At Unidata.pro, our team of machine learning engineers and data scientists has spent years training AI systems across industries, and we've learned one undeniable truth: the quality of training data determines everything. Organizations can invest in the most sophisticated neural network architectures, cutting-edge optimization algorithms, and state-of-the-art infrastructure — but if the training data is poor, the model will fail.
Training data is the fuel that powers artificial intelligence, and understanding how to source, prepare, and use it effectively is what separates successful ML projects from expensive failures.

This article walks you through the entire process of preparing training data for ML and AI projects, helping you understand each step, even if you're new to the field.
Understanding Training Data: Definition and Core Concepts
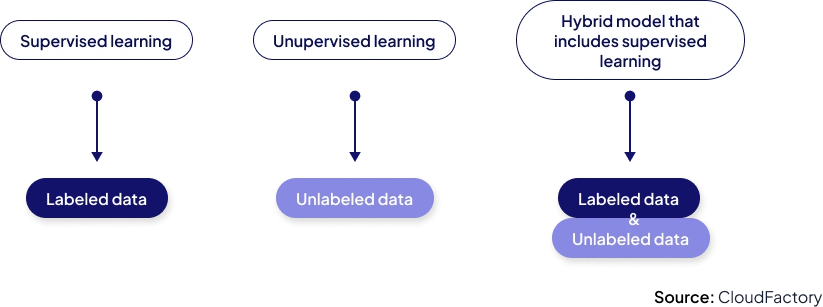
Training data is the dataset used to teach machine learning algorithms to recognize patterns, make predictions, or perform specific tasks. Think of it as the textbook from which an AI model learns — every example in the training dataset provides the model with information about the relationships between input features and desired outputs. In supervised learning, this means labeled data showing both the input and the correct answer; in unsupervised learning, it's raw data from which the algorithm must discover hidden structures.
The Unidata.pro team regularly works with clients building predictive models where training data quality makes the decisive difference. In one telecommunications customer churn prediction project, the initial training dataset contained six months of customer behavior data — call volumes, data usage, support tickets, and payment history — for 50,000 customers, labeled with whether they churned or stayed. The model learned patterns: customers who called support three times in one month with unresolved issues had a 73% churn probability. That insight came directly from the training data patterns.

The relationship between training data and machine learning models is foundational. The algorithm processes training data during the training phase, adjusting its internal parameters to minimize prediction errors. Neural networks, for instance, use backpropagation to update connection weights based on how far their predictions deviate from the actual labels in the training data. This iterative process of learning from examples is what enables pattern recognition and, ultimately, accurate predictions on new, unseen data.
The Critical Role of Training Data in Machine Learning
The relationship between training data quality and model performance cannot be overstated — it's a direct, cause-and-effect relationship the Unidata.pro team has witnessed across dozens of projects. The principle 'garbage in, garbage out' isn't just a platitude; it's a harsh reality. Poor-quality training data leads to models that underperform, exhibit bias, fail to generalize, or produce nonsensical predictions regardless of algorithmic sophistication.
We encountered this firsthand when building a fraud detection system for an e-commerce platform. The initial model achieved only 62% accuracy — barely better than random guessing. After two weeks tweaking hyperparameters, trying different algorithms, and adjusting network architectures with minimal improvement, our team audited the training data and discovered the problem: 18% of transactions were mislabeled, legitimate purchases were missing critical features, and fraudulent patterns from the past year weren't represented. After one month cleaning the data, correcting labels, and adding recent fraud examples, the same base algorithm jumped to 94% accuracy. The model hadn't changed — the data quality had.
Five ways training data quality affects model performance:
- Accuracy: Clean, correctly labeled data leads to models that make accurate predictions; noisy or mislabeled data teaches the model incorrect patterns
- Generalization: Diverse, representative data allows models to perform well on new examples; limited or biased data causes overfitting to training examples
- Robustness: Comprehensive data covering edge cases builds models that handle unusual inputs; sparse data creates models that break on unexpected scenarios
- Convergence speed: High-quality data enables faster training with fewer iterations; poor data causes training instability and longer development cycles
- Maintenance costs: Good data reduces the need for constant retraining; poor data requires ongoing fixes and model updates
Data quality metrics the Unidata.pro team assesses include accuracy (correctness of labels), completeness (no missing values in critical fields), consistency (uniform formats and definitions), relevance (alignment with the actual prediction task), and timeliness (recency for problems where patterns shift over time).
These dimensions collectively determine training data effectiveness and ultimately dictate whether an AI system succeeds or fails in production.
Types of Learning Approaches Using Training Data
Different machine learning paradigms use training data in fundamentally different ways, and understanding these distinctions is critical for project planning. We have implemented all four major approaches across various industries, and each has distinct data requirements that shape everything from collection costs to labeling needs.
| Learning Type | Data Requirements | Key Advantages | Main Challenges |
|---|---|---|---|
| Supervised Learning | Large volumes of labeled data (input-output pairs) | Highest accuracy for well-defined tasks; clear performance metrics | Expensive labeling; requires domain expertise; time-intensive |
| Unsupervised Learning | Unlabeled data only | No labeling cost; discovers hidden patterns; useful for exploration | Difficult to evaluate; results can be hard to interpret; less precise |
| Semi-supervised | Small labeled set + large unlabeled set | Reduced labeling costs; leverages abundant unlabeled data | Complex implementation; still needs some labeled examples |
| Reinforcement Learning | Environment interactions + reward signals | Learns through trial and error; handles sequential decisions | Requires simulation environment; slow convergence; complex reward design |
In supervised learning, the Unidata.pro team has found the labeling bottleneck to be consistently underestimated. For a medical imaging project, 50,000 labeled chest X-rays were needed to achieve clinical-grade accuracy[1]. With three radiologists labeling at $75/hour and 3 minutes per image, data labeling alone cost 187,500 dollars — more than the entire initial model development budget.
This is why careful consideration of learning approach matters: semi-supervised learning enabled training on 5,000 labeled images plus 200,000 unlabeled ones, reducing labeling costs by 90% while achieving 92% of the fully supervised model's accuracy.
Training Data vs. Validation and Test Data
One of the most common mistakes the Unidata.pro team observes in ML projects is improper separation between training, validation, and test datasets. These three data types serve completely different purposes, and confusing them leads to catastrophically misleading results — models that appear highly accurate during development but fail spectacularly in production.
The typical 70/15/15 or 80/10/10 split (training/validation/test) works well for most projects[2], though the Unidata.pro team adjusts based on total dataset size. With less than 1,000 examples, k-fold cross-validation is used instead of a fixed validation set. With millions of examples, larger test sets provide more reliable performance estimates.
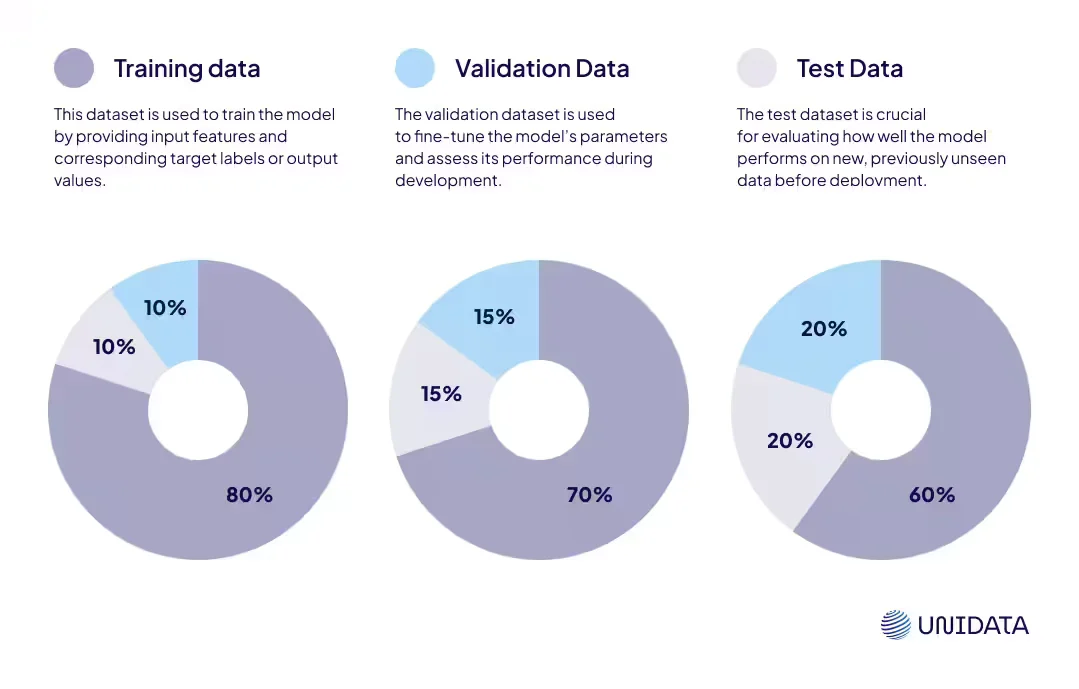
The cardinal rule: test data must remain untouched until final evaluation. If iteration occurs on test data — adjusting features, trying different models, or tuning based on test performance — you're effectively training on it, and results become unreliable.
| Dataset Type | Purpose | When Used | Typical Size | Key Characteristics |
|---|---|---|---|---|
| Training Data | Teach the model patterns | During model training | 60-80% of total | Model learns from this; adjusts parameters based on it |
| Validation Data | Tune hyperparameters & prevent overfitting | During model development | 10-20% of total | Used for model selection; never for training |
| Test Data | Final performance evaluation | After all development complete | 10-20% of total | Touched once only; simulates real-world performance |
Types of Training Data
Understanding different training data types is essential because they determine project approach, tooling requirements, and processing pipelines. The Unidata.pro team has worked with every major data type across domains from natural language processing to computer vision to time-series forecasting, and each brings distinct challenges and considerations.
Structured vs. Unstructured Data
Structured data — organized in rows and columns with predefined schemas — is what most traditional databases contain: customer records, transaction logs, sensor measurements, financial data. It's the easiest type to work with because feature engineering is straightforward, relationships are clear, and processing is computationally efficient. The Unidata.pro team has built credit scoring models using structured data from relational databases: income, debt levels, payment history, credit utilization — all clean numerical or categorical features stored in organized tables.
Unstructured data — text, images, audio, video — makes up the vast majority of the world's data but requires sophisticated preprocessing[3]. For sentiment analysis projects analyzing customer reviews, text data has no inherent structure: variable-length sentences, slang, emojis, multilingual content, sarcasm. Tokenization, vectorization, and feature engineering must occur before any machine learning can begin. Similarly, computer vision projects with image data require handling variable sizes, lighting conditions, backgrounds, and orientations.
Examples of structured and unstructured data our team works with:
- Structured: SQL database tables (financial transactions), CSV files (sales data), time-series sensor data (IoT), spreadsheets (inventory records), log files with fixed formats
- Unstructured: Customer emails and reviews, product images, call center recordings, social media posts, medical imaging (X-rays, MRI scans), surveillance video
Three key considerations when choosing between structured and unstructured approaches:
- Data availability: Structured data often exists already in business systems; unstructured data may need special collection
- Feature richness: Unstructured data (especially images/text) can encode far more complex patterns but requires deeper models
- Processing requirements: Structured data runs efficiently on traditional algorithms; unstructured data often requires deep learning and GPU infrastructure
Labeled vs. Unlabeled Data
The distinction between labeled and unlabeled data fundamentally shapes project economics and timelines. Labeled data includes both the input and the correct answer — an image with bounding boxes around objects, a sentence with its sentiment classification, a customer record with churn status. Creating labeled data requires human expertise and time, making it expensive and slow to produce at scale.

The Unidata.pro team supervised a project requiring 100,000 labeled images of manufacturing defects. At 30 seconds per image and $15 / hour for trained labelers, the annotation budget was 125,000 dollars — more than model development, infrastructure, and deployment combined. This led to exploring semi-supervised learning, where 10,000 labeled images bootstrapped a model that then helped annotate the remaining 90,000[4], reducing human labeling time by 65%.

Image Annotation for Construction and Heavy Machinery
- Construction & Infrastructure
- 5,000 images annotated (20,000 bounding boxes)
- 1,5 week
Unlabeled data is abundant and cheap but limits options to unsupervised approaches or requires creative solutions. For a customer segmentation project, the Unidata.pro team had millions of unlabeled customer behavior records. Clustering algorithms identified natural groupings without any labeled examples. While specific outcomes like churn couldn't be predicted, five distinct customer segments were discovered that marketing used to personalize campaigns, increasing conversion rates by 34%.
Quality Considerations for Training Data
After years of ML development, the Unidata.pro team is convinced that data quality is more important than model architecture, algorithm selection, or hyperparameter tuning combined. Simple models trained on excellent data consistently outperform sophisticated neural networks trained on poor data. Data quality isn't about perfection — it's about ensuring training data accurately reflects the patterns the model should learn and represents the real-world conditions where it will operate.
The Unidata.pro framework for assessing training data quality evaluates five dimensions:
- Accuracy — Are labels and values correct?
- Completeness — Are critical fields populated?
- Consistency — Are formats and definitions uniform?
- Relevance — Does the data match the prediction task?
- Timeliness — Is the data recent enough to reflect current patterns?
For each dimension, specific metrics are defined, thresholds set, and samples audited regularly. This systematic approach prevents subtle bugs that would cause production failures.
Avoiding Bias and Ensuring Representativeness
Algorithmic bias resulting from biased training data is one of the most serious challenges in modern AI — it's both a technical problem and an ethical responsibility. The Unidata.pro team encountered this directly when evaluating a resume screening model. The system performed well on validation data, but systematic downranking of female candidates for technical roles was discovered.
The problem? Training data consisted of 10 years of successful hires, and due to historical gender imbalance, 87% were male. The model learned that gender (inferred from names and schools) correlated with hiring success, perpetuating the bias into future hiring decisions.
Checklist for evaluating dataset bias and representativeness:
- Demographic balance: Are all relevant groups represented proportionally to the target population?
- Feature correlation: Do protected attributes (race, gender, age) correlate with outcomes in unexpected ways?
- Historical bias: Does training data reflect historical inequities that shouldn't be perpetuated?
- Sample selection: Was data collection method likely to exclude certain groups?
- Label accuracy: Are labels accurate across all demographic groups, or does quality vary?
- Edge case coverage: Are rare but important scenarios adequately represented?
- Geographic diversity: For global applications, is data collected from all target regions?
Representative sampling is the primary Unidata.pro strategy for mitigating bias. For the resume screening model, training data was corrected by ensuring gender balance (50/50 male/female), including diverse educational backgrounds beyond top-tier universities, and adding examples of successful non-traditional career paths.
Names and other potential proxies for protected attributes were also removed from the feature set. The retrained model evaluated candidates based on skills and experience rather than demographic patterns.
Sourcing and Preparing Training Data
Data acquisition is often the longest and most expensive phase of ML projects, yet it's frequently underestimated during planning. The Unidata.pro team has observed projects allocate 80% of budget to model development and only 20% to data, then stall because adequate training data couldn't be sourced. The reality is reversed: data acquisition, preparation, and quality assurance should consume 60-70% of resources, with model development getting 30-40%.
| Source Method | Pros | Cons | Best For |
|---|---|---|---|
| Public Datasets | Free; immediately available; often pre-labeled | May not match specific needs; quality varies; licensing restrictions | Prototypes; benchmarking; academic research |
| Data Creation (Manual) | Perfect fit for needs; full control over quality | Very expensive; slow; requires domain expertise | Specialized domains; custom requirements |
| Web Scraping | Large volumes; diverse sources; automated collection | Legal/ethical concerns; messy data; maintenance required | NLP; market research; public information |
| Synthetic Data | Unlimited volume; perfect labels; privacy-safe | May not capture real-world complexity; domain adaptation needed | Rare events; privacy-sensitive domains; augmentation |
| Partnerships/Purchase | High quality; domain-specific; properly licensed | Expensive; vendor lock-in; update lag | Enterprise applications; regulated industries |
The Role of Synthetic Data
Synthetic data has become a key Unidata.pro strategy for addressing data scarcity, privacy concerns, and class imbalance problems[5]. The concept is simple: algorithmically generate artificial data that mimics real-world statistical properties without containing actual sensitive information. The Unidata.pro team has used synthetic data successfully in healthcare projects where patient privacy regulations made real data access difficult, and in fraud detection where fraudulent examples were too rare to train robust models.
How To Generate Synthetic Data: Full Guide
Learn more
For an autonomous vehicle perception project, training data was needed showing vehicles in rare but critical scenarios: cars on icy roads, pedestrians in unusual clothing, animals on highways at night. Collecting real examples of these edge cases would take years and involve dangerous situations. Instead, simulation software generated 500,000 synthetic images showing vehicles in every conceivable configuration, weather condition, and lighting scenario[5]. The perception model trained on this synthetic data transferred surprisingly well to real-world driving, accurately detecting obstacles the model had never seen in reality — only in simulation.
Key scenarios where synthetic data has been particularly valuable:
- Privacy-sensitive domains (healthcare, finance) where real data access is restricted by regulation
- Rare events (fraud, equipment failures, accidents) where natural occurrence is too infrequent for training
- Class imbalance correction by generating additional minority class examples
- Data augmentation to expand limited real datasets through variations and transformations
- Edge case coverage by systematically generating scenarios that are unlikely but important
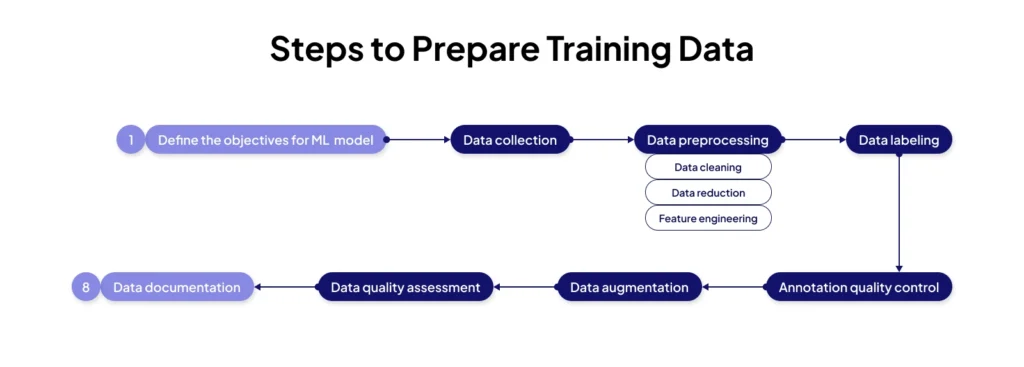
Data Preprocessing Techniques
Data preprocessing is where raw data becomes training data. This transformation stage determines data quality more than any other phase, and corners cut during preprocessing inevitably surface as model performance problems later. The Unidata.pro five-step preprocessing workflow covers the most critical transformations that dramatically improve model outcomes.
5-step data preprocessing workflow:
- Data Cleaning: Handle missing values (imputation, deletion, or special encoding), remove duplicates, fix inconsistencies, correct obvious errors, filter outliers that represent noise rather than signal
- Feature Engineering: Create derived features from raw data (e.g., day-of-week from timestamps), combine features (e.g., spending per transaction = total / count), extract components (e.g., domain from email), apply domain knowledge to construct meaningful predictors
- Normalization/Scaling: Apply min-max scaling ([0,1] range) or z-score standardization (zero mean, unit variance), ensure all features contribute proportionally to distance calculations, critical for gradient-based optimization and neural networks
- Encoding: Convert categorical variables to numerical representations (one-hot encoding, label encoding, embeddings), handle high-cardinality categories appropriately, maintain information while making data ML-compatible
- Train-Test Splitting: Separate data BEFORE any preprocessing, apply transformations fitted on training data to validation/test sets, prevent data leakage that inflates performance estimates
Data Normalization and Transformation
Feature scaling is essential for most machine learning algorithms, particularly gradient descent-based models, distance-based algorithms, and neural networks. Without normalization, features with large absolute magnitudes dominate the learning process while small-scale features contribute negligibly. The Unidata.pro team encountered this when a fraud detection model completely ignored transaction frequency (range: 1-50) because it focused entirely on dollar amounts (range: $0-$50,000). After applying z-score normalization, both features contributed appropriately, and accuracy improved from 76% to 89%.
Min-max normalization is typically used for bounded features where preserving zero values and proportions matters, and z-score normalization for unbounded distributions where deviations from the mean are important. The critical mistake observed repeatedly is normalizing before splitting train/test — this leaks information from test data into training and overestimates performance. Always fit scaling parameters on training data only, then apply those same transformations to validation and test sets.
How Much Training Data Do You Need?
This is hands-down the most frequently asked question the Unidata.pro team receives, and unfortunately, there's no single answer. Dataset size requirements vary dramatically based on model complexity, problem difficulty, feature dimensionality, and desired accuracy. However, practical rules of thumb provide useful starting points[6,7,8].
For traditional machine learning algorithms (logistic regression, random forests, gradient boosting), the Unidata.pro team aims for at least 10 times the number of examples as parameters being estimated[6]. For deep learning, requirements escalate dramatically: image classification typically needs 1,000+ labeled images per class to approach human-level performance[7]; natural language processing models benefit from tens of thousands of examples; and deep neural networks generally require orders of magnitude more data than shallow models.
How Much Training Data is Needed for Machine Learning?
Learn more
The Unidata.pro team has successfully built models with surprisingly small datasets when using transfer learning. For a medical imaging task classifying rare diseases, 91% accuracy was achieved with only 200 labeled examples per disease category by fine-tuning a pre-trained ResNet model. The model had already learned general visual features from millions of ImageNet images; the small dataset just adapted it to the specific medical domain. This is why understanding the available techniques for working with limited data — transfer learning, data augmentation, synthetic data, semi-supervised learning[4,5] — is critical for real-world ML projects where abundant labeled data is rare.
Signs that indicate you need more training data:
- High variance: Large gap between training and validation accuracy (model overfitting)
- Inconsistent predictions: Model performance varies dramatically between runs
- Poor generalization: Strong training performance but weak test performance
- Learning curves plateau: Validation accuracy stops improving as training progresses
- Sensitivity to examples: Removing small numbers of training examples significantly changes results
Best Practices for Training Data Management
Training data management practices become critical as projects scale from proof-of-concept to production systems. The Unidata.pro team has learned that systematic data management is as important as model development itself.
7 essential practices for effective training data management:
- Dataset Versioning: Use version control for data (DVC, Git LFS) just like code; tag versions with descriptive names; maintain lineage from raw data through all transformations to final training sets
- Metadata Documentation: Record data collection methods, dates, sources, processing steps, quality metrics, and known issues; document label definitions and annotation guidelines
- Reproducibility: Store exact preprocessing code and parameters with each dataset version; lock dependency versions; ensure others can recreate results from scratch
- Quality Monitoring: Implement automated quality checks that run on every data update; track key statistics (distributions, missing rates, label balance) over time; alert when patterns shift
- Access Control: Protect sensitive data with proper authentication and encryption; implement role-based access; audit data usage for compliance
- Backup and Recovery: Maintain multiple backups of critical datasets; test recovery procedures; protect against accidental deletion or corruption
- Integration with MLOps: Connect data pipelines to model training pipelines; automate retraining when data updates; track which data versions produced which model versions
Ethical and Privacy Considerations in Training Data
The Unidata.pro team recognizes that every machine learning practitioner bears responsibility for the real-world impacts of their models — and those impacts trace directly back to training data decisions. When using someone's data to train a model that affects their lives, ethical obligations extend beyond technical performance. Data privacy, algorithmic fairness, and informed consent aren't optional additions or regulatory checkboxes — they're fundamental requirements of responsible AI development.
The Unidata.pro ethical framework applied from project inception: (1) Privacy by Design — minimize data collection, anonymize when possible, protect sensitive information throughout the pipeline; (2) Fairness Assessment — explicitly test for bias across demographic groups, measure performance disparities, mitigate identified biases; (3) Transparency — document data sources and known limitations, explain model behavior where possible, enable oversight and auditing; (4) Accountability — establish clear responsibility for model outcomes, implement monitoring for harmful effects, provide mechanisms for redress when errors occur.
Ethical checklist for training data collection and usage:
- Consent: Was data collected with informed consent for this specific use? Are users aware of how their data will be used?
- Privacy: Is personally identifiable information minimized, anonymized, or encrypted? Are regulations (GDPR, CCPA) followed?
- Fairness: Are all demographic groups represented fairly? Have you tested for disparate impact?
- Transparency: Can users access their own data? Are data practices documented and explainable?
- Security: Is data protected from unauthorized access? Are there breach notification procedures?
- Purpose limitation: Is data only used for the stated purpose? Are there safeguards against function creep?
- Accountability: Is there clear responsibility for data practices? Are there mechanisms for redress?
Training Data Regulations and Compliance
The regulatory landscape for training data has become increasingly complex, particularly for projects handling European data (GDPR) or California residents (CCPA)[9]. These regulations grant individuals rights over their data — rights to access, correction, deletion, and objection to processing — that directly impact machine learning projects. The Unidata.pro team has navigated compliance for healthcare projects (HIPAA), financial services (SOX), and international data transfers.
| Regulation | Main Requirements | Unidata.pro Compliance Approach |
|---|---|---|
| GDPR (EU) | Consent, data minimization, right to deletion, privacy by design, data protection officer | Anonymize early; document legal basis; implement deletion procedures; conduct privacy impact assessments |
| CCPA (California) | Consumer rights to know, delete, opt-out; non-discrimination | Maintain data inventory; implement opt-out mechanisms; track data sources; honor deletion requests |
| HIPAA (Healthcare) | Protected health information safeguards; access controls; audit trails | De-identify clinical data; encrypt at rest and transit; limit access to minimum necessary; log all access |
| COPPA (Children) | Parental consent for under-13; data minimization; no behavioral ads | Age-gate data collection; implement parental consent; avoid profiling children; delete data when no longer needed |
Future Trends in Training Data
The field of training data is evolving rapidly, driven by both technical innovation and economic pressure. Based on industry experience and research, the Unidata.pro team sees five trends that will fundamentally transform how training data is sourced and used in the coming years — trends that are already influencing current project decisions[4,5,8].
Top 5 training data trends transforming ML:
- Synthetic Data Maturation: Advanced GANs and simulation creating high-fidelity synthetic data that rivals real examples for many tasks, dramatically reducing collection costs and privacy concerns
- Automated Labeling: AI-assisted annotation tools reducing human labeling time by 70-90%, with active learning selecting the most valuable examples for human review
- Self-Supervised Learning: Models learning from unlabeled data by predicting parts of the input from other parts (like BERT's masked language modeling), minimizing expensive labeling needs
- Data-Centric AI: Systematic focus on improving data quality and quantity as the primary lever for model improvement, with tooling for data debugging, augmentation, and optimization
- Federated Learning: Training models across decentralized data sources without centralizing sensitive data, enabling privacy-preserving ML on distributed datasets
Frequently Asked Questions (FAQ)
Training data is the dataset used to teach machine learning models by providing labeled or unlabeled examples that demonstrate patterns, relationships, and behaviors the model should learn. It’s the foundation that enables algorithms to make accurate predictions on new, unseen data.
Training data is used to teach the model patterns; testing data evaluates final performance on completely unseen examples. Test data must remain untouched until final evaluation to provide unbiased performance estimates. Training data shapes model parameters; test data measures how well those learned patterns generalize.
Algorithms process training data during the training phase, adjusting internal parameters to minimize prediction errors. In supervised learning, models learn mappings from inputs to outputs using labeled examples. In unsupervised learning, algorithms discover patterns and structures in unlabeled data without explicit guidance.
It depends on model complexity and problem difficulty. Traditional ML needs 10x examples as parameters; deep learning image classification typically requires 1,000+ examples per class; NLP benefits from tens of thousands of examples. Transfer learning dramatically reduces requirements by leveraging pre-trained models.
Audit data for errors and inconsistencies; correct mislabeled examples; handle missing values appropriately; remove irrelevant features; ensure demographic diversity; add examples of edge cases; validate label quality with inter-annotator agreement; implement systematic preprocessing; continuously monitor data distributions over time.
Structured data (tables, databases), unstructured data (text, images, audio, video), labeled data (with correct answers), unlabeled data (raw examples), synthetic data (artificially generated), time-series data (sequential observations), and multimodal data (combining multiple types like text + images).
Preparation involves: data cleaning (handling missing values, fixing errors, removing duplicates), feature engineering (creating meaningful predictors), normalization (scaling features to comparable ranges), encoding (converting categories to numbers), labeling (adding correct answers for supervised learning), splitting (separating train/validation/test sets).
Sources include: public datasets (Kaggle, UCI, ImageNet), internal business data, web scraping, data partnerships or purchases, synthetic data generation, crowdsourcing platforms (Amazon Mechanical Turk), APIs (Twitter, Google), sensors and IoT devices, manual data collection campaigns, and data annotation services.
Quality datasets are accurate (correct labels), complete (minimal missing data), consistent (uniform definitions), diverse (representing all scenarios), balanced (adequate representation of all classes), relevant (aligned with prediction task), recent (reflecting current patterns), large enough (sufficient examples for model complexity), and ethically sourced (with proper consent).
Quality is impacted by: labeling accuracy and consistency, measurement errors in data collection, missing or incomplete values, outliers and noise, bias in sampling or selection, temporal relevance (data staleness), class imbalance, annotation guideline clarity, domain expert involvement, and systematic collection methodology.