

Introduction
In the realm of machine learning (ML), data is the driving force that shapes intelligent systems. Much like how a skilled chef relies on quality ingredients to craft a masterpiece, a data scientist depends on reliable data to construct precise, effective models. This guide offers an in-depth look at data collection, providing valuable insights and actionable tips for both experienced professionals and newcomers to the ML field.
Why Data Collection Matters
Data collection is the cornerstone of any machine learning project. Without solid data, even the most advanced algorithms will struggle. Here’s why it’s so critical:
- Model Accuracy: The quality of the data directly impacts the accuracy of the model, leading to more reliable predictions and decisions.
- Bias Mitigation: Ensuring data is diverse and representative minimizes biases, fostering fairness and reliability.
- Cost Efficiency: Thoughtful data collection can streamline the process, saving time and resources throughout the ML pipeline.
- Regulatory Compliance: Following best practices in data collection helps you meet legal and ethical standards, ensuring that your work aligns with necessary regulations.
Types of Data
Understanding the different types of data is essential for effective data collection. Let's explore the three main categories:
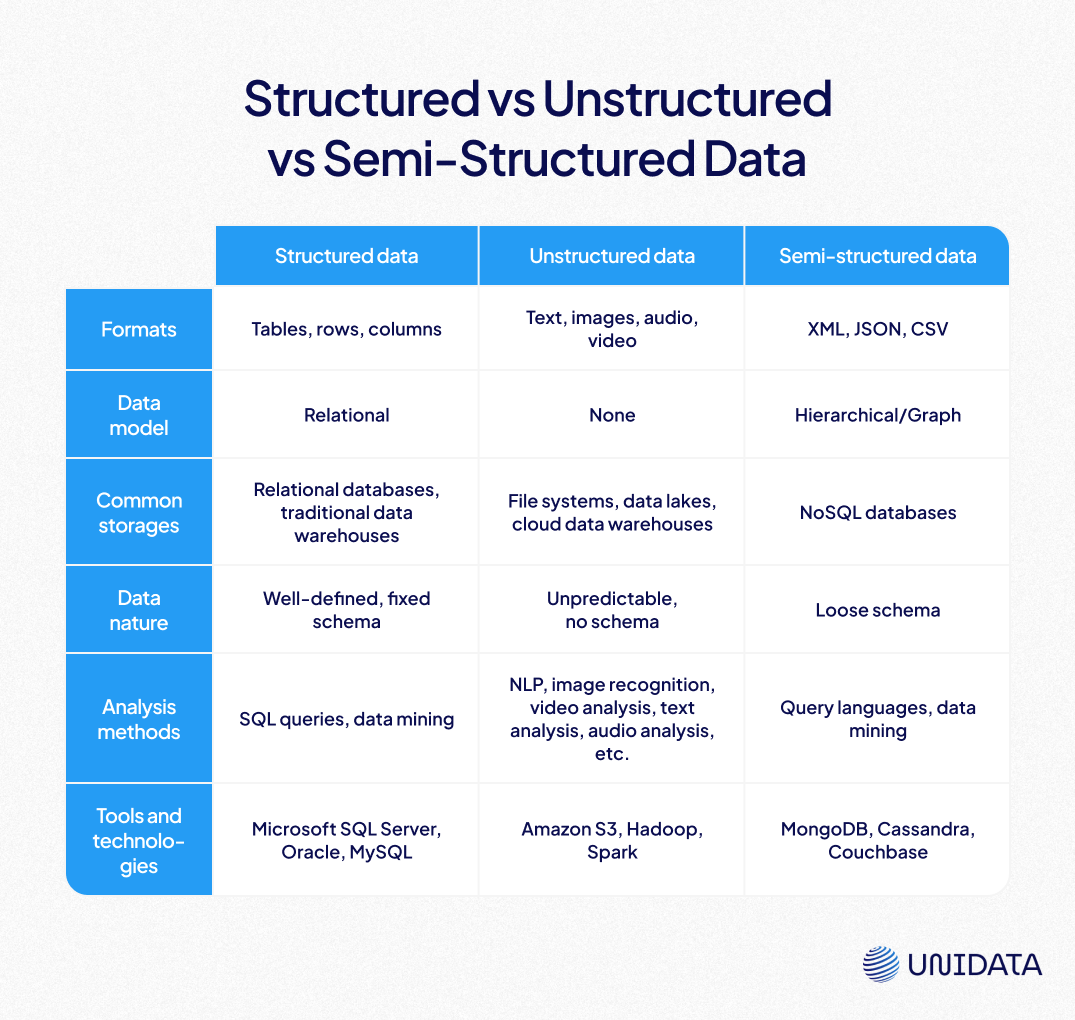
Structured Data
Structured data is organized and formatted in a way that makes it easy to search and analyze. Think of it as a neatly arranged bookshelf where each book has a specific place.
| Example | Format |
|---|---|
| Customer Database | SQL Table |
| Financial Records | CSV File |
| Sensor Readings | JSON Object |
Unstructured Data
Unstructured data lacks a predefined format or organization. It's like a pile of papers scattered on a desk, requiring more effort to sort through.
| Example | Format |
|---|---|
| Social Media Posts | Text |
| Images and Videos | JPEG, MP4 |
| Emails | Plain Text |
Semi-Structured Data
Semi-structured data combines elements of both structured and unstructured data. It has some organizational structure but is not as rigidly formatted as structured data.
| Example | Format |
|---|---|
| XML Documents | XML File |
| JSON Files | JSON Object |
| Log Files | Text with Tags |
Data Collection Methods
1. Third-Party Data Providers
Third-party data providers offer pre-collected and curated datasets that can be purchased or accessed through subscriptions. They also offer leading Data Collection projects.
Getting data from Data Providers has its strong advantages such as:
- Quality and Reliability: Data is often vetted and cleaned by the provider.
- Convenience: Saves time and resources compared to collecting data in-house.
- Diversity: Access to a wide range of data types and sources.
Cons:
- Cost: It can be expensive, especially for large or specialized datasets.
For example, at UniData, we offer curated, ready-to-use datasets designed to enhance biometric systems like facial recognition and liveness detection. By partnering with us, clients save valuable time that would otherwise be spent creating and managing the data collection pipeline from the ground up. We also specialize in managing custom data collection projects tailored to specific client needs.
Some data requirements simply can’t be met without expert help. When data needs are highly specialized, require specialized equipment, or involve coordinating an entire team, outsourcing to a company like UniData is the best solution. We provide professional support in the following areas:
- When strict adherence to complex technical specifications is necessary (e.g. when a subject needs to perform specific actions under supervision).
- When professional-grade equipment is required (such as high-end cameras or specialized audio recording tools).
- When the precision and quality of each individual task take precedence over data diversity.
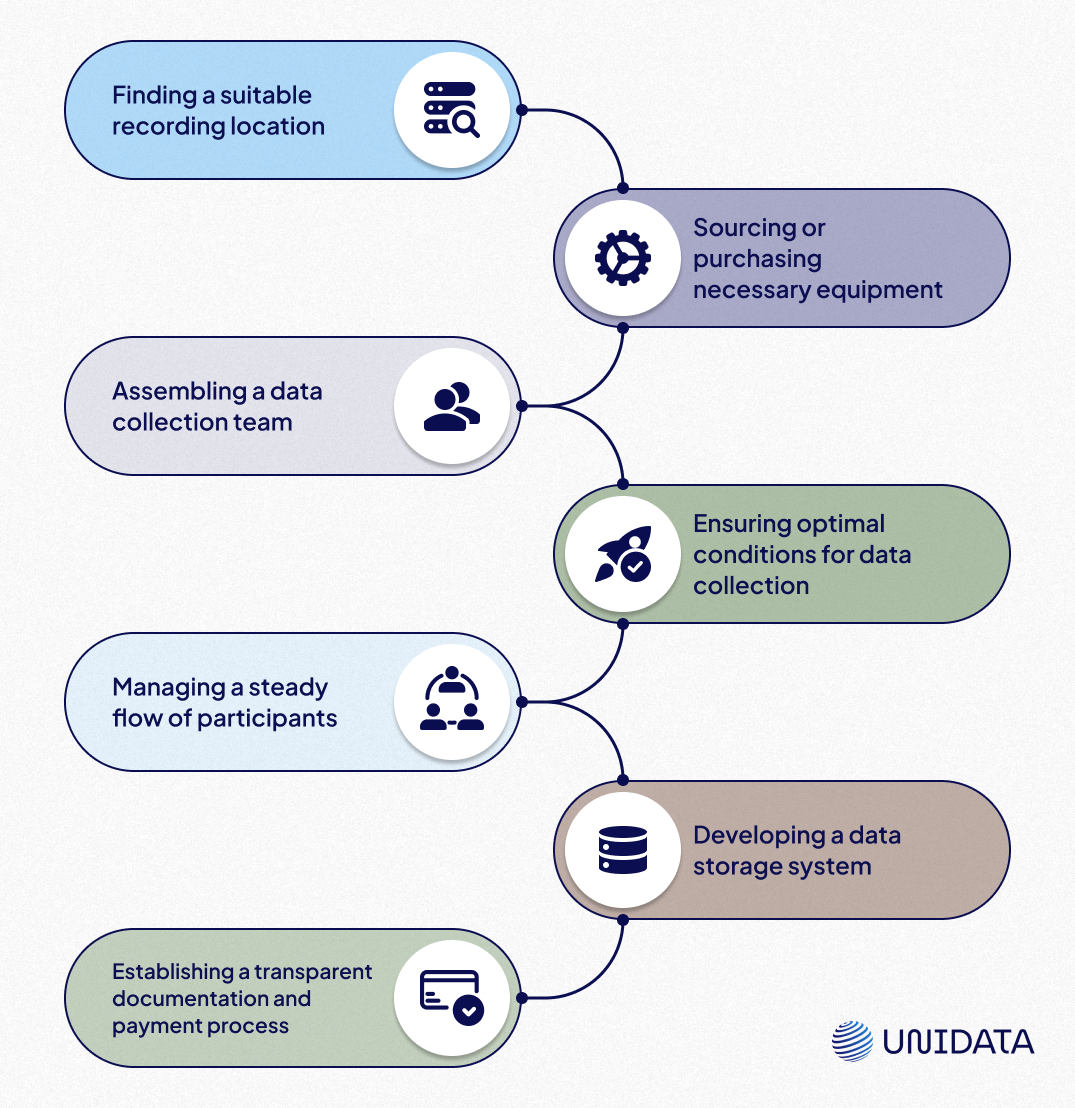
Stages of Offline Data Collection:
Below is an example of how we curate data collection projects:
2. Crowdsourcing
Crowdsourcing is a method of data collection where a large number of people participate online. This approach is particularly effective when gathering diverse data takes precedence over achieving perfect quality. It’s also ideal for tasks that need to be distributed to a broad audience, where the work is simple and easy for contributors to understand and complete.
Crowdsourcing Platforms
- Crowdsourcing platforms such as Amazon Mechanical Turk

- Social media networks and communities
- Internal or customer audience
When to Use Crowdsourcing?
Crowdsourcing shines when the value lies in data diversity rather than flawless quality. It’s the best choice when a large number of contributors are needed, or when the task is straightforward enough for individual participants to grasp. Additionally, crowdsourcing can be an effective solution when developers are able to verify the accuracy of each data point submitted.
Important to consider:
- Legal Compliance: Regulations regarding personal data collection (e.g., biometric data, voice recordings, vehicle license plates) must be followed. Many platforms prohibit unauthorized personal data collection.
- Platform Limitations: Each crowdsourcing platform has specific audience restrictions that can impact data diversity.
- Payment Speed: Slow payment processing can lead to low task ratings, reducing engagement and participation.
- Payment Methods: Different payment methods may limit the reach of contributors.
- Instruction Quality: Poorly written instructions lead to low-quality submissions. Striking a balance is crucial—short instructions may result in noisy data, while lengthy instructions may be ignored. Using visual and video-based instructions can help improve comprehension.
Internal Sources
Internal sources refer to data that is generated within your organization, such as transaction records, customer interactions, and operational logs. Leveraging internal data can provide deep insights into your business operations and customer behavior.
Pros:
- Control: Greater control over data quality and security.
- Relevance: Directly related to your business, making it highly relevant.
- Cost-Effective: Often already available, reducing the need for external data collection.
Cons:
- Bias: Internal data may be biased towards specific aspects of your business.
- Limited Scope: May not provide a broad perspective, especially for new markets or products.
- Integration: Requires integration with existing systems and processes.
Example:
An e-commerce platform uses internal sales data to analyze customer purchasing patterns and optimize inventory management. This data-driven approach helps them reduce stockouts and overstock situations.
Publicly Available Datasets
Numerous organizations and governments provide open datasets, making them an excellent starting point for ML projects.

- Kaggle Datasets (https://www.kaggle.com/datasets)

- UCI Machine Learning Repository (https://archive.ics.uci.edu/ml/index.php)

- Google Dataset Search (https://datasetsearch.research.google.com/)


- Open Government Data Portals (e.g., https://data.gov, https://data.europa.eu)
Web Scraping and APIs
Both web scraping and APIs are powerful methods for extracting data, each with its own advantages and challenges. The right choice depends on factors like data availability, automation needs, and compliance considerations.
Web Scraping
Web scraping involves automatically extracting data from websites, making it particularly useful for collecting large amounts of public information.
Pros:
- Scalability: Can handle vast amounts of data efficiently.
- Automation: Reduces manual effort and minimizes errors.
Cons:
- Legal Considerations: Must comply with website terms of service and data protection laws.
- Dynamic Content: Websites frequently change their structure, requiring constant script updates.
Example:
A marketing agency scrapes e-commerce websites to analyze consumer trends, helping clients refine their marketing strategies.
APIs
Application Programming Interfaces (APIs) enable programmatic access to data from various platforms, offering a structured way to retrieve information.

Pros:
- Standardized Access: Ensures consistent and reliable data retrieval.
- Real-Time Data: Provides up-to-date information on demand.
Cons:
- Rate Limiting: Many APIs restrict the number of requests per minute or day.
- Cost: Premium or high-usage access often requires payment.
Example:
A financial services company uses APIs to access real-time stock market data, enabling algorithmic trading models to make informed investment decisions.
Both methods have their place in data collection strategies—APIs are ideal for structured, real-time data access, while web scraping offers flexibility in gathering large-scale public information.
Sensors and IoT Devices
Sensors and Internet of Things (IoT) devices collect data from the physical world, such as temperature, humidity, and motion.
Pros:
- Continuous Monitoring: Provides real-time data for ongoing analysis.
- Diverse Applications: Useful in various industries, including healthcare, manufacturing, and agriculture.
Cons:
- Maintenance: Requires regular upkeep and calibration to ensure accuracy.
- Data Volume: Generates large amounts of data, which can be challenging to store and process.
Example:
A smart city project uses IoT sensors to monitor traffic flow and air quality. The data collected helps city planners optimize traffic management and improve environmental conditions.
Synthetic Data Generation
Synthetic data is created using algorithms or simulations to generate artificial yet realistic datasets — a process known as synthetic data generation.
For example, training models for passport data recognition can leverage synthetic images. This approach helps mitigate ethical and legal concerns while ensuring diverse data for training.
When to Use Synthetic Data?
- Collecting real-world data is too expensive or time-consuming.
- When working with sensitive personal data it must remain private.
- When supplementing real datasets with rare or underrepresented data classes, rather than replacing real data entirely.
Please consider that:
- Real data is still necessary as a foundation for training generative models.
- Synthetic data may contain artifacts that are imperceptible to the human eye but can impact model performance.
This technique is especially valuable in industries requiring data privacy (e.g., healthcare and finance) and in cases where rare event simulation is crucial, such as fraud detection or autonomous vehicle training.
Case Study: Combining Multiple Data Sources for Better Insights
Let’s say you work at a retail company that wants to optimize inventory management and customer experience. Instead of relying on a single source of data, you decide to pull insights from multiple channels:

- Internal Sales Data – Analyzing past sales to spot trends.
- Customer Surveys – Gathering direct feedback on what customers like (or don’t).
- Social Media Sentiment – Scraping reviews and comments to see public perception.
- Third-Party Market Research – Using industry reports to understand bigger trends.
- IoT Sensors in Stores – Tracking foot traffic and product movement in real-time.
By combining all these data sources, you get a much clearer picture of what’s working, what’s not, and how to improve. Whether you’re in retail, finance, AI, or any other field, mixing different types of data can lead to smarter, more informed decisions.
What to Consider When Collecting Data
Collecting data is about making sure it’s accurate, fair, ethically sourced, and usable in the long run. Here’s what you need to keep in mind to get the best results.
Bias and Representativeness: Avoid Skewed Data
Biased data leads to biased results. If your dataset isn’t diverse enough, your model or analysis could unintentionally favor certain groups or perspectives while ignoring others.
A good example is hiring algorithms trained mostly on resumes from one demographic group. Without diverse data, the system may develop unintended biases that disadvantage equally qualified candidates from different backgrounds. To prevent this, data collection should aim for broad representation across demographics, behaviors, and categories. If certain data points are underrepresented, techniques like oversampling or synthetic data generation can help balance things out.
Ethical and Legal Considerations: Follow the Rules
If your data collection involves personal information, transparency and consent are non-negotiable. Regulations like GDPR, CCPA, and HIPAA exist to ensure data is handled responsibly, and failing to comply can lead to legal trouble—not to mention a loss of trust.
For instance, healthcare organizations handling patient records must follow strict privacy guidelines. Even outside regulated industries, anonymization techniques can help protect sensitive data while still allowing for meaningful insights.
Scalability and Maintenance: Plan for Growth
Data collection isn’t a one-time task—it’s an ongoing process. As your dataset grows, automation, storage, and updates become critical.
Think of a financial firm tracking stock market data. If their pipeline can’t handle real-time updates, they risk basing decisions on outdated information. Regularly updating datasets, maintaining clear documentation, and ensuring infrastructure can scale with demand are key to keeping data reliable over time.

Best Practices for Data Collection
Collecting data isn’t just about grabbing as much as possible and hoping for the best. Whether you're working on a machine learning project, running a business, or just analyzing trends for fun, how you collect your data matters—a lot. To make sure you're collecting data the right way, here are some key things to keep in mind.
Know Your Goal Before You Start
Before diving in, ask yourself: What do I actually need this data for? Being clear on your goal helps you avoid collecting unnecessary information or missing critical details. If you're studying customer behavior, collecting random social media posts with no context will just clutter your dataset with noise.
Defining your goal upfront helps you pick the right data sources, formats, and collection methods—saving time and effort down the road.
Quality Over Quantity
It’s easy to fall into the trap of thinking more data = better results, but that’s not always true. High-quality, well-organized data beats massive amounts of messy, unreliable data any day.
Imagine you’re trying to train a speech recognition system. If half your dataset is full of background noise or misheard words, your model won’t learn correctly. That’s why it’s important to clean and validate data as you collect it. Watch out for duplicates, missing values, inconsistent formatting, and errors—because bad data leads to bad outcomes.
Keep Track of Your Sources and Methods
If you’ve ever looked at an old spreadsheet and thought, Where did I get this data from?, you already know the importance of documentation. Keeping track of where your data comes from, how it was collected, and what has been done to it makes it easier to organize, verify, and even reuse later.
Good documentation helps avoid confusion and ensures that you (or anyone else working with your data) can make sense of it. This is especially important when combining different datasets—without proper records, you might end up mixing apples with oranges (or worse, outdated and incorrect data with fresh, reliable data).
Respect Privacy and Ethical Guidelines
If you’re working with personal information, make sure you have permission to use it and follow relevant privacy laws like GDPR or CCPA. Even if you’re just scraping public data from websites, it’s worth checking terms of service to avoid legal trouble.
Store Data Securely and Efficiently
Once you've collected your data, where do you put it? Storing data securely and in an organized way is just as important as collecting it properly. If you're working with small datasets, a well-structured spreadsheet might be enough. For larger projects, cloud storage solutions like AWS, Google Cloud, or Azure can help manage, back up, and secure your data.
A few things to keep in mind:
- Security matters: Protect sensitive data with encryption and access controls.
- Backups save lives: Always have a backup plan in case something goes wrong.
- Scalability is key: If your dataset is growing, make sure your storage can handle it.
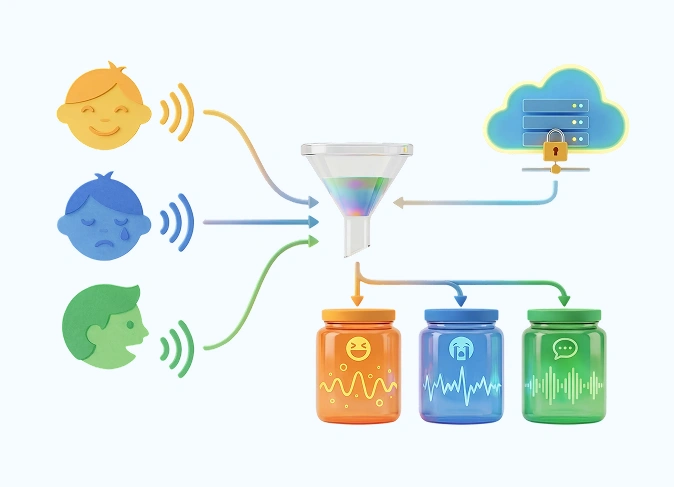
Audio Data Collection for Emotion-Sensitive Voice Systems
- Development of child response systems for laughter and crying
- 750 unique audio files featuring children's voices
- 1 month
Tools and Technologies for Data Collection
If you’re determined to dive into the Data Collection by yourself, leveraging these tools and technologies will be useful for streamlining the process. Here are some popular options:
Data Collection Tools
- Google Forms: For creating and distributing surveys.
- Beautiful Soup: A Python library for web scraping.
- Postman: For testing and using APIs.
- Raspberry Pi: For building IoT devices and sensors.
Data Storage Solutions
- Amazon S3: Scalable cloud storage for large datasets.
- Google BigQuery: Fully managed, serverless data warehouse.
- MongoDB: NoSQL database for semi-structured data.
Data Cleaning and Validation
- Pandas: A Python library for data manipulation and analysis.
- OpenRefine: A powerful tool for data cleaning and transformation.
- Trifacta: A user-friendly platform for data preparation.
Conclusion
Data collection is a multifaceted process that involves leveraging various methods and sources to gather the information needed for machine learning projects. Whether you're using surveys, web scraping, APIs, sensors, third-party data providers, or internal sources, each method has its unique strengths and challenges. By carefully selecting and combining these methods, you can ensure that your data is robust, relevant, and ready to drive meaningful insights and innovations.
Frequently Asked Questions (FAQ)
The most important aspect is ensuring the data is accurate, relevant, and representative. High-quality data leads to more accurate and reliable machine learning models.
Implement data validation checks, clean and preprocess data, and use multiple sources to reduce bias. Regularly review and update your data collection methods to maintain quality.
Key ethical considerations include obtaining informed consent, protecting privacy, ensuring transparency, and being accountable for data handling and storage.
Yes, web scraping is a powerful tool for collecting large amounts of public data. However, ensure you comply with website terms of service and data protection laws.
Popular tools include Google Forms for surveys, Beautiful Soup for web scraping, Postman for APIs, and Raspberry Pi for IoT devices. For data storage and processing, consider Amazon S3, Google BigQuery, and MongoDB.










