Introduction
Imagine sorting through a massive pile of letters, each containing different messages—some urgent, some promotional, others personal. Manually organizing them would take forever. Now, imagine having a smart assistant that instantly categorizes each letter based on its content. This is essentially what text classification does in the digital world—it acts as an intelligent organizer for textual data.
In this article, we’ll explore what text classification is, why it’s vital in today’s data-driven landscape, and how you can implement it effectively. We’ll cover key techniques, real-world applications, challenges, and best practices to help both beginners and professionals navigate this crucial field of machine learning (ML).

What is Text Classification?
Definition and Core Concepts
Text classification, a core task in Natural Language Processing (NLP), is powered by machine learning and deep learning. It goes beyond simple keyword matching to grasp context, intent, and sentiment. This technology fuels everything from smarter search engines to automated fraud detection, making it an essential tool in today’s AI-driven world.
Types:
Binary classification keeps things simple: it sorts text into one of two categories. A classic example is spam detection, where emails are categorized as either spam or legitimate, helping keep inboxes clutter-free.
Multiclass classification takes things a step further by sorting text into three or more categories. Imagine organizing a massive collection of news articles—some might fall under politics, others under sports, and some under entertainment. This approach makes retrieving and structuring information much easier.
Text sentiment analysis is all about figuring out the emotional tone behind a piece of text—whether it’s positive, negative, or neutral. Think of it as a mood detector for words. Businesses use it to analyze product reviews, social media posts, and customer feedback to gauge public opinion.
Toxicity detection, a close cousin of sentiment analysis, steps in to flag harmful or offensive language. It’s a game-changer for online communities, helping moderators maintain respectful discussions by weeding out toxic comments, hate speech, or cyberbullying.
Intent recognition is like reading between the lines—it’s used to understand the purpose behind a user’s message. This is what powers chatbots and virtual assistants, allowing them to respond accurately based on whether a user wants to book a flight, check the weather, or just say hello.
Intent Annotation for E-commerce
- E-commerce and Retail
- 150,000 user messages
- Ongoing project
Topic categorization, which is similar to multiclass classification, groups content based on predefined themes. For instance, a news aggregator might categorize articles into topics like health, technology, and finance, making it easier for readers to find relevant content.
Language identification is like a built-in translator’s assistant—it detects which language a piece of text is written in. This is crucial for multilingual applications, helping platforms provide language-specific services or translations.
Question classification helps search engines and virtual assistants by categorizing questions based on the type of answer expected. For example, "Who is the president of the U.S.?" and "How tall is Mount Everest?" require different response formats. This makes information retrieval much more efficient.
Named entity recognition (NER) works like a highlighter for key information, identifying and classifying names of people, places, organizations, dates, and more. It’s widely used in search engines, financial analysis, and even legal document processing. We have a dedicated service that can make outsourcing your NER tasks both easy and professional.
Benefits of Text Classification
Text classification is not just a technical endeavor—it’s a game-changer for businesses and industries. Let’s explore the key benefits:
1. Enhancing Data Organization & Retrieval
Think of text classification as a well-structured library—without it, finding a book in a disorganized heap would be impossible. By categorizing documents, emails, and messages, organizations can quickly retrieve relevant information and improve workflow efficiency.
2. Driving Informed Decision-Making
Just like a seasoned detective analyzing clues, text classification helps organizations extract meaningful insights from raw text data. Businesses use sentiment analysis to gauge public opinion, while financial institutions rely on it for fraud detection.
Case Study: X employs text classification to analyze millions of tweets daily, providing companies with real-time sentiment analysis of their brand perception.
3. Improving Operational Efficiency
Automated text classification reduces manual effort, allowing businesses to focus on strategic initiatives. Customer support teams, for instance, can use text classification to automatically route queries to the appropriate departments.
4. Automating Large-Scale Text Analysis
With AI-driven text classification, organizations can process massive volumes of unstructured text at lightning speed, identifying trends and patterns that would otherwise go unnoticed.
| Benefit | Impact |
|---|---|
| Data Organization | Easier access and retrieval of textual data |
| Decision-Making | Extract actionable insights from text |
| Operational Efficiency | Reduce manual effort and costs |
| Large-Scale Text Analysis | Process massive amounts of text quickly |
The Power of Text Classification Across Industries
Text classification has quietly become one of the most transformative tools in artificial intelligence, automating tasks that once required painstaking manual effort. Here’s a closer look at how different sectors are harnessing the power of text classification.
1. Business & Marketing: Understanding Customers at Scale
In today’s digital world, businesses are drowning in customer feedback—social media comments, reviews, and support tickets pour in by the second. Text classification helps make sense of all this unstructured data, turning it into actionable insights.

Sentiment analysis functions as a virtual ear to the ground, determining if feedback is positive, negative, or neutral. Companies such as Amazon and Yelp use this technology to gauge customer satisfaction trends and refine their services accordingly. Outsourcing sentiment analysis can save companies time while providing valuable data to boost their business.
Customer Feedback Categorization goes beyond emotions, grouping reviews into relevant topics. For example, an e-commerce platform might automatically separate complaints about delivery from those about product quality, helping companies pinpoint areas for improvement.
2. Cybersecurity: Fighting Digital Threats
With cyber threats on the rise, AI-powered text classification plays a critical role in protecting users from malicious attacks.
Spam & Phishing Detection is at the front line of email security, filtering out harmful messages before they reach users. Gmail’s ML-based spam filter, for instance, blocks over 100 million spam emails daily.
Fraud Prevention leverages text patterns to detect fraudulent transactions in banking and e-commerce. Suspicious language in financial requests—like those common in phishing scams—triggers alerts, preventing scams before they cause damage.
3. Healthcare: Organizing Medical Knowledge
Healthcare is another sector benefiting from AI-driven text classification, helping doctors, researchers, and patients make sense of complex medical information.
Medical Record Classification organizes patient records based on diagnosis and treatment history, making retrieval more efficient. Hospitals use this to streamline administrative processes and improve patient care.
Symptom-Based Diagnosis assists doctors in predicting potential diseases by analyzing patient descriptions. AI-driven models, trained on vast medical datasets, suggest possible conditions based on textual inputs, aiding in faster diagnosis.
4. Media & Journalism: Sorting Truth from Misinformation
In the age of information overload, text classification helps media organizations manage and verify vast amounts of content.

Fake News Detection flags misleading or manipulated articles, helping prevent the spread of misinformation. Social media platforms and news aggregators use ML classifiers to assess credibility and reduce the impact of false reporting.
Topic Labeling ensures that news articles are accurately categorized into predefined sections—politics, sports, entertainment—allowing readers to find relevant content effortlessly.
5. Legal & Compliance: Navigating Complex Regulations
Legal professionals deal with mountains of documents, from contracts to compliance reports. Text classification streamlines the process, saving time and reducing human error.

Contract Classification identifies key clauses, obligations, and legal terms, making contract analysis faster and more reliable. AI tools can highlight risks or missing information in agreements, preventing costly legal disputes.
Regulatory Compliance ensures that businesses adhere to industry-specific regulations by automatically classifying legal and corporate documents. This helps companies stay compliant with minimal manual intervention.
| Industry | Application | Example |
|---|---|---|
| Business & Marketing | Sentiment Analysis | Customer review monitoring on Amazon & Yelp |
| Cybersecurity | Spam & Fraud Detection | Gmail spam filter & banking fraud detection |
| Healthcare | Medical Record Classification | AI-assisted patient diagnosis |
| Media & Journalism | Fake News Detection | Facebook misinformation flagging |
| Legal & Compliance | Contract Classification | AI-driven legal document review |
Approaches to Text Classification
Text classification can be approached using various methods, ranging from rule-based approaches to machine learning (ML) and deep learning techniques. Each approach has its strengths and weaknesses, making them suitable for different use cases.

1. Rule-Based Methods
Rule-based text classification relies on manually defined rules, such as keywords, pattern matching, and Boolean expressions. These systems are particularly effective in structured environments where text follows predictable patterns.
For example, a simple spam filter might flag emails containing phrases like “free money” or “urgent.” While this approach works well for clear-cut cases, it struggles with more sophisticated phishing attempts that use subtle variations in wording.
The key advantage of rule-based systems is their simplicity—they are easy to implement and can achieve high precision for specific cases. However, they require constant manual updates to remain effective and often fail when faced with linguistic variations, such as synonyms or different writing styles.
Bag-of-Words (BoW)
The Bag-of-Words (BoW) model represents text as a collection of word occurrences, ignoring grammar and word order. It is a foundational technique in text classification, commonly used in applications like spam detection and topic categorization.
For instance, in BoW, the sentences “The cat chased the dog” and “The dog chased the cat” are treated as identical because they contain the same words, despite having different meanings.
BoW is computationally efficient and straightforward to implement, making it useful for basic text analysis. However, it can lead to sparse, high-dimensional data representations and struggles with capturing context or semantic meaning.
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF enhances BoW by weighting words based on their importance in a document relative to a collection of documents. This method is widely used in search engines, document ranking, and keyword extraction. Here’s the formulas:
$$$\mathrm{TF}(t, d) = \frac{n_t}{\sum_k n_k}$$$
Where nt is the number of occurrences of token t in the document, and the denominator is the total number of words in document d. This represents the frequency of the token in that document.
$$$\mathrm{IDF}(t, D) = \log \left(\frac{|D|}{\left|\{\,d_i \in D \mid t \in d_i\}\right|}\right)$$$
is the set of documents in the text collection D that contain the token t. This factor penalizes components corresponding to overly common tokens and increases the weight of tokens that are specific (and presumably more informative) to individual documents.
$$\{\,d_i \in D \mid t \in d_i\}$$ is the set of documents in the text collection D that contain the token t. This factor penalizes components corresponding to overly common tokens and increases the weight of tokens that are specific (and presumably more informative) to individual documents.
Unlike BoW, TF-IDF reduces the influence of common words like “the” or “and” while emphasizing distinctive terms. For example, in a news article about climate change, the word “carbon” would carry more weight than “is” or “the” because it is more specific to the topic.
TF-IDF is particularly useful for identifying key terms in text, improving relevance in search and retrieval tasks. However, like BoW, it treats words independently and does not capture deeper contextual relationships, limiting its ability to fully understand the meaning of text.

2. Machine Learning-Based Methods
Machine learning approaches leverage statistical models to classify text based on learned patterns. These models can be trained using labeled datasets and optimized for accuracy over time.
Supervised Learning Algorithms for Text Classification
Supervised learning requires a dataset with predefined categories. Some popular algorithms include:
| Algorithm | Description | Use Case |
|---|---|---|
| Naïve Bayes | Probabilistic model based on word frequencies | Spam filtering |
| Random Forests | Ensemble of decision trees | Topic classification |
| Logistic Regression | Statistical model for binary / multiclass classification | Customer feedback categorization |
Unsupervised Learning in Text Classification
When labeled data is limited or unavailable, unsupervised learning techniques step in to make sense of raw text without human-defined categories. Unlike supervised learning, which relies on labeled examples, unsupervised methods identify patterns, structures, and relationships within data on their own.
One of the most popular approaches is clustering, where algorithms like K-Means group similar texts based on their content. Another powerful technique is topic modeling, with Latent Dirichlet Allocation (LDA) being a widely used method for uncovering hidden themes in large text corpora.
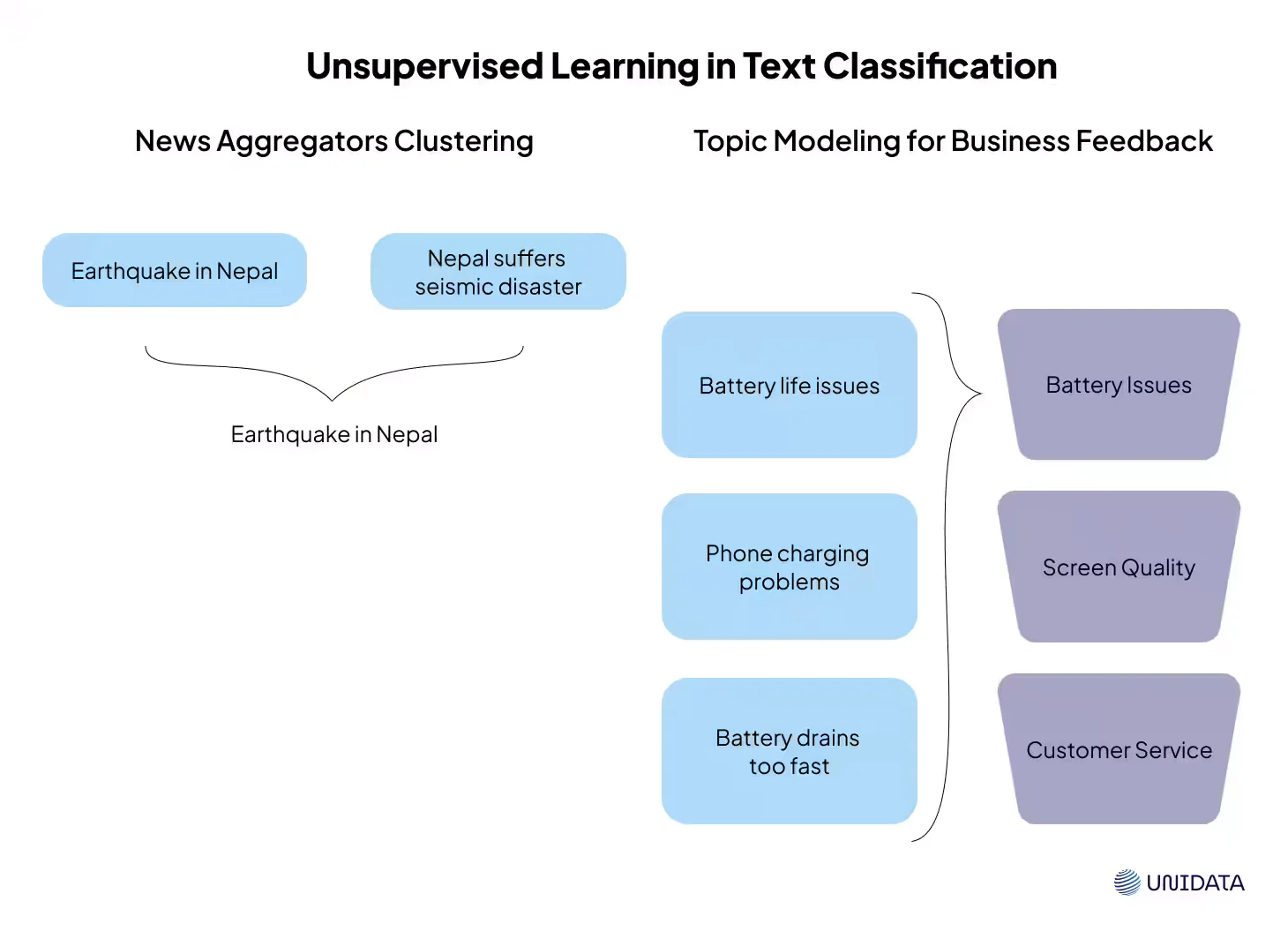
For example, news aggregators use unsupervised learning to automatically cluster articles about the same event, even if they come from different sources and use varying terminology. Similarly, businesses leverage topic modeling to analyze customer feedback and identify recurring concerns without manually labeling each response. While unsupervised methods offer flexibility and scalability, they often require fine-tuning to generate meaningful and interpretable results.
3. Deep Learning-Based Methods
Deep learning has dramatically advanced text classification, allowing models to learn intricate language structures and capture complex contextual meanings. Traditional machine learning models rely on handcrafted features, whereas deep learning methods automatically extract and refine patterns from raw text. Some of the most effective architectures include:
Recurrent Neural Networks (RNNs) & Long Short-Term Memory (LSTM)
RNNs and their improved variant, LSTMs, are designed to process sequential data, making them well-suited for tasks where word order matters. By maintaining a memory of previous words, these models excel in sentiment analysis, chatbot interactions, and text generation. For example, an LSTM-based sentiment classifier can determine whether a customer review conveys positive or negative emotions by analyzing sentence structure and contextual clues.
Convolutional Neural Networks (CNNs) for Text Classification
Although CNNs are primarily associated with image processing, they have proven effective for text classification by capturing local word patterns. By applying filters to text data, CNNs detect important n-grams (short sequences of words) that signal different categories. These models are particularly useful for classifying short texts, such as X (Twitter) sentiment analysis, where identifying key phrases is more important than understanding full sentence structures.
Transformer-Based Models (BERT, GPT, RoBERTa)
Transformers represent the pinnacle of modern NLP, allowing models to understand words in context rather than in isolation. Unlike RNNs, which process words sequentially, transformers analyze entire sentences at once, capturing nuanced relationships between words.
- BERT (Bidirectional Encoder Representations from Transformers) excels at understanding the meaning of a word based on both its preceding and following context, making it highly effective for text classification tasks.
- GPT (Generative Pretrained Transformer) models, such as ChatGPT, are designed to generate coherent and contextually aware text, making them powerful for tasks that require a deep understanding of language structure.
A notable real-world application of transformers is Google’s BERT update in 2019, which significantly improved search engine comprehension of natural language queries, resulting in more relevant search results.
Challenges in Text Classification
While text classification has become more powerful, several challenges remain that can affect model performance and reliability.
Unstructured Data
Unlike structured databases with neatly organized rows and columns, raw text is highly unstructured, filled with variations in spelling, grammar, and formatting. Before classification models can make sense of text, it must go through extensive preprocessing, which typically involves:
- Tokenization – Breaking text into individual words or phrases.
- Stopword Removal – Filtering out common words like the, and, is that do not add meaningful value.
- Stemming & Lemmatization – Reducing words to their root forms to unify similar words (e.g., "running" → "run").
Without these preprocessing steps, text classification models may struggle with inconsistencies and irrelevant noise in the data.
Noisy Data
Real-world text data is rarely clean. Social media posts, customer reviews, and user-generated content are often riddled with typos, slang, abbreviations, emojis, and informal language. This noise makes it difficult for traditional text classification models to function effectively.
A robust text preprocessing pipeline is essential to handle such inconsistencies. Common preprocessing steps include:
- Spell correction to fix typos and misspellings.
- Text normalization to standardize abbreviations and slang (e.g., converting "u" to "you").
- Entity recognition to identify proper names, brands, and domain-specific terms.
Class Imbalance
Some categories may have significantly more training data than others, leading the model to favor majority classes while neglecting minority ones. This is particularly problematic in fraud detection, where fraudulent cases are much rarer than legitimate transactions.
Ambiguity in Language
Many words have multiple meanings depending on context. For example, “apple” could refer to the fruit or the tech company, leading to potential misclassification. Advanced models like BERT help address this issue, but challenges remain in cases requiring deep contextual understanding.
Domain-Specific Jargon
A text classification model trained on general datasets may not perform well in specialized industries like healthcare or law, where technical terms and abbreviations are common. Fine-tuning models on domain-specific data is crucial to achieving high accuracy in such fields.
Scalability and Performance Issues
As the volume of text data grows, ensuring real-time classification becomes a major challenge. Large-scale platforms like Facebook, which process billions of posts daily, require highly optimized architectures to keep up with the demand. Achieving this level of scalability relies on several key techniques:
- Efficient Indexing – Search engines and recommendation systems use tools like Elasticsearch to quickly retrieve and classify text.
- Parallel Processing – Distributed computing frameworks like Apache Spark allow models to process vast amounts of text simultaneously.
- Model Optimization – Techniques such as quantization and distillation reduce model size and computational requirements, enabling faster inference without sacrificing accuracy.
Without these optimizations, text classification models can become bottlenecks, leading to slow responses and increased computational costs.
Getting Started with Text Classification
For those new to text classification, here’s a step-by-step roadmap:
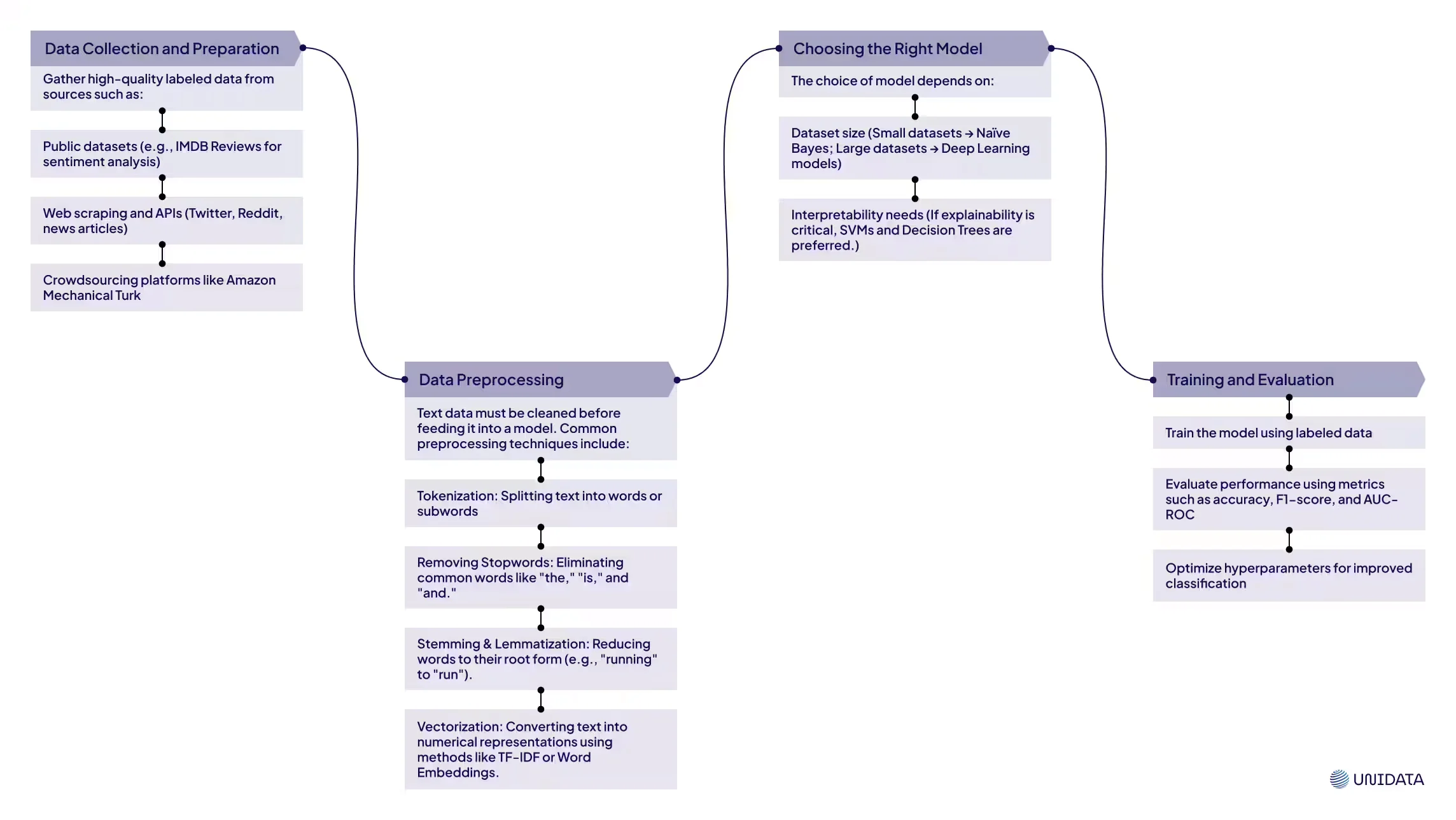
Here is the comparative table of the models to choose from:
| Model Type | Pros | Cons |
|---|---|---|
| Naïve Bayes | Fast, works well with small datasets | Assumes feature independence |
| LSTM | Good for sequential text | Requires large datasets |
| BERT | State-of-the-art accuracy | High resource consumption |
Tools and Frameworks to Get Started with Text Classification
The good news? You don’t have to build everything from scratch. There are plenty of tools and frameworks designed to simplify the process.
Popular Libraries and Platforms
| Tool | Used In | Key Features | Example Use Case |
|---|---|---|---|
| Scikit-learn | Traditional Machine Learning | Supports classification, regression, and clustering | Email spam detection, sentiment analysis with logistic regression |
| NLTK / SpaCy | Text Preprocessing & Basic NLP Tasks | Tokenization, stemming, lemmatization, POS tagging, named entity recognition | Extracting named entities from news articles, preprocessing text for classification |
| TensorFlow / PyTorch | Deep Learning for NLP | Optimized for neural networks, supports large-scale models, offers flexibility and customization | Training a sentiment analysis model on Twitter data, developing a chatbot |
| Libraries from Hugging Face | Pre-trained NLP Models | State-of-the-art transformers (BERT, GPT, etc.), extensive model hub, fine-tuning support | Fine-tuning BERT for customer support automation, text summarization for news articles |
Best Practices for Implementing Text Classification
Creating a powerful text classification system isn’t just about picking a good algorithm and calling it a day. If you want your model to actually work—and keep working—you need to focus on three key things: clean data, regular updates, and making sure your AI isn’t making biased or unfair decisions. Here’s how to do it right.
Keep Your Data Clean and Balanced
Your model is only as good as the data it learns from. If that data is messy, full of duplicates, or unbalanced, your classifier will be just as unreliable as a weather forecast from 2005. To keep things on track:
- Ditch the duplicates – No need to learn the same thing twice.
- Filter out the noise – Irrelevant text will only confuse the model.
- Balance your data – If one category has way more samples than another, the model might get lazy and favor it.
Good data = good results. It’s that simple.
Update Your Model—Because Language Evolves
Language is always shifting. New slang, industry jargon, and even emojis take on new meanings over time. If your model isn’t keeping up, it’s going to start making mistakes—like thinking "fire" is just about flames instead of a compliment.
The solution?
- Retrain with fresh data so the model stays relevant.
- Use transfer learning—instead of starting from scratch, fine-tune a pre-trained model (like BERT) to fit your specific needs. Think of it as giving your model a quick refresher instead of making it relearn everything from the beginning.
Make Sure Your AI Plays Fair
No one wants an AI that makes unfair predictions—whether it’s sentiment analysis, hiring tools, or content moderation. If your model is unknowingly reinforcing bias, it can lead to some serious problems.
How do you prevent this?
- Check for bias – Words, topics, or patterns in the training data might be skewing results unfairly.
- Make decisions transparent – Users should have some insight into why the AI made a certain classification.
Case Study: IBM’s AI Fairness 360 toolkit helps developers catch and reduce bias in NLP models, making AI-driven decisions more ethical.
Conclusion
Text classification is a powerful tool that enables businesses, researchers, and developers to harness the full potential of textual data. Whether you're detecting spam, analyzing customer sentiment, or automating document categorization, understanding and implementing the right techniques can drive better decision-making and efficiency.
Next Steps for Enthusiasts and Professionals
- Experiment with real-world datasets
- Build your own text classifier using Python (Scikit-Learn, TensorFlow, PyTorch)
- Stay updated with NLP research (Hugging Face, arXiv papers, Kaggle competitions)
Frequently Asked Questions (FAQ)
Text classification is a core task in NLP that uses machine learning and deep learning to automatically categorize text into predefined labels. It goes beyond keyword matching by understanding context, intent, and sentiment, enabling applications like spam detection, sentiment analysis, and topic categorization.
Yes, text classification is a fundamental task within Natural Language Processing (NLP). It focuses on organizing and labeling unstructured text data, allowing machines to interpret human language for tasks like intent recognition, sentiment analysis, and content filtering.
The main types of text classification include binary classification (e.g., spam vs. not spam), multiclass classification (multiple categories like news topics), sentiment analysis (positive, negative, neutral), toxicity detection, intent recognition, and topic categorization. Each type serves different business and analytical needs.
Text classification works by preprocessing text (tokenization, stopword removal), converting it into numerical representations (e.g., TF-IDF or embeddings), and applying machine learning or deep learning models such as Naïve Bayes, LSTM, or transformers like BERT to assign categories based on learned patterns.
Text classification is widely used in spam filtering, fraud detection, customer feedback analysis, medical record organization, fake news detection, and legal document classification. It helps businesses automate large-scale text analysis and improve decision-making.
Key challenges in text classification include handling unstructured and noisy data, managing class imbalance, understanding ambiguous language, adapting to domain-specific jargon, and scaling models for real-time processing. Continuous data cleaning and model updates are essential for maintaining accuracy.