
DeepFake Videos Dataset
The deepfake dataset contains real and AI-generated deepfake videos, featuring diverse subjects with detailed metadata on age, gender, and ethnicity to help train powerful deepfake detectors
-
- files
- 5,000
-
- people
- 5,000

- Facial Recognition
- Computer Vision
- Machine learning
- Data generation
- Security
The deepfake dataset contains real and AI-generated deepfake videos, featuring diverse subjects with detailed metadata on age, gender, and ethnicity to help train powerful deepfake detectors
- Facial Recognition
- Computer Vision
- Machine learning
- Data generation
- Security
-
- files
- 5,000
-
- people
- 5,000
Dataset Info
| Characteristic | Data |
| Description | Real video of people with AI-generated faces, where individuals turn their heads in different directions |
| Data types | Video |
| Tasks | Facial recognition, Computer Vision |
| Total number of files | 5,000 |
| Number of people | 5,000 |
| Video generation sites | aisaver.io, faceswapvideo.ai, magichour.ai |
| Labeling | Metadata (age, gender, ethnicity) |
| Gender | Male, Female |
| Ethnicity | Asian (30%), African (70%) |
| Age | Min = 18, max = 80, mean = 45 |


attacks monthly
download our free white paper
Statistics
-
- Distribution by age
-
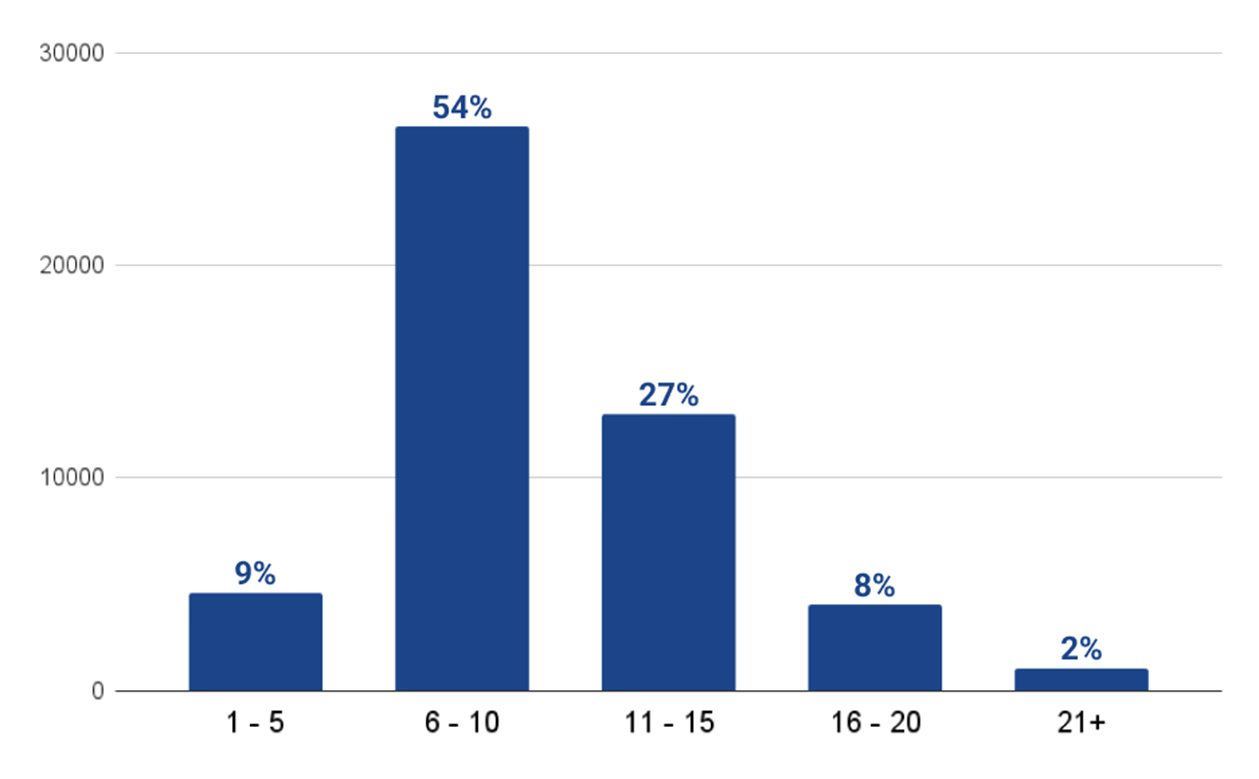
- Duration of the video duration
-

- Distribution by gender
-
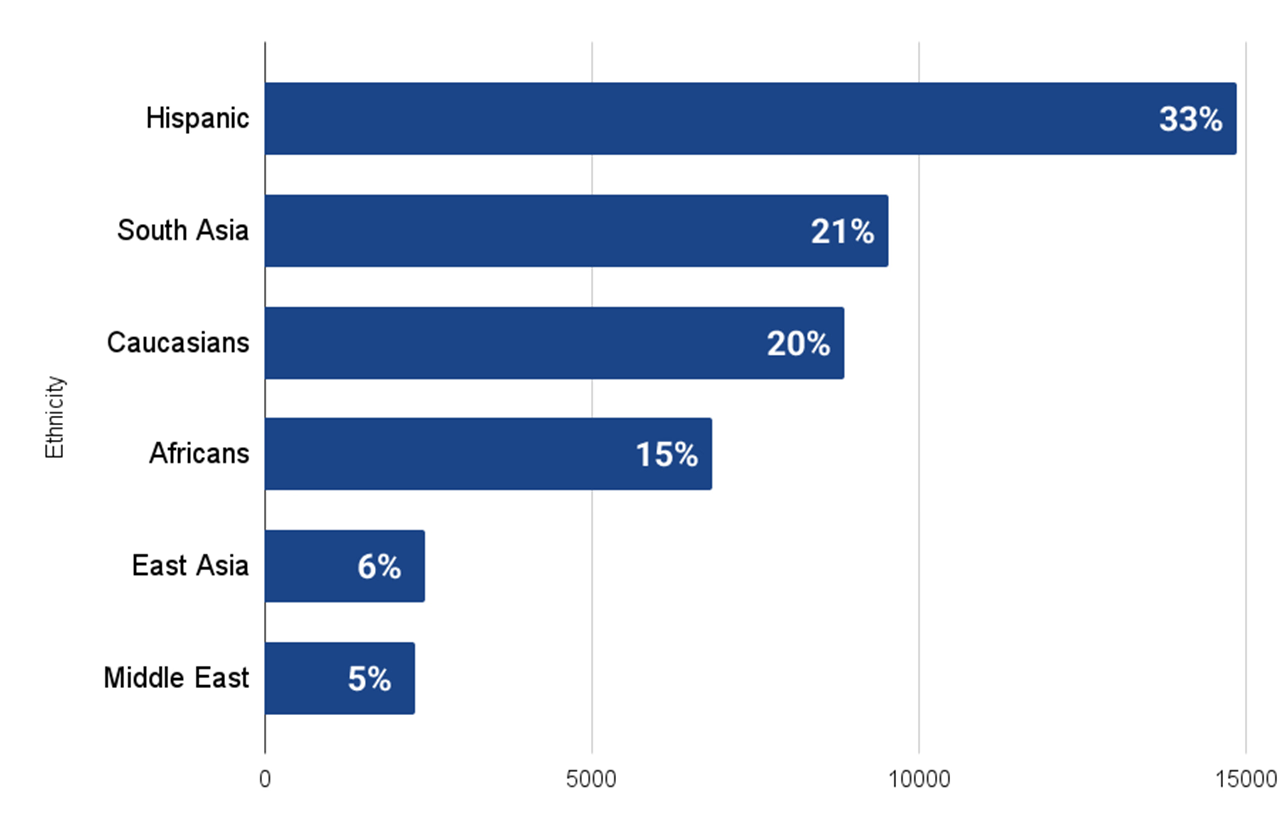
- Distribution by ethnicity
Technical
Characteristics
| Characteristic | Data |
| Video extension | mp4, MOV |
| Video Resolutions | 1920 x 1080p, 480 x 360p, 1280 x 720p, 720 x 480p, 640 x 480p, 1920 x 920p |
| Video duration | Mean = 9, median = 9, min = 2, max = 34 |
| Frames per second | Mean = 26.6 |
| Devices | iPhone 13 (30%), Google Pixel (70%) |
Dataset Use Cases
FAQs
Unidata Cases

Digital Tree Passport Annotation for Forest Mapping
- Forestry Monitoring & GIS
- 200,000 trees, 10 species classes
- 2 months

License Plate Annotation for Vehicle Recognition System
- 100,000 images with detailed license plate markup (bounding boxes, digits, regional symbols)
- 2 weeks
Sentiment Annotation for Brand Monitoring
- Marketing & Consumer Insights
- 12,000 text samples, 3 sentiment classes (positive, negative, neutral)
- 3 weeks

Surveillance Video Annotation for Entrance Monitoring
- Surveillance & Security
- 90 minutes of video from three cameras, approximately 50-60 thousand frames
- 2 week
Similar Datasets
-

 Commercial
Commercial
- Computer Vision
- Machine Learning
- Image Processing
- Security
- Anti-Spoofing
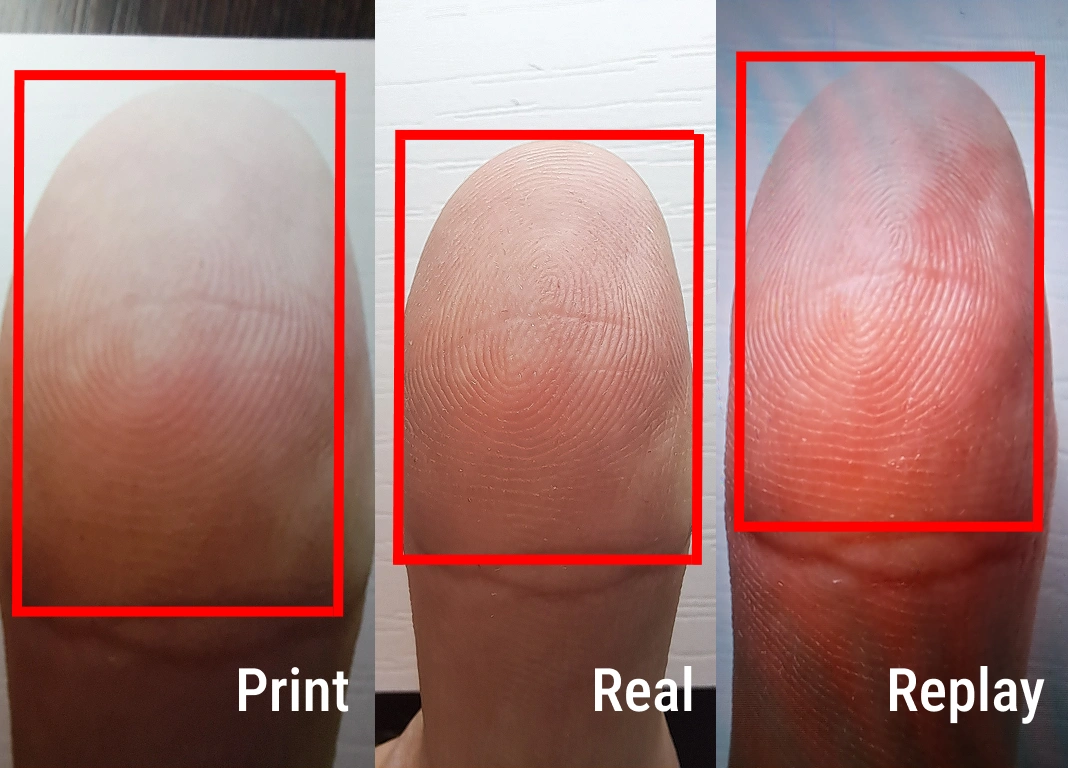
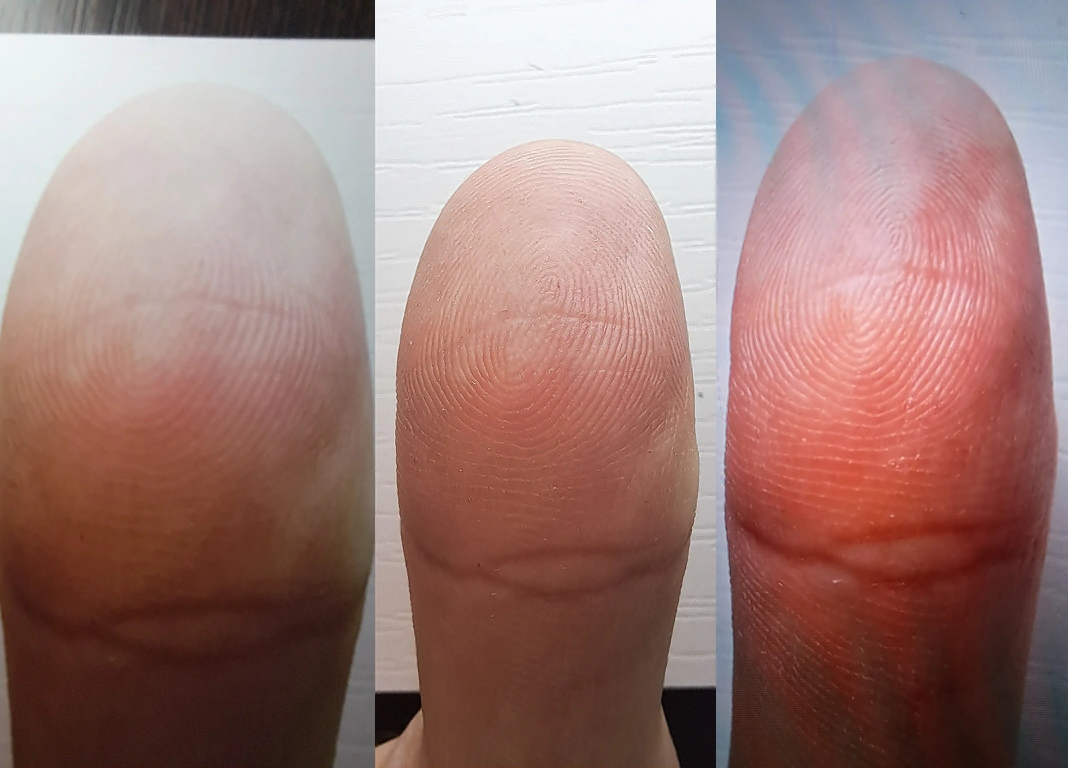
Multi-Material Fingerprint Spoofing Dataset
Multi-Material Fingerprint Spoofing Dataset contains 4,000+ fingerprint images from 100 individuals, captured with a ZKTeco ZK9500 optical scanner and including real fingerprints and spoofing attacks created with alginate, plasticine, and silicone materials. The fingerprint dataset includes metadata (gender, age, finger, hand, device) and supports biometric security research, presentation attack detection, spoof detection, and fingerprint recognition model training.
100 People
4000+ Photos -
 Commercial
Commercial
- Computer Vision
- Machine Learning
- Image Processing
- Security
- Anti-Spoofing
Biometric Fingerprint Spoofing Dataset
Biometric Fingerprint Spoofing Dataset contains 5,000+ high-quality fingerprint images capturing real fingerprints and multiple spoofing fingerprint attack types, including print and replay scenarios. Designed for spoofing detection and liveness detection tasks, the fingerprint dataset provides labeled biometric data from different devices and fingers to train and evaluate biometric security and fingerprint recognition systems.
100 People
5000+ Photos -

 Commercial
Commercial
- Facial Recognition
- Liveness Detection
- Security
- Anti-spoofing
- Computer Vision
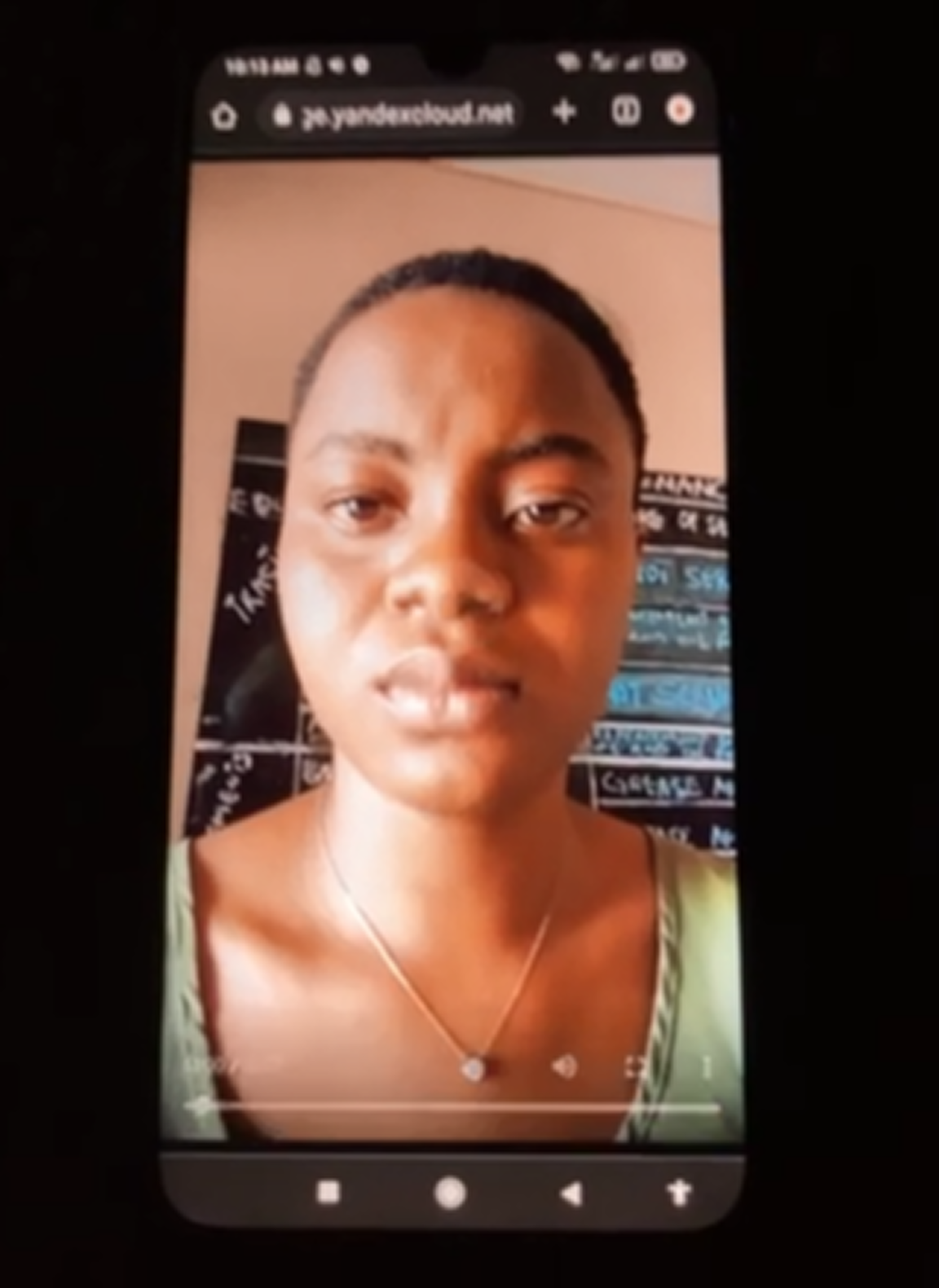
Anti-Spoofing Replay PC Videos Dataset
This is a high-quality replay attack dataset containing 4,714 PC-recorded video clips of real faces, designed for training and evaluating face recognition and liveness detection systems. This anti-spoofing videos dataset includes diverse attack scenarios, technical metadata (age, gender, ethnicity), and MP4/MOV formats to support spoofing detection, biometric security, and computer vision model development.
4,714 Videos
4,714 People -
 Commercial
Commercial
- Facial Recognition
- Liveness Detection
- Security
- Anti-spoofing
- Computer Vision
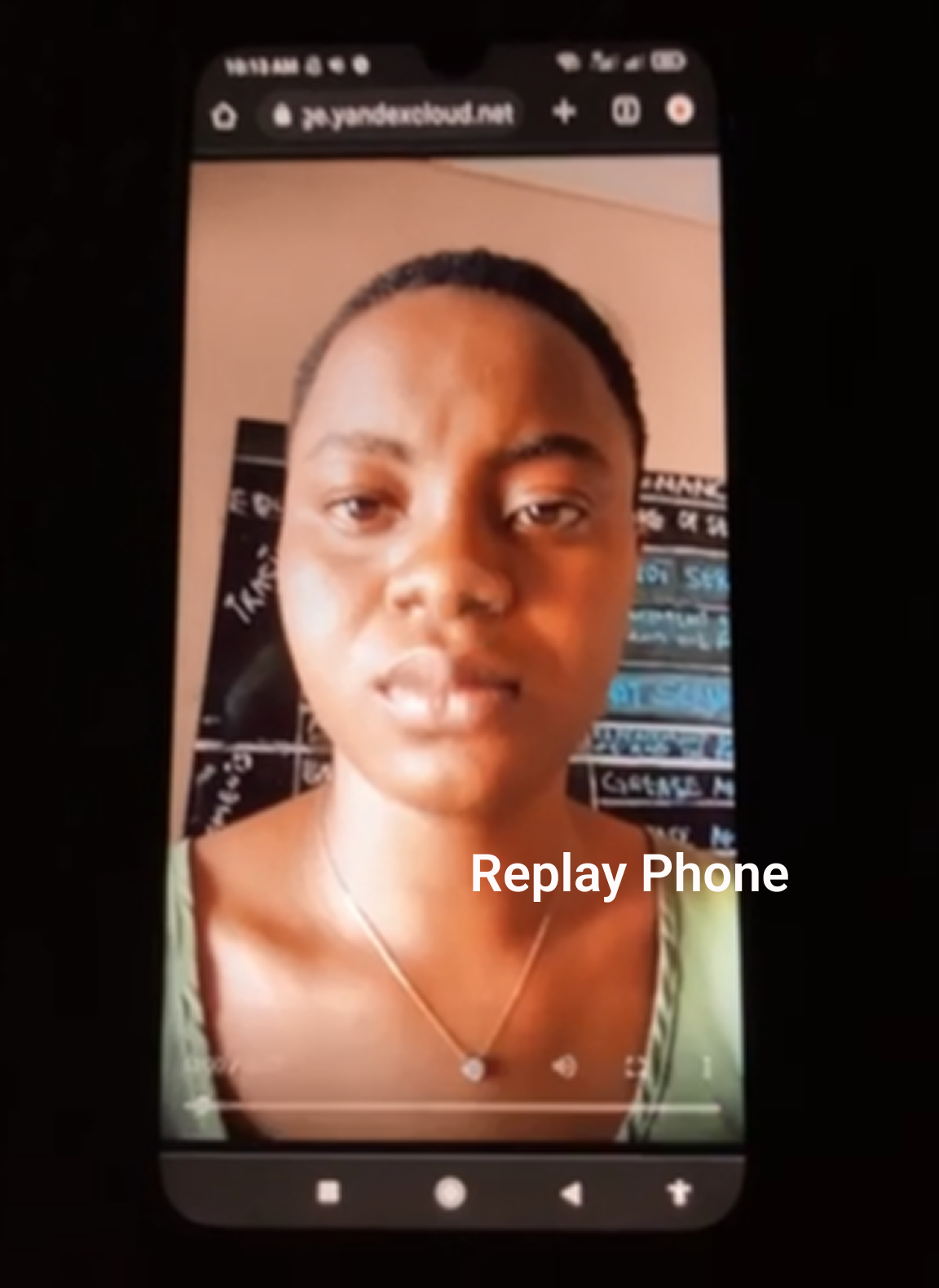
Anti-Spoofing Replay Phone Videos Dataset
This anti-spoofing dataset contains over 38,000 live facial video recordings captured on mobile devices to support replay attack detection and biometric anti-spoofing research. With paired video sets, MP4/MOV formats, and rich metadata such as age, gender, and ethnicity, it provides reliable training data for face antispoofing, liveness detection, and secure biometric authentication systems.
38,029 Videos
20,018 Sets -

 Commercial
Commercial
- Speech Analysis
- ASR
- Machine learning
- Data generation
- Audio Processing
Real vs Fake Human Voice – Deepfake Audio Dataset
Real vs Fake Human Voice – Deepfake Audio Dataset contains 5,000 audio files featuring both genuine human recordings and AI-generated voice samples. Each set includes four speakers with multiple clips across M4A and MP3 formats. The dataset supports research in deepfake detection, generated speech analysis, and real vs fake human voice recognition tasks.
5,000 Audio
-

 Commercial
Commercial
- Facial Recognition
- Security
- Anti-spoofing
- Computer Vision
- Machine Learning
Kids Anti-Spoofing Dataset
Kids Anti-Spoofing Dataset provides 6,000 high-quality facial images of children aged 7–15 for face anti-spoofing and liveness detection tasks. This child safety dataset supports research in biometric systems, helping improve facial recognition accuracy, detect spoofing attacks, and build safer AI models for protecting kids in digital and identification environments.
6 000 Images
300 people -
 Commercial
Commercial
- Image Processing
- Machine Learning
- Hand Recognition
- Forensics
- Computer Vision
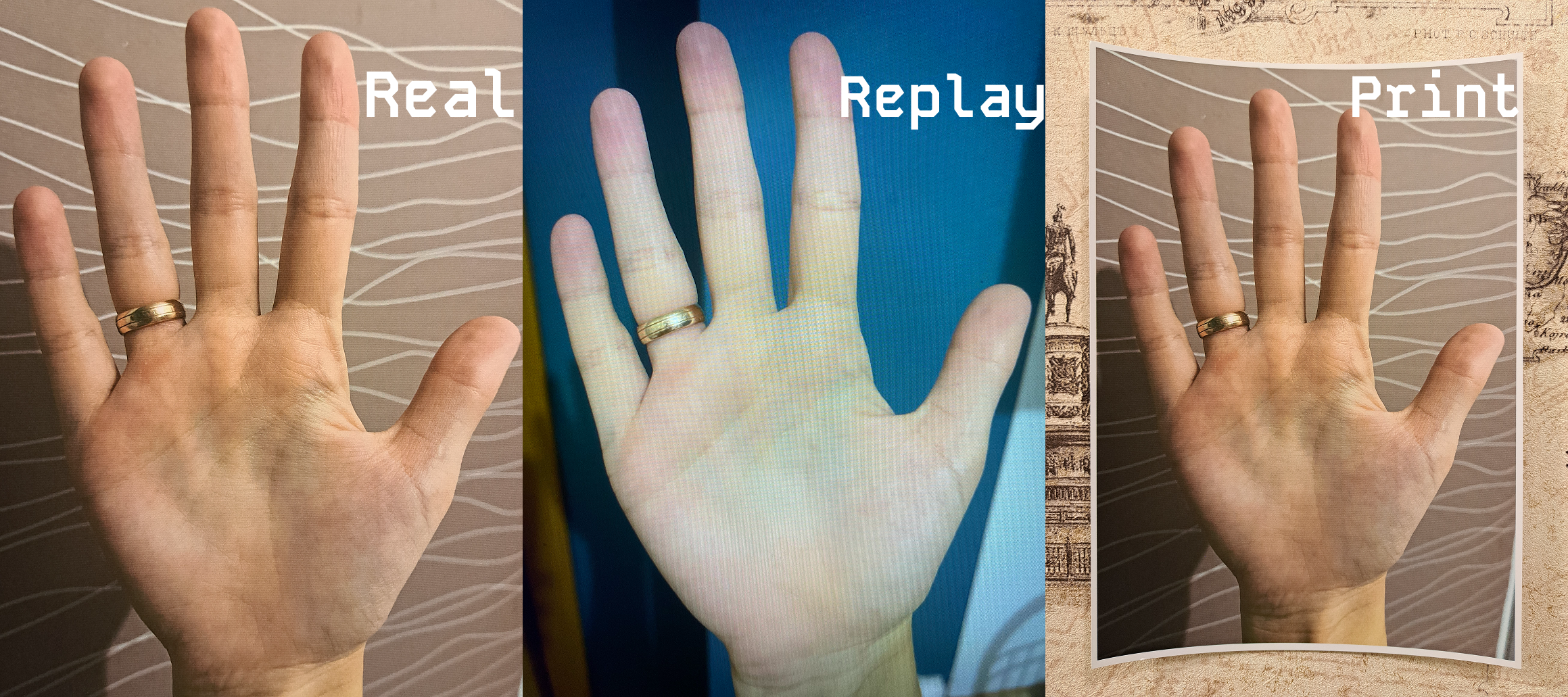
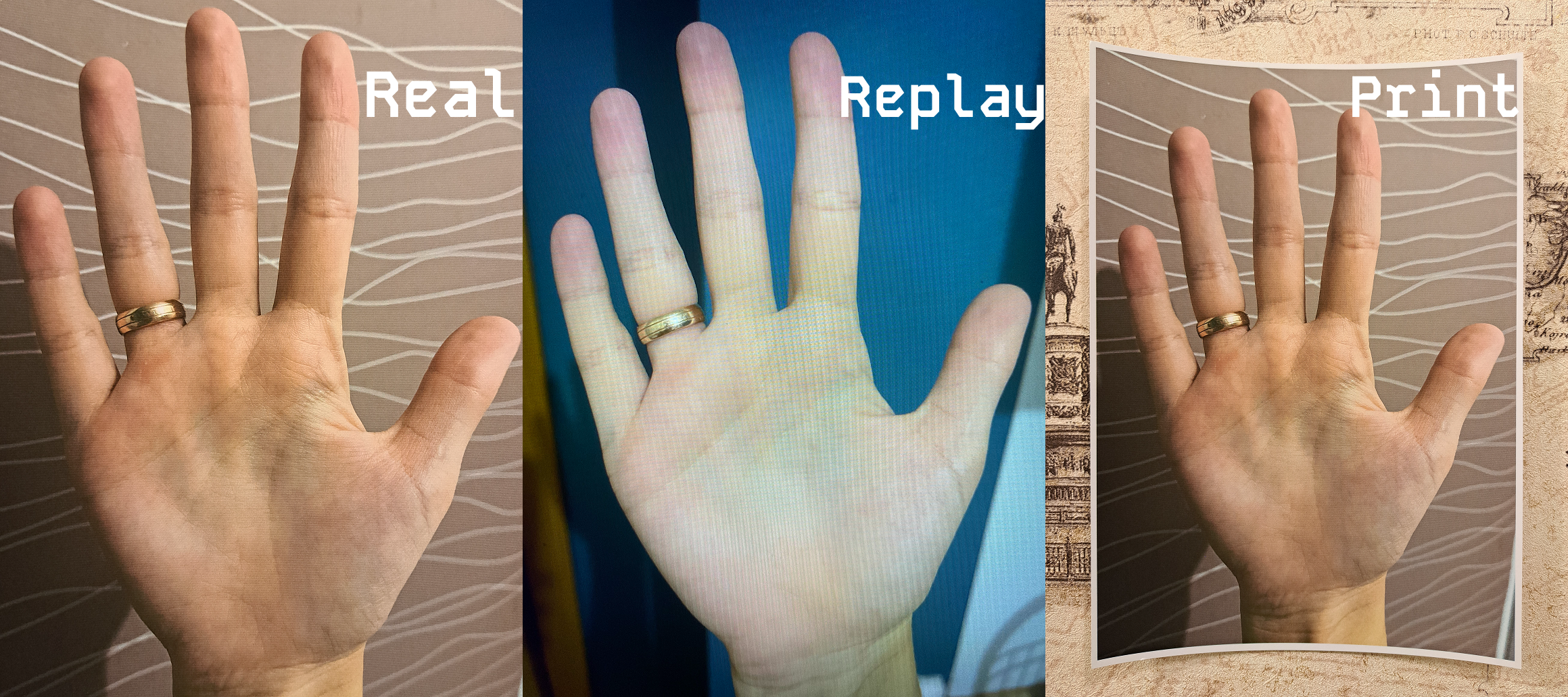
Open Palm Hand Images Dataset
This high-quality open palm dataset includes 500,000 annotated images collected from 50,000 people, with each set containing six palm photos, two printed-hand images, and two replay videos. Designed for hand recognition and computer vision research, it provides detailed metadata - age, gender, ethnicity, profession, device type, dominant hand, and jewelry status.
500,000 Images
50,000 People -

 Commercial
Commercial
- PII
- Data generation
- Security
- Anti-spoofing
- Computer Vision
Synthetic Printed Turkish Passports Dataset
It is a synthetic Turkish passports dataset containing 5,000 high-quality, AI-generated images. Labeled with detailed metadata - including passport ID, class, gender, and lighting - this dataset supports PII extraction, identity verification, and biometric recognition system training while maintaining strict data protection standards.
5000 Images
-

 Commercial
Commercial
- Facial Recognition
- iBeta
- Liveness Detection
- Security
- Anti-spoofing
- Computer Vision
iBeta Kids Dataset
iBeta Kids Dataset is a child safety dataset featuring over 46,000 short video samples of children across different age groups, recorded under varied lighting, devices, and conditions. It includes four main attack types - Real Person, 2D Mask, 3D Mask, and Replay - helping develop biometric systems that detect spoofing and ensure safe, accurate child identification.
45 600 Videos
60 People -

 Commercial
Commercial
- PII
- Data generation
- Security
- Anti-spoofing
- Computer Vision
Synthetic Printed German Passports Dataset
This German passport dataset provides 5,000 AI-generated synthetic passport images, engineered for training and benchmarking ML models in document analysis and PII extraction. It features high-resolution JPG samples with controlled variations across 3 angles, 4 lighting conditions, and 4 backgrounds, each annotated with detailed metadata including passport ID, gender, and age group for robust model development.
5 000 Images
Why Companies Trust Unidata's Datasets
Share your project requirements, we handle the rest. Every service is tailored, executed, and compliance-ready, so you can focus on strategy and growth, not operations.
What our clients are saying

UniData

Data purchase
Our team got in touch with UniData for purchasing video data. The team at UniData was transparent, timely, and pleasant to communicate and negotiate with. Their samples and descriptions aligned well with the data we received. We will certainly reach out to UniData again if we're in search of 3rd party video data.

Data is well organized and easy to…
Data is well organized and easy to consume. We could download and use it for training within few hours of receiving the data links.
Our Clients Love Us
Ready to get started?
Tell us what you need — we’ll reply within 24h with a free estimate

- Andrew
- Head of Client Success
— I'll guide you through every step, from your first
message to full project delivery
Thank you for your
message
We use cookies to enhance your experience, personalize content, ads, and analyze traffic. By clicking 'Accept All', you agree to our Cookie Policy.