
1. Introduction: What’s the Big Deal?
Machine learning (ML) might sound like a tech buzzword, but at its core, it’s about how algorithms learn from data to make predictions, recognize patterns, or even discover new insights. The world of ML is vast, and one of the first major decisions data scientists face is whether to use supervised or unsupervised learning.

Your choice here depends largely on how your data is structured and what you aim to accomplish. This article explores the differences between the two, how they work, and when to use each one, so you can make informed decisions in your own ML projects.
2. Supervised Learning: Teaching with Examples
Supervised learning is, in simple terms, like teaching a child with flashcards. Each flashcard has a picture (input) and a label (output). The child learns to associate the picture with the label—just like an algorithm learns from labeled data.
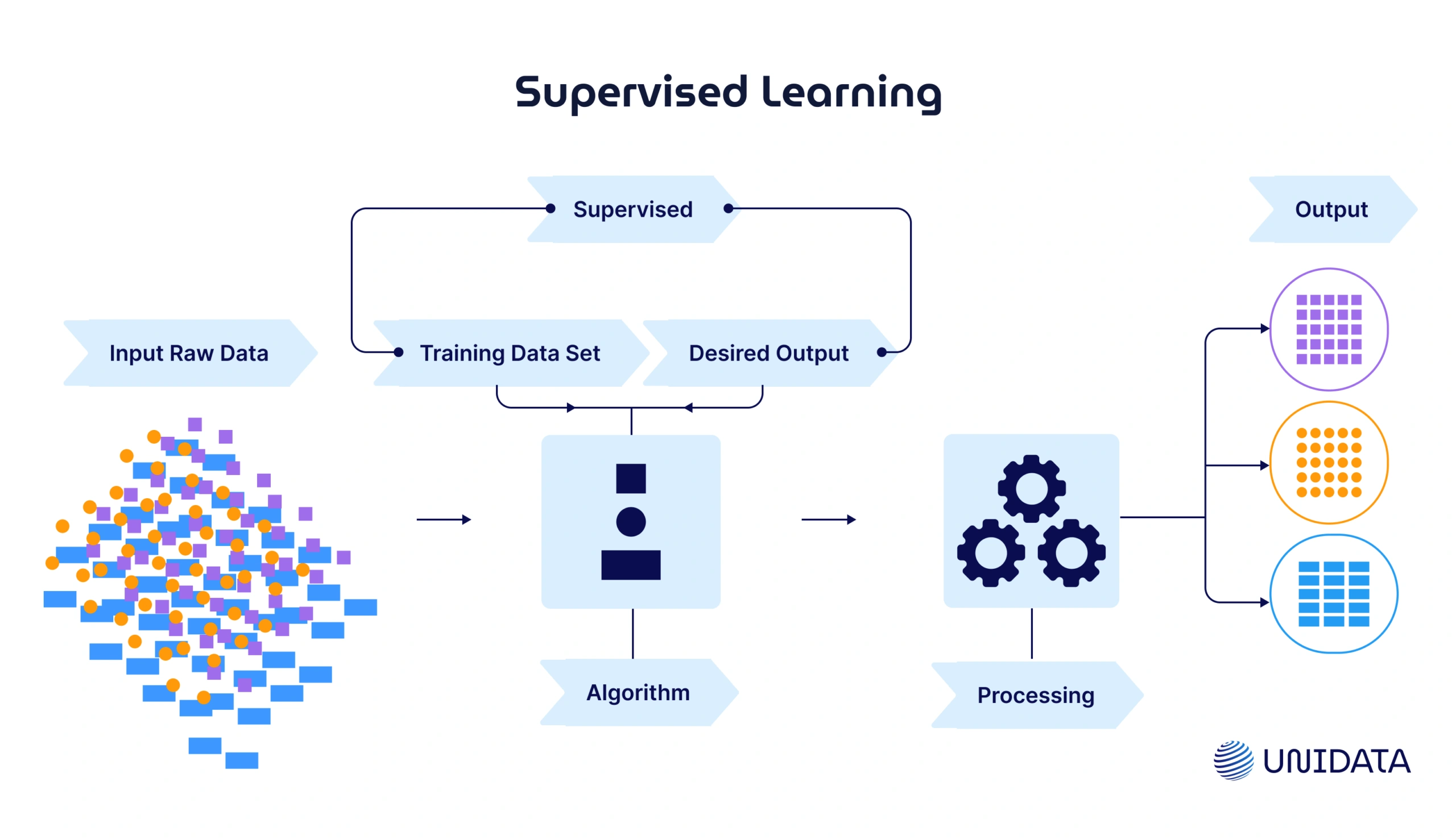
Key Components
Supervised learning requires a labeled dataset, meaning that each training sample includes both the input data (features) and the corresponding correct output (label). The goal is for the model to learn from this data and generalize to make predictions on new, unseen data.
When a supervised learning algorithm is trained, it makes predictions on the training data, and the output is compared to the true label. The difference (error) is then used to adjust the model, improving it over time until it can make accurate predictions.
Supervised learning is widely used for tasks where the goal is to predict or classify data. Here are a few common examples:
- Email Spam Detection: Classify emails as spam or not spam.
- Sentiment Analysis: Classify text as positive, negative, or neutral.
- Medical Diagnosis: Predict if a patient has a particular disease based on symptoms or test results.
In supervised learning, the model’s performance is typically evaluated using metrics like accuracy, precision, recall, or F1 score, which help you understand how well it can generalize to new data.
Some of the commonly used Supervised Learning algorithms are:
- Linear Regression: A statistical method that models the relationship between a dependent variable and one or more independent variables by fitting a straight line to the data.
- Decision Trees: These are flowchart-like structures where each internal node represents a feature (attribute), each branch represents a decision rule, and each leaf node represents an outcome.
- Neural Networks: Inspired by the human brain, neural networks consist of layers of interconnected nodes (neurons), and are great for handling complex, high-dimensional data.
3. Unsupervised Learning: Letting the Data Speak for Itself
Unsupervised learning, on the other hand, works a bit differently. It’s like giving someone a set of mixed-up puzzle pieces and asking them to find patterns or group similar pieces together without knowing what the finished puzzle looks like.In unsupervised learning, no labels are provided with the data. The algorithm's job is to find the hidden structure in the data and make sense of it, often by grouping similar items together or reducing the dimensionality of the data to highlight important features.
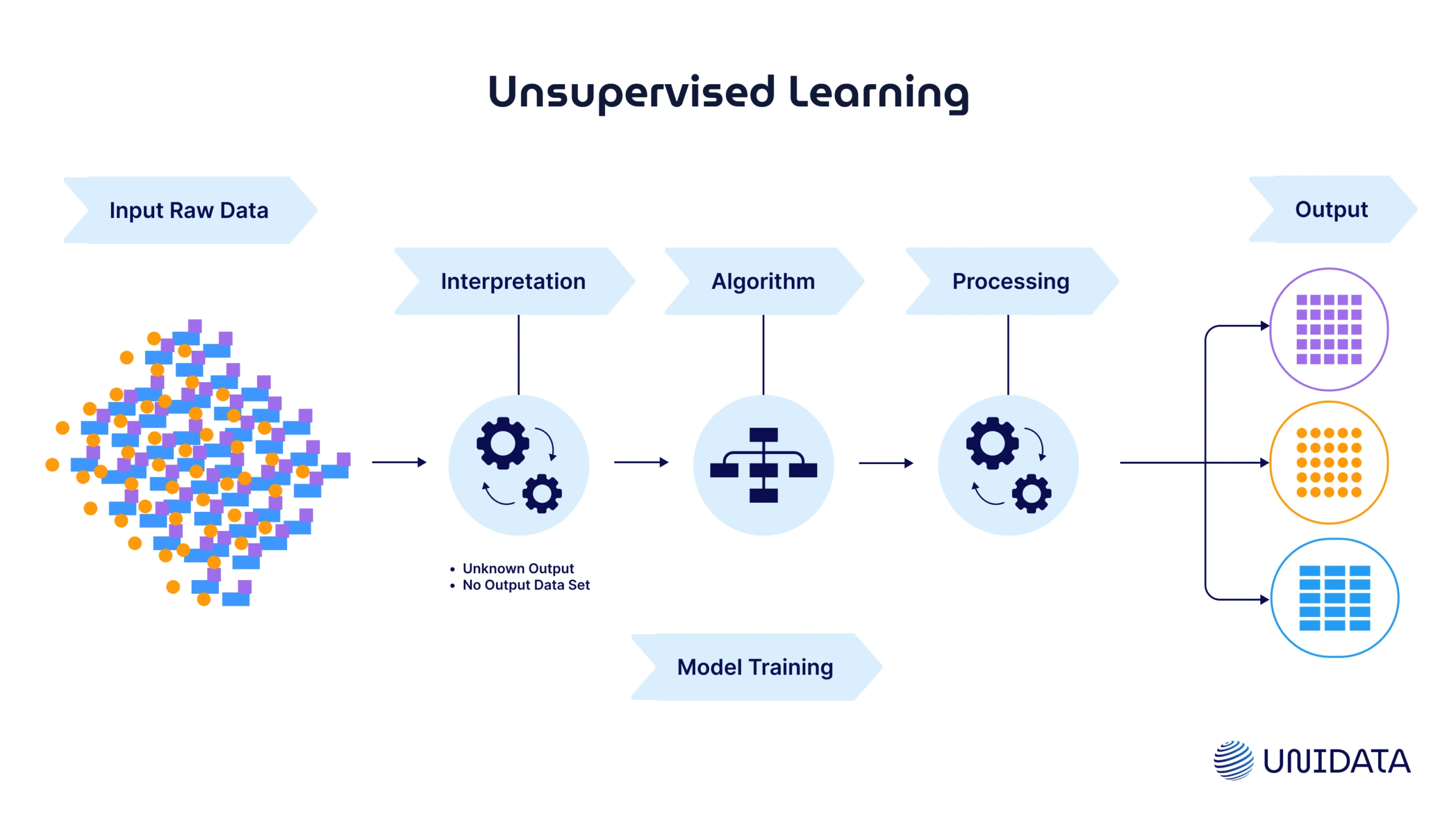
Key Components
Unsupervised learning doesn't have predefined outcomes or labels to guide the learning process. Instead, it relies on the algorithm’s ability to identify patterns, correlations, and groupings within the data. In most cases, the goal is to find structure in the data that wasn’t immediately apparent.
Despite being “unsupervised,” humans still play a role in validating the results and providing context. For example, an unsupervised model might identify clusters of products that are often bought together, but a human analyst needs to determine whether those clusters make sense for a retail recommendation system.
Unsupervised learning is great for exploratory tasks where the goal is to uncover patterns or group similar data points. Some common applications include:
- Customer Segmentation: Grouping customers based on purchasing behavior.
- Anomaly Detection: Identifying outliers that might signify fraud or errors.
- Topic Modeling: Grouping documents based on shared themes or topics.
Some of the commonly used Unsupervised Learning algorithms are:
- K-Means Clustering: This algorithm divides data into K clusters based on similarity, with each point assigned to the cluster whose center is nearest.
- Hierarchical Clustering: This method builds a tree-like structure of clusters that shows the relationships between them, useful for hierarchical data like taxonomies.
- PCA (Principal Component Analysis): A technique used for reducing the dimensionality of data, making it easier to visualize and analyze by retaining the most important features.
Unlike supervised learning, unsupervised learning doesn’t use accuracy or similar performance metrics for evaluation. Instead, results are often evaluated based on how well the identified patterns or clusters match real-world expectations.
4. Key Differences at a Glance
The key difference between supervised and unsupervised learning lies in how the data is presented to the model. Simply put, supervised learning involves labeled data, where the algorithm is given both the input data and the corresponding correct output. Unsupervised learning, however, works with data that does not include any labels, leaving the model to figure out patterns or structures on its own.
In supervised learning, the algorithm learns by making predictions on the training data, comparing those predictions with the actual outputs (the labels), and adjusting its parameters accordingly. This process continues until the model becomes proficient at predicting future data. However, this method relies on the fact that data must be labeled ahead of time. For instance, consider a model trained to predict the price of a house. You’ll need a dataset where each house's features—such as square footage, number of bedrooms, and location—are matched with its actual sale price. The model learns from these labeled examples and applies what it has learned to predict the prices of unseen homes.
In contrast, unsupervised learning doesn’t have the luxury of labeled data. Instead, the algorithm is tasked with finding inherent patterns or structures within the data on its own. While there are no explicit labels to guide the process, human oversight is still necessary to interpret the results. For example, an unsupervised learning model may analyze customer behavior data and identify several distinct groups of shoppers based on their purchasing habits. However, it's up to a business analyst to determine whether those clusters represent meaningful customer segments, such as “budget-conscious buyers” or “loyal brand enthusiasts.”
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Type | Labeled | Unlabeled |
| Objective | Predict outcomes | Find hidden patterns |
| Examples Needed | Often large | Can work with smaller data |
| Algorithms | Regression, Classification | Clustering, Dimensionality Reduction |
| Evaluation | Accuracy, F1 Score | Cluster quality metrics |
5. Strengths and Weaknesses
Supervised learning comes with several notable strengths. It excels at delivering accurate predictions when a large volume of labeled data is available. This reliability is further supported by the fact that many supervised algorithms, such as decision trees, are relatively easy to interpret, making it simpler for data scientists and stakeholders to understand how decisions are made. Moreover, supervised learning is often the preferred choice for predictive modeling tasks, where the goal is to forecast future outcomes based on historical data.
However, these advantages come with some significant weaknesses. Supervised learning heavily relies on labeled data, which can be both time-consuming and expensive to produce, especially in industries where expert annotation is required, such as healthcare or legal document review. Another challenge is the risk of overfitting, particularly when working with smaller datasets or overly complex models. Additionally, supervised learning models tend to be less flexible when applied to new data types or scenarios that differ significantly from the training data, making them less adaptable to evolving environments.
Unsupervised learning, by contrast, offers flexibility and autonomy by discovering patterns directly from unlabeled data. This makes it an excellent choice for exploratory data analysis when there’s little prior knowledge about the data structure. Another strength is its ability to work without manual labeling, drastically reducing upfront data preparation costs and accelerating the initial analysis phase.
That said, unsupervised learning also presents unique weaknesses. The results can be difficult to interpret, since the discovered patterns or clusters do not come with inherent meaning—human interpretation is required to make sense of them. Additionally, validation in unsupervised learning tends to be more subjective, as there’s no single “correct answer” to compare against. Finally, performance evaluation lacks standardized metrics, making it harder to benchmark models consistently across different projects or datasets.
6. Which One Should You Use? Decision Flow
When deciding between supervised and unsupervised learning, consider the type of data you have and the problem you're trying to solve.
On the flowchart, there are the core decisions needed to choose between supervised, unsupervised, and semi-supervised learning:
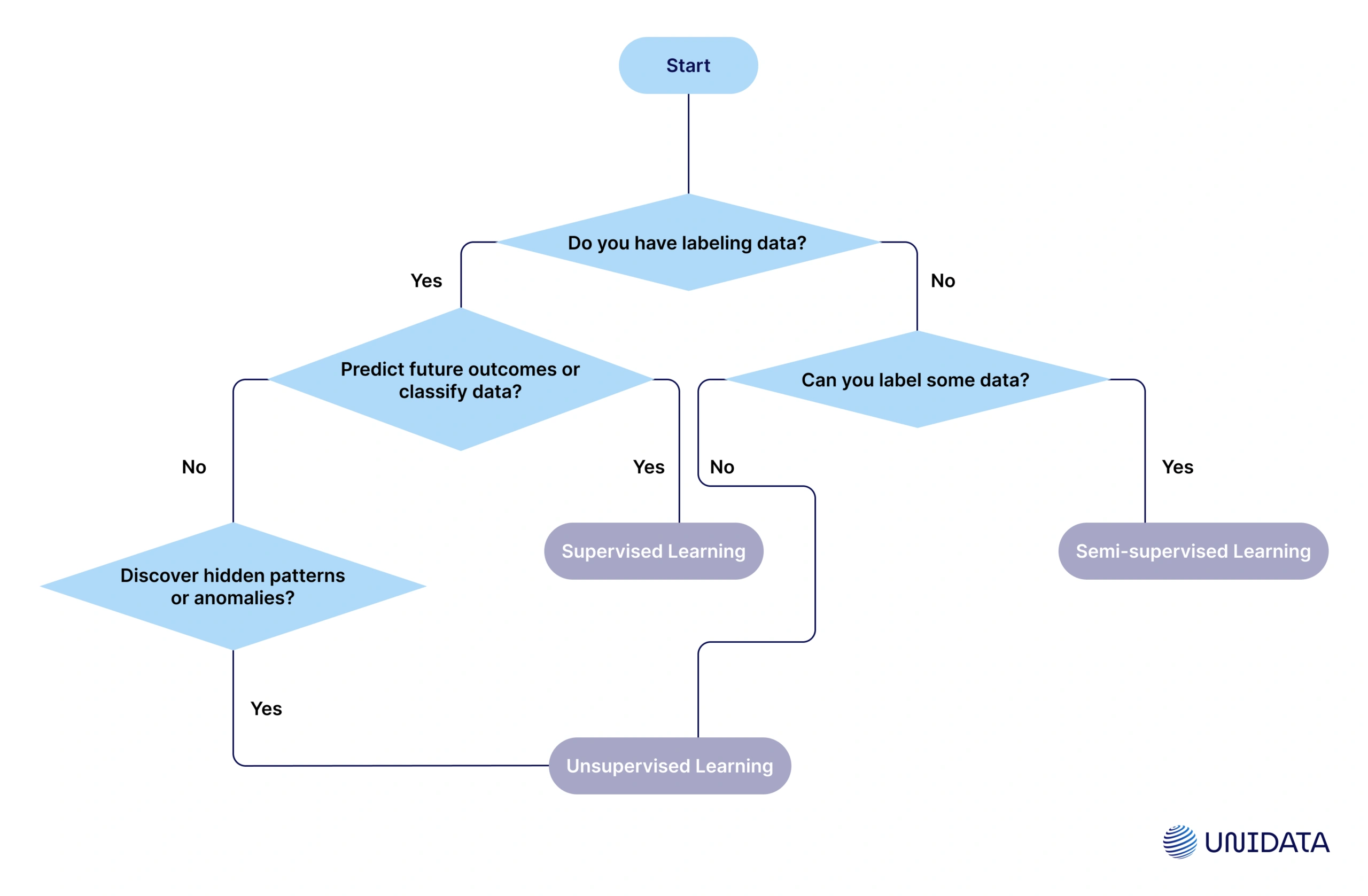
Here’s a bit more detailed decision flow:
Step 1: What Does Your Data Look Like?
Before you even think about algorithms, look at the state of your data. Ask yourself:
- Do you have clear labels or target outcomes attached to your data?
For example, if you’re predicting equipment failure, do you already know which machines failed and which didn’t? That’s labeled data, ideal for supervised learning. - If you don’t have labels, can you afford to create them?
Labeling is expensive and time-consuming. If labeling 100,000 customer service chats to classify their sentiment sounds impractical, you may want to explore unsupervised methods. - If your data has no labels and you can’t realistically label it, can you still define a business question that unsupervised learning could answer?
For example: “What types of customer purchasing behaviors exist?” This question can be tackled through unsupervised clustering.
Step 2: What’s Your Business Objective?
The type of insight you need dictates the learning method:
- Are you trying to predict a future event?
Example: Will this customer cancel their subscription next month?
Use supervised learning (you need labeled historical data).
- Are you trying to uncover hidden structure in the data?
Example: What hidden customer segments exist in my user base?
Use unsupervised learning (labels are not needed).
- Do you want to detect anomalies—things that don’t fit known patterns?
Example: What unusual transactions should we flag for investigation?
This can lean either way:
- Supervised if you have examples of past fraud.
- Unsupervised if you’re looking for previously unseen fraud patterns.
Step 3: Resource Check—What’s Feasible?
The real world isn’t perfect, so this part often overrides theoretical best practices:
- Do you have a small labeled dataset, but a huge pool of unlabeled data?
This is a perfect case for semi-supervised learning—use the small labeled set to guide learning on the larger unlabeled set.
- Do you have very high-dimensional data (like genomic data or high-resolution images)?
Even if you want to use supervised learning eventually, you may first need to apply unsupervised techniques (like PCA) to reduce dimensionality.
- Do you need quick results for exploratory analysis before committing to labeling?
Start with unsupervised learning to get an initial sense of structure, then decide if full labeling is worth the investment.
Step 4: Think Long-Term—Model Maintenance & Scalability
- Will the data evolve quickly over time (like social media trends)?
Unsupervised learning is often better at adapting to evolving patterns, while supervised models can get stuck if the training labels no longer match reality. - Are you building a product that relies on highly interpretable and defensible predictions?
Supervised learning (especially simple models like logistic regression) tends to offer better explainability, which is critical in regulated industries like finance and healthcare.
Final Tip: When in Doubt, Prototype Both
In reality, professional data scientists rarely commit upfront. Often, teams will:
- Prototype a quick unsupervised clustering to understand the data landscape.
- Use those insights to guide the labeling process if supervised learning is needed.
- Test both approaches and compare the results against business goals.
7. Final Thoughts
While supervised learning is widely used due to its proven effectiveness in a variety of applications, unsupervised learning is gaining momentum as the amount of unlabeled data continues to grow. The rise of semi-supervised learning, where both labeled and unlabeled data are used together, offers a hybrid approach that can strike a balance between the two.
Frequently Asked Questions (FAQ)
The key difference between supervised learning vs unsupervised learning lies in the type of data used. Supervised learning relies on labeled datasets, where each input has a known output, enabling the model to make predictions. In contrast, unsupervised learning works with unlabeled data, allowing the algorithm to discover hidden patterns, groupings, or structures without predefined answers.
Choosing between supervised learning vs unsupervised learning depends on your goal and data. Use supervised learning when you need to predict outcomes or classify data (e.g., spam detection or medical diagnosis). Use unsupervised learning when your goal is to explore data, identify patterns, or segment groups, such as customer segmentation or anomaly detection.
In real-world scenarios, supervised learning vs unsupervised learning appears in many applications. Supervised learning is used in email spam filters, sentiment analysis, and disease prediction, where labeled data is available. Unsupervised learning is applied in customer segmentation, fraud detection, and topic modeling, where the system uncovers patterns without labeled outputs.
When comparing supervised learning vs unsupervised learning, supervised models are generally more accurate for prediction tasks because they learn from labeled data with known outcomes. However, unsupervised learning excels in discovering unknown patterns and insights, especially when labeled data is unavailable.
Understanding the limitations of supervised learning vs unsupervised learning is crucial. Supervised learning requires large amounts of labeled data, which can be expensive and time-consuming to create. Unsupervised learning, while more flexible, often produces results that are harder to interpret and evaluate, since there are no predefined labels.
Yes, combining supervised learning vs unsupervised learning is common in modern machine learning workflows. Techniques like semi-supervised learning use a small amount of labeled data alongside large unlabeled datasets. Additionally, unsupervised methods (e.g., dimensionality reduction) are often used to preprocess data before applying supervised models.








