
Let’s face it — training a machine learning model without a validation dataset is like prepping for a marathon but skipping your practice runs. You might show up with the right gear, but the real test is: can you actually perform when it counts?
That’s exactly what validation data helps answer.
In this article, we’ll break down what validation datasets are, why they’re crucial, and how they shape better, smarter, and more reliable ML models. Whether you’re tuning hyperparameters or battling overfitting demons, this is one concept you absolutely need to master.
So, What Is a Validation Dataset?
A validation dataset is a slice of your data that your model never sees during training — and that’s the point.
Instead of helping the model learn, this dataset helps us evaluate how well the model is doing. It’s your behind-the-scenes check to make sure the model isn’t just memorizing patterns but can actually apply them to new, unseen data.
In machine learning, we typically divide our data into three main buckets:
| Dataset Type | Purpose |
|---|---|
| Training Set | Teaches the model to recognize patterns |
| Validation Set | Fine-tunes the model and prevents overfitting |
| Test Set | Gives an unbiased, final performance check |
Validation is where the real tweaking happens — adjusting hyperparameters, testing different model versions, and finding that sweet spot between underfitting and overfitting.
Why Validation Data Is So Important
Here’s why validation data deserves the spotlight:
Catches Overfitting Before It’s Too Late

One of the biggest risks in machine learning is overfitting—when a model clings too tightly to the training data, memorizing instead of generalizing. It performs exceptionally on what it’s seen but collapses when shown anything new.
Validation data acts as an early warning system. It steps in mid-training to ask: “Hey, are you actually learning useful patterns or just mimicking the training set?” If your validation accuracy starts dropping while training accuracy keeps rising, that’s your cue—your model’s probably overfitting, and it’s time to pull back.
Enables Hyperparameter Tuning

Things like learning rate, batch size, number of trees, dropout rates—these aren't learned by the model itself. They’re predefined by you, and even small tweaks can drastically impact performance.
How do you know which combination works best? You guessed it: validation data. By evaluating how different configurations perform on this set, you can dial in the optimal settings that balance learning and generalization. Without validation feedback, hyperparameter tuning is just a guessing game.
Helps Select the Best Model

Let’s say you’ve built three models: a logistic regression, a random forest, and a neural network. They all look great on paper—but which one’s ready for deployment?
That’s where the validation set comes in. It gives you an unbiased comparison point, helping you pick the version that performs best on data it hasn’t seen. And spoiler alert: the best model on training data isn’t always the best on validation data. The one that generalizes well is the one worth taking to production.
Simulates Real-World Conditions

Your model won’t live in a lab forever. It’ll be exposed to new environments, unseen users, or fresh market trends. Validation data simulates this unpredictability.
If your model can’t handle your validation set—a sample meant to imitate real-world inputs—it’s definitely not ready for the real thing.
Best Practices for Building a Validation Set
Creating a strong validation set isn’t just about splitting data—it’s about making that slice truly meaningful.
Mirror the Real World
Your validation data should look like the data your model will face after deployment—messy, varied, and unpredictable. If you're working with user-generated text, include slang, typos, and emojis. If it's product images, throw in some poor lighting and odd angles.
Too-clean validation sets give you a false sense of model readiness.
Watch for Class Imbalance
An unbalanced validation set can seriously skew your evaluation. If 90% of the data belongs to one class, your model might look accurate just by guessing the majority. Stratify your splits or rebalance your samples to make sure minority classes get fair representation.
Keep It Fully Isolated
No overlap. Not even a little. Validation data must be completely separate from training data—no shared IDs, rows, or feature leakage.
If there’s any contamination, your performance metrics become meaningless.
Handle Time-Series with Care
For time-based data, don’t shuffle. Keep the chronological order intact—train on earlier data, validate on later. That way, you’re testing your model the way it’ll actually be used: predicting the future, not the past.
Also, if seasonality matters in your domain, match validation windows to reflect those cycles.
Apply the Same Preprocessing
Whatever you do to the training data—scaling, encoding, filling in gaps—do the exact same to the validation set. Using training-derived parameters (like mean and std for normalization) is a must.
Automate it with a pipeline to avoid manual mistakes.
How to Prepare a Dataset for Machine Learning
Learn more
The Quality + Quantity Equation
A validation set isn’t just about having enough data—it’s about having the right data.
Quality First
Your validation data should look and behave like the data your model will face in real life. That means:
- Clean formatting
- Correct, consistent labels
- No missing or misleading values
If the data is messy or inaccurate, your model’s feedback loop breaks. It might learn the wrong lessons—or appear better than it is.
How Much Is Enough?
The sweet spot is usually 10–20% of your total dataset. That’s enough to evaluate performance without pulling too much from training.
Too little validation data? Your metrics get noisy. Too much? Your model may not learn enough during training.
Here’s a quick look:
| Problem | Impact |
|---|---|
| Not enough data | Unreliable results |
| Too much data | Wastes resources, weakens training |
| Bad quality | Misleading performance |
| Poor representation | Good scores, poor real-world results |
Small, clean, well-balanced validation sets beat large, sloppy ones every time. If you’ve got lots of data, great—but check that your validation slice still covers edge cases and real-world variation.
How to Create a Validation Set: Splitting Methods That Work
Choosing the right way to split your data matters more than it might seem. The method you use can affect how your model learns, how it’s evaluated, and ultimately—how well it performs in the real world. Here are the most commonly used approaches, when to use them, and what to watch out for.
Holdout Method
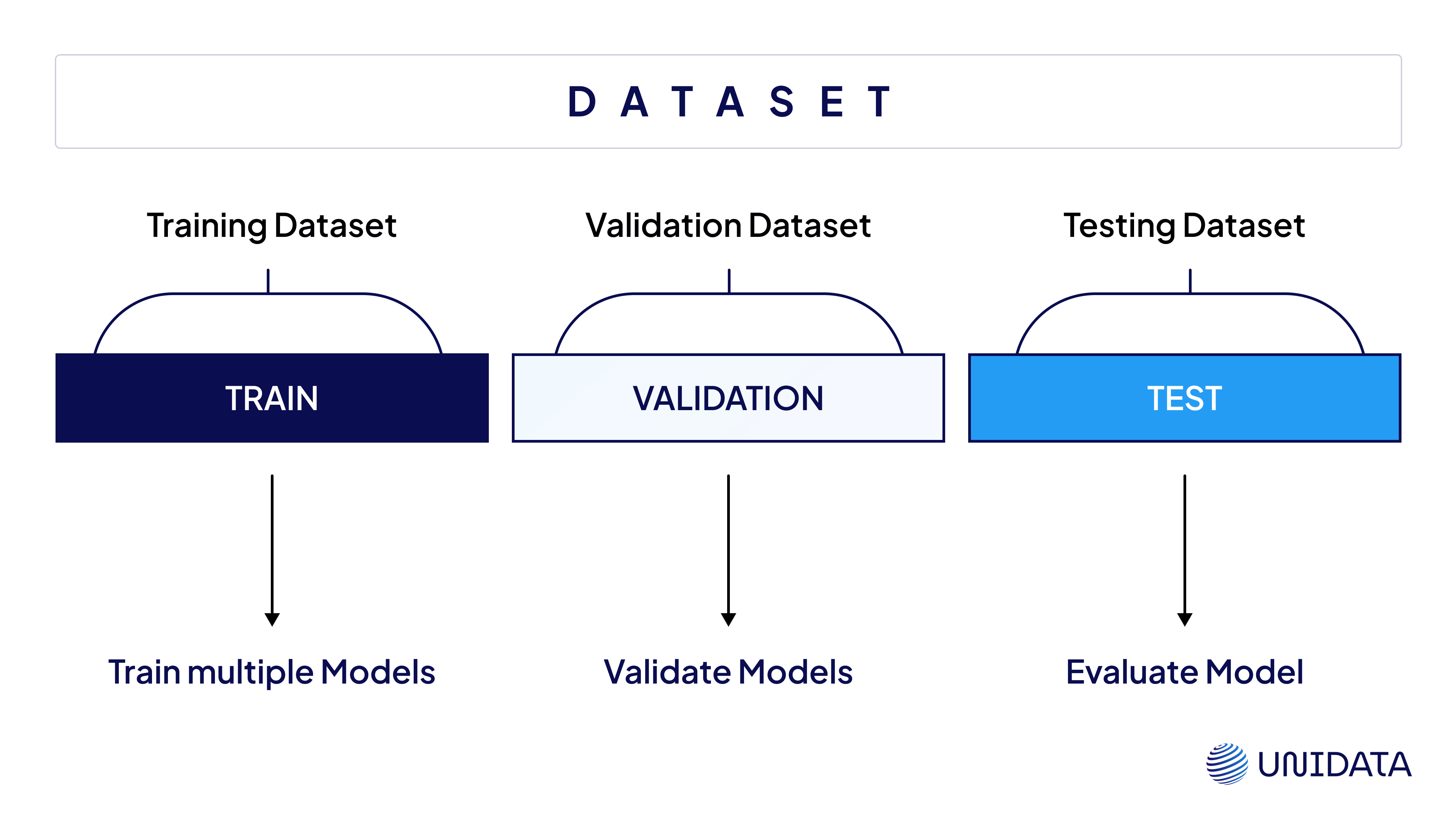
This is the most basic and widely used technique: split your dataset once into two parts—typically 80% for training and 20% for validation.
It’s fast and easy to implement, making it a go-to for large datasets where even 20% leaves you with enough validation data. But for smaller datasets, it can lead to unstable or misleading results, especially if your split happens to be unbalanced or unrepresentative.
Use it when: you’ve got plenty of data and need quick iteration.
K-Fold Cross-Validation
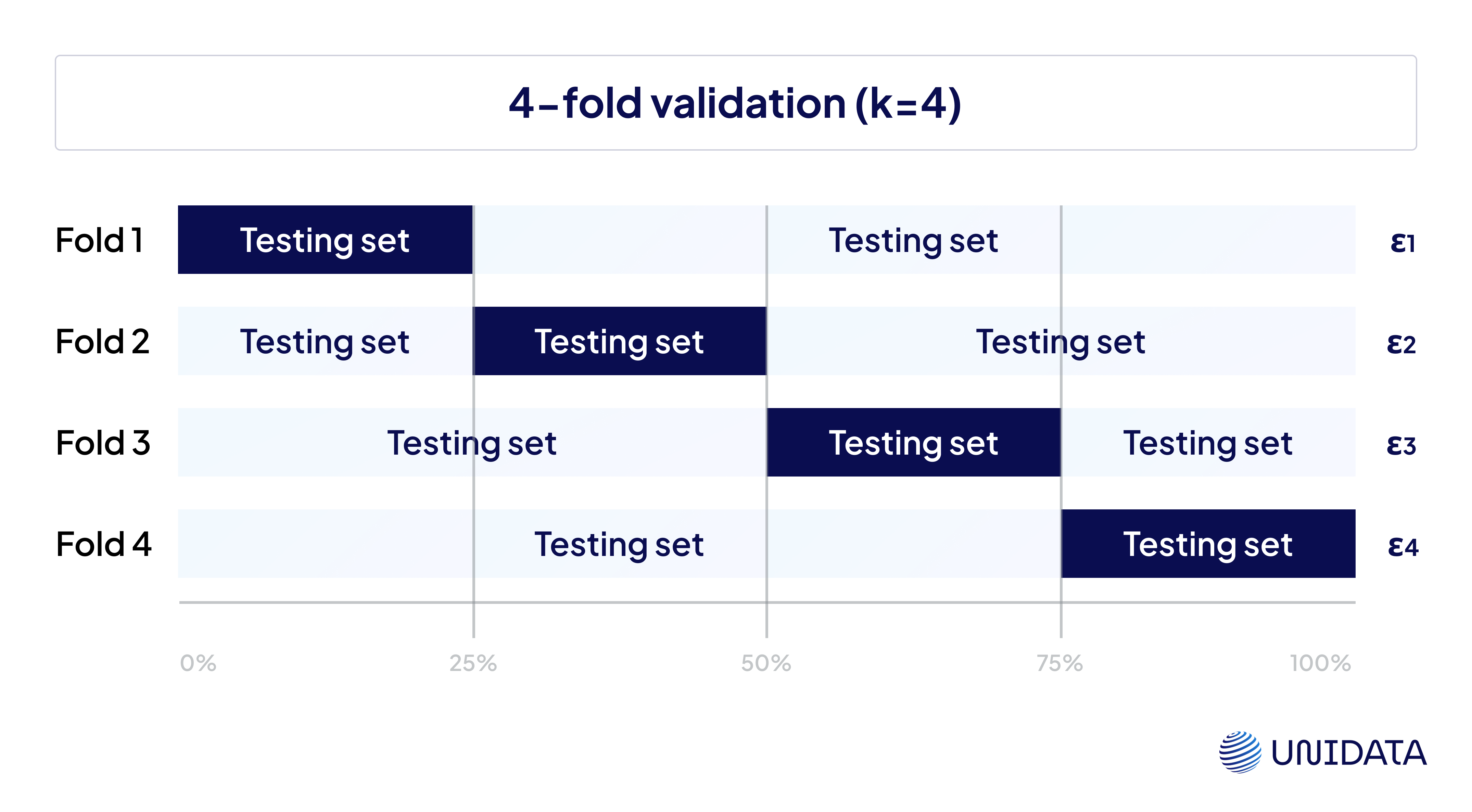
Here, the data is divided into k equal parts (or folds). Each fold takes a turn as the validation set, while the remaining k-1 folds are used for training. You repeat this k times, and average the results.
This gives a much more reliable estimate of model performance, especially when your dataset isn’t huge. It also reduces the chances of depending on one lucky (or unlucky) split.
Use it when: your dataset is moderate in size and you want a well-rounded performance check.
Stratified K-Fold
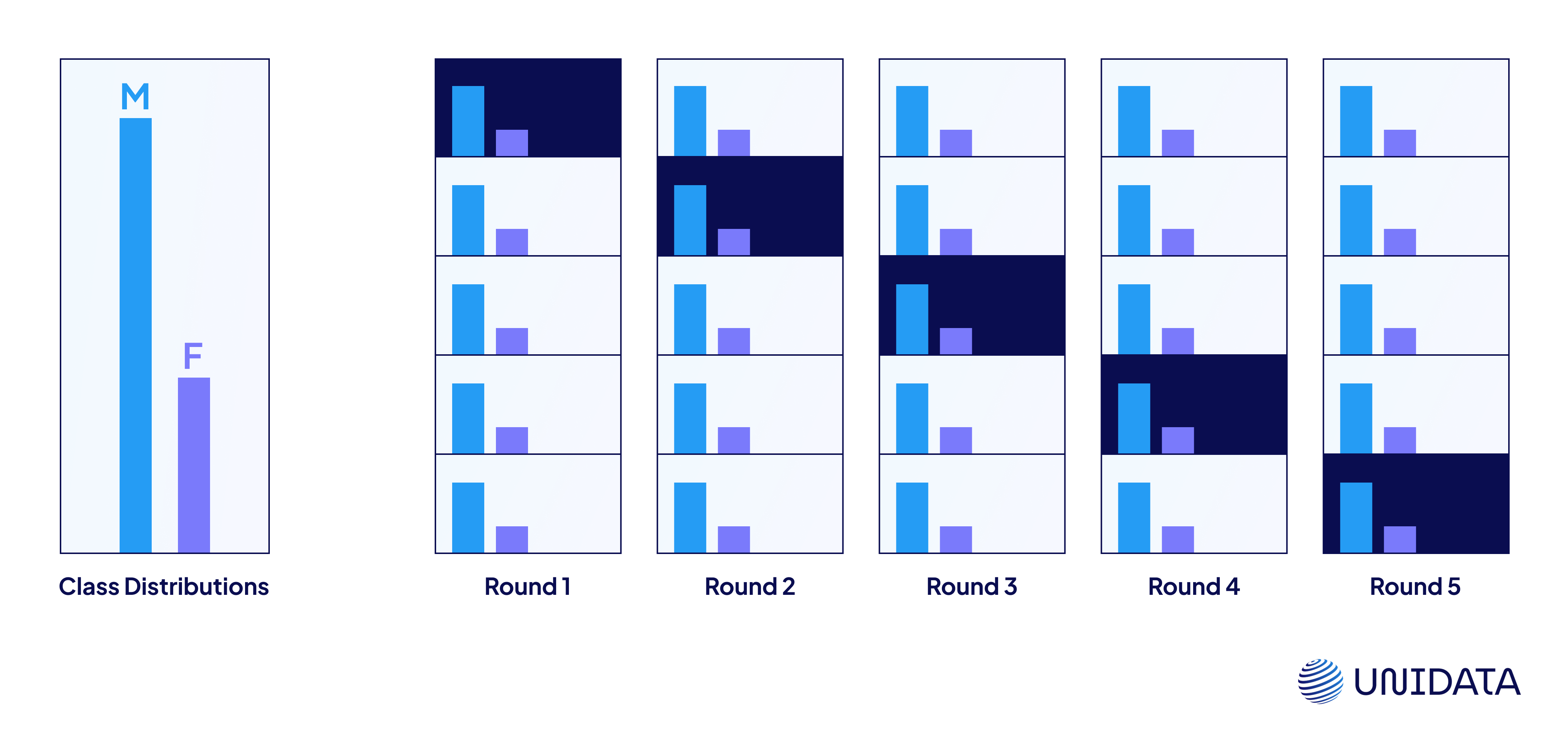
A smarter variation of K-Fold for classification problems, this method ensures that each fold maintains the same proportion of class labels as the original dataset.
It’s particularly helpful when dealing with imbalanced classes. Without stratification, you might end up with folds that don’t represent all labels properly—leading to skewed evaluation results.
Use it when: your data is imbalanced and label distribution matters.
Leave-One-Out Cross-Validation (LOOCV)

In this method, every single data point gets a turn as the validation set, while the rest are used for training. So if you have 100 data points, you’ll train and validate 100 times.
It gives you the most thorough use of data but is computationally expensive. That’s why it’s usually reserved for very small datasets where every sample counts.
Use it when: your dataset is tiny, and precision matters more than speed.
Time-Series Cross-Validation
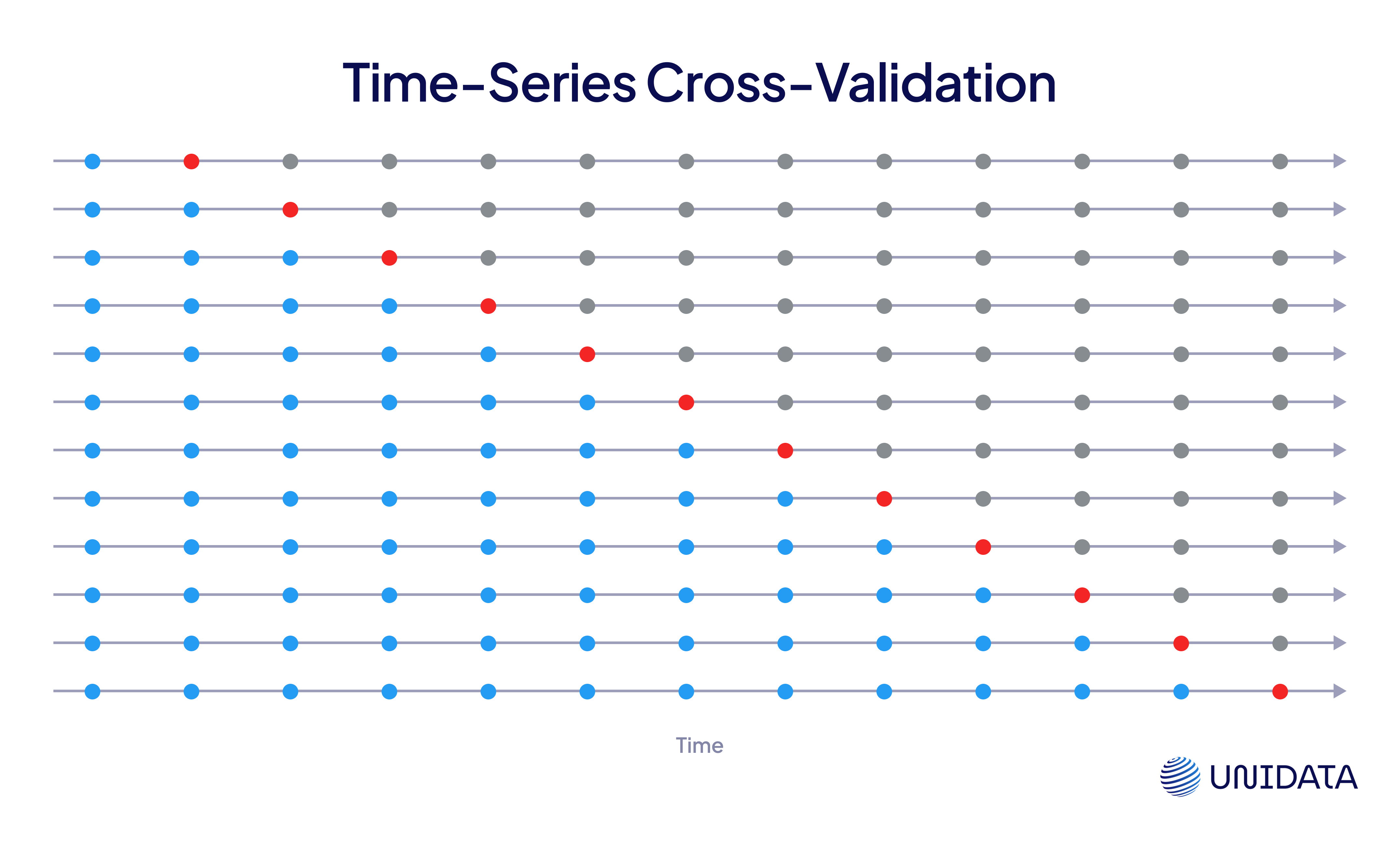
With time-series data, you can’t randomly shuffle your samples—order matters. This method uses a rolling or expanding window: train on past data, validate on future data, and repeat by shifting the window forward.
It respects the temporal structure and prevents data leakage from future timestamps, which would otherwise inflate your performance metrics.
Use it when: your data is time-dependent and must be evaluated in sequence (e.g., forecasting, financial modeling).
Step-by-Step: How Validation Fits Into Model Training
Validation isn’t just one step—it threads through the entire model-building process. Here’s how it fits in:
1. Prepare the Data
Clean, scale, encode. Whatever preprocessing you apply to training data, apply it identically to validation data using the same parameters.
2. Train the Model
Fit your model on the training set. This is where it learns patterns and relationships.
3. Tune the Parameters
Use the validation set to adjust things like learning rate, number of layers, tree depth, etc.
This step helps avoid overfitting or underfitting.
4. Evaluate Performance
Look at metrics that matter to your task—accuracy, F1, AUC, RMSE. The validation set gives you an honest preview of how your model might perform in the real world.
5. Pick the Best Model
Choose the configuration that performs best on validation—not just on training.
6. Test Once, Only Once
With everything tuned, test on your final, untouched test set. This gives you the cleanest measure of real-world readiness.
7. Iterate and Improve
Refine features, retrain, experiment with different architectures. Use validation feedback to drive better versions—just don’t overfit to it along the way.
Final Thoughts
Validation data isn’t just a sidekick to training data — it’s a crucial co-pilot. It helps steer your model toward robustness, accuracy, and generalization.
Done right, it saves you from costly mistakes in production and helps you ship smarter, stronger models. Want to build models that stand up to real-world chaos? Start by treating your validation data like the VIP it is.
Frequently Asked Questions (FAQ)
Validation data is a separate portion of your dataset used to evaluate model performance during training. Unlike training data, it helps detect overfitting, tune hyperparameters, and ensure the model generalizes well to unseen data—making it essential for building reliable machine learning systems.
Validation data is used during model development to fine-tune parameters, while training data teaches the model patterns. Test data, on the other hand, is used only once at the end to provide an unbiased evaluation. Keeping validation data separate ensures accurate performance measurement.
A common best practice is to allocate 10–20% of your total dataset as validation data. This balance provides enough data to evaluate performance without reducing the amount available for training, ensuring both learning quality and reliable evaluation.
Validation data acts as an early warning system for overfitting. If a model performs well on training data but poorly on validation data, it indicates the model is memorizing instead of generalizing—allowing you to adjust before deployment.
Popular methods include the holdout method, k-fold cross-validation, and stratified k-fold for imbalanced datasets. For time-series data, time-based splitting is essential to avoid data leakage and ensure realistic evaluation.
Common mistakes include data leakage between training and validation sets, using unrepresentative or overly clean data, and over-tuning models specifically to validation results. These issues can lead to misleading performance and poor real-world outcomes.
Validation data simulates real-world conditions by testing the model on unseen, diverse inputs. This helps ensure the model performs reliably outside the training environment, making it more robust, accurate, and production-ready.










