In the world of machine learning (ML), a model's effectiveness largely depends on the quality and characteristics of the data used for testing.
Test data, also known as testing data, play a crucial role in determining the efficiency and accuracy of machine learning models. These data sets are used to assess how well a model performs on tasks and adapts to new, unseen data.
Understanding Test Data
What Are Test Data in Machine Learning?
Test data in machine learning refers to a portion of a dataset specifically designated for evaluating the performance of a trained model.
Unlike training data, which helps the model identify patterns and develop decision-making algorithms, test data is intended to verify how the model handles information it has never encountered before. This process provides an objective assessment of the model's accuracy, generalization ability, and overall performance.

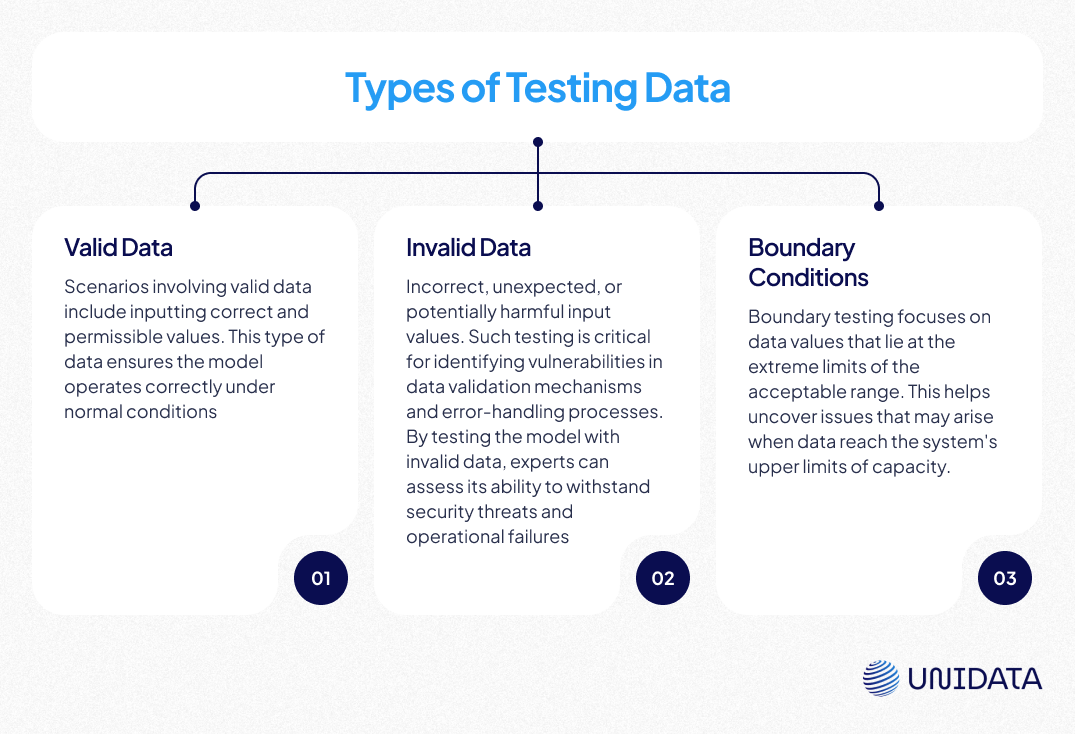
Types of Test Data
Test data can be categorized based on the nature of the dataset and the purpose of testing:
Comparison of Test, Training, and Validation Sets
Understanding the differences between test data, training data, and validation data is crucial in machine learning. It is also important to consider the various data types in ML when preparing these datasets to ensure balanced and representative samples.
| Data Type | Description |
|---|---|
| Training Dataset | Used to build and train the model, helping it identify patterns and make predictions based on the provided information. |
| Validation Dataset | Used during model training to fine-tune hyperparameters and optimize performance. |
| Test Dataset | Essential for evaluating how well the model performs on new data before deployment. |
Preparing Test Data
Preparing test data is a crucial step in both software development and machine learning model testing. Well-prepared data enable an objective evaluation of the model’s functionality, generalization ability, and robustness against errors and unexpected situations.
Methods for Collecting and Generating Test Data

Techniques for Ensuring Data Quality and Relevance
Data Cleaning
This process involves removing errors and inconsistencies such as duplicates, incorrect, or missing data, which enhances the dataset's quality and accuracy. Common methods for handling missing data include imputation (filling missing values with the mean, median, or mode of the column).
Data Validation
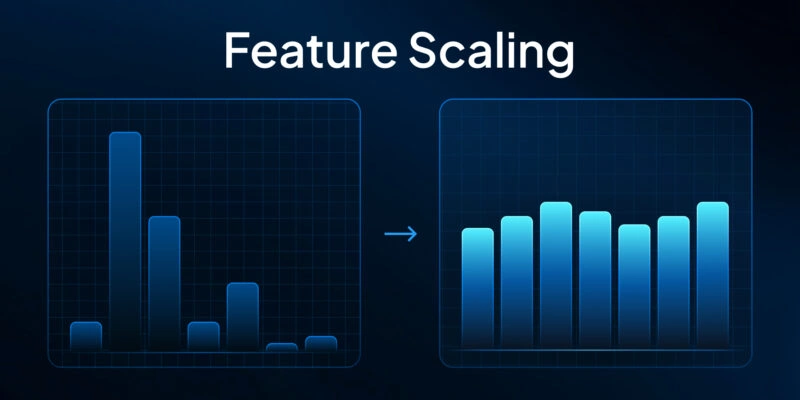
Ensuring that data meet standards and requirements, such as value ranges, format consistency, and correctness, guarantees their suitability for testing. Normalizing numerical features to a standard scale (e.g., 0 to 1 or -1 to 1) helps prevent one feature from dominating another—for example, when one feature ranges from 0–1000 and another from 0–1.
Aligning Test Data with Training Data
Bringing test data into a consistent format with the training dataset ensures compatibility and reliable evaluation.
Data Updates
Keeping test data up to date with environmental changes is necessary to maintain accuracy and efficiency.
Characteristics of High-Quality Test Data
Using accurate and high-quality test data is crucial for developing machine learning models, as it impacts model accuracy and the effectiveness of the testing process. Below are key characteristics of high-quality test data:

Using the Test Dataset
The test dataset serves as the final evaluator of a model's readiness. Here's how it is utilized:
- Final Evaluation: The model is assessed on the test dataset after training and fine-tuning to prevent metric distortion due to overfitting.
- Model Comparison: Test data enables an objective comparison of different models or versions of the same model.
- Error Analysis: Examining model errors on the test set helps identify weak spots, such as incorrect classifications.
- Generalization Check: The test dataset evaluates the model’s ability to generalize to new, unseen data.
Quality Evaluation Metrics
Classification Metrics
When evaluating the quality of a machine learning model, it's crucial to use appropriate metrics that reflect its performance accurately. Below are key classification metrics that help assess different aspects of a model’s predictive ability:
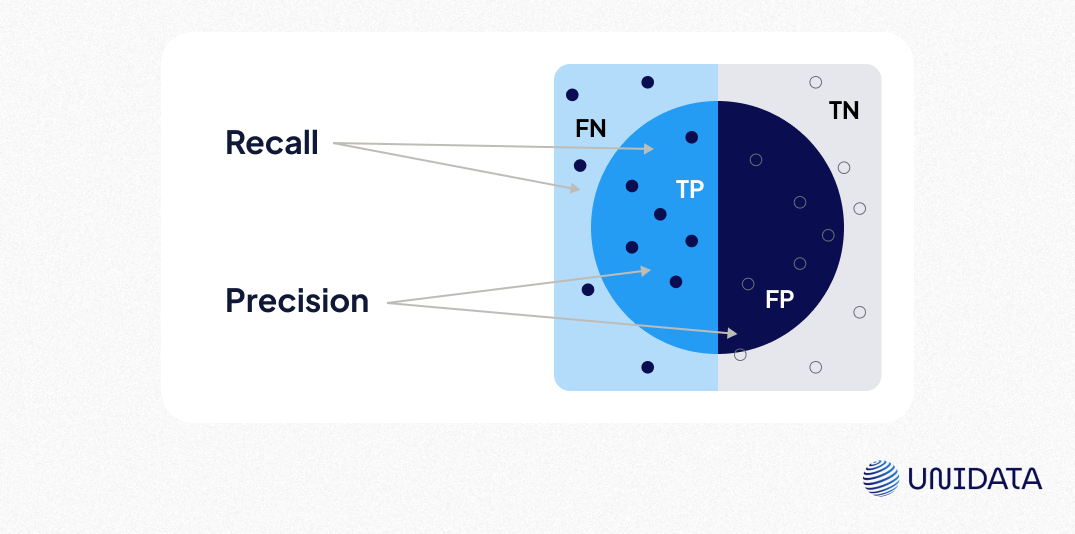
- Accuracy: The proportion of correct predictions out of all predictions. It can be misleading if the data is highly imbalanced.
- Precision: The proportion of instances classified as positive that are actually positive. It does not account for false negatives (FN), which may be critical in some cases.
- Example: Imagine a warship identifying enemy vessels (positive class). If it only detects actual threats but misses many others, it has high precision but low recall.
- Recall: The proportion of correctly identified positive cases. It does not consider false positives (FP), where the model incorrectly classifies negative instances as positive.
- Using the warship analogy, if it spots all enemy vessels but sometimes misidentifies neutral ships as threats, it has high recall but lower precision.

- F1-Score: The harmonic mean of precision and recall. This metric is used when a single measure is needed to balance false positives and false negatives.
- Example: Think of a team on the warship—one group focuses on precision (avoiding false alarms), while the other prioritizes recall (ensuring no enemy goes undetected). The F1-score helps strike a balance between these efforts for optimal performance.

Regression Metrics
For regression tasks, where the goal is to predict continuous values, the following metrics are commonly used:
- Mean Squared Error (MSE): Calculates the average squared difference between predicted and actual values. Larger errors are penalized more heavily, making this metric sensitive to outliers.
$$ MSE = \frac{1}{n} \sum_{t=1}^{n} e_t^2 $$
- Root Mean Squared Error (RMSE): The square root of MSE, allowing error interpretation in the same units as the predicted values. RMSE is particularly sensitive to large outliers, as squaring the errors amplifies their impact.
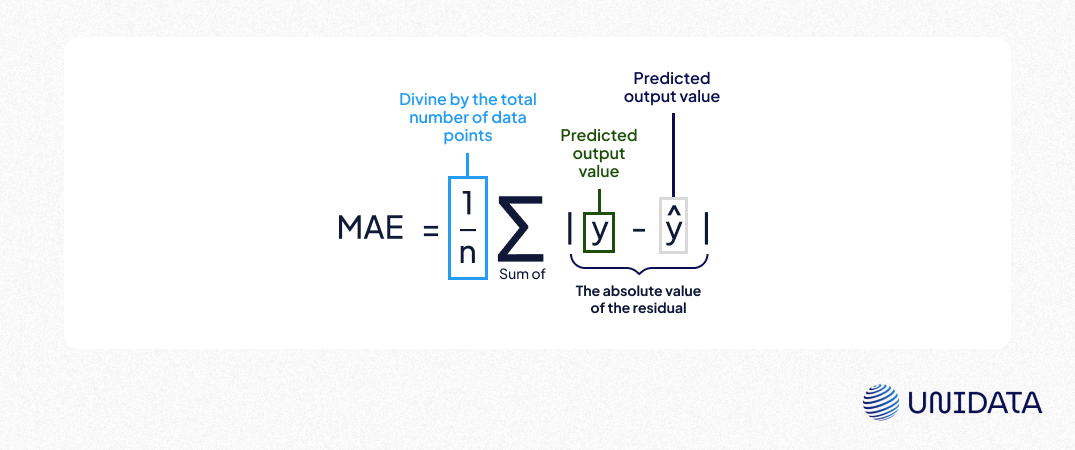
- Mean Absolute Error (MAE): Measures the average absolute deviation between predicted and actual values, indicating the average prediction error. Unlike RMSE, MAE treats all errors equally, making it less sensitive to outliers.
RMSE vs. MAE:
If a model makes a large error, RMSE will increase significantly due to the quadratic nature of the metric, whereas MAE will remain more stable, as it only considers absolute error values.
- Example: Imagine measuring wave heights—RMSE will emphasize the highest waves, while MAE will show the average height of all waves.
How Much Training Data is Needed?
Determining the optimal training data size is like packing for a trip—too little, and you're unprepared; too much, and you're overloaded. The ideal amount depends on several factors:
- Model Complexity: Simple models (e.g., linear regression) require fewer data points to perform well compared to complex models like deep neural networks.
- Task Complexity: More complex tasks require more data examples.
- Data Quality: High-quality data reduces the need for large volumes.
- Empirical Testing: Use techniques like learning curves to evaluate how model performance changes with increasing data size.
Challenges of Training and Evaluating Model Quality
Overfitting and Underfitting
Training and evaluating machine learning models come with several challenges that can impact their performance and reliability. Below are some common issues and potential solutions to improve model quality.

- Overfitting occurs when a model memorizes the training data too well, including noise and irrelevant details, but struggles to generalize to new data. This leads to high accuracy on the training set but poor performance on unseen examples.
- Underfitting happens when a model is too simplistic and fails to capture the underlying patterns in the data. As a result, it performs poorly on both the training and test datasets.
Biased or Insufficient Test Data
Biased test data can lead to skewed model predictions, making the evaluation process unreliable. If the test data does not accurately represent real-world conditions, the model’s performance metrics may be misleading.
Insufficient test data means there is not enough information to properly evaluate the model’s performance, increasing the risk of inaccurate assessments. Solutions are:
- Stratified sampling: This is a sampling method in which the entire dataset is divided into several mutually exclusive subgroups, known as strata, and a sample is then drawn from each stratum. This approach ensures that different subgroups within the dataset are adequately represented in the final test set, leading to a more balanced and fair evaluation.
- Generating synthetic data or applying bootstrapping to artificially expand the dataset, providing more diverse examples for training and evaluation.
Conclusion
Test data plays a crucial role in assessing and improving machine learning models. A well-prepared test dataset ensures an objective evaluation of model performance under real-world conditions, helping to fine-tune the model and improve its generalization capabilities.