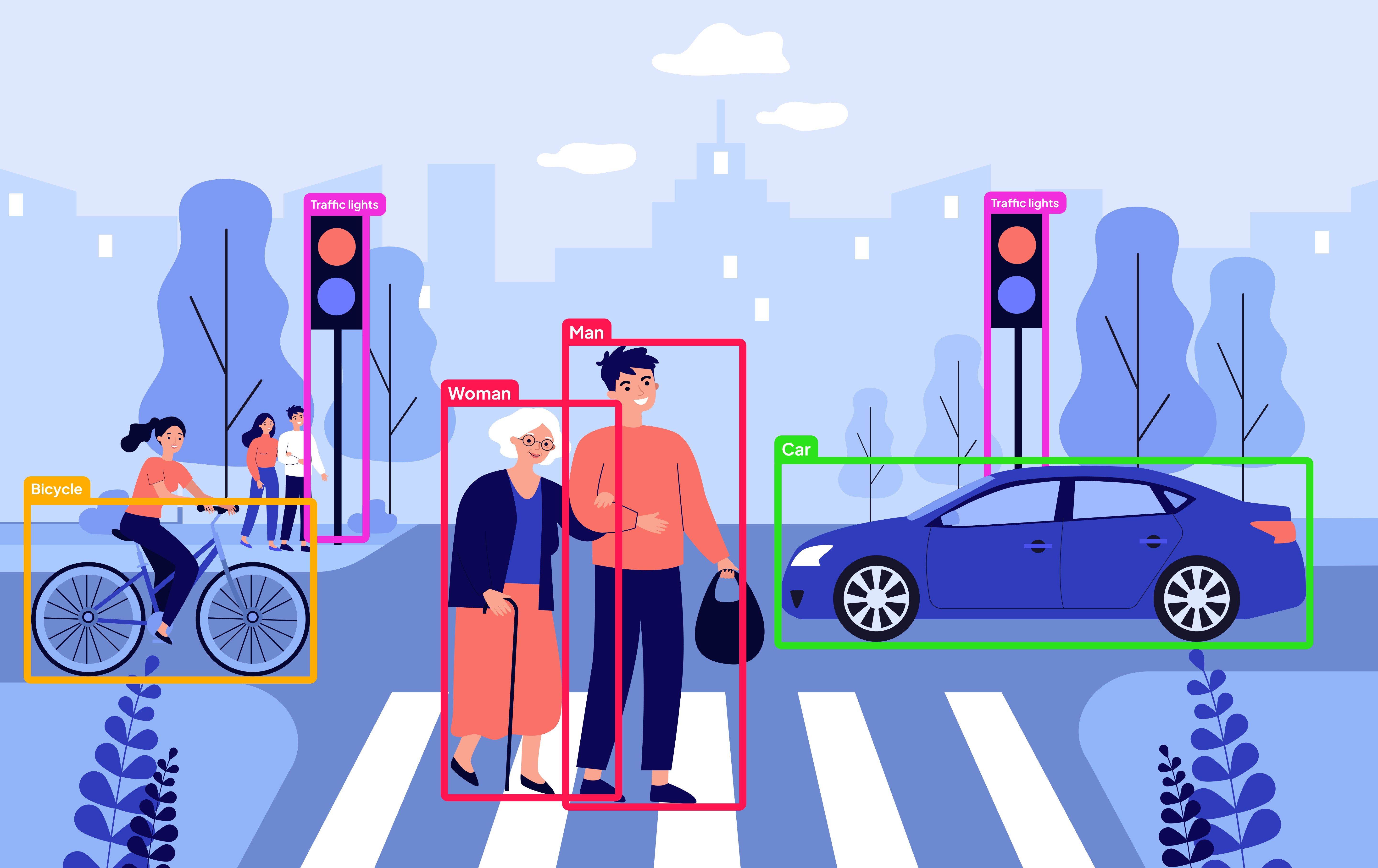
What Is Object Detection?
Object Detection is a computer vision task aimed at identifying and localizing individual objects within an image or video stream.
The Process Involves Two Main Steps:
- Object Identification
The model analyzes the image and determines which objects are present and what class they belong to.
- Object Localization
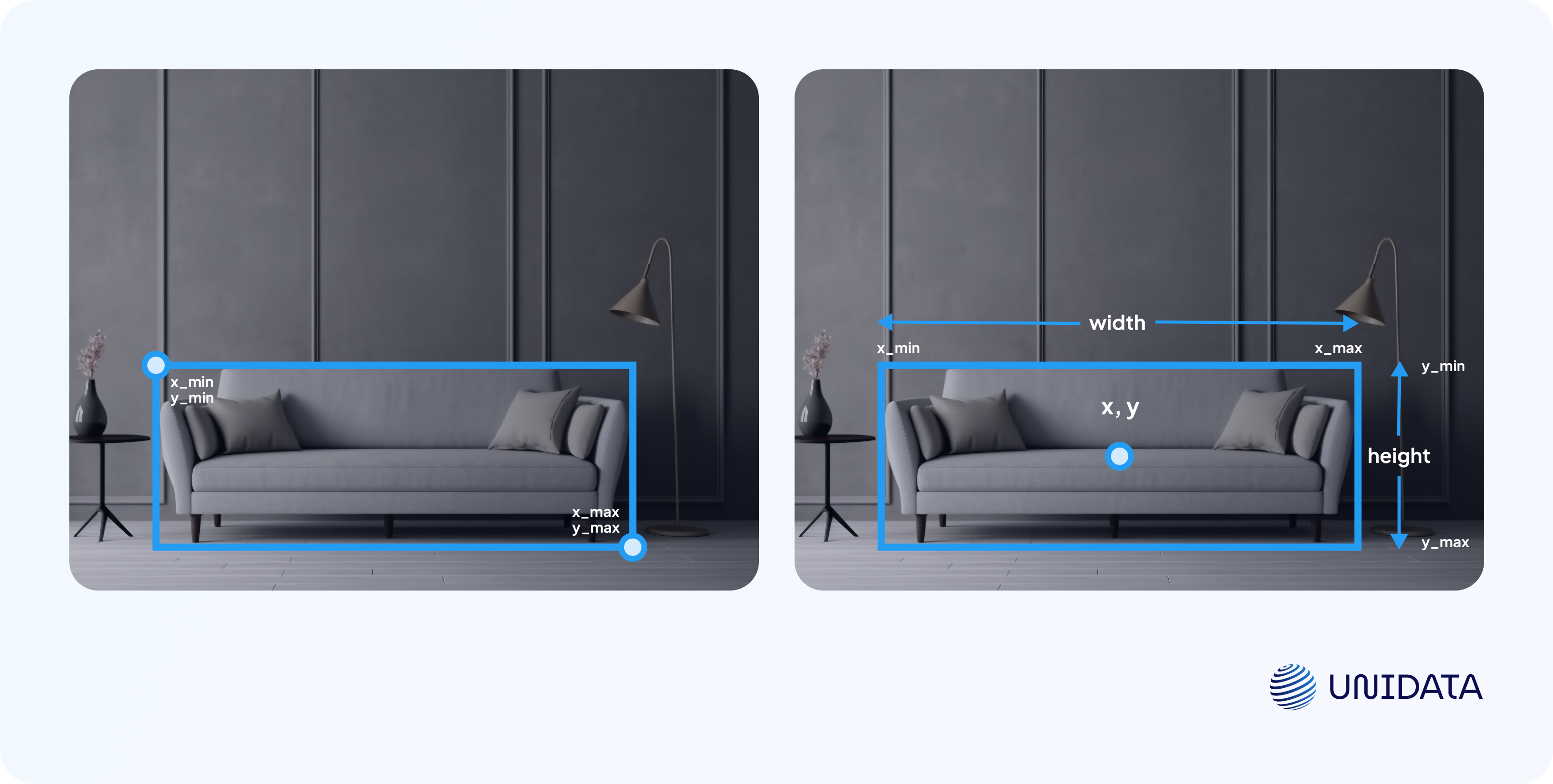
Each detected object is assigned a bounding box. This box is a rectangle that outlines the object's boundaries, indicating its location and dimensions using a set of parameters:
- x_min, y_min and x_max, y_max — the coordinates of the top-left and bottom-right corners. They indicate where the bounding box starts and ends on the image, allowing precise positioning relative to the entire image.
- x, y — the coordinates of the bounding box center.
Width, height — the width and height of the box — the difference between x_max and x_min, and y_max and y_min, respectively.
Comparison with Other Computer Vision Tasks
Object Detection is just one of many tasks within the field of computer vision. To better understand its distinct features, it’s helpful to compare it with two related tasks: image classification and segmentation.
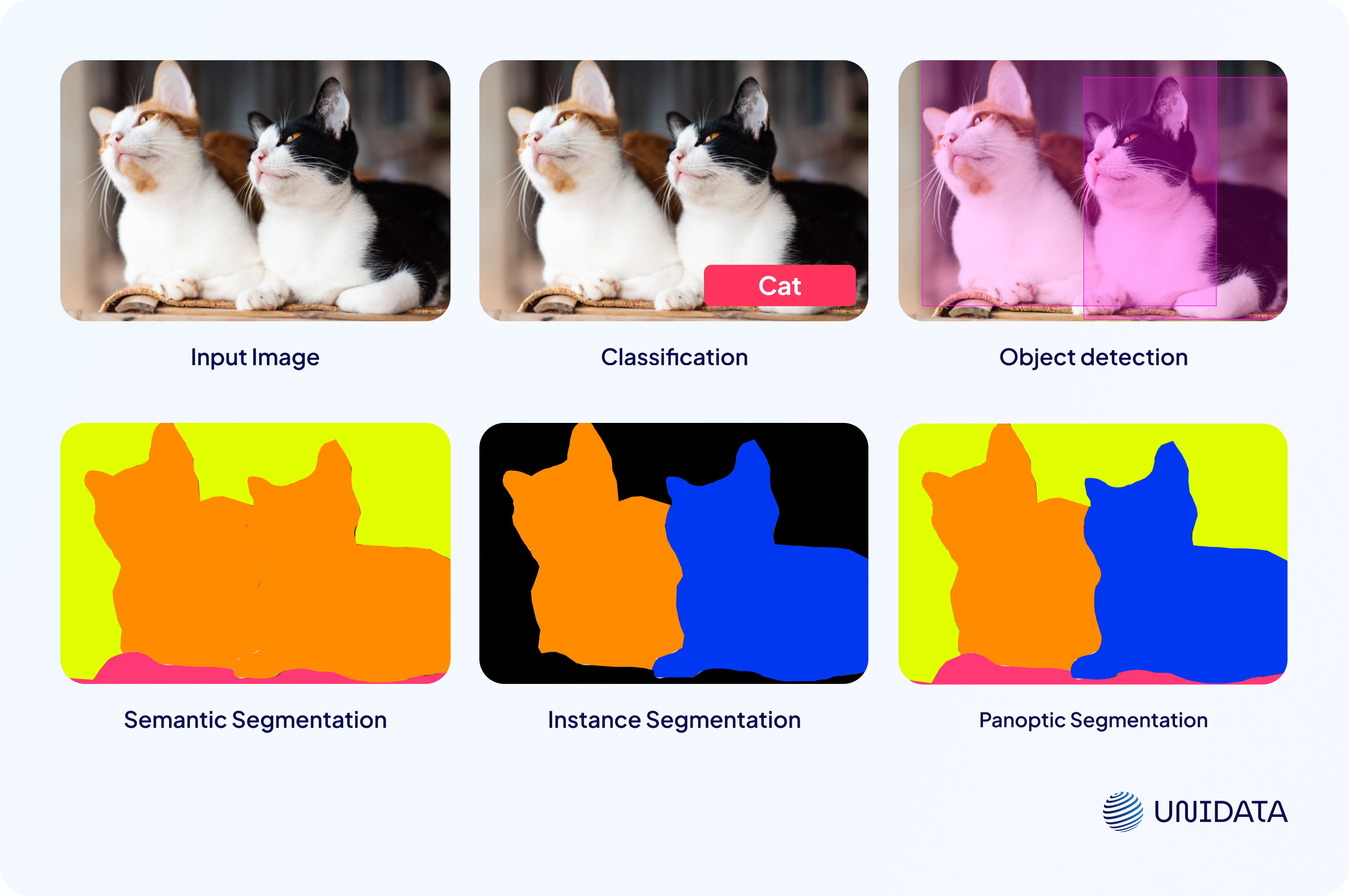
Classification is a foundational computer vision task. Its goal is to identify which objects are present in an image and assign them the appropriate class labels. However, classification does not provide information about the location of these objects.
Object Detection, unlike classification, not only identifies the classes of objects but also localizes them within the image. For example, a model can simultaneously detect the presence of a cat and specify its exact location using a bounding box.
Segmentation takes things a step further. Instead of simply enclosing an object within a box, it defines the exact pixel-level boundaries of each object, creating a mask for it.
There are three types of segmentation:
- Semantic Segmentation determines the class of every pixel in the image but does not differentiate between separate objects of the same class. For instance, multiple cats in the image will all be labeled the same way.
- Instance Segmentation differentiates between individual objects of the same class (e.g., two distinct cats), but typically ignores background elements that don’t belong to target classes.
- Panoptic Segmentation combines the principles of semantic and instance segmentation. It labels every pixel with its class and also distinguishes between separate instances within the same class, including both target and background objects.
Applications of Object Detection
Object Detection is a powerful tool with a wide range of real-world applications. It enables cars to see the road, security cameras to recognize faces, and doctors to diagnose faster and more accurately. Let’s take a look at the most common use cases for this technology.
Autonomous Transportation

Self-driving cars and Advanced Driver Assistance Systems (ADAS) rely on object detection to recognize pedestrians, cyclists, vehicles, traffic lights, road signs, animals, and other objects on and near the road. Thanks to this capability, vehicles can automatically brake, change lanes, avoid collisions, and predict the behavior of other road users. Without object detection, fully autonomous driving would be impossible.
Medicine
In healthcare, object detection helps automatically identify tumors, fractures, hemorrhages, and other pathologies on X-rays, CT scans, MRIs, and ultrasound images. This accelerates diagnosis and reduces the risk of error—especially in complex cases.
Industry
In manufacturing, object detection is used to identify defects at every stage—from raw material intake to product packaging. Smart cameras automatically detect shape, size, or color deviations, check for assembly correctness, and spot flaws. This reduces the defect rate, improves product quality, and cuts down on manual inspection costs.
Agriculture

By analyzing images from drones and video cameras, object detection assists in identifying plant diseases, spotting pests and weeds, assessing fruit ripeness and quantity, pinpointing areas in need of irrigation or fertilization, and monitoring livestock movement. This leads to more efficient resource use, reduced crop loss, and improved agricultural productivity.
Retail
Computer vision and object detection help retail stores monitor product availability on shelves, ensure timely restocking, and analyze customer movement throughout the store. In e-commerce, these technologies are used for automatic image-based product searches and generating personalized recommendations.
Security and Surveillance

Security systems use object detection to recognize faces, detect suspicious behavior, and identify unattended items. Smart cameras analyze the environment in real time, detect potential threats, and instantly alert security personnel. This plays a crucial role in crime prevention and maintaining public safety.

Fight Detection for Surveillance Systems
- Security, Video Analytics
- 200 professionally produced 4K videos
- 2 weeks
How Does Object Detection Work?
Traditional Object Detection Methods
Before the rise of deep neural networks, object detection relied on mathematical algorithms that analyzed image features such as edges, textures, and color gradients.
Key Methods
Haar Cascades
Introduced by Paul Viola and Michael Jones in 2001, this method marked one of the first major breakthroughs in automated object detection. It is still used today, notably in the OpenCV library.

How it works:
- The method detects objects based on brightness contrasts. It uses simple rectangular templates — Haar features. For example, a template with light and dark areas can highlight the boundary between the forehead and eyes on a face.
- To improve object recognition, the AdaBoost algorithm is applied. It combines simple classifiers into a strong one, with a focus on examples where previous errors occurred.
A cascade structure is also used — a sequence of filters. Each stage eliminates irrelevant parts of the image. If a region fails the first check, it’s not analyzed further. This greatly speeds up the detection process.
| Pros | Cons |
|---|---|
| Fast performance on low-resolution images with relatively uniform backgrounds | Performs poorly under changing lighting conditions |
| Effective for detecting objects in frontal positions | High rate of false positives, especially in noisy environments |
HOG + SVM (Histograms of Oriented Gradients + Support Vector Machine)
This method emerged in 2005 and was widely used for pedestrian and vehicle detection for many years.
How It Works:
- The image is divided into small regions (cells). In each cell, the direction of the greatest pixel intensity change is calculated — this is the gradient.
- A histogram is built for each cell, showing how many gradients fall into each of a set number of directions (usually 9).
- Multiple cells are grouped together, and all the resulting data is compiled into a single feature set — the HOG vector, which describes the object’s shape in the image.
- Then, a Support Vector Machine (SVM) is used — a machine learning algorithm that finds the boundary between object classes. It chooses a hyperplane that maximally separates the categories (e.g., "pedestrian" vs. "not a pedestrian").
| Pros | Cons |
|---|---|
| Performs well on simple objects with clear edges | Not suitable for complex scenes with overlapping objects |
| Relatively easy to implement | Relies on fixed feature extraction rules, limiting adaptability to varying conditions |
Deep Learning and Convolutional Neural Networks (CNNs)
Traditional methods had rigid limitations: they relied on manually crafted features and couldn’t adapt to complex scenarios. The advent of Convolutional Neural Networks (CNNs) marked a turning point in object detection, pushing it to a whole new level.
Core Idea
CNNs automatically extract features from images using a hierarchical structure of layers. This allows neural networks to detect objects even under complex and challenging conditions.
How It Works:
- The image passes through a series of convolutional layers, each applying a set of filters (also called convolution kernels) to either the raw image or the output of the previous layer. Each filter detects a specific feature, such as a vertical edge, corner, arc, etc.
- After each convolutional layer, an activation function (typically ReLU) is applied to introduce non-linearity into the model.
- Between convolutional layers, pooling layers are often used to reduce the spatial dimensions of the data while retaining the most important information. Pooling makes the network more robust to small shifts and distortions and reduces computational complexity.
- Deeper layers in the network combine simple features into more complex ones, creating a hierarchical representation of the image. For instance, basic features (like lines and corners) are combined into more abstract ones (like object parts).
- The output layers of the network — which may include both convolutional and fully connected layers — predict object classes and bounding box parameters (coordinates, width, height).
| Pros | Cons |
|---|---|
| No need for manual feature engineering | Requires large amounts of training data |
| Adapts well to varying image conditions | Demands powerful computational resources |
| Delivers high detection |
Object Detection Models
Modern object detection models use deep learning techniques built upon Convolutional Neural Networks (CNNs). They vary in architecture, speed, and accuracy. Below, we’ll explore the most well-known models and their characteristics.
Two-Stage Detectors
Two-stage models first identify regions in an image where objects might be located. Then, they classify those regions and refine their boundaries. These models tend to be very accurate, but they are computationally intensive and slower compared to single-stage approaches.
R-CNN (2014)
How It Works:
- The image is analyzed using Selective Search, which proposes around 2000 regions that may contain objects.
- Each region is resized to a fixed size and passed through a neural network to extract features.
- The resulting features are then sent to a classifier (e.g., SVM), which determines the object class.
- Linear regression is used to refine the bounding box coordinates — adjusting the corners or center as well as the box's width and height.
| Pros | Cons |
|---|---|
| High accuracy (for its time) | Very slow, since each region is processed independently |
| Suitable for precise object localization | Complex and time-consuming to train |
Fast R-CNN (2015)
How It Works:
- Unlike R-CNN, Fast R-CNN processes the entire image at once using a CNN. This generates a feature map — a compressed representation of the image.
- For each region (obtained from Selective Search or another method), the corresponding area is extracted from this feature map.
- A special layer called ROI Pooling converts each region of the feature map into a fixed-size feature vector. This is done by dividing the region into equal sections (e.g., 7×7) and taking the maximum value from each section. This standardizes variable-sized regions.
- The resulting feature vector is passed through fully connected layers, which output the object class and refine the bounding box coordinates.
| Pros | Cons |
|---|---|
| Faster than R-CNN | Still not fast enough for real-time applications |
| Leverages full-image information during training | Performance depends heavily on the quality of the input data |
Faster R-CNN (2016)
How It Works:
Unlike previous models, Faster R-CNN determines where to look for objects on its own. Instead of relying on the slower Selective Search method, it introduces a Region Proposal Network (RPN) — a separate convolutional network that works alongside the main detection network.
- The RPN receives a feature map — a high-level representation of the image — and predicts where objects are likely to be located.
- It uses a set of predefined anchor boxes of various sizes and aspect ratios, distributed across the image. These act as potential bounding boxes.
The regions proposed by the RPN are then passed to ROI Pooling and through fully connected layers for classification and bounding box refinement, following the same process as in Fast R-CNN.
| Pros | Cons |
|---|---|
| High detection accuracy | Requires powerful hardware for optimal performance |
| Faster than Fast R-CNN | More complex to implement than single-stage models |
Mask R-CNN (2017)
How It Works:
Mask R-CNN is an enhanced version of Faster R-CNN with an added branch that predicts a segmentation mask for each detected object — enabling instance segmentation.
- It introduces a modified version of ROI Pooling called ROIAlign, which more accurately aligns the extracted features with the original image.
| Pros | Cons |
|---|---|
| High detection accuracy | More resource-intensive than Faster R-CNN |
| Combines object detection and segmentation | More complex to implement and fine-tune |
Single-Stage Detectors
Unlike two-stage models, single-stage detectors immediately determine where the object is and what class it belongs to — without an intermediate region proposal step. This makes them much faster and suitable for real-time tasks.
YOLO (2016)
How it works:
YOLO divides the image into a grid (for example, 7×7 cells). In each cell, the model predicts several bounding boxes, the probability that a box contains an object (objectness score), and the probabilities of the object belonging to different classes, assuming the object’s center falls within that cell.
For each box, the model predicts the coordinates of its center, width, height, and a confidence score — the product of the objectness probability and the IoU (Intersection over Union) between the predicted box and the actual one.
| Pros | Cons |
|---|---|
| High speed | Slightly less accurate than two-stage models |
| Suitable for real-time applications | Performs poorly on small objects |
SSD (2016)
How it works:
Instead of using a grid like YOLO, SSD applies multi-scale image processing to better detect objects of different sizes. SSD uses several convolutional layers with different resolutions (feature maps) to predict bounding boxes and object classes. Each layer is responsible for detecting objects of a particular scale: earlier layers (with higher resolution) for small objects, later layers (with lower resolution) for large ones.
At each level, anchor boxes — predefined bounding boxes of various shapes and sizes — are used. For each anchor box, the network predicts the object’s coordinates, class, and presence probability.
| Pros | Cons |
|---|---|
| Optimal balance between speed and accuracy | Inferior to Faster R-CNN in complex scenes |
| Handles small objects better than YOLO | Can produce errors when objects overlap heavily |
RetinaNet (2017)
How it works:
- RetinaNet uses the Feature Pyramid Network (FPN) architecture to detect objects at different scales, similar to SSD.
- It introduces Focal Loss — a loss function that allows the model to focus on difficult objects and address the class imbalance problem (when one class, such as background, greatly outnumbers others).
| Pros | Cons |
|---|---|
| High accuracy, comparable to Faster R-CNN | Requires more resources than YOLO and SSD |
| Handles rare and small objects more effectively | Slower compared to other single-stage models |
In recent years, models based on the Transformer architecture, originally designed for natural language processing, have been gaining popularity.
DEtection TRansformer (DETR) is one such model that uses a Transformer to predict bounding boxes and object classes without relying on anchor boxes. DETR shows competitive accuracy and holds strong potential for further development.
Choosing a Model: Which One Is Best?
If you need high accuracy — Faster R-CNN. If speed is a priority — YOLO. If small objects matter — RetinaNet. If you need both segmentation and detection — Mask R-CNN.
The Role of Data in Training Object Detection Models
The performance of object detection algorithms is directly influenced by the quality of the data they are trained on. A lack of data or low-quality annotations leads to reduced detection accuracy, prediction errors, and poor model performance in real-world conditions.
Data Annotation
Object detection models are trained on large datasets of labeled images. Annotation is the process of assigning specific labels to objects. In object detection, this most commonly involves bounding boxes, but depending on the task, segmentation masks, keypoints, and skeletal annotations may also be used.
Annotation Methods
| Method | Description |
|---|---|
| Manual annotation | Data is labeled manually using specialized tools |
| Automatic annotation | Annotation is performed using automated algorithms without human involvement |
| Semi-automatic annotation | Combines automated labeling with human review and correction |
Annotation Tools
Various specialized platforms are used for annotation:
- LabelImg — a simple open-source tool for manually labeling bounding boxes.
- CVAT (Computer Vision Annotation Tool) — a powerful tool for annotating images and video, with support for team collaboration.
- LabelMe — a convenient tool for annotation and exporting data in JSON format.
Supervisely, V7, Scale AI — commercial platforms offering annotation automation and advanced functionality.
Open Datasets for Object Detection
Manually collecting and annotating images is time-consuming and expensive, especially for large-scale projects. To save time and resources, developers often use open datasets — pre-existing image collections with ready-made annotations.
Here are a few examples:
- Open Images Dataset — one of the largest datasets, with over 9 million images and annotations for thousands of object categories.
- Pascal VOC — a smaller but convenient dataset, containing around 11,000 images and 20 object classes.
- ImageNet — includes more than 14 million images and 20,000 object categories. While it’s primarily used for classification, it’s also employed for pretraining detection models.
However, for specialized tasks — such as medical applications — teams often have to build their own datasets, since suitable data is rarely available publicly.
Data Quality
Even the most powerful model cannot perform well if it’s trained on low-quality data. In this regard, several factors are critically important:
- Annotation accuracy — errors in bounding box coordinates or class labels negatively affect training.
- Data diversity — the model should learn to operate in varied conditions: different lighting, camera angles, partial occlusion of objects, and in the presence of noise, compression artifacts, and other distortions.
- Class balance — if some object classes appear much more frequently than others in the training set, the model may become biased and skew predictions toward the dominant classes.
Data Enhancement Techniques
To improve training quality and a model’s ability to generalize, the following techniques are commonly used:
- Oversampling and undersampling — methods for balancing class distribution in the training dataset.
- Data augmentation — artificially increasing the dataset size by applying various transformations to the original images: rotation, brightness adjustment, noise addition, scaling, cropping, color shifts, and flipping. Augmentation helps the model become more resilient to variations in objects and shooting conditions.
- Synthetic data — generating artificial images using rendering techniques or generative models when real data is scarce or difficult to collect.
It's essential for synthetic images to be realistic and not introduce a domain gap — a shift in data distribution that could affect model performance.
Key Takeaways
Object detection is one of the most essential technologies in the field of computer vision. It allows not only for recognizing but also for precisely locating objects within an image. These systems are used in medicine, transportation, security, and many other domains.
Modern models are based on neural networks and can handle even complex visual data. However, even the most advanced algorithms cannot function effectively without high-quality data — the diversity, accuracy, and annotation quality of data largely determine the success of an object detection project.
Frequently Asked Questions (FAQ)
Object detection is a computer vision task that identifies objects in an image and determines their exact location using bounding boxes. It combines classification (what the object is) with localization (where the object is).
In practice, object detection models analyze an image, assign class labels to detected objects, and define their positions using coordinates such as x_min, y_min, x_max, and y_max. This allows systems to not only recognize objects like cars or people but also track where they appear within a scene.
Object detection works by analyzing images with algorithms that detect patterns and predict object classes and bounding box coordinates. Modern systems rely on deep learning models, especially convolutional neural networks (CNNs).
The process typically includes feature extraction through multiple neural network layers, followed by prediction of object classes and bounding boxes. Advanced models such as YOLO, SSD, and Faster R-CNN can process entire images and detect multiple objects simultaneously, making them suitable for real-time and large-scale applications.
Object detection identifies both the type and location of objects, while image classification only determines what objects are present. Classification does not provide spatial information.
For example, an image classification model may label an image as “cat,” while an object detection model can identify multiple cats in the image and draw bounding boxes around each one. This makes object detection more useful for tasks that require spatial awareness, such as autonomous driving or surveillance.
Object detection uses bounding boxes to locate objects, while segmentation defines the exact pixel-level boundaries of each object. Segmentation provides more precise detail than detection.
There are different types of segmentation, including semantic segmentation, instance segmentation, and panoptic segmentation. While object detection is faster and less computationally intensive, segmentation is preferred when precise object shapes and boundaries are required, such as in medical imaging or advanced visual analysis.
The most popular object detection models include YOLO, SSD, Faster R-CNN, and RetinaNet, each optimized for different use cases. These models vary in speed, accuracy, and computational requirements.
YOLO is widely used for real-time applications due to its high speed. Faster R-CNN is known for high accuracy but requires more computational resources. SSD offers a balance between speed and accuracy, while RetinaNet performs well on detecting small and rare objects. Choosing the right model depends on the specific requirements of the task.
Object detection is used in industries such as autonomous driving, healthcare, retail, agriculture, and security. It enables systems to automatically analyze visual data and make decisions.
In autonomous vehicles, object detection helps identify pedestrians, vehicles, and traffic signs. In healthcare, it supports the detection of tumors and abnormalities in medical images. Retail systems use it for inventory tracking and customer behavior analysis, while security systems rely on it for surveillance and threat detection.
High-quality data is essential for training accurate object detection models. The performance of a model depends heavily on the quality, diversity, and annotation of the dataset. Object detection requires labeled data with precise bounding boxes and correct class labels. Poor annotation quality or imbalanced datasets can lead to inaccurate predictions. Techniques such as data augmentation, synthetic data generation, and class balancing are often used to improve model robustness and generalization.