained on data with uncertain or unclear annotations.
Programmatic Data Annotation
This type of data relies on data scientists or similar specialists to create scripts that can automatically apply markings to data. Programmatic data annotation applies algorithms to generate tags for large datasets, significantly reducing the manual effort involved in the annotation process.
This approach is useful when the data follows consistent patterns that can be captured – e.g. categorizing news articles by topic based on keywords or tagging social media posts based on sentiment indicators.
This method uses guidelines based on expert knowledge in the field to mark datasets for specific tasks. It’s fast and can be highly accurate. Still, the annotations' quality depends on how precise these guidelines are. Therefore, a careful balance between automated and manual work is necessary to ensure the data's reliability.
Auto Annotation Techniques Overview
| Auto Annotation Technique | Short Overview | What is it used for? | Pros | Cons |
|---|---|---|---|---|
| Human-in-the-Loop (HITL) | Integrates human expertise with AI to improve annotation quality | Used in complex tasks like sentiment analysis or medical imaging, where human insight is crucial | Continuously improves the model’s accuracy and the quality of annotation | Time-consuming and costly due to human involvement |
| Supervised Learning | Relies on annotated datasets to train models | Tasks with clear input-output relationships, like image classification and speech recognition | High accuracy when trained on large datasets; control over the learning process | Requires large-scale and accurate data annotation; accuracy highly depends on the manual work |
| Unsupervised Learning | Identifies patterns in raw data | Grouping data points or reducing variables in datasets, e.g., e.g.in customer segmentation or gene sequence analysis | Eliminates the need for manual data annotation; can also discover unexpected patterns / relationships | Results might come off as ambiguous and hard to interpret |
| Semi-supervised Learning | Uses a small amount of annotated data and a bigger pool of raw data, reducing the need for extensive datasets | Suitable when annotation is expensive or time-consuming, blending supervised and unsupervised learning benefits | Requires fewer annotated examples; both tagged and raw data can help improve the accuracy of models | Accuracy depends on the small tagged dataset and there’s a risk of reinforcing incorrect predictions in a model |
Auto Annotation Case Studies
The introduction of automated data annotation has revolutionized the way different industries handle large amounts of data. Auto annotation has fast-tracked workflow in several fields – some examples include the healthcare industry, manufacturing, and retail.
Automated Data Annotation Cases Across Different Industries
Automated Data Annotation in Healthcare
In healthcare, the precision and dependability of data are particularly critical. Automated annotation has improved medical image analysis, helping diagnosis and disease detection. DICOM (Digital Imaging and Communications in Medicine) is a unique tool that facilitates automated annotations in medical images and videos. This instrument helped reach tremendous achievements in cancer detection and ultrasound imaging.
Nevertheless, involving medical experts in the pre-annotation and QA is essential, given the complex and nuanced nature of medical data.
Promising steps have been made in the medical field concerning automated detection of poor-quality data. According to a study, an automated system, UDC, has proven to be impressively precise in handling datasets with big levels of incorrect tags. With datasets containing up to 50% incorrect markings in one class and up to 30% incorrect markings across all classes of data, UDC remained effective. The system's ability to identify and remove 88% of intentionally mislabeled images showcases its potential to increase the reliability of automatically annotated data used in healthcare.
Auto Annotation in Manufacturing

In manufacturing, computer vision models need correctly annotated images to identify flaws, optimize production lines, and automate quality control. Predictive maintenance algorithms are used to diagnose faults, estimate service needs, and alert engineers, thereby preventing costly machinery failures and production losses.
Automated data annotation tools allow manufacturers to quickly tag images of components, machinery, and assembly processes, saving time and cost of manual annotation. This makes the manufacturing process efficient and improves flaw detection accuracy, contributing to higher-quality products and reduced waste.
Automated Annotation in Retail

In retail, auto annotations are used to keep track of inventory and improve the customer experience. By automating the annotation of product images and videos, retailers can efficiently manage their online catalogs, making sure that products are correctly annotated and easily searchable for customers. Automated annotations also enable more detailed customer analytics, helping retailers better understand shopper behavior and preferences.
By investing in customer analytics, retail companies can increase average order values, improve operational efficiency, and create a more personalized shopping experience.
Automated Data Annotation Software
The automated annotation software you choose can remarkably shape the success of your AI and ML projects. If you can't decide between building your solution or opting for a ready-made one, let's weigh all the pros and cons.
Building vs. Buying Automated Annotation Solutions
The dilemma between building an in-house tool or purchasing a ready-made solution is critical for many ML and data operations leaders. Building an in-house tool can be resource-intensive, often taking several months, 6 to 18 months, and requiring considerable financial investment. The scope of features and tools can be extensive – it depends on the volume of data, the number of annotators, and the scale of your project. Moreover, an in-house annotation tool demands ongoing maintenance and updates.
On the other hand, buying automated annotation software can be notably more time- and cost-effective. Setting up a ready-made solution is only a matter of hours or days. You can choose a tool tailored to your specific case and data annotation needs, without the limitations of in-house engineering resources.
Multi-Speaker Audio Annotation for Banking
- Speech AI
- 20 hours of audio, 2 task types (segmentation and transcription)
- 4 weeks
What Features to Look for in an Annotation Tool?
When selecting an automated data annotation software, several features should be considered for it to meet a project's requirements:
AI-assisted annotation support: the tool should facilitate AI-assisted annotation to streamline the annotation process.
Compatibility with different data types: the annotation software needs to support various file types and formats relevant to the project.
User-friendly interface with collaborative dashboard: an easy-to-use tool that encourages collaboration among team members is vital for efficient project management.
Data privacy and security: data privacy and compliance are must-haves, especially in regulated industries like healthcare.
Customizable quality control workflows: the ability to customize QC workflows helps maintain high annotation standards.
Training data and model debugging features: tools should aid in identifying and fixing errors within the training datasets.
Best Software for Data Annotation
Nowadays, there are numerous automated data annotation software solutions. The right software can transform your workflow, streamline tasks, and ensure scalability. Take a look at the top 3 automatic data annotation solutions according to G2:
SuperAnnotate

This is the leading platform in automated data annotation, offering help in building, fine-tuning, iterating, and managing AI models with high-quality training data. SuperAnnotate can be of great help in fields such as autonomous driving, retail, healthcare, agriculture, and more since this software stands out for its ability to facilitate efficient auto annotation of images and videos. One of the key advantages of this software is the annotation services marketplace where customers can find the right annotation team according to their needs.
SuperAnnotate is also open-source, based on Python and auto annotates with bounding boxes. The ML models are pre-trained and TensorFlow repositories are also used for training. The final images and XML can be exported and opened in Labellmg.
This service has integrated MLOps capabilities: tools for dataset and model management and automation. SuperAnnotate is highly praised for its extensive range of annotation tools, supporting various data formats including images, videos, LiDAR, and audio.
SuperAnnotate is FREE for up to 3 users and 5.000 data items. The full software is available in “Pro” and “Enterprise” packages.
Encord

Encord’s approach to automating the annotation process revolves around its active learning platform equipped with a variety of tools that streamline the creation, management, and deployment of high-quality annotated datasets. The software intelligently selects data samples that will most improve the AI model's performance.
The software’s tools were built with ideas from quantitative research in financial markets in mind. Encord stands out for its focus on efficiency, collaboration, and scalability, making it a valuable resource for projects in various industries, especially in computer science and healthcare.
Encord focuses on active learning pipelines, automating the cycle of training, diagnosing, and validating models – this optimizes the annotation process and model development based on model feedback. The platform's flexible pricing options cater to different user needs, from free access and a “Team” package to enterprise solutions.
Kili

Kili is a platform with powerful quality control features – e.g. consensus validation and review workflows. This software, like SuperAnnotate and Encord, deals with a wide range of data types, including text, images, videos, and audio. Kili allows users to tailor the annotation process to their project’s specific requirements, which enhances the efficiency of data annotation.
The service uses custom automation within its annotation workflows, offering powerful QA features – consensus validation and review workflows. Automated consensus mechanisms reduce the manual effort involved in validating data annotations, streamlining the whole process.
The platform combines collaborative data annotation with data-centric workflows, automation, curation, integration, and simplified DataOps. Kili stands out with its user-friendly platform and intuitive design, relieving the learning curve for new users.
Kili subscription comes in 3 different price packages: a free version (up to 2 users and a 100 annotations limit), “Grow” and “Enterprise” plans.
Conclusion
Data annotation has undeniably revolutionized machine learning, shaping AI models to be more efficient and capable. While manual annotation offers unmatched accuracy, automatic annotation introduces speed, scalability, and cost-efficiency, making it an essential tool for handling vast datasets. However, the optimal approach often lies in a hybrid method—leveraging automation while ensuring human oversight for quality and accuracy.
As industries like healthcare, manufacturing, and retail continue integrating automated annotation, the demand for reliable tools and refined models will only grow. Whether building an in-house solution or adopting ready-made software, selecting the right annotation strategy is key to achieving AI-driven success. By striking a balance between automation and human expertise, businesses can unlock new levels of efficiency and innovation in the ever-evolving landscape of machine learning.