Introduction
Imagine you’re a librarian sorting thousands of books in a huge library. Each book is like a piece of data, and finding what you need can be overwhelming without proper organization. In the digital world, data curation is the careful process of organizing and managing information so it’s accurate, easy to find, and useful. But why does this matter so much today? Let’s explore the key steps of data curation and see how it helps unlock the true value of information.
Definition of Data Curation
Data curation is part of the data management process. It involves a comprehensive approach to managing, organizing, and enhancing the value of data throughout its lifecycle. The goal is to make sure that data remains accurate and accessible over time.
Data curation involves collecting, organizing, annotating, preserving, and sharing data to make it more useful for individuals, groups of people (e.g., researchers, policymakers, businesses), or the general public. It plays a critical role in preparing high-quality training data for machine learning and AI models, ensuring that the data is accurate, well-labeled, and context-rich. Data curation is not just about storing data – it’s about ensuring data quality, context, and relevance.

Why is Data Curation Important?
Today, the volume of generated data is expanding rapidly: International Data Corporation (IDC) estimates that 175 zettabytes of data will be created annually by 2025. This immense volume of data demands an all-encompassing and effective approach to storing and curating data.
Data curation is crucial for several reasons:
Quality Control
Data curation helps ensure that the data you’re using is correct and reliable. When data is clean and free of mistakes, you can trust it to make the right decisions. Without quality control, you might base decisions on inaccurate or incomplete data.
Example of quality control in data cleaning:
# Checking for outliers or extreme values in the dataset import numpy as np # Assume df is the DataFrame with numerical data outliers = df[(np.abs(df['col1'] - df['col1'].mean()) > 3 * df['col1'].std())] print(outliers)
Efficiency
When your data is well-organized and easy to find, you can work faster and save time. If the data is messy and disorganized, it takes longer to find what you need. Curating your data makes it easier to access and analyze, saving time and making everything more efficient.
Example of optimizing data structure for better efficiency:
# Indexing a column to speed up search operations in a large dataset
df.set_index('col1', inplace=True)
Long-Term Value
Curating your data ensures it’s useful in the long run. By cleaning and organizing it properly, you can use the same data for future research or projects. This makes your data a valuable resource that keeps on giving.
Example of adding long-term value by documenting data:
# Adding documentation or notes about the dataset for future reference df.attrs['last_updated'] = '2025-04-01' df.attrs['data_origin'] = 'Customer Survey 2025'
Data Verification
Data curation is especially important in research. It helps make sure the data is accurate and can be checked by others. When data is properly curated, others can verify your results and build on them, which is important for research to be trusted and useful.
Example of verifying data consistency with a dataset:
# Ensuring data consistency by comparing two datasets
df1 = pd.read_csv('dataset1.csv')
df2 = pd.read_csv('dataset2.csv')
# Checking for any discrepancies between two datasets
assert df1.equals(df2), "Datasets do not match"
The Data Curation Process
Data curation is like refining raw gold into pure, valuable metal. It involves multiple steps, each designed to enhance the usability and reliability of data.
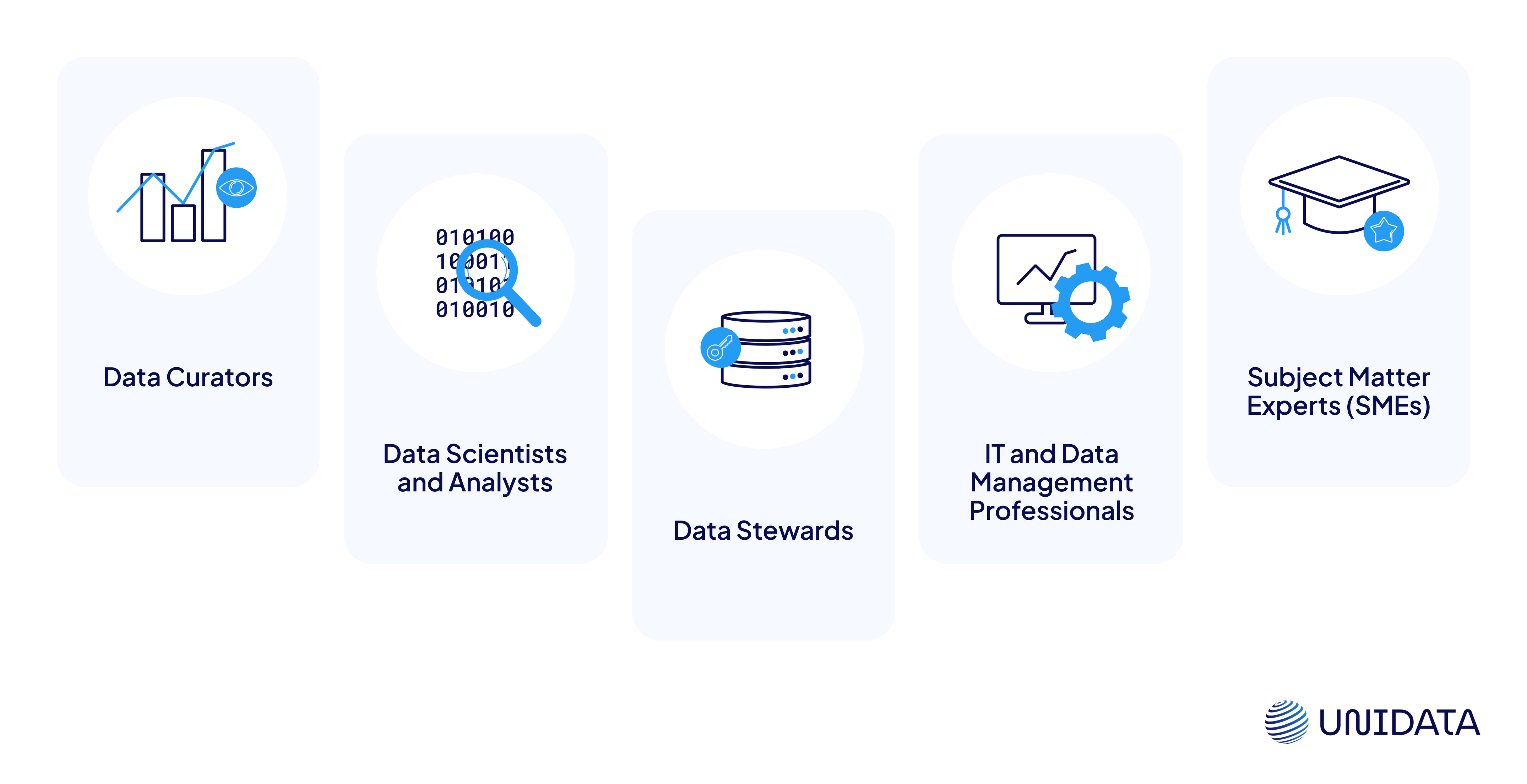
Who is Involved in Data Curation?
Just as a well-run library relies on librarians, data curation depends on several key roles:
Data Curators
These are the professionals who lead the curation process. They have a strong understanding of both the subject matter and the technical aspects of data management.
Data Scientists and Analysts
These individuals focus on analyzing the data, deriving insights, and ensuring the data is ready for analysis. They play a key role in data cleaning and annotation processes.
Data Stewards
Data stewards and curators work together to maximize the value of data. Stewards are responsible for the data governance aspect: they ensure that data is managed according to the organization’s policies, compliance requirements, and ethical standards.
IT and Data Management Professionals
These professionals focus on the technical aspects of storing, preserving, and securing the data. They manage databases, storage systems, and data security protocols.
Subject Matter Experts (SMEs)
SMEs provide essential knowledge about the context and use of the data, assisting in its annotation and ensuring its relevance and accuracy.
Responsibilities of Data Curators
Data curators have a comprehensive set of responsibilities that span the entire data lifecycle:
Assessment and Acquisition
Evaluating potential data sources and overseeing the data collection process to make sure it meets all the requirements.
Quality Assurance
Implementing processes to check and maintain the quality of the data.
Metadata Management
Creating and managing metadata so the data is well-documented and its lineage is clear.
Access and Sharing
Establishing protocols for data access, sharing, and distribution. Data curators also ensure compliance with data privacy and security policies.
Preservation
Implementing strategies for the long-term preservation of data, choosing the right storage solutions and formats.
Community Engagement
Communicating with end-users, stakeholders, and the broader community to ensure the data meets their needs.
Main Steps in the Data Curation Process
1. Data Collection
First, data is gathered from various sources, including sensors, surveys, transactions, or online interactions. During this phase, it’s crucial to ensure that data collection meets ethical and legal requirements.
Example of collecting data from an API:
import requests url = "https://api.example.com/data" response = requests.get(url) data = response.json() # Retrieved data in JSON format print(data)
2. Data Assessment
Once collected, the data undergoes an assessment phase where its quality and accuracy are evaluated. This involves checking for completeness, reliability, and relevance to the intended purpose.
Example of checking for missing values in a dataset:
import pandas as pd
df = pd.read_csv("dataset.csv")
print(df.isnull().sum()) # Displays the count of missing values per column
3. Data Cleaning
Next, data undergoes cleaning: errors are rectified and inconsistencies are identified during this phase. Data cleaning ensures the integrity of the dataset.
Example of removing duplicates and filling in missing values:
df.drop_duplicates(inplace=True) # Remove duplicate rows df.fillna(method='ffill', inplace=True) # Fill missing values with the previous valid entry
4. Metadata Creation
During this stage, metadata is added to the dataset, to provide deeper understanding of the data's origin, context, and format.
Example of adding metadata to a DataFrame:
df.attrs["source"] = "Survey 2025" df.attrs["description"] = "Dataset containing customer feedback data"
5. Data Transformation
Data needs to be transformed into a standardized format. This will make it easy to find and analyze data. Data transformation may involve standardizing naming conventions for variables or fields within your dataset.
Example of standardizing column names:
df.columns = [col.lower().replace(" ", "_") for col in df.columns] # Convert column names to lowercase and replace spaces with underscores
6. Data Storage
After undergoing all these steps, data is then stored in a suitable format and location – for example, in databases, data warehouses, or cloud storage solutions.
Example of saving data to a CSV file:
df.to_csv("cleaned_data.csv", index=False)
Example of storing data in an SQLite database:
import sqlite3
conn = sqlite3.connect("database.db")
df.to_sql("data_table", conn, if_exists="replace", index=False)
conn.close()
7. Data Preservation
Long-term preservation is necessary for data to remain accessible. This includes maintaining data’s format compatibility and safeguarding against data loss.
Data Preservation Example of archiving data:
import shutil
shutil.make_archive("dataset_backup", 'zip', "cleaned_data.csv") # Create a ZIP archive
8. Data Sharing and Access
The final step is to make sure the data is available to users. This requires establishing access controls and distribution mechanisms that maintain openness and privacy balance.
Example of providing data access via an API:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route("/data", methods=["GET"])
def get_data():
return jsonify(data)
if __name__ == "__main__":
app.run(debug=True)
Data Curation vs Data Management: What Is the Difference?
Data curation and data management are two critical processes in data science. While they overlap in certain areas, each process has distinct objectives, methods, and outcomes.
| Aspect | Data Curation | Data Management |
|---|---|---|
| Goal | Enhancing the usability and value of data for specific research or analysis | Overseeing the entire lifecycle of data to ensure its availability and quality |
| Focus | In-depth handling of specific datasets | Broad oversight of all data assets |
| Activities | Selection, annotation, enrichment, and preservation of data | Data architecture design, integration, storage, security, governance, and policy implementation |
| Outcome | A dataset that is ready for specific analytical or research needs | A structured environment where data is securely stored, accessible, and managed |
| Tools Used | Data analysis software, metadata management tools, data archiving systems | Database management systems, data governance tools, security software |
Challenges in Data Curation
Data Volume and Variety
The sheer volume and diversity of data types can be overwhelming, making it difficult to curate data effectively. Innovative methods in artificial intelligence (AI) and machine learning (ML) can help overcome this challenge by automating parts of the curation process. Automation saves time and alleviates the workload, allowing data curators to focus on the important parts of the process.
Data Quality
Ensuring data quality is a widespread challenge, given the various sources and potential for errors. To maintain high data quality, curators should implement strict QA protocols, including regular audits and validation checks.
Resource Constraints
Data curation is a multistage process that often requires significant resources for hiring, including skilled personnel and employing advanced technology. Investing in automation from the start can significantly cut expenses in the future.
Compliance and Security
Adhering to data privacy regulations and ensuring the security of data is becoming increasingly challenging. Compliance standards are hard to implement, while failures can be quite costly: GDPR fines can reach 20 million euros or 4% of a company’s global annual turnover. That’s why comprehensive data governance policies that align with legal requirements should be developed from the get-go. Moreover, implementing robust security measures will only facilitate compliance with legal requirements in the future.
Tools and Technologies for Data Curation
Software and Platforms
Several software solutions and platforms have been developed to support the various aspects of data curation:
Data Management Platforms
Platforms like CKAN and Dataverse provide solutions for data publishing, sharing, and management. These platforms offer useful features such as metadata creation, data storage, and access control.
Data Cleaning Tools
Software such as OpenRefine and Trifacta are designed to clean and transform data, helping curators ensure accuracy and consistency.
Metadata Management Tools
Dublin Core The Dublin Core or Dublin Core Metadata Element Set (DCMES), is a set of 15 main metadata items used to describe digital or physical resources. It allows for the detailed documentation and annotation of datasets. Also, MODS (Metadata Object Description Schema) is a valuable resource in data curation: it’s a bibliographic metadata standard. It’s used as a basis for the representation of bibliographic data in machine-readable form.
Digital Preservation Systems
Tools like Archivematica and Preservica ensure the long-term preservation of digital data, ensuring its ongoing relevance.
Automation in Data Curation
Data scientists complain that 80% of their time is spent preparing data for analysis and only 20% of the time is used for the actual analysis. Automation plays a critical role in enhancing the efficiency and accuracy of the data curation process. Machine learning algorithms and AI can automate repetitive tasks such as data cleaning, classification, and annotation. For example, ML models can be trained to identify and rectify inconsistencies in datasets, reducing the manual workload and minimizing human errors.
Automation also extends to the extraction and analysis of data. Natural Language Processing (NLP) technologies, for instance, can automatically analyze textual data, extract relevant information and insights. This significantly speeds up the data curation process.
The integration of these automated tools and technologies into data curation workflows not only streamlines the process but also enables data curators to focus on more strategic aspects of data management, such as quality analysis and decision-making. With the increasing complexity and volume of data, automation in data curation is becoming not just beneficial but essential in managing data efficiently.
Case Studies: Data Curation Across Different Industries
Healthcare: Genomic Data Curation at NCBI
The National Center for Biotechnology Information (NCBI) curates genomic data through its GenBank database, a comprehensive public database of nucleotide sequences and supporting bibliographic and biological annotation. This curation is vital for research in genomics, medicine, and biology, facilitating scientific discoveries and advancements in healthcare.
Finance: Bloomberg's Financial Data Services
Bloomberg is a prominent example in the financial industry, providing extensive data curation through its financial data services. Bloomberg collects, integrates, and delivers high-quality financial information, including market data, pricing, analytics, and news, to support investment and financial decisions worldwide.
Retail: Walmart's Data Café
Walmart has established a data analytics hub known as the Data Café (Collaborative Analytics Facilities for Enterprise), where vast amounts of data from over 200 sources, including sales, finance, social media, and logistics, are curated and analyzed to improve decision-making and operational efficiency in real-time. This private cloud processes 2.5 PB of data every hour. More than 200 streams of external and internal data, along with 40 PB of transactional data, can be managed, modeled, and visualized.
Conclusion
In summary, data curation is an essential process for managing data throughout its lifecycle. By carefully collecting, organizing, cleaning, and preserving data, organizations can ensure that the data remains accurate, useful, and accessible over time. The importance of data curation has only increased as the amount of data being generated grows rapidly. Data curation is not only about storing data but also about enhancing its quality, making sure it is relevant, and making it easy to access for future use.
With the right approach, data curation adds significant value, improving decision-making processes, increasing efficiency, and ensuring that data can be trusted and verified, especially in research and scientific fields. As technology continues to evolve, incorporating tools like automation and machine learning into the data curation process will make it even more efficient and effective.
In an era where data is one of the most valuable assets, data curation ensures that organizations and individuals can harness the full potential of their data, now and in the future. Whether in healthcare, finance, or retail, the proper curation of data is fundamental to making informed decisions and driving progress across various industries.