

Why Is Data Quality Important in AI?
The performance of intelligence (AI) systems greatly depends on the quality of the data they use. Data accuracy, completeness, consistency, and timeliness are crucial for AI to make predictions and facilitate decision-making processes.
Data quality has practical implications – low-quality data can have harmful impacts on your business. For instance, according to The Revenue Marketer’s Guide by Integrate among 3.64 million leads generated annually, 45% are identified as “bad leads” due to duplicate information, incorrect formatting, unsuccessful email verification, and missing details.
Furthermore, there are financial implications linked to poor data quality. As per IBM’s research findings, the annual cost of poor data quality in the United States is estimated to be around $3.1 trillion.
It’s essential to understand that ensuring data quality is not just a necessity for AI systems; it plays a strategic role in driving businesses’ success.
Data Quality in the Machine Learning Lifecycle
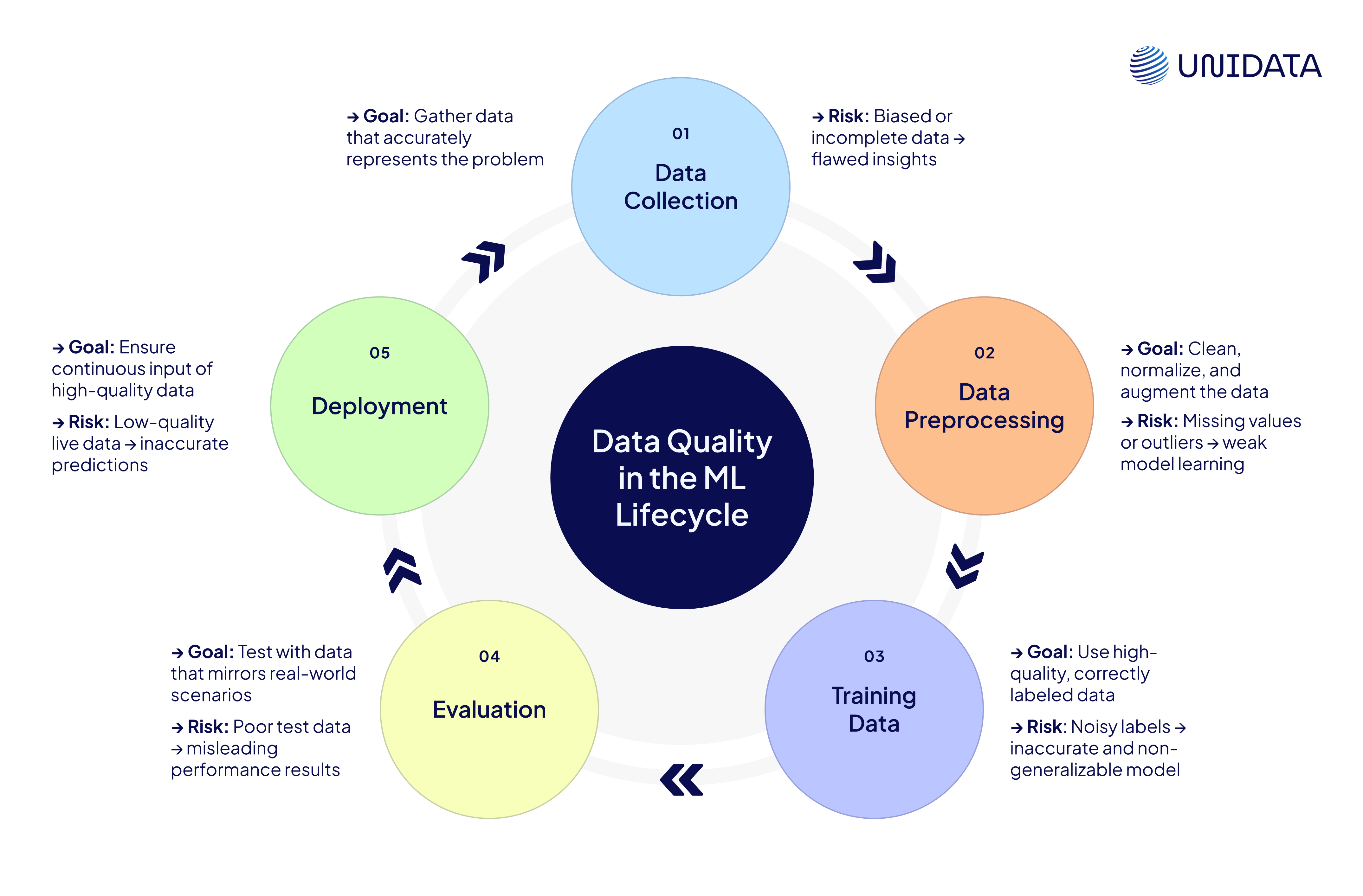
In the life cycle of machine learning (ML), the quality of data plays a role in every step – from data collection and preprocessing to model training, evaluation, and deployment.
When it comes to gathering data in the initial phase, the main aim is to acquire data that accurately represents the problem at hand. The model learns from what it sees – that’s why data of poor quality at this stage, such as biased or incomplete datasets, can lead to flawed insights.
During data preprocessing, the focus is on refining and reshaping the data. Problems such as missing values, outliers, or inaccuracies can greatly impact how well the model learns. Employing preprocessing techniques such as data normalization and data augmentation can improve the performance of deep learning models.
In the training phase, the quality of input data directly influences how effectively a model learns. High-quality and properly labeled data can lead to more accurate and generalizable models.

During the evaluation process, if the test dataset is of poor quality or doesn’t reflect real-world situations accurately, it may give a misleading picture of the model's performance.
Finally, during deployment, the model's ability to make accurate predictions in a live environment depends on the continuous input of high-quality data.
AI Projects Affected by Poor Quality of Data
Amazon’s Biased Recruiting Tool
The incident with Amazon's AI recruiting tool in 2018 is a prominent example of how data quality, particularly in terms of bias and representativeness, can significantly affect AI applications. Amazon created the tool with the goal of streamlining their hiring process, aiming to make it more efficient by automatically assessing resumes and ranking job candidates. However, the tool soon revealed a bias against female applicants.
This bias was not intentionally built into the algorithm – it stemmed from the historical data used to train the AI. The tech industry, including Amazon, had a long history of gender imbalance, with more men in technical roles. As a result, the AI system learned from the imbalances in its training data, which predominantly consisted of resumes from male candidates and decisions that favored them. This resulted in the AI devaluing resumes containing words like "women’s," as in “women’s chess club captain,” or resumes from candidates who graduated from women's colleges.
Amazon decided to halt the use of their AI recruiting tool. This situation highlighted a critical aspect of AI development: the need for careful consideration of data sources and the biases they may contain.
Uber’s Self-Driving Tragedy
In 2018, Uber self-driving car was involved in a fatal collision with a pedestrian in Tempe, Arizona. The subsequent investigation brought to light several issues concerning how the vehicle's AI system processed and responded to the sensor data.
Self-driving vehicles come equipped with an array of sensors – cameras, radar, and lidar that collectively generate vast amounts of data. This information is essential for understanding the surroundings, making decisions, and controlling the vehicle in real time. For these systems to operate efficiently, the data must be accurate, timely, and reliable. However, in the Uber incident, there was a failure in interpreting sensor data regarding the presence and movements of pedestrians.
The investigation by the National Transportation Safety Board (NTSB) following the accident revealed that the system did detect the pedestrian and her bicycle. However, there were misclassifications that caused a delay in the vehicles response. This tragic event underscores the critical need for robust data processing algorithms and system redundancy to ensure the safety and reliability of autonomous cars.
Ensuring high quality of data input for AI systems used in self-driving vehicles is a task that involves not only accurate sensors but also algorithms capable of making instant driving decisions based on this data.
The Failure of Google Flu Trends
Google Flu Trends (GFT) was a project launched by Google to track and predict flu outbreaks based on search query data. The concept was innovative: by studying the volume and pattern of searches related to flu symptoms, GFT aimed to detect flu outbreaks faster than traditional methods, such as reports from healthcare providers and laboratories.
Initially, GFT showed great potential in monitoring flu trends in real time, offering a valuable tool for public health surveillance and response. Nevertheless, over time, issues related to data quality emerged, significantly impacting the accuracy and reliability of the project.
The main challenge faced by GFT was its reliance on search terms that, although initially linked to flu outbreaks, were not consistently reliable indicators over time. External factors like media coverage of flu outbreaks could cause a surge in search activity not necessarily related to flu cases, leading to inaccuracies in the data. This phenomenon, known as "big data hubris," led to the overestimation of flu trends.
Moreover, the algorithm used by GFT failed to adjust to shifts in Google's search algorithms and changes in user behavior over time. This lack of adaptability further undermined the accuracy of its forecasts. For instance, Google's own improvements in search algorithms and the increasing use of mobile devices changed how people searched for information online, affecting the data GFT was based on.
The situation with Google Flu Trends serves as a reminder of the significance of upholding data quality in AI initiatives, particularly those heavily reliant on indirect indicators or proxy data for making predictions.
Best Practices for Improving Data Quality
Strategies for Data Cleaning and Preprocessing
Data cleaning and preprocessing are crucial steps in improving the quality of data before it’s used in AI models. These processes involve a variety of techniques aimed at correcting inaccuracies and ensuring consistency in the dataset. Some effective strategies include:
Normalization
The ML shouldn’t be distorted by the range of values. Normalization is the process of changing the numbers in a dataset so they all fall within the same range, such as 0 to 1. This makes it easier for AI systems to work with them and make fair comparisons.
Example:
Imagine a dataset with two features:
- Age (1–100)
- Income (1,000–100,000)
Without normalization, the model might weigh income more heavily due to its larger range, even though age might be just as important.
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
# Example data
data = pd.DataFrame({
'age': [20, 40, 60],
'income': [10000, 50000, 100000]
})
# Normalize to 0–1 range
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data[['age', 'income']])
print(pd.DataFrame(normalized_data, columns=['age_normalized', 'income_normalized']))
Before vs. After Normalization
| Feature | Raw Value | Normalized Value |
|---|---|---|
| Age | 50 | 0.49 |
| Income | 50,000 | 0.49 |
Data Transformation
This strategy improves the model's ability to learn patterns. This can include turning dates into a standard format, changing text to numbers, or adjusting values so they are easier to analyze.
Data Transformation Transforming raw data into a format that’s easier to analyze helps models detect meaningful patterns.
Example:
Date: 03/08/2023 → becomes:
- Year: 2023
- Month: 8
- Day: 3
This enables better time-based trend detection.
import pandas as pd
df = pd.DataFrame({'date': ['2023-08-03']})
df['date'] = pd.to_datetime(df['date'])
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
print(df)
Feature Encoding
Feature encoding is turning categories or labels into a numerical format so a computer can understand and use them. For example, if you have colors like red, blue, and green, you change them into numbers like 1 for red, 2 for blue, and 3 for green. This way, an AI system can easily work with these categories in its calculations.
Example:
Color: ["Red", "Green", "Blue"] → becomes:
- Red → 2
- Green → 1
- Blue → 0
(Encoded using label encoding)
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.DataFrame({'color': ['Red', 'Green', 'Blue', 'Red']})
encoder = LabelEncoder()
df['color_encoded'] = encoder.fit_transform(df['color'])
print(df)
Handling Missing Data, Outliers, and Duplicates
Missing Data
Techniques like imputation (filling missing values with statistical estimates) or using algorithms that support missing data are essential.
Missing data is a common issue in real-world datasets. When key values like age, income, or category are absent, it can reduce model performance or introduce bias. A common way to handle this is through imputation—filling in missing values using statistical estimates such as the mean, median, or mode.
Example – Mean Imputation
import pandas as pd
import numpy as np
# Sample dataset with a missing value
df = pd.DataFrame({'age': [25, np.nan, 40, 30]})
# Fill missing value with the mean of the column
df['age'] = df['age'].fillna(df['age'].mean())
print(df)
Outliers
Outliers are data points that differ significantly from the norm. Identifying and addressing outliers through methods like Z-score analysis or IQR (Interquartile Range) helps an AI model make reliable predictions.
Code Example – Z-score Method:
import pandas as pd
import numpy as np
from scipy import stats
# Sample dataset
df = pd.DataFrame({'feature': [10, 12, 11, 14, 15, 13, 300]}) # 300 is an outlier
# Remove outliers using Z-score
df = df[(np.abs(stats.zscore(df['feature'])) < 3)]
print(df)
Duplicates
Removing duplicate records is vital to prevent biased results. Automated tools and scripts are often used in this process, ensuring the uniqueness and reliability of the dataset.
Code Example – Removing Duplicates:
import pandas as pd
# Sample dataset with a duplicate row
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Alice'],
'age': [25, 30, 25]
})
# Drop duplicate rows
df = df.drop_duplicates()
print(df)
Importance of Data Governance and Management
Data governance and management encompass establishing policies, standards, and practices for data handling to maintain its accuracy, completeness, and consistency over time. A report by Gartner on data governance highlights its significance in achieving business objectives and enhancing operational efficiency. Proper data governance not only improves the quality of data but also ensures that the data is ethically and legally used, protecting the organization from data-related risks.
Key aspects include:
Data Curation
Assigning responsibility for data quality and compliance with data management policies.
Quality Monitoring
Regularly auditing data to assess its quality and adherence to established standards.
Data Lifecycle Management
Implementing processes for the effective creation, storage, archiving, and deletion of data.
Tools and Technologies for Data Quality Assurance
Maintaining data accuracy in artificial intelligence involves using tools and technologies that automate and improve the tasks of verifying, cleaning, and monitoring data. These resources are crucial for companies aiming to uphold the accuracy of their data throughout their AI projects lifespan.
Here are some notable tools and technologies used for data quality assurance:
| Tool/Platform | Category | Advantages | Disadvantages |
|---|---|---|---|
| IBM InfoSphere QualityStage | Data Profiling Tool | - Robust data profiling and cleansing capabilities - Ideal for large enterprises - Integration with other IBM products | - High cost - Steep learning curve - Best suited for enterprise-scale projects |
| Dataedo | Data Profiling Tool | - User-friendly interface - Great for data documentation - Lightweight and fast to deploy | - Limited data cleaning features - May not scale well for very large datasets |
| OpenRefine | Data Cleaning Solution | - Free and open-source - Excellent for quick, one-time data cleaning tasks | - Limited automation - Not suitable for large-scale enterprise usage |
| Alteryx | Data Cleaning Solution | - Powerful drag-and-drop interface - Extensive data transformation features - Good for analytics workflows. | - Expensive licensing - Requires training to use effectively |
| SAP Master Data Governance | Master Data Management (MDM) System | - Enterprise-grade MDM - Strong integration with SAP ecosystem - Supports governance and compliance. | - Complex to implement - High cost - Primarily suitable for SAP-centric organizations |
| PiLog MDRM | Master Data Management (MDM) System | - Specialized MDM capabilities - Strong focus on governance and data accuracy | - Less known in the global market - Limited integration outside MDM-specific tasks |
| SAS Data Management | Data Quality Management Software | - Comprehensive suite for data integration, cleansing, and governance - Strong reporting capabilities | - Premium pricing - May require SAS expertise to maximize utility |
| Precisely Trillium | Data Quality Management Software | - Deep profiling and validation tools - Real-time data quality insights | - High cost - Designed for larger enterprises |
| Ataccama | Automated Data Monitoring Tool | - AI-powered data quality monitoring - Unified data governance features - Scalable architecture | - Complex initial setup - Enterprise-oriented pricing. |
| Qlik Sense | Automated Data Monitoring Tool | - Visual analytics with embedded data validation - Easy integration with BI pipelines | - Limited advanced data cleaning features - Focused more on visualization than deep profiling |
Data Profiling Tools
Software like IBM InfoSphere QualityStage and Dataedo are used to analyze datasets and identify inconsistencies, outliers, or patterns that require attention. These tools help in understanding the data's structure and quality.
Data Cleaning Solutions
OpenRefine and Alteryx are examples of tools for cleaning and transforming data, fixing inconsistencies, filling in missing values, and correcting errors to ensure that datasets are ready for analysis.
Master Data Management (MDM) Systems
Tools like SAP Master Data Governance and PiLog MDRM are designed to help organizations create a single, unified data view across the enterprise. These systems are crucial for ensuring data consistency and accuracy across different sources and systems.
Data Quality Management Software
Solutions like SAS Data Management and Precisely Trillium offer comprehensive data quality modules that include features for data cleansing, enrichment, and monitoring, supporting ongoing data quality improvement initiatives.
Automated Data Monitoring and Validation Tools
Technologies like Ataccama and Qlik Sense provide automated monitoring capabilities. They help find data quality issues in real-time and maintain the ongoing accuracy and reliability of data.
The effectiveness of these tools often depends on their integration into the broader data management and analytics infrastructure of an organization. By effectively employing these technologies, businesses can enhance their data quality, leading to more effective AI applications.
Key attributes of data quality
Precision
High-quality data reflects reality accurately. Precision in data ensures a correct representation of the phenomena it intends to depict, free from inaccuracies or alterations.
For instance, within the healthcare sector, accurate patient records play a vital role in determining diagnosis and treatment decisions. A study highlighted the importance of data precision in health records, pointing out that subpar data quality could lead to incorrect treatment plans and adverse patient outcomes.
Completeness
Data should encompass all elements of the intended analysis or decision-making process. Inadequate data can skew AI analyses and decisions. For example, when examining customer data, missing information about buyers’ preferences or behaviors can lead to incorrect customer profiles, which in turn impact business strategies and outcomes.
Consistency
Consistency guarantees that data remains uniform across various datasets or databases by adhering to predetermined formats and standards. This aspect of data integrity is critical for AI systems that integrate information from various sources.
Timeliness
Timely data is up-to-date and relevant to the current period. In dynamic environments, the value of data diminishes rapidly over time, while utilizing irrelevant data in AI systems can lead to inaccurate outcomes. For instance, financial markets require timely data to make precise trading choices.
Reliability
Reliability pertains to how trustworthy the sources of data are and the uniformity of the methods used for data collection. Reliable data can be verified and is collected through tested methods. Ensuring data reliability in AI builds a foundation for dependable models.
Challenges in Ensuring the Quality of Data
Securing the quality of data in AI systems presents several challenges that are often multifaceted, touching on technical, organizational, and operational aspects.
Volume and Complexity
Managing the quality of diverse data presents an issue due to its sheer volume and diversity. With the rise of big data, organizations are facing an unprecedented amount of data, both structured and unstructured. IDC predicts that the global data sphere will reach 175 zettabytes by 2025, highlighting the magnitude of the data management task faced by businesses.
Data from Multiple Sources
Many AI systems rely on data sourced from different origins, each with varying formats, standards, and levels of quality. Bringing together this data into a unified format while upholding its quality is a complex endeavor.
Dynamic Data
It's important to understand that data is not stagnant – it evolves. Ensuring that data stays accurate, complete, and timely amidst constant changes presents a challenge. For instance, in the domain of AI-driven market analysis, the rapid changes in market conditions result in data becoming outdated. This necessitates continuous updates and validation to retain its relevance and accuracy.
Data Governance and Standardization
Creating and upholding data governance frameworks is essential for ensuring data quality. These frameworks should define policies and standards for managing data across areas like collection, storage, processing, and sharing. However, creating data governance frameworks and establishing compliance throughout an organization can be challenging.
The Human Factor
The human factor also plays a role in maintaining data quality. This encompasses challenges related to training, awareness, and the organizational culture regarding data management practices. Human errors, resistance to change, and undervaluing the importance of data quality can all compromise the quality of the data.
Conclusion
The success of any AI initiative rests on a single, fundamental pillar: data quality. No matter how advanced the algorithm or how powerful the infrastructure, AI systems are only as reliable as the data they are built upon.
High-quality data—accurate, complete, consistent, timely, and reliable—enables AI to learn effectively, make informed decisions, and deliver meaningful insights. It fuels everything from training and evaluation to real-time prediction in production. When data quality falters, so do the outcomes: biased algorithms, flawed automation, poor decision-making, and even safety failures, as demonstrated by real-world cases like Amazon’s recruiting tool, Uber’s autonomous vehicle accident, and Google Flu Trends.
Beyond technical performance, poor data quality has serious business implications—from wasted marketing spend on bad leads to financial losses estimated in trillions. Conversely, investing in robust data quality practices—from data preprocessing and transformation to governance, monitoring, and tool adoption—can lead to competitive advantages, increased trust in AI, and long-term value creation.
In the age of AI, quality isn’t a luxury—it’s a necessity. Organizations that prioritize and maintain high standards for data will be the ones that harness AI most effectively and responsibly.










