
This guide is for ML/AI teams who need a data annotation partner for training, validation, or evaluation data, and want to reduce delivery risk before scaling. In one sitting, you should be able to shortlist a few providers, run a pilot, and choose a partner you can trust in production.
The list is organized as 15 vendor profiles (strengths, related services, and best-fit projects), followed by a comparative overview and a step-by-step selection framework.

Quick shortlist keys:
- Confirm your primary modality and domain constraints (images/video, text, audio, 3D point clouds, multimodal; regulated vs. non-regulated).
- Decide the delivery model you actually need: a platform, a managed service team, or a crowdsourcing marketplace.
- Shortlist a small set of candidates that match your use case and can show repeatable domain experience.
- Require QA transparency: how quality is measured, reviewed, and reported (not just “accuracy claims”).
- Treat security and compliance as gating criteria (certifications, access controls, retention/deletion, auditability).
- Validate scale promises with evidence: how they ramp volume without quality drift and how they handle edge cases.
- Run a pilot with a number of representative samples and score results against your own gold standard before committing.
Understanding Data Annotation and Why It Matters for AI
Data annotation is the process of labeling raw data, including images, text, audio, and video, to create datasets used for training machine learning models. Because label quality shapes model outcomes, choosing an annotation partner is a consequential decision. According to industry research, data scientists often spend a large share of their time on data preparation tasks. [1]
Why Data Annotation Is Critical
AI systems aren’t trained by algorithms or code in isolation; they learn from data, and more precisely, from labeled data.
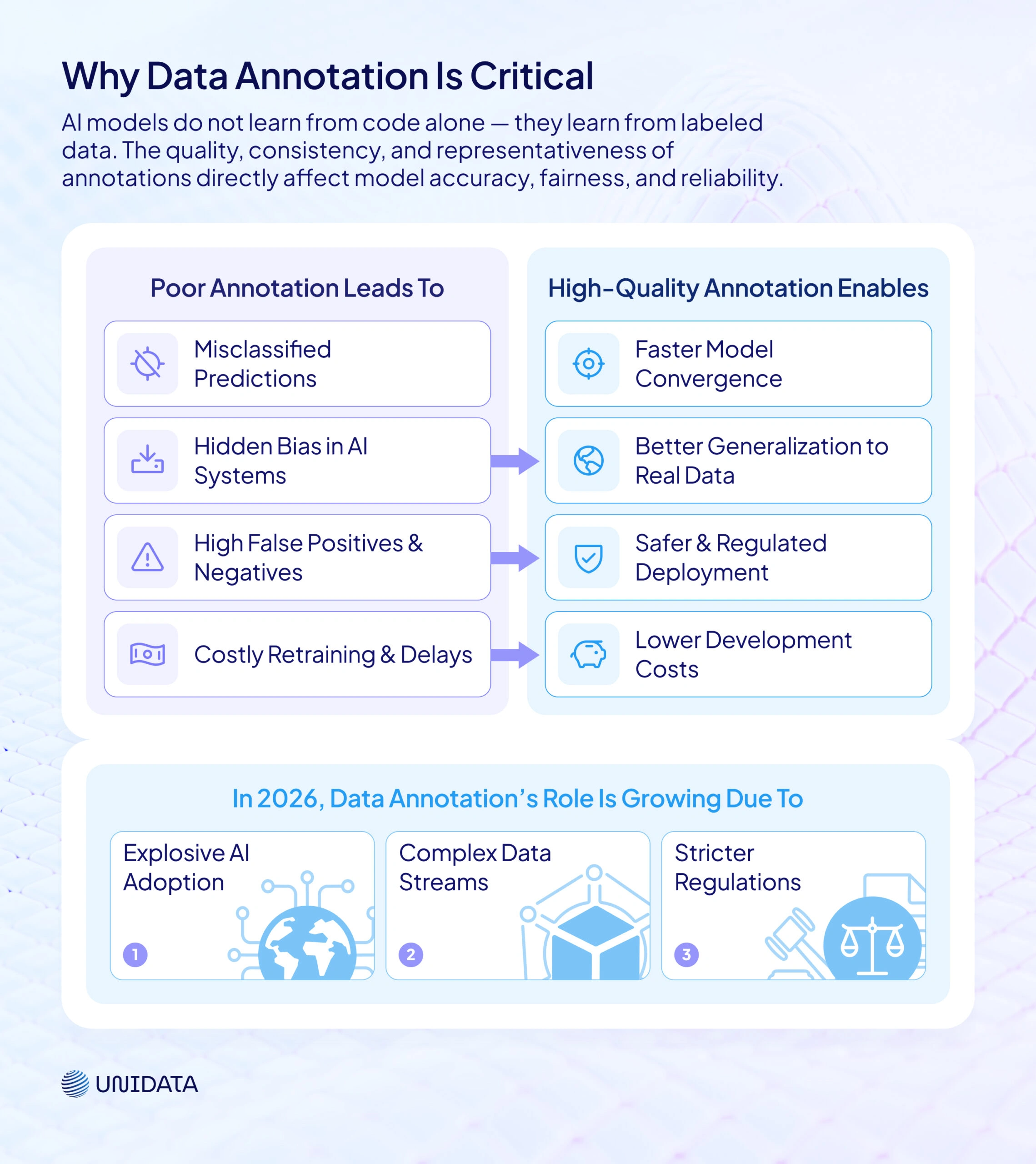
Poor annotation leads to:
- Misclassified predictions
- Hidden bias in AI systems
- Higher false-positive or false-negative rates
- Costly retraining cycles and delayed deployments
High-quality annotation, on the other hand, enables:
- Faster model convergence
- Better generalization to real-world data
- Safer deployment in regulated or high-risk environments
- Lower long-term development costs
Recently, this role has become even more important due to three major shifts:
- The rise of large language models and multimodal AI
Modern AI systems are trained on massive, diverse datasets that require nuanced human judgment. Tasks like Reinforcement Learning from Human Feedback (RLHF), red teaming, and preference ranking often still require expert review and clear adjudication rules.
- Increased regulatory scrutiny
In regulated sectors, expectations increasingly emphasize transparency, auditability, and bias mitigation in AI systems, especially in healthcare, finance, and autonomous technologies. Annotation companies may provide documented processes, quality reporting, and compliance support that internal teams may not have in place.
- Scale and speed requirements
Competitive AI development demands rapid iteration. Many annotation providers combine AI-assisted pre-labeling with human review, which can help teams scale volume while monitoring for quality drift.
In many programs, annotation providers function as part of the data pipeline. They matter most when they support both pilots and production delivery with measurable, repeatable quality checks.
Best 15 Data Annotation Companies
This list uses “companies” as an umbrella term for three different provider types: platforms (software), managed services (delivery teams), and crowdsourcing marketplaces. The evaluation factors in this guide still apply, but the emphasis shifts by type: platforms tend to win on tooling, workflow control, and integration; managed services win when you need an accountable team to run guidelines, QA, and delivery at scale; crowdsourcing win on flexible capacity and speed, but require extra scrutiny on consistency, quality controls, and security.
1. Scale AI
Founded in 2016 and led by CEO Alexandr Wang, Scale AI emerged from the recognition that AI companies needed specialized data infrastructure to train machine learning models effectively. [2] The company initially focused on autonomous vehicle annotation and expanded into robotics and generative AI. In June 2025, Meta announced a $14.8B investment for a 49% non-voting stake. [3]

Key Strengths:
- Specialized verticals: Deep expertise in autonomous vehicles, robotics, and generative AI
- Rapid Scale marketplace: Access to an on-demand workforce; validate qualification, oversight, and QA reporting for your use case
Related Services:
- Image and video annotation (2D/3D bounding boxes, semantic segmentation)
- 3D point cloud annotation for LiDAR and sensor fusion
- Text classification and NLP data preparation
- Audio transcription and speech recognition data
- Model evaluation and benchmarking (Scale Evaluation platform)
- Generative AI data engine for synthetic data creation
- RLHF (Reinforcement Learning from Human Feedback) for LLM training
Best For: Enterprise-scale AI projects with high QA requirements, autonomous vehicle development, and companies handling sensitive data (validate scope, controls, and any required certifications).
Headquarters: San Francisco, California, USA
2. Unidata

Founded in 2016 and headquartered in Dubai, United Arab Emirates, Unidata provides managed data services for ML teams, including data collection and labeling support for common modalities (text, image, audio, video) and related workflows used in training, validation, and evaluation. [4]
Unidata positions itself as a provider that can support both pilots and scaled delivery. Treat capacity claims and customer counts as vendor-provided marketing and validate them during a pilot (including ramp plans, QA reporting, and edge-case handling).
Key Strengths:
- Delivery model: Managed services with project-specific guidelines and QA
- Data privacy focus: States it uses security controls, validate access controls, retention/deletion, and auditability during a pilot.
- Human-led quality: Trained annotators and QA review (request team composition and QA reporting during a pilot)
- Delivery: Validate ramp plans, QA drift controls, and edge-case handling during a pilot
- Operations: Project management and defined delivery expectations
Related Services:
- Image, video, text, and audio annotation
- Product categorization and attribute extraction
- Bounding boxes and object detection
- Image tagging and classification
- Named entity recognition (NER)
- OCR annotation and document processing
- LiDAR and DICOM annotation
- LLM training data preparation
- Content moderation
- Dataset collection, validation, and management
Best For: AI teams, fintech companies, retail and e-commerce platforms, healthcare organizations, IT enterprises, and businesses seeking scalable, secure, and fully managed data annotation and LLM training services.
Website: https://unidata.pro
Headquarters: Dubai, United Arab Emirates
3. Labelbox
Labelbox provides a data labeling platform with optional expert annotation services.

Key Strengths:
- Hybrid model: Combination of self-service platform and expert annotation services
- Enterprise adoption: Platform features oriented to enterprise workflows; validate references during a pilot
- Workflow automation: Built-in consensus scoring and quality control analytics
- Framework integration: Seamless connections to TensorFlow, PyTorch, and major ML frameworks
Related Services:
- Data labeling platform (SaaS) for images, video, and text
- Model evaluation and LLM comparison tools
- Data curation and quality management
- Annotation marketplace for flexible scaling
- API-first integration for ML pipelines
- Custom ontology development
Best For: ML teams wanting flexibility between self-service and managed annotation, organizations building frontier AI models, and teams requiring strong platform capabilities with on-demand expert support.
Headquarters: San Francisco, California, USA
4. Appen
Appen began as a language technology company and has evolved into a data annotation provider. Appen operates globally and uses a large crowdsourced workforce (validate delivery model and security tiers for your program).

Key Strengths:
- Broad language coverage: Supports multilingual projects (confirm availability for your target locales)
- Large global crowd: States it uses a large contributor network
- Deep NLP expertise: Long-running experience in speech recognition and natural language processing
- Three-tier workforce: Segmented contributor pools based on project security requirements
- Public sector experience: Validate any government/regulated requirements, controls, and evidence during a pilot
Related Services:
- Text annotation and classification across multiple languages (confirm coverage for your target locales)
- Audio data collection and transcription
- Speech modeling for ASR and TTS applications
- Video and image annotation
- Search relevance evaluation
- Pre-built datasets may be available (confirm catalog and licensing)
- RLHF for large language models
- Document intelligence and OCR
- Location-based services and geospatial annotation
Best For: Multilingual AI projects, global companies requiring cultural and linguistic diversity, NLP and speech recognition applications, and organizations needing massive scalability.
Headquarters: Kirkland, Washington, USA (global HQ); Chatswood, NSW, Australia (origin)
5. Sama (formerly Samasource)
Founded in 2008 by social entrepreneur Leila Janah, Sama began as a nonprofit organization (Samasource) with the mission of providing dignified digital work to people in underserved communities. Sama operates delivery teams for data annotation services; validate delivery locations, scope, and customer references during a pilot.

Key Strengths:
- Ethical AI positioning: Emphasizes social impact; verify current certifications in vendor documentation
- Long-running experience: Proven track record in computer vision and sensor fusion
- Social impact: Verified employment and income improvement for marginalized communities
- Security posture: Request up-to-date security documentation, confirm scope, audit dates, and subprocessor coverage for your program
Related Services:
- Sama Curate: AI-powered data curation and selection
- Sama Annotate: Expert annotation for images, video, and 3D point clouds (provider marketing may cite accuracy guarantees; validate the exact definition, measurement method, and scope in your pilot)
- Sama Validate: Model evaluation and prediction review
- Sama GenAI: RLHF, red teaming, and LLM fine-tuning
- Sensor fusion annotation for autonomous vehicles
- Content moderation (historically, now reduced focus)
- Custom training data development
Best For: Organizations prioritizing ethical AI and ESG commitments, autonomous vehicle manufacturers, companies requiring audit trails for responsible AI, and projects demanding both quality and social impact.
Headquarters: San Francisco, California, USA, with delivery centers in East Africa
6. CloudFactory
Founded in 2010 in Kathmandu, Nepal, CloudFactory practices the "dedicated team" model for data annotation. The company's approach assigns consistent, trained teams to specific clients rather than using transient crowd workers, resulting in better quality and institutional knowledge retention. CloudFactory has served a broad set of clients globally and maintains a hybrid approach combining AI technology with human expertise to deliver high-performing annotation services.

Key Strengths:
- Dedicated team model: Same annotators work on your projects continuously
- Comprehensive project management: Full-service approach with minimal client overhead
- AI-powered automation: Smart tools enhance speed without sacrificing quality
- Custom workflows: Flexible processes aligned with unique client needs
Related Services:
- Image segmentation and object detection
- Data categorization and extraction
- Video analysis and annotation
- Text classification and entity recognition
- Quality control and validation
- Data digitization services
- Custom annotation workflows
Best For: Companies with ongoing annotation needs, organizations preferring team continuity over crowd-based approaches, projects requiring consistent quality and institutional knowledge.
Headquarters: Reading, England, UK (operations).
7. Dataloop AI
Founded in 2017, Dataloop positions itself as an end-to-end platform that unifies data management, annotation, and pipeline automation for ML teams. The company's vision is to provide ML teams with a single platform for the entire AI lifecycle, reducing tool sprawl and improving efficiency.

Key Strengths:
- Unified MLOps platform: Single solution for data, annotation, and deployment
- Automated QA workflows: Built-in consensus and validation processes
- Pre-built ontologies: Ready-made labeling taxonomies for common use cases
- Human-in-the-loop integration: Seamless collaboration between AI and human annotators
- Strong video capabilities: Advanced tools for temporal annotation
Related Services:
- Video object tracking and annotation
- Image segmentation (2D/3D)
- 3D cuboid annotation
- Classification tasks across data types
- NLP annotation and text processing
- Pipeline automation and orchestration
- Model serving and deployment
- Data versioning and management
Best For: ML teams seeking to consolidate their technology stack, organizations wanting end-to-end AI lifecycle management, teams requiring strong data pipeline automation.
Headquarters: Tel Aviv, Israel
8. SuperAnnotate
SuperAnnotate specializes in computer vision annotation tooling and workflow automation for complex imaging tasks. Validate AI-assisted labeling workflows and QA reporting during a pilot.

Key Strengths:
- Computer vision specialization: Deep expertise in image and video segmentation
- Neural network auto-annotation: AI models accelerate repetitive labeling tasks
- Advanced polygon tools: Precision tooling for irregular shapes and complex objects
- Quality analytics dashboard: Real-time monitoring of annotation accuracy
- Team collaboration features: Built-in workflows for distributed annotation teams
Related Services:
- Instance segmentation
- Keypoint detection and pose estimation
- 3D cuboid annotation
- Video object tracking
- Image classification and tagging
- SDK and API integration
- Custom neural network training for auto-annotation
Best For: Computer vision engineers, medical imaging applications, satellite imagery analysis, manufacturing quality control, projects requiring pixel-level precision.
Headquarters: San Francisco, California, USA (US HQ); Yerevan, Armenia (Engineering)
9. Keymakr
Keymakr focuses on annotation for regulated domains such as healthcare and automotive. Validate compliance claims, scope, and supporting documentation during a pilot.

Key Strengths:
- Medical imaging specialization: Domain-trained teams
- LiDAR expertise: Advanced 3D point cloud annotation for self-driving technology
- Security controls: End-to-end encryption and audit trails (Request details on encryption, access controls, and logging)
Related Services:
- Medical image segmentation (X-rays, MRIs, CT scans, pathology slides)
- 3D point cloud annotation for LiDAR
- Semantic segmentation for complex environments
- Object tracking and trajectory prediction
- Landmark annotation for surgical planning
- Sensor fusion annotation
- Custom compliance-ready workflows
Best For: Healthcare AI companies, autonomous vehicle manufacturers, medical device developers, any organization requiring regulatory-grade annotation with compliance documentation.
Headquarters: Wilmington, Delaware, USA
10. Alegion
Alegion focuses on complex enterprise data annotation where nuance, domain knowledge, and context are paramount. The company emphasizes the use of subject matter experts for specialized annotation tasks requiring professional judgment.

Key Strengths:
- Domain expert annotators: Professionals with specialized knowledge in relevant fields
- Custom workflow design: Tailored processes for unique client requirements
- Advanced quality frameworks: Multi-tier review with domain validation
- NLP and computer vision: Strong capabilities across multiple AI disciplines
- Enterprise focus: Designed for large-scale, complex corporate projects
Related Services:
- Entity extraction and relationship mapping
- Document processing and intelligent extraction
- Image and video segmentation
- Sentiment analysis and classification
- Custom annotation pipelines
- Quality assurance and validation
- Data transformation services
Best For: Financial services, legal technology, insurance, and industries requiring complex data interpretation with specialized domain knowledge.
Headquarters: Austin, Texas, USA
11. Hive
Hive emphasizes AI-assisted workflows for content understanding and related tasks. Validate whether you need API tooling, managed services, or a hybrid delivery model, and how AI-assisted pre-labeling is reviewed.

Key Strengths:
- AI pre-labeling: Proprietary models provide initial annotations for human refinement
- Fast annotation: Speed advantage through intelligent automation
- Content moderation expertise: Specialized in detecting harmful or inappropriate content
- API-first approach: Easy integration with existing workflows
- Competitive pricing: Lower costs due to automation efficiency
Related Services:
- Image classification and object detection
- Video analysis and temporal annotation
- Text moderation and content safety
- Audio transcription
- Logo and brand detection
- Custom AI model training
- Real-time annotation APIs
Best For: Social media platforms, content companies, startups needing rapid iteration, projects where speed is critical, organizations with large-scale moderation needs.
Headquarters: San Francisco, California, USA
12. Cogito
Founded in 2010, Cogito specializes in natural language processing and conversational AI annotation. The company focuses on text, sentiment, and audio annotation for chatbots, virtual assistants, and voice recognition systems.

Key Strengths:
- NLP specialization: multiple annotation task types for conversational and text data (confirm supported schemas)
- Multilingual sentiment analysis: Accurate emotion and intent detection across languages
- Intent recognition expertise: Deep understanding of user queries and conversational context
- Custom taxonomy development: Tailored classification schemes for unique domains
- Conversational AI focus: Optimized for chatbot and voice assistant training
Related Services:
- Named entity recognition (NER)
- Intent classification and slot filling
- Sentiment labeling (positive, negative, neutral, mixed)
- Dialog annotation and conversation flows
- Part-of-speech (POS) tagging
- Text classification and categorization
- Audio transcription for voice AI
- Multilingual annotation services
Best For: Companies building chatbots, customer service AI, voice assistants, NLP applications, and conversational interfaces.
Headquarters: India (primary operations)
13. iMerit
iMerit began with a social mission to provide digital skills training and employment opportunities in underserved communities. iMerit has developed particular expertise in automotive, agriculture, and retail applications.

Key Strengths:
- Domain-trained workforce: Large-scale capacity with specialized domain knowledge
- Security posture: Request up-to-date security documentation and confirm scope if compliance is a gating requirement
- Automotive and agriculture focus: Deep vertical expertise in key industries
- Custom ML-assisted tools: Proprietary platform (Ango Hub) for efficient annotation
Related Services:
- 2D/3D bounding boxes and object detection
- Semantic and instance segmentation
- Landmark and keypoint annotation
- Text extraction and OCR
- Video labeling and tracking
- Sensor fusion for autonomous systems
- RLHF for large language models
- Medical imaging annotation
Best For: Large-scale computer vision projects, retail and e-commerce applications, agriculture technology, autonomous vehicle development.
Headquarters: San Jose, California, USA (with global delivery centers)
14. Clickworker
Founded in 2005, Clickworker is one of the pioneering crowdsourcing platforms, connecting businesses with a large global worker community. The platform offers flexible, pay-per-task pricing ideal for smaller projects and organizations testing AI concepts.

Key Strengths:
- Large crowd: Global worker community
- Pay-per-task pricing: No subscriptions or minimum commitments
- Quick turnaround: Fast completion through crowd distribution
- Self-service platform: Easy project setup and management
- No minimums: Suitable for small-scale testing and research
Related Services:
- Image tagging and classification
- Text categorization
- Sentiment analysis
- Data collection and web research
- Transcription services
- Translation and localization
- Simple annotation tasks
Best For: Startups with limited budgets, researchers, small businesses, proof-of-concept projects, testing new AI applications, simple annotation tasks.
Headquarters: Essen, Germany.
15. Lionbridge AI
Founded in 1996, Lionbridge began as a localization and translation company and has evolved into a major data annotation provider leveraging its language expertise. With long-running localization experience, Lionbridge states it supports work across a wide range of languages; validate coverage for your target locales and the exact delivery model (managed service vs. platform workflows) during a pilot.

Key Strengths:
- Broad language coverage: Validate supported languages and dialects
- Long-running experience: Deep localization and linguistic expertise
- Cultural consulting: Ensuring AI appropriateness across global markets
- Gaming and e-commerce focus: Specialized expertise in these verticals
- Proprietary platform: Custom annotation tools integrated with translation workflows
Related Services:
- Multilingual text annotation
- Image labeling with cultural context
- Audio transcription across multiple languages
- Search relevance evaluation
- Content classification and moderation
- Localization quality assessment
- Gaming AI data (player behavior, in-game actions)
Best For: Global enterprises, multilingual product launches, gaming companies, international e-commerce platforms, organizations requiring cultural nuance in AI models.
Headquarters: Waltham, Massachusetts, USA
Comparative Overview: Top 15 Data Annotation Companies
| Company | Best For |
|---|---|
| Scale AI | Enterprise-scale AI projects with very high quality requirements, autonomous vehicle development, and companies handling sensitive data. |
| Unidata | AI teams, fintech companies, retail and e-commerce platforms, healthcare organizations, IT enterprises, and businesses seeking scalable, secure, and fully managed data annotation and LLM training services. |
| Labelbox | ML teams wanting flexibility between self-service and managed annotation, organizations building frontier AI models, and teams requiring strong platform capabilities with on-demand expert support. |
| Appen | Multilingual AI projects, global companies requiring cultural and linguistic diversity, NLP and speech recognition applications, and organizations needing massive scalability. |
| Sama | Organizations prioritizing ethical AI and ESG commitments, autonomous vehicle manufacturers, companies requiring audit trails for responsible AI, and projects demanding both quality and social impact. |
| CloudFactory | Companies with ongoing annotation needs, organizations preferring team continuity over crowd-based approaches, projects requiring consistent quality and institutional knowledge. |
| Dataloop AI | ML teams seeking to consolidate their technology stack, organizations wanting end-to-end AI lifecycle management, teams requiring strong data pipeline automation. |
| SuperAnnotate | Computer vision engineers, medical imaging applications, satellite imagery analysis, manufacturing quality control, projects requiring pixel-level precision. |
| Keymakr | Healthcare AI companies, autonomous vehicle manufacturers, medical device developers, any organization requiring regulatory-grade annotation with compliance documentation. |
| Alegion | Financial services, legal technology, insurance, and industries requiring complex data interpretation with specialized domain knowledge. |
| Hive | Social media platforms, content companies, startups needing rapid iteration, projects where speed is critical, organizations with large-scale moderation needs. |
| Cogito | Companies building chatbots, customer service AI, voice assistants, NLP applications, and conversational interfaces. |
| iMerit | Large-scale computer vision projects, retail and e-commerce applications, agriculture technology, autonomous vehicle development. |
| Clickworker | Startups with limited budgets, researchers, small businesses, proof-of-concept projects, testing new AI applications, simple annotation tasks. |
| Lionbridge AI | Global enterprises, multilingual product launches, gaming companies, international e-commerce platforms, organizations requiring cultural nuance in AI models. |
How to Choose the Right Data Annotation Company for Your AI Project
Selecting the right data annotation partner is a high-leverage decision: the wrong fit can surface as errors only after deployment, while the right fit makes pilots, iteration, and production scaling more predictable. Apply the following step-by-step process:
Step 1: Define Your Requirements
Before contacting vendors, document:
- Data types: Images, video, text, audio, 3D point clouds, or multimodal
- Annotation complexity: Bounding boxes, segmentation, NER, sentiment, etc.
- Volume: Current needs and projected growth
- Quality target (often expressed as a score): Only meaningful once you define what ‘correct’ means, how you will sample, and how you will measure it
- Timeline: Project deadlines and ongoing annotation needs
- Budget: Per-item cost tolerance and total budget allocation
- Compliance needs: HIPAA, SOC 2, GDPR, FDA, or other regulatory requirements
- Domain expertise: Medical, legal, automotive, e-commerce, etc.
Step 2: Shortlist Candidates
Based on your requirements, select providers from this guide that match your:
- Industry specialization
- Scale capabilities
- Compliance certifications
- Pricing model preferences
Request detailed proposals including:
- Sample annotation workflows and guidelines
- Quality assurance processes and validation methods
- Relevant case studies from similar projects
- Detailed pricing structure with volume discounts
- Security certifications and data handling practices
Step 3: Run Pilot Projects
Never commit to large-scale annotation without testing. Send a representative sample of your data to each finalist.
Evaluate:
- Actual accuracy: Measure against your own gold standard test set
- Turnaround time: Compare promises to reality
- Communication: Responsiveness and clarity
- Guideline interpretation: How well they handle your edge cases
- Quality consistency: Check if accuracy holds across the full sample
Step 4: Validate Quality Independently
Create a small gold standard test set with known correct annotations. Measure each vendor's output against your ground truth rather than relying solely on their reported accuracy.
Red flags to watch for:
- Accuracy claims not validated by independent testing
- Poor communication during the pilot phase
- Resistance to guideline clarifications or refinements
- Inability to handle domain-specific edge cases
- Lack of transparency in annotation processes
Step 5: Negotiate and Launch
Use pilot results to negotiate:
- Pricing: Volume discounts, long-term commitments
- SLAs: Quality targets and remedies (with a defined measurement method), turnaround times, escalation procedures
- Quality metrics: Regular reporting, audit rights
- Scalability: Ramp-up timelines, maximum throughput
Start with manageable batch sizes, monitor quality closely through regular sampling, and scale gradually as confidence builds.
Cost Considerations and ROI Analysis
Typical Annotation Pricing by Type
Annotation costs vary widely with task complexity and the level of detail and review depth you require. A typical pattern looks like this:
- Simple classification (low complexity). Often lower per item. This covers things like basic content moderation or assigning a simple category or label.
- Bounding boxes on images (medium complexity). Often mid-range per item. You pay more than for simple tags because annotators must draw boxes accurately around objects (for example, products in catalog photos).
- Semantic segmentation (high complexity). Often higher per image. Annotators label objects at the pixel level, which takes much more time and care. This is common in domains like medical imaging or autonomous driving.
- 3D point clouds (very high complexity). Among the highest per item. Labeling LiDAR or other 3D sensor data involves detailed 3D shapes across many frames or scenes.
- Video annotation (high complexity). Often higher per item. Video requires tracking objects over time, not just in a single frame, so effort scales with both resolution and duration.
- Text / NLP annotation (low–medium complexity). Usually in the low to moderate range per item. Examples include sentiment labeling, entity extraction, intent tagging, or dialogue annotation.
The key idea: simple tags tend to be lower cost per item, while dense vision, 3D, and long videos tend to be substantially higher per item because they require more human time and review.
Calculating Annotation ROI
You can think about annotation return on investment (ROI) in two ways:
- How much value you get from your AI system compared with what you spent specifically on annotation.
- How much value you get compared with the cost of the entire project (data + modeling + engineering).
Basic formulas
- Annotation-focused ROI:
Here you are asking: “If the project succeeds, how much benefit do I get for every unit of money I put into labeling alone?”
- Overall project ROI:
Here you compare the benefits to everything you spent (annotation, engineering, infrastructure, etc.).
Example (customer service chatbot)
Imagine a customer service chatbot that saves your company a substantial amount per year (for example, by reducing the workload on human agents). You might spend some portion of your budget on annotation (to label conversations, intents, and responses) and the rest on engineering and deployment.
- If you plug those values into the annotation‑focused formula, you’ll see that even a relatively modest annotation spend can drive a lot of value if the system works well.
- If you use the overall project formula, the ROI number will be smaller but still healthy if the savings meaningfully exceed your total costs.
The takeaway is that annotation is usually only a slice of the total budget, but it has an outsized influence on whether the model performs well enough for the project to pay off.
Key Insight: Why Data Quality Dominates
- In many AI projects, labeling and data preparation can be a minority of the total cost when you include engineering, infrastructure, and maintenance.
- Even so, data quality is a common reason models struggle in production: mislabeled examples, inconsistent guidelines, or missing edge cases can tank performance even if your model architecture is good.
Because of that, teams often treat annotation as a leverage point: a relatively small extra investment in better guidelines, QA, and expert review can unlock much higher model performance and a better business outcome.
Hidden Costs to Watch For
When thinking about budget and ROI, it helps to consider a few less visible costs:
- Rework. Fixing labeling problems after you’ve already trained and integrated a model is significantly more expensive than getting it right up front. You may need new data, retraining, re‑testing, and re‑deployment.
- Failed deployments. Many AI initiatives never make it into real production use or never deliver the hoped‑for value. Poor or inconsistent data is frequently cited as a major factor behind these failures.
- Reputation and trust. If a model behaves badly in public (for example, biased or incorrect outputs), the reputational damage and loss of user trust can be much more costly than the direct project spend.
- Opportunity cost. Time spent fixing data issues and re‑running experiments slows down your time‑to‑market. That delay can mean lost revenue or lost strategic advantage compared with competitors.
Overall, it’s often more efficient to treat data and annotation as a core product investment, not a place to cut corners: a bit more care and spending on labeling can dramatically reduce rework, risk, and failure later on.
Quality Assurance Best Practices
Industry-Standard QA Process
Many professional annotation providers use a multi-stage quality assurance workflow to ensure production-ready datasets:
Stage 1: Pre-Production Providers develop detailed annotation guidelines with visual examples and conduct annotator training sessions. Test batches validate that guidelines are clear and annotators can meet quality targets before full production begins.
Stage 2: Production Annotation Trained specialists annotate data with a project-defined quality target (as defined by the agreed evaluation protocol). Real-time spot checks and feedback loops operate continuously, allowing immediate intervention when quality metrics drift below targets.
Stage 3: Consensus Review Multiple annotators may label the same items independently. Any stated agreement target is only interpretable once the agreement definition and adjudication process are fixed. Items with low agreement are flagged for expert review.
Stage 4: Automated Quality Checks AI algorithms flag statistical outliers and inconsistencies, focusing human attention on items most likely to need correction while automatically approving obviously correct annotations.
Stage 5: Expert Validation Domain specialists review complex cases requiring professional judgment, making final decisions on ambiguous items and refining guidelines based on edge cases encountered.
Stage 6: Client Review Providers deliver representative samples for client validation. Feedback is incorporated iteratively before final delivery, preventing the expensive scenario of receiving unusable datasets.
Stage 7: Final Delivery Complete annotated dataset with comprehensive quality reports documenting accuracy metrics, QA processes applied, and recommendations for use. Any stated accuracy target should be measured against the agreed gold standard and scoring rules.
Critical Quality Metrics
These metrics are only comparable across vendors when you use the same label definitions, sampling plan, and evaluation protocol.
Accuracy: Percentage of correctly labeled items. Simple but can be misleading with imbalanced datasets.
Precision: True positives / (True positives + False positives). Critical when false positives are costly (e.g., content moderation, spam detection).
Recall: True positives / (True positives + False negatives). Essential when missing positive cases has serious consequences (e.g., medical diagnosis, fraud detection).
F1 Score: Harmonic mean of precision and recall. Preferred when balancing both metrics without favoring either dimension.
Inter-Annotator Agreement: Measures consistency between annotators using Cohen's Kappa or Fleiss' Kappa. Any stated agreement target is only interpretable once the agreement definition and adjudication process are fixed. Low agreement signals unclear guidelines or ambiguous data.
Throughput: Items per day while meeting the project’s defined quality standard. Compare throughput only within the same task setup (guidelines, tooling, and review depth), and balance speed with your chosen quality metric.
Security and Compliance Considerations
Data Security Checklist
Before sharing data with an annotation partner, verify the following:
Certifications & Documentation
Request up-to-date certification reports, review audit findings, confirm scope coverage, and track expiration dates.
Data Processing Agreements (DPAs)
Clearly define data ownership, usage limitations, breach notification timelines, liability terms, and GDPR obligations.
Encryption Standards
Ensure modern encryption for data in transit and at rest. Confirm coverage for backups and key management.
Access Controls
Require individual accounts, MFA, role-based access control (RBAC), regular access reviews, and immediate revocation when needed.
Data Retention & Deletion
Specify retention periods, require certified deletion after project completion, and verify deletion across backups and systems.
Geographic Data Residency
Confirm data center and annotator locations. For EU data, ensure Standard Contractual Clauses or equivalent safeguards are in place.
NDAs
Ensure NDAs cover all project data and are signed by individual annotators, with clear enforcement procedures.
Audit Rights
Include routine and incident-based audits, access to security logs, and third-party review rights.
Breach Notification
Establish immediate notification procedures, written investigation reports, and coordinated incident response plans.
Subprocessor Management
Require full disclosure of subprocessors, enforce equivalent security standards, and maintain approval rights.
Implementation Framework
Pre-Engagement Assessment
Conduct security due diligence before sharing data. Use structured questionnaires, request evidence, and document identified risks.
Ongoing Monitoring
Perform quarterly or semi-annual reviews, monitor for anomalies, and reassess compliance regularly.
Data Minimization
Share only necessary data, anonymize sensitive elements, and consider privacy-enhancing techniques such as data synthesis or differential privacy.
Security Culture
Ensure both internal teams and providers treat security as foundational — supported by training, clear policies, and accountability measures.
Conclusion: Making Your Final Decision
The data annotation market in 2026 offers more choice than ever, but the right decision comes down to alignment. Each provider excels in specific areas - enterprise scale, platform flexibility, domain expertise, speed, ethics, or cost efficiency. There is no universal best option, only the best fit for your use case.
Focus on data quality, validate vendors through pilot projects, and prioritize partners with proven experience in your domain. Ethical practices, scalability, and long-term collaboration matter as much as pricing and turnaround time. Since AI performance ultimately depends on training data, choosing the right annotation partner is a strategic decision that will directly shape the success of your AI initiatives.
📑 Article Disclaimer
The information contained in this article is provided for general informational and editorial purposes only. The content reflects the opinions, research, and editorial judgment of the author(s) at the time of publication and does not constitute professional, legal, financial, or business advice of any kind.
No Endorsement or Warranty
The mention, ranking, or listing of any company, product, or service within this article does not constitute an endorsement, recommendation, or guarantee of quality, reliability, or fitness for any particular purpose. The publisher makes no representations or warranties, express or implied, regarding the accuracy, completeness, timeliness, or suitability of the information provided.
Independence of Judgment
Readers are strongly encouraged to conduct their own independent research and due diligence before engaging with, contracting, or entering into any business relationship with any of the companies referenced herein. The inclusion or exclusion of any company does not imply a definitive assessment of its capabilities, compliance, or business conduct.
No Liability
To the fullest extent permitted by applicable law, the publisher, editors, authors, and any affiliated parties expressly disclaim all liability for any direct, indirect, incidental, consequential, or punitive damages arising from reliance on the information contained in this article, including but not limited to decisions made on the basis of company rankings or descriptions.
Third-Party Information
Certain information presented in this article may be sourced from third parties, publicly available data, or company self-disclosures. The publisher does not independently verify all such information and assumes no responsibility for errors, omissions, or changes occurring after the date of publication.
No Legal or Regulatory Advice
Nothing in this article should be construed as legal, regulatory, or compliance guidance. Data collection practices are subject to varying laws and regulations across jurisdictions. Readers should consult qualified legal counsel regarding their specific circumstances and applicable law.
Subject to Change
The data collection industry is dynamic. Company rankings, capabilities, and reputations are subject to change. This article represents a snapshot in time and may not reflect current market conditions.
By accessing and reading this article, you acknowledge and agree to the terms of this disclaimer.
Frequently Asked Questions (FAQ)
Timelines depend on task complexity, tooling, QA depth, and vendor capacity. Quality control can add time and cost.
In-house: For sensitive data, small volumes, proprietary expertise, or real-time ML collaboration.
Outsource: For large volumes, faster turnaround, specialized skills, or cost efficiency.
Often, a hybrid model works well: keep gold standards and edge cases in-house, outsource bulk tasks.
Key measures include:
- SOC 2 or ISO 27001-certified vendors
- Data Processing Agreements
- Encryption (in transit + at rest; confirm specifics)
- Role-based access + MFA
- Data minimization & anonymization
- Defined retention/deletion policies
- NDAs and audit rights
For highly sensitive data, consider on-premise tools or cleared facilities.
- Accuracy: Overall correctness
- Precision: Avoids false positives
- Recall: Avoids missed positives
- F1 Score: Balance of precision & recall
- Inter-Annotator Agreement: Labeling consistency
Numeric target ranges are not comparable across vendors unless measured with the same protocol; rely on your own gold standard and an agreed evaluation method.
Common methods:
- Consensus labeling (majority vote)
- Confidence scoring
- Expert review
- Guideline refinement
- Structured adjudication workflows
Track agreement rates; a sustained drop in your chosen setup signals the need to review guidelines, ambiguity, and adjudication.
Yes, but plan carefully.
Best practices: overlap vendors temporarily, validate with test sets, document guidelines clearly, and monitor quality metrics to ensure consistency.
At minimum:
- A representative sample set large enough to cover edge cases
- Clear guidelines with examples
- Edge case rules
- Quality targets
- Timeline, volume, and budget
Helpful extras: use case details, prior annotations, terminology definitions, known biases.
- Create a gold-standard dataset with expert-reviewed items and use it to score vendor output.
- Sample early batches more heavily, then reduce sampling once performance is stable under your evaluation protocol.
- Track accuracy, consistency, turnaround time, SLA compliance, and edge case handling.
Further Reading & References:
- https://www.forbes.com/sites/gilpress/2016/03/23/data-preparation-most-time-consuming-least-enjoyable-data-science-task-survey-says/
- https://www.businessofbusiness.com/articles/scale-ai-machine-learning-startup-alexandr-wang/
- https://www.reuters.com/sustainability/boards-policy-regulation/metas-148-billion-scale-ai-deal-latest-test-ai-partnerships-2025-06-13/
- https://unidata.pro/
- https://www.prnewswire.com/news-releases/dataloop-raises-16m-to-launch-its-advanced-platform-for-ai-annotation-and-management-301151958.html










