Your model won’t guess a face out of thin air. It learns. From pixels, patterns — and the datasets you feed it. And here's the catch: the quality of your data defines everything. Accuracy. Bias. Speed. Security.
So if you're working on face recognition in 2025 — whether it's unlocking doors, verifying selfies, or flagging deepfakes — these are the datasets that actually matter. No filler. No fluff. Just the ones used, cited, or benchmarked by teams who take face data seriously.
How to Tell If a Dataset’s Actually Worth It
You don’t need 10 million blurry selfies. You need signal — not noise.
Before we hit the list, here’s how top teams size up a face recognition dataset. If yours doesn’t tick most of these boxes, it’s probably not ready for production.
Type of Data
Are we talking static photos, live video, 3D scans, or synthetic faces? Different tasks = different formats.
Size & Diversity
It's not just how many images — but how many people, poses, ethnicities, lighting conditions, devices. If it only knows sunny selfies from Silicon Valley, it’ll struggle in a rainy parking garage.
Use Case Alignment
Is the dataset built for detection, verification, spoofing defense, or fairness testing? Pick wrong, and your model learns the wrong game.
Annotation Quality
Keypoints, age, gender, liveness, emotion — these labels turn raw pixels into trainable structure.
Access & Licensing
Some are open. Some require NDA. Some are ISO‑certified for compliance-heavy industries. Know before you build.
Foundational Recognition Datasets
These are the core datasets used to train and benchmark most modern face recognition models. They’re large, well-documented, and time-tested — ideal for pretraining, fine-tuning, and academic comparison.
1. VGGFace2
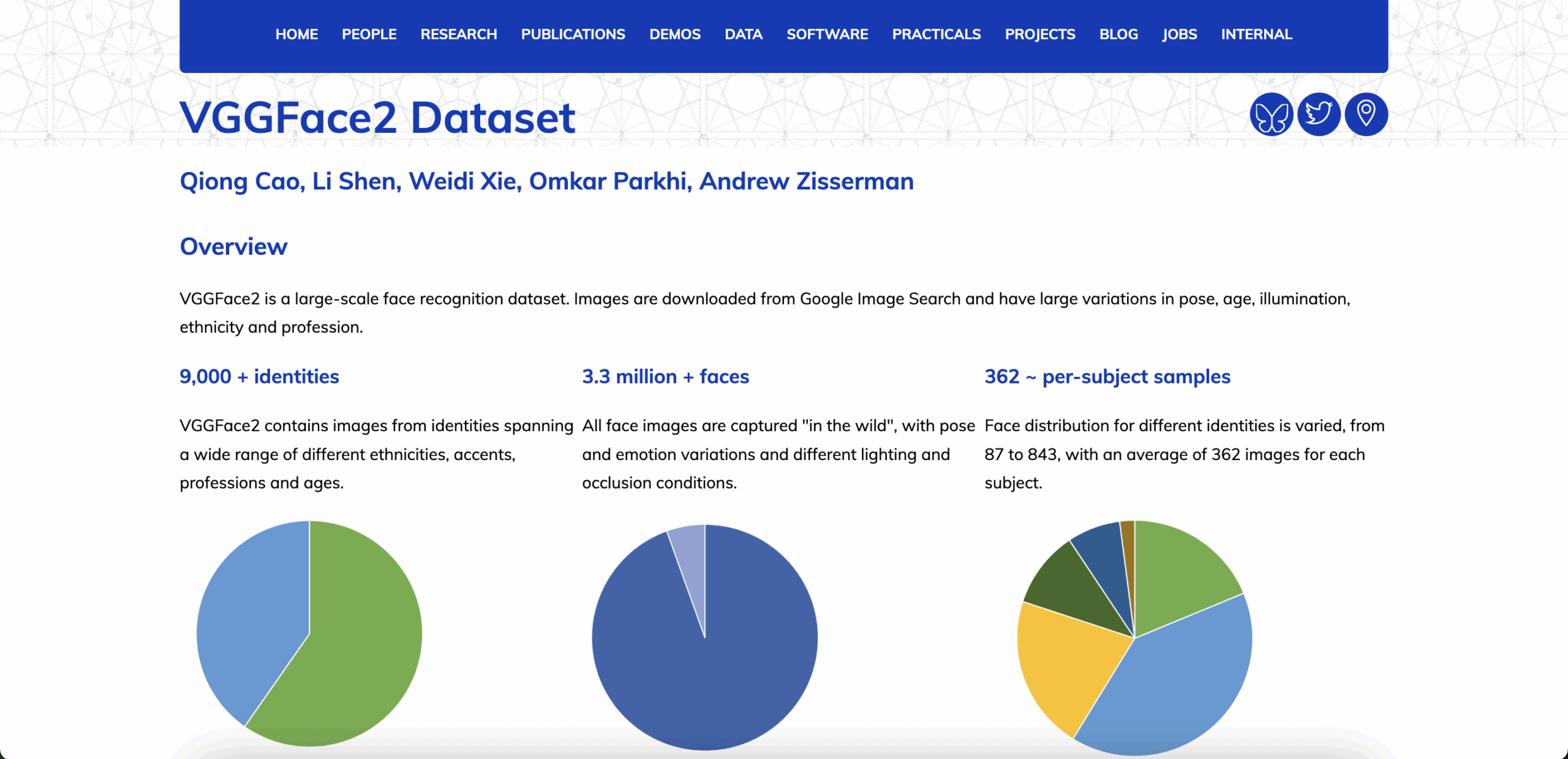
Format: Photo
Volume: 3.3 million images (9,131 identities)
Access: Free (academic use only)
Released by Oxford, VGGFace2 includes 3.3M face images from 9,131 identities with wide variation in age, pose, and lighting. It remains one of the most trusted datasets for recognition and bias testing, used in ArcFace, FaceNet, and other SOTA models.
Dataset Spotlight (click to expand)
name: COUGHVID type: Cough recordings format: Audio volume: 25,000+ samples access: Free (open access) use_case: Disease detection, acoustic modeling, mobile diagnostics
2. CASIA-WebFace
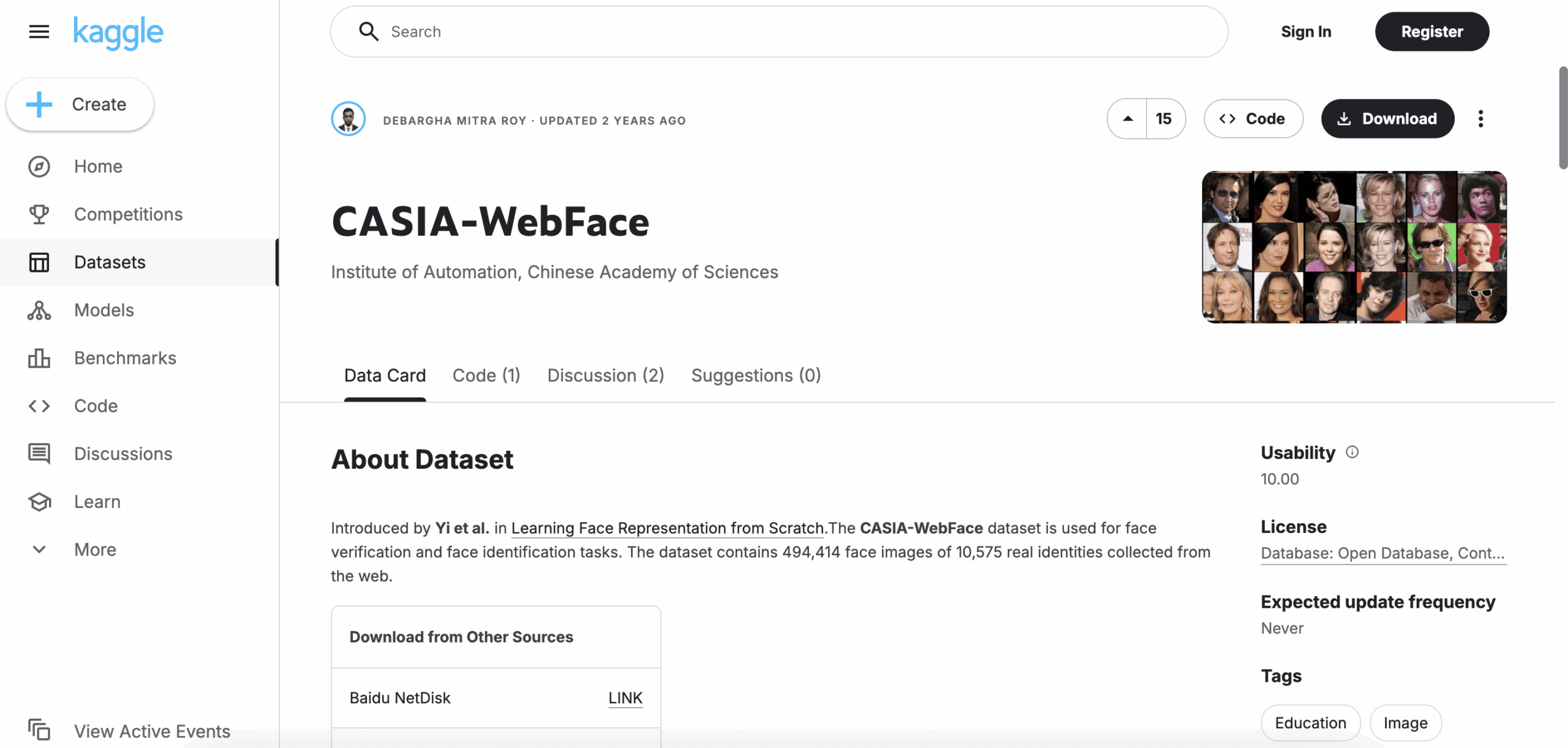
Format: Photo
Volume: 494,414 images (10,575 identities)
Access: Free (academic use only)
Collected from web celebrity photos, this dataset contains 494,414 images of over 10,000 subjects. While some noise is present, it’s still a widely used benchmark for face embedding models and baseline verification pipelines.
3. LFW (Labeled Faces in the Wild)

Format: Photo
Volume: 13,000+ labeled images
Access: Free (open access)
A historic benchmark of 13K+ labeled images captured in the wild, LFW introduced unconstrained face verification. It’s no longer state-of-the-art, but still useful for sanity checks and legacy model evaluation.
4. MegaFace
Format: Photo
Volume: 1 million distractor images
Access: Free (open access)
This dataset isn’t for training — it’s a challenge benchmark that includes over 1 million distractor images to stress-test face identification systems. Essential for measuring how your model scales under real-world noise.
5. WebFace42M

Format: Photo
Volume: 42 million images (2 million identities)
Access: Free (academic use only)
A recent large-scale dataset with 42 million images from 2 million subjects, offering strong diversity in age, pose, and lighting. Used for training high-capacity models that need to generalize across global populations.
Fairness & Attribute Modeling
If your model performs worse on certain demographics or can’t handle facial attributes, you’ll want these datasets. They include rich labels for age, gender, race, expressions, and more — ideal for fairness audits and multi-task training.
6. CelebA

Format: Photo
Volume: 200,000+ images
Access: Free (academic use only)
One of the most widely used facial attribute datasets, CelebA features over 200K celebrity images labeled with 40 binary traits (like smiling, eyeglasses, gender). It’s great for training multi-label classifiers and testing model bias.
Dataset Spotlight (click to expand)
name: CelebA format: photo volume: 200,000+ images access: free license: academic use only use_case: - attribute modeling - bias testing
7. CelebA-HQ
Format: Photo (1024×1024)
Volume: 30,000 images
Access: Free (academic use only)
A high-resolution (1024×1024) version of CelebA, reprocessed and aligned for use in GANs and high-fidelity facial modeling. While smaller in size (30K images), it’s favored in generative research.
8. AgeDB

Format: Photo
Volume: 12,240 images (440 subjects)
Access: Free (academic use only)
Focused on age variation, AgeDB provides 12,240 face images from 440 subjects with both real and apparent age labels. It’s ideal for age-invariant face recognition and age estimation benchmarks.
9. UTKFace

Format: Photo
Volume: 20,000+ images
Access: Free (open access)
This open dataset includes over 20K images labeled by age, gender, and ethnicity. Despite some label noise, it’s a go-to for training and evaluating demographic fairness in face models.
10. CALFW

Format: Photo
Volume: ~4,000 image pairs
Access: Free (academic use only)
A curated version of LFW where image pairs differ in age — designed to test how well face verification holds up across time. Small but targeted, CALFW is great for temporal robustness studies.
Anti-Spoofing & Deepfake Detection
Face recognition systems fail fast when they can't tell real from fake. These datasets cover spoof attempts, 3D masks, deepfakes, and face obfuscation — making them essential for liveness detection, security testing, and adversarial defense.
11. MFR2

Format: Photo
Volume: 53,000 images
Access: Free (academic use only)
Created for real-world masked face recognition, MFR2 includes 53,000 images of subjects wearing medical masks under natural lighting. It reflects post-COVID challenges and helps models learn to see behind occlusion.
Dataset Spotlight (click to expand)
name: MFR2 format: photo volume: 53,000 images access: free license: academic use only use_case: - masked face recognition
12. 3DMAD
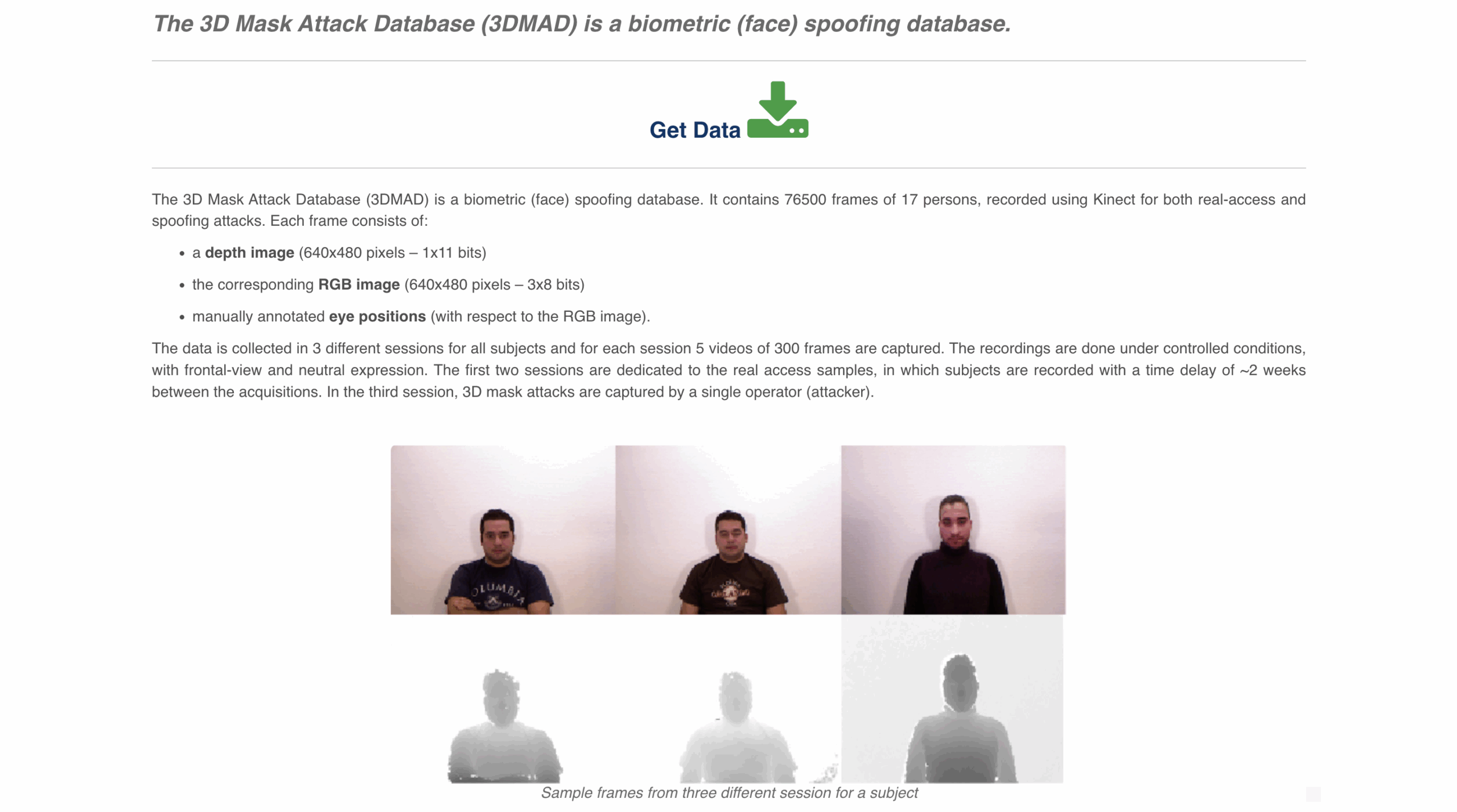
Format: Video
Volume: 17 subjects (multiple sessions)
Access: Free (academic use only)
A high-quality spoofing dataset focused on 3D mask attacks, captured with depth sensors across 17 subjects. It’s often used for evaluating liveness models under presentation attack conditions.
13. FaceForensics++
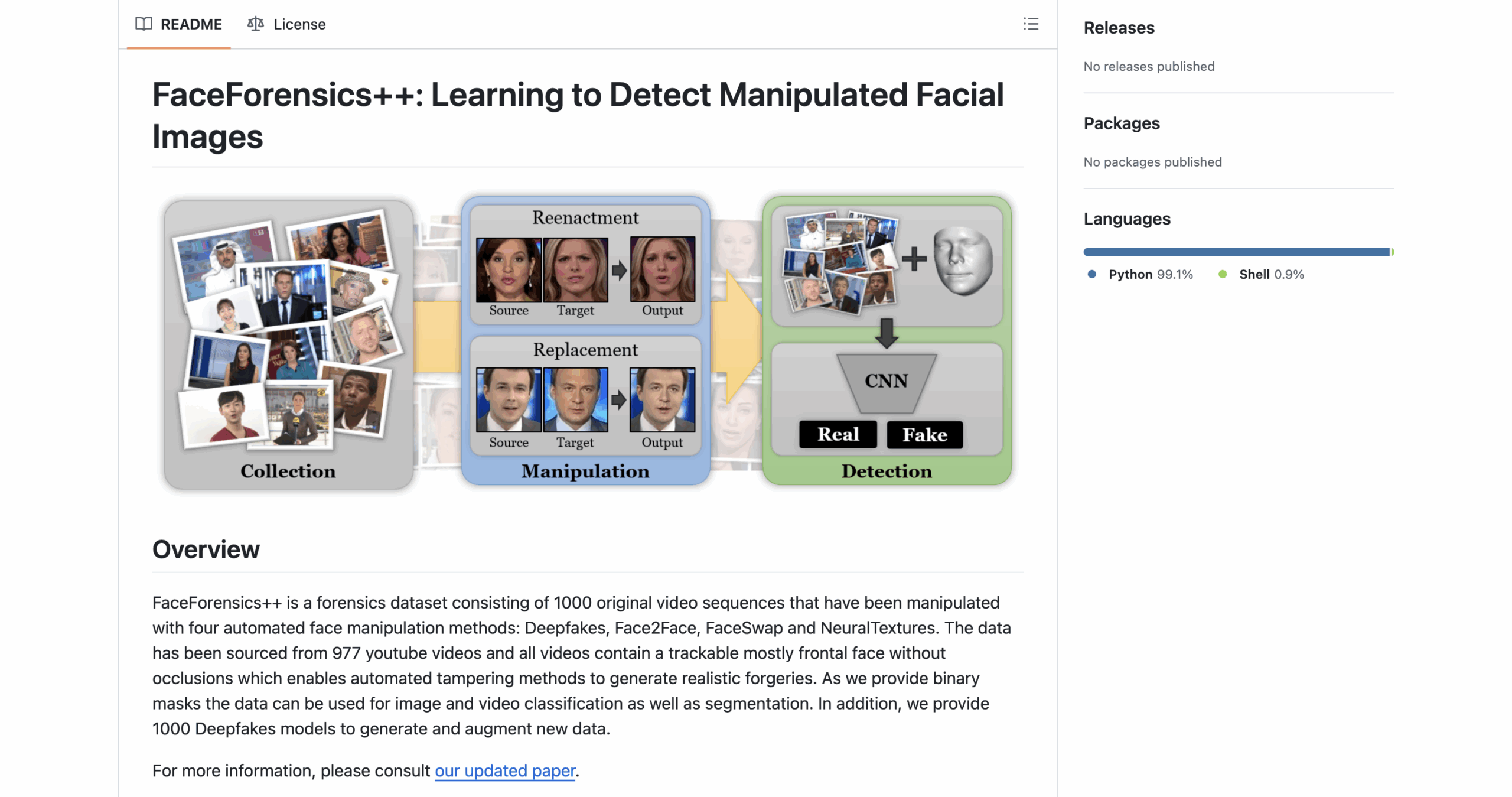
Format: Video
Volume: 1.8M+ frames
Access: Free (academic use only)
A benchmark for manipulated video detection with 1.8M+ frames covering four types of facial tampering. Includes compression levels and ground truth masks for precise training and evaluation.
14. DFDC
Format: Video
Volume: 100,000+ video clips
Access: Free (academic use, non-commercial)
Released by Meta, this dataset includes over 100,000 video clips of real and fake faces under different lighting and compression. It’s noisy but realistic — useful for building robust adversarial defenses.
15. FFHQ
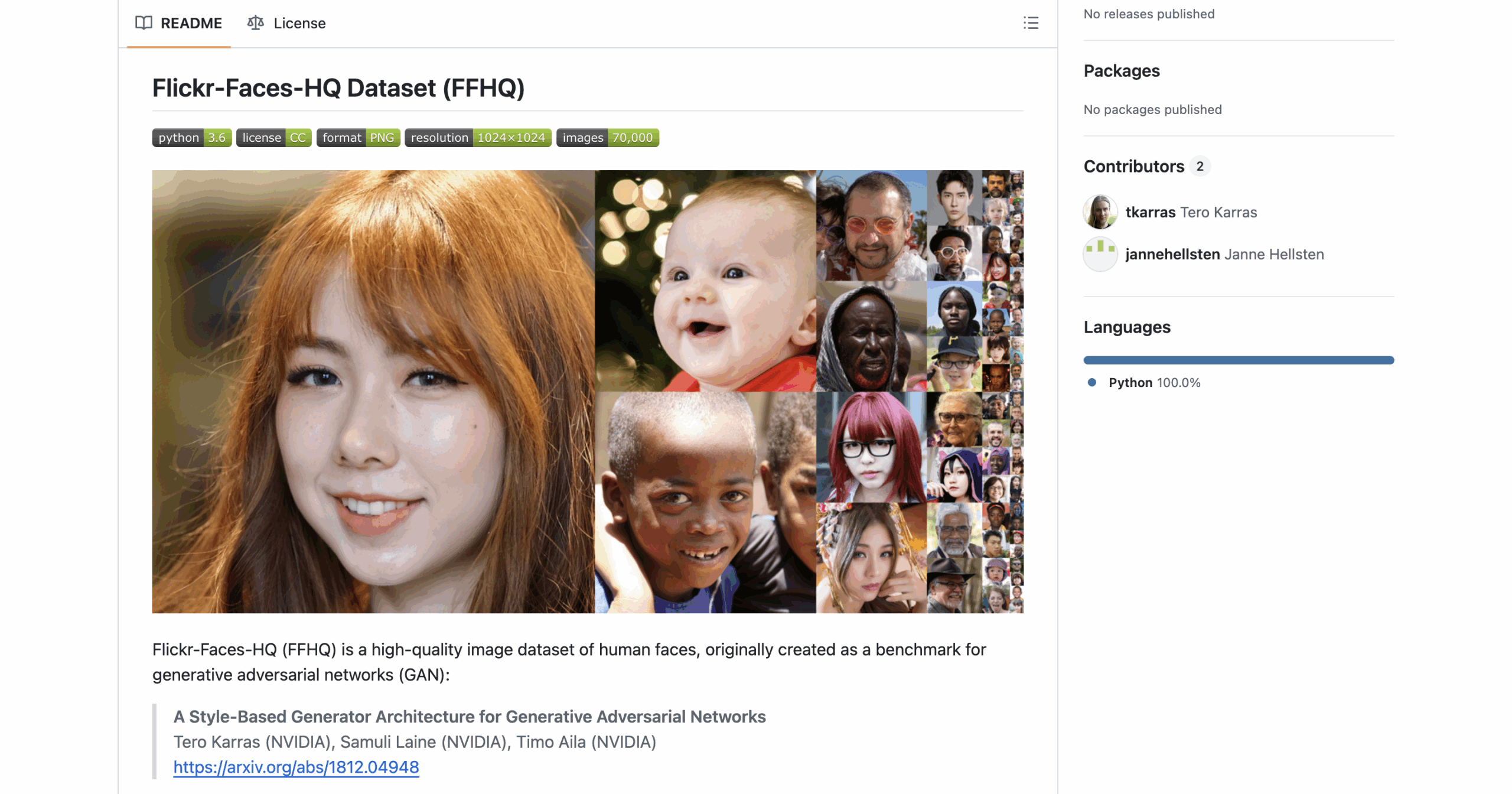
Format: Photo (1024×1024)
Volume: 70,000 images
Access: Free (open access)
70,000 high-resolution images scraped from Flickr, designed for training GANs and testing generative bias. Includes wide variation in age, skin tone, and image background — perfect for fairness augmentation.
Additional Free Datasets
Not every dataset fits neatly into detection or verification. These five give you broader tools: emotion tags, 3D structure, surveillance realism, and extreme poses — great for edge cases and specialized training.
16. AffectNet

Format: Photo
Volume: 1,000,000+ images
Access: Free (academic use only)
A massive dataset with over 1M images labeled for facial expressions, arousal, and valence. Ideal for emotion classification, but also includes 68 facial landmarks for multi-task training.
Dataset Spotlight (click to expand)
name: AffectNet format: photo volume: 1,000,000+ images access: free license: academic use only use_case: - emotion recognition - facial keypoint detection
17. SCface

Format: Photo (RGB + IR)
Volume: 4,000+ images (130 subjects)
Access: Free (academic use, via request)
Simulates low-resolution surveillance scenarios using visible and infrared cameras. Includes 4,000+ images from 130 subjects at multiple distances and angles — great for testing robustness.
18. WIDER FACE

Format: Photo
Volume: 32,000 images (400,000+ faces)
Access: Free (academic use only)
One of the largest datasets for face detection in complex scenes. It contains 32K images with nearly 400K labeled faces, many in extreme poses, small sizes, and crowded settings.
19. EURECOM Kinect Face
Format: RGB + Depth
Volume: 52 subjects (multiple settings)
Access: Free (academic use only)
RGB-D dataset with RGB and depth images from 52 subjects under various occlusion and expression settings. Useful for 3D-aware face recognition and pose variation handling.
20. PUT Face Database
Format: Photo
Volume: 100 subjects (varied head pose, lighting, expression)
Access: Free (academic use only)
Includes controlled images from 100 subjects with variation in head pose, illumination, and expression. Good for training classical models or augmenting lightweight pipelines.
Production-Grade Datasets (Commercial Use)
Open data can take you far — but when real-world compliance, spoofing risks, or ID verification come into play, you need structured, certified data. These Unidata datasets are designed for live deployment environments: mobile onboarding, ISO certification, and biometric KYC flows.
1. iBeta Level 1
Format: Video
Volume: 35,800+ videos
Access: Paid (commercial, ISO-ready)
A liveness dataset built for ISO 30107-3 Level 1 testing. Includes 35,800+ high-quality videos of both genuine access attempts and spoof attacks, recorded under varied lighting and device setups. Ideal for validating liveness models before certification.
Dataset Spotlight (click to expand)
name: iBeta Level 1 format: video volume: 35,800+ videos access: paid license: commercial, ISO-ready use_case: - liveness detection - compliance testing
2. Liveness Detection Video Dataset
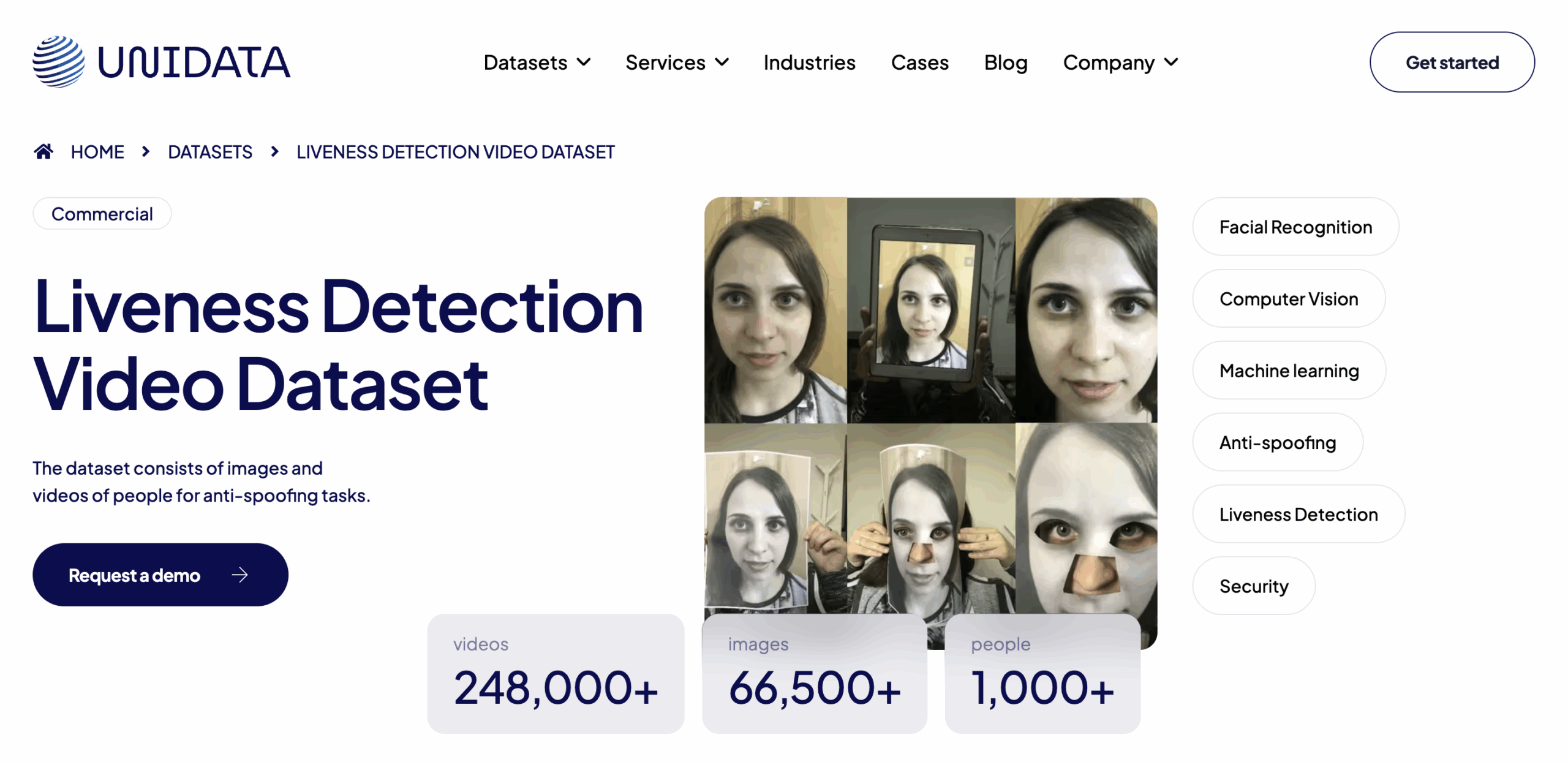
Format: Video + Image
Volume: 248,000 video clips + 66,000 stills (1,056 subjects)
Access: Paid (commercial license)
One of the largest commercial face video datasets for spoof prevention. Includes 248K liveness video clips and 66K stills from 1,056 subjects across diverse settings — indoor, outdoor, various devices, and skin tones. Useful for both training and evaluating production-ready anti-spoofing models.
Dataset Spotlight (click to expand)
name: Liveness Detection Video Dataset format: video + image volume: 248,000 video clips + 66,000 stills (1,056 subjects) access: paid license: commercial use_case: - spoof detection - biometric security
3. Selfie with ID Dataset
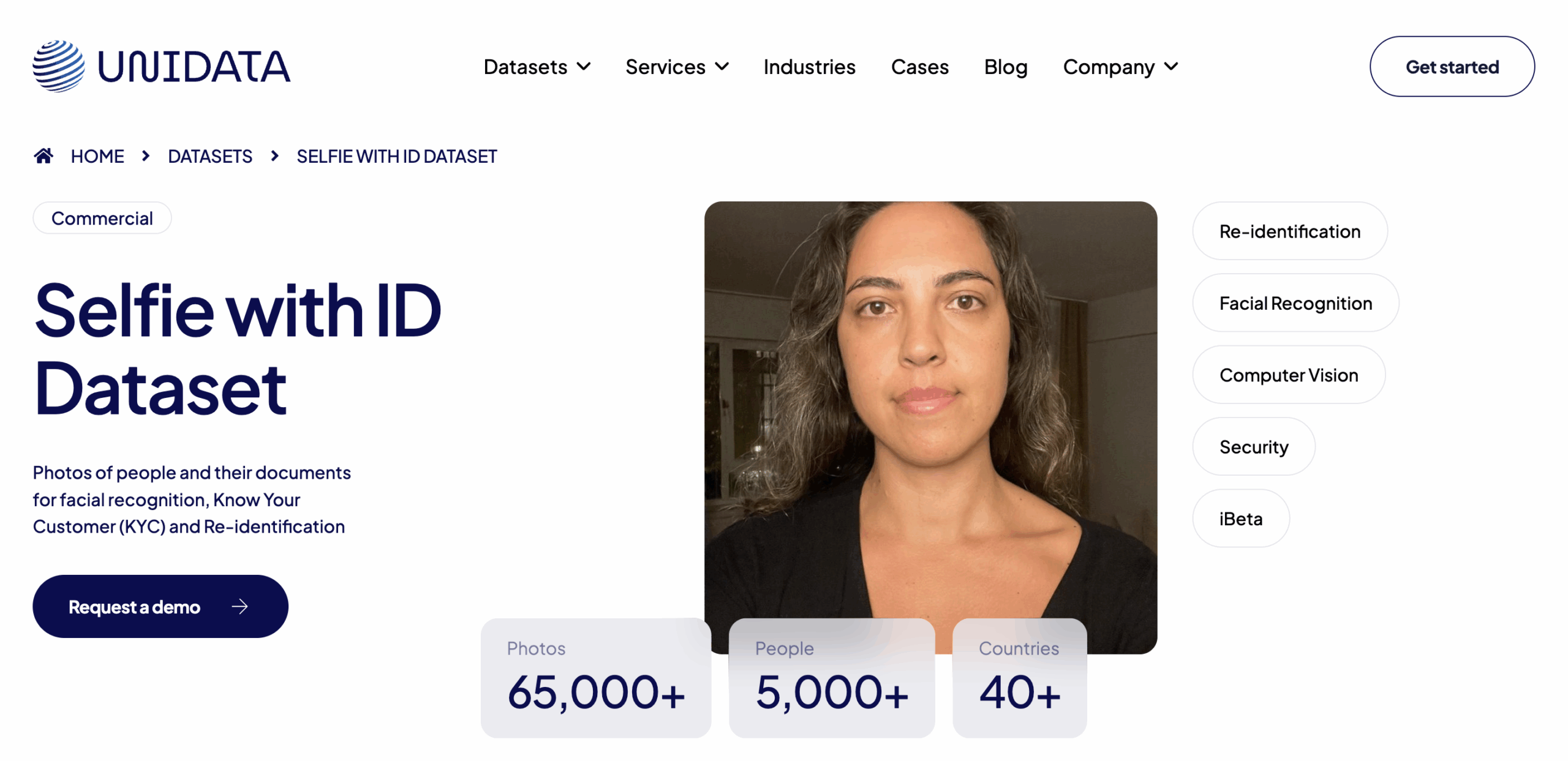
Format: Photo
Volume: 65,000+ selfie–ID pairs (5,000+ users)
Access: Paid (commercial license)
Over 65,000 paired selfie and document images from 5,000+ users across 40+ countries. Each sample includes diverse lighting, document types, and real-world capture conditions — ideal for testing document-face match models in KYC workflows.
Dataset Spotlight (click to expand)
name: Selfie with ID Dataset format: photo volume: 65,000+ selfie–ID pairs (5,000+ users) access: paid license: commercial use_case: - ID verification - KYC - document matching
Final Takeaway
You don’t need to pay to get started with face recognition. These 20 free datasets cover the essentials — from clean baselines to deepfake defense. Pair them smartly, benchmark often, and know when it’s time to level up to production-grade data. Because great models start with the right faces.
Cheat Sheet: All 23 Face Recognition Datasets
Dataset Spotlight (click to expand)
- name: VGGFace2
format: photo
volume: 3.3 million images (9,131 identities)
access: free
license: academic use only
use_case:
- face recognition
- bias testing
- name: CASIA-WebFace
format: photo
volume: 494,414 images (10,575 identities)
access: free
license: academic use only
use_case:
- face embeddings
- pretraining
- name: LFW
format: photo
volume: 13,000+ images
access: free
license: open access
use_case:
- face verification
- legacy model evaluation
- name: MegaFace
format: photo
volume: 1 million distractor images
access: free
license: open access
use_case:
- 1:N benchmarking
- false positive testing
- name: WebFace42M
format: photo
volume: 42 million images (2 million identities)
access: free
license: academic use only
use_case:
- large-scale pretraining
- fairness analysis
- name: CelebA
format: photo
volume: 200,000+ images
access: free
license: academic use only
use_case:
- attribute modeling
- bias testing
- name: CelebA-HQ
format: photo (1024×1024)
volume: 30,000 images
access: free
license: academic use only
use_case:
- generative modeling
- style transfer
- name: AgeDB
format: photo
volume: 12,240 images (440 subjects)
access: free
license: academic use only
use_case:
- age estimation
- robustness testing
- name: UTKFace
format: photo
volume: 20,000+ images
access: free
license: open access
use_case:
- bias analysis
- subgroup accuracy
- name: CALFW
format: photo
volume: ~4,000 image pairs
access: free
license: academic use only
use_case:
- long-term face verification
- temporal robustness
- name: MFR2
format: photo
volume: 53,000 images
access: free
license: academic use only
use_case:
- masked face recognition
- name: 3DMAD
format: video
volume: 17 subjects (multiple sessions)
access: free
license: academic use only
use_case:
- 3D anti-spoofing
- liveness evaluation
- name: FaceForensics++
format: video
volume: 1.8M+ frames
access: free
license: academic use only
use_case:
- deepfake detection
- forgery classification
- name: DFDC
format: video
volume: 100,000+ video clips
access: free
license: academic use (non-commercial)
use_case:
- deepfake training
- adversarial robustness
- name: FFHQ
format: photo (1024×1024)
volume: 70,000 images
access: free
license: open access
use_case:
- generative modeling
- dataset balance
- name: AffectNet
format: photo
volume: 1,000,000+ images
access: free
license: academic use only
use_case:
- emotion recognition
- facial keypoint detection
- name: SCface
format: photo (RGB + IR)
volume: 4,000+ images (130 subjects)
access: free
license: academic use (via request)
use_case:
- low-res face recognition
- surveillance
- name: WIDER FACE
format: photo
volume: 32,000 images (400,000+ faces)
access: free
license: academic use only
use_case:
- face detection
- occlusion and crowd handling
- name: EURECOM Kinect Face
format: RGB + depth
volume: 52 subjects (multiple settings)
access: free
license: academic use only
use_case:
- depth-based recognition
- expression robustness
- name: PUT Face Database
format: photo
volume: 100 subjects (varied head pose, lighting, expression)
access: free
license: academic use only
use_case:
- pose robustness
- face preprocessing
- name: iBeta Level 1
format: video
volume: 35,800+ videos
access: paid
license: commercial, ISO-ready
use_case:
- liveness detection
- compliance testing
- name: Liveness Detection Video Dataset
format: video + image
volume: 248,000 video clips + 66,000 stills (1,056 subjects)
access: paid
license: commercial
use_case:
- spoof detection
- biometric security
- name: Selfie with ID Dataset
format: photo
volume: 65,000+ selfie–ID pairs (5,000+ users)
access: paid
license: commercial
use_case:
- ID verification
- KYC
- document matching