
SWE-Bench Coding Tasks Dataset
SWE-Bench Coding Tasks Dataset is an extended programming languages dataset that builds on the original SWE-Bench benchmark with broader language coverage, golden/test patches, and real-world coding tasks like bug fixing, code completion, and automated code review. It supports coding agents, language models, and developer tools with verified benchmark scores and multi-language test sets.
-
- files
- 8,712
-
- programming languages
- 6

- Programming languages
- Machine Learning
- Automated Code Review
- Bug Fixing
SWE-Bench Coding Tasks Dataset is an extended programming languages dataset that builds on the original SWE-Bench benchmark with broader language coverage, golden/test patches, and real-world coding tasks like bug fixing, code completion, and automated code review. It supports coding agents, language models, and developer tools with verified benchmark scores and multi-language test sets.
- Programming languages
- Machine Learning
- Automated Code Review
- Bug Fixing
-
- files
- 8,712
-
- programming languages
- 6
Dataset Info
| Characteristic | Data |
| Description | An extended benchmark of real-world software engineering tasks with enhanced artifacts and broader language coverage |
| Data types | Text |
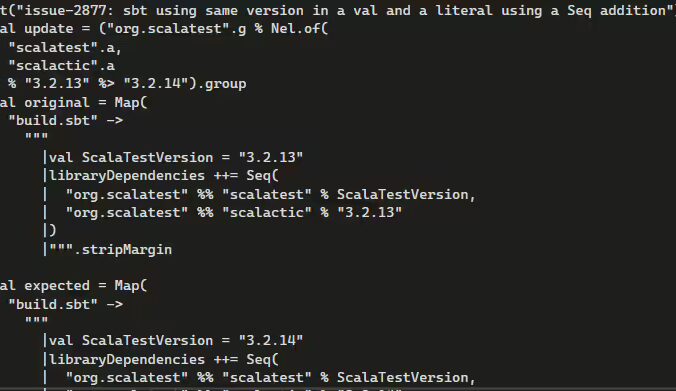
| Tasks | Bug fixing, code completion, pull request generation, automated code review |
| Total number of files | 8,712 |
| Total number of people | 30 |
| Labeling | Annotated with golden patches, test patches, post-patch reference states, and metadata stored in parquet files (e.g., repository name, issue/PR identifier, diffs, test results) |
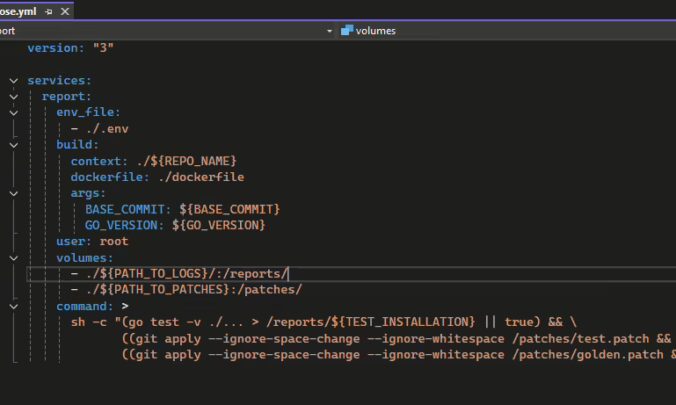
| Programming languages | C#, Go, PHP, Rust, Kotlin, Ruby |
Technical
Characteristics
| Characteristic | Data |
| Files Extensions | parquet (metadata), .patch (golden/test patches), .txt/.xml (reference outputs), .yml (docker-compose), Dockerfile, Makefile, .env |
| Models | Compatible with original Multi-SWE-Bench execution tools and models designed for code understanding and generation |
| File Size | 8.85 GB |
Dataset Use Cases
FAQs
Unidata Cases

Digital Tree Passport Annotation for Forest Mapping
- Forestry Monitoring & GIS
- 2 months
- 200,000 trees, 10 species classes

License Plate Annotation for Vehicle Recognition System
- 100,000 images with detailed license plate markup (bounding boxes, digits, regional symbols)
- 2 weeks
Sentiment Annotation for Brand Monitoring
- Marketing & Consumer Insights
- 12,000 text samples, 3 sentiment classes (positive, negative, neutral)
- 3 weeks

Surveillance Video Annotation for Entrance Monitoring
- Surveillance & Security
- 90 minutes of video from three cameras, approximately 50-60 thousand frames
- 2 week
Similar Datasets
-

 Commercial
Commercial
- PII
- Data generation
- Security
- Anti-spoofing
- Computer Vision
Synthetic Printed USA Passports Dataset
Synthetic Printed USA Passports Dataset is a high-quality synthetic passport dataset containing 9,600 AI-generated passport images designed for training OCR and computer vision models in identity verification and PII extraction. This USA passport dataset includes varied angles, lighting conditions, backgrounds, and distances, with detailed metadata for accurate document analysis and model training.
9 600 Images
-

 Commercial
Commercial
- Facial Recognition
- Computer Vision
- Machine learning
- Data generation
- Security
DeepFake Videos Dataset
The deepfake dataset contains real and AI-generated deepfake videos, featuring diverse subjects with detailed metadata on age, gender, and ethnicity to help train powerful deepfake detectors
10,000+ files
7,000+ people -

 Commercial
Commercial
- Know your customer
- Data generation
- Computer Vision
- Security
- Anti-spoofing
Synthetic Passports Dataset
The passport dataset comprises synthetic document images from multiple countries with metadata and is designed for training AI models in face recognition, identity verification, and document analysis to detect fake passports and prevent identity fraud
100 000 Images
100+ Countries -

 Commercial
Commercial
- NLP
- LLM
- Classification
- Data Collection
- GPT
LLM Text Generation Dataset
LLM Text Generation Dataset provides high-quality training data for language models, containing diverse text generations across multiple domains to enhance generative AI capabilities
4 Millions+ logs
32 Languages
3 Models of GPT
Why Companies Trust Unidata's Datasets
Share your project requirements, we handle the rest. Every service is tailored, executed, and compliance-ready, so you can focus on strategy and growth, not operations.
What our clients are saying

UniData

Data purchase
Our team got in touch with UniData for purchasing video data. The team at UniData was transparent, timely, and pleasant to communicate and negotiate with. Their samples and descriptions aligned well with the data we received. We will certainly reach out to UniData again if we're in search of 3rd party video data.

Data is well organized and easy to…
Data is well organized and easy to consume. We could download and use it for training within few hours of receiving the data links.
Our Clients Love Us
Ready to get started?
Tell us what you need — we’ll reply within 24h with a free estimate

- Andrew
- Head of Client Success
— I'll guide you through every step, from your first
message to full project delivery
Thank you for your
message
We use cookies to enhance your experience, personalize content, ads, and analyze traffic. By clicking 'Accept All', you agree to our Cookie Policy.