Synthetic data is artificially generated information that mimics the statistical properties of real-world data, crafted through algorithms or simulations to resemble authentic datasets without containing any actual real-world information.
It has become a valuable resource in situations where real data is limited, sensitive, or challenging to collect.
Synthetic data provides a privacy-compliant, scalable alternative to real datasets, making it especially valuable for training AI models and supporting research and development in areas that require robust, diverse data.

In machine learning, synthetic data plays a transformative role by addressing challenges like data scarcity, privacy concerns, and potential biases in real datasets. By generating data that replicates real-world phenomena, synthetic data enables machine learning models to be trained, tested, and validated across a wider range of scenarios. This approach not only supports the development of more generalizable and reliable models but also ensures compliance with data privacy regulations.
Synthetic data is instrumental in exploring rare events and edge cases, which are often underrepresented in real data, thereby enhancing model performance and resilience in real-world applications. Through these capabilities, synthetic data accelerates innovation and expands the possibilities of what machine learning can achieve.
Why Synthetic Data? The Motivation Behind Its Use
The demand for synthetic data originates from several key challenges:
- Data Scarcity: In many cases, gathering real-world data is time-consuming, costly, or impossible. Autonomous vehicles, for example, require millions of miles of driving data to improve, which is costly and takes years to accumulate.
- Privacy Concerns: Real data often involves sensitive information, particularly in sectors like healthcare or finance. Synthetic data can represent the statistical properties of real data without exposing actual user data, safeguarding privacy.
- Control and Flexibility: Synthetic data offers flexibility in modeling and controlling variables, enabling ML engineers to simulate specific scenarios and edge cases that may be underrepresented or even absent in real-world data.
Together, these benefits make synthetic data a valuable asset for training, testing, and validating ML models. Synthetic data expands possibilities beyond what’s achievable with real data alone, accelerating ML development in secure and innovative ways.
Types
Synthetic data comes in various forms, each suited to specific applications:
- Fully Synthetic Data: Contains no real data; created entirely by algorithms, often from scratch or through simulation.
- Hybrid Synthetic Data: Combines real and synthetic data, where synthetic data fills gaps or augments real-world datasets.
Synthetic data can also be classified by format:
- Structured Data: Found in databases and tabular form, used in areas like finance.
- Unstructured Data: Includes images, audio, and video, commonly used in computer vision and NLP.
- Sequential Data: Time-series data, crucial in financial and environmental modeling.
It can also be classified according to its nature and generation method:
| Synthetic data type | Description | Application |
|---|---|---|
| Numerical | Includes artificially generated data with numerical values, often used in statistics, finance, and healthcare analytics. | Simulations, predictive modeling, and risk assessments, financial modeling, medical research for simulating patient data, and industrial process optimization |
| Categorical | Entails generating non-numerical entries that belong to a set of categories, such as yes/no answers, types of products, or demographic information. | Market research, customer segmentation, recommendation systems, and demographic analysis |
| Textual | Artificially generated text that mimics the style, structure, and linguistic patterns of human language. | Natural language processing (NLP) applications, training chatbots and sentiment analysis models, language translation, text summarization, and named entity recognition (NER) |
| Image | Comprises artificially created images or altered real images used predominantly in computer vision tasks. | Testing image recognition models, training and testing image recognition models, object detection, and segmentation models |
| Audio | Consists of generated sounds, speech, or music, providing valuable resources for machine learning in the auditory domain | Refining voice recognition systems, speech-to-text technologies, and digital assistants, audio classification |
| Time-series | Involves sequences of data points indexed in time order, often used in forecasting models. | Stock market analysis and weather forecasting, sensor data simulation, where temporal patterns and trends |
| Tabular | The data is structured in tables, similar to what you'd find in relational databases. | Testing database systems, developing business intelligence applications, and conducting research (supporting structured data analysis in research across domains like finance, healthcare, and customer analytic) |
| Mixed-type | Combines multiple types—such as numerical, categorical, and text—into a single dataset, enabling comprehensive testing and model development | Testing and developing new models, can be applied in multiple scenarios, such as predictive analytics, healthcare diagnostics, and customer profiling |
Synthetic Data vs. Real Data: A Comparative Analysis
While synthetic data offers many benefits, it’s essential to understand how it stacks up against real-world data.
| Criteria | Real Data | Synthetic Data |
|---|---|---|
| Cost | High | Lower |
| Scalability | Limited by availability | Easily scalable |
| Privacy | Risk of exposure | High privacy assurance |
| Control | Limited control | Full control over features |
| Representativeness | Generally accurate | May have biases if poorly generated |
| Time Spent | Takes a lot of time | Quicker to obtain |
Synthetic data shines where scalability, privacy, and control are crucial, though real data often provides unmatched authenticity. Many organizations are now combining real and synthetic data to achieve the best of both worlds.
How Synthetic Data Is Generated
Synthetic data generation involves leveraging sophisticated algorithms and models to create datasets that closely mimic the characteristics of real-world data. These techniques aim to replicate the patterns, trends, and correlations found in original datasets, making synthetic data a valuable resource for machine learning, data analysis, and privacy-preserving applications.
Here are some of the most commonly used methods for generating synthetic data:
Generative models
Generative models are algorithms designed to create new data points that resemble the original dataset. These models learn patterns, distributions, and structures in the training data, enabling them to generate realistic synthetic data.
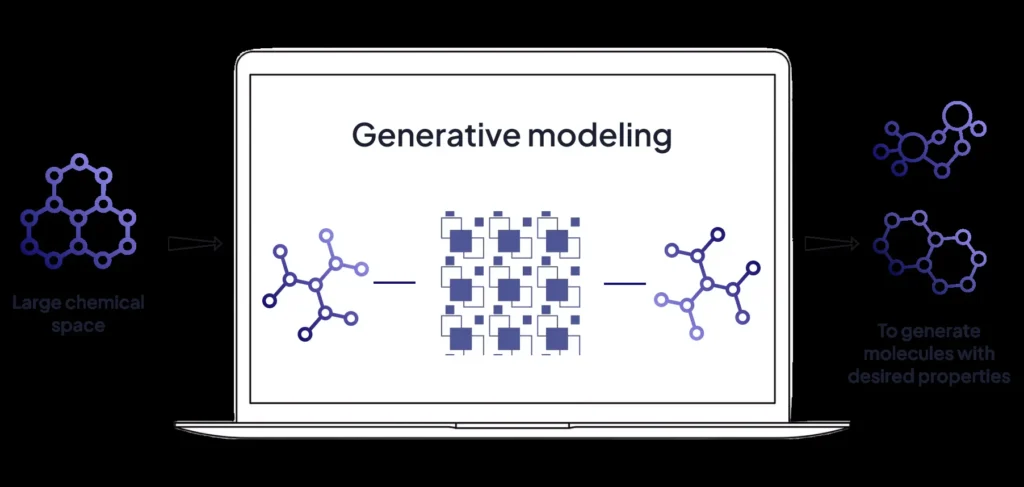
Here are a few key examples:
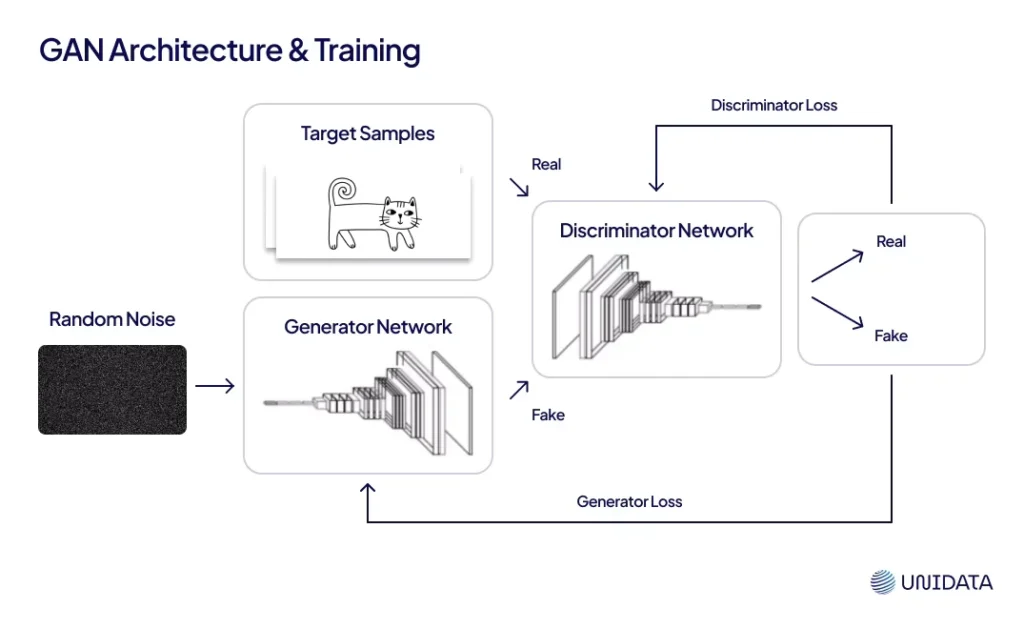
Generative Adversarial Networks (GANs)
involve two competing neural networks—a generator that creates synthetic data, and a discriminator that tries to identify if the data is real or synthetic. This adversarial training leads to high-quality, realistic data generation.
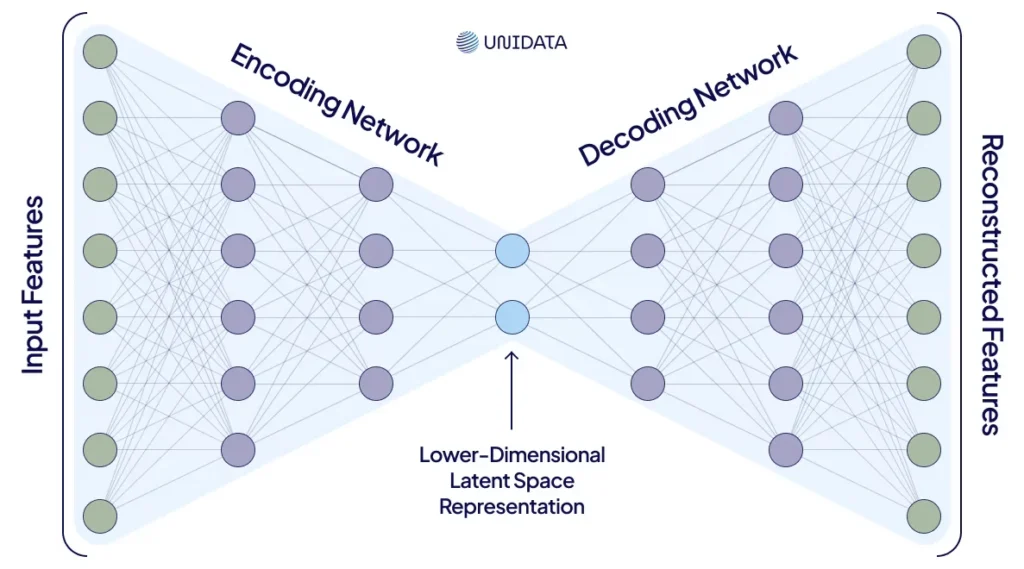
Variational Autoencoders (VAEs)
Encode data into a compressed latent space, then decode it back to generate new samples. This approach captures complex relationships within the data, making it effective for generating diverse and realistic synthetic data.
Statistical Modeling
Statistical models use probabilistic techniques to simulate data based on the distributional properties of the original dataset. By capturing underlying statistical patterns, this method produces data with similar characteristics to the original.
Simulation-based methods
These involve creating data based on simulations of real-world processes or systems. This approach is often used in domains where the underlying mechanisms of the system are well-understood, such as in engineering or environmental science.
Data augmentation
Data augmentation is primarily used to expand existing datasets by modifying real data points rather than creating entirely new ones. It involves applying transformations like cropping, rotating, flipping, scaling, or adding noise to generate varied data points. This technique is especially prevalent in image and signal processing tasks, where it enhances model robustness and helps prevent overfitting by introducing diversity into the training data.

Data augmentation technique for synthetic data generation
Rule-Based Data Generation
Rule-based data generation uses predefined rules, based on expert knowledge, to create synthetic data that follows expected patterns and distributions. This method is especially effective in domains where data patterns and constraints are well-understood and can be easily codified, such as in finance, healthcare, and customer behavior modeling. While it ensures consistency and domain relevance, rule-based generation may lack the flexibility to capture complex or unexpected variations in the data.
Synthetic Minority Over-sampling Technique (SMOTE)
In machine learning, SMOTE is a popular method for handling imbalanced datasets by generating synthetic examples of the minority class. It works by interpolating between existing minority class instances to create new synthetic data points, thus balancing the dataset. This process improves the performance and generalization of classification algorithms, which might otherwise favor the majority class. However, while SMOTE can be highly effective, it may sometimes lead to overfitting in the minority class or create overlapping data points, requiring additional techniques or parameter tuning.

Comparing Synthetic Data to Other Anonymization Techniques

Tools used for generating Synthetic Data
Synthetic data generation tools can range from open-source libraries designed for research and development to commercial platforms offering advanced features for enterprise use.
Here we have hand-picked a set of tools commonly used for synthetic data generation.
- Synthea: An open-source simulator that generates synthetic patient data for healthcare applications. Synthea models the medical history of synthetic patients, producing realistic but not real patient data for research and analysis without compromising privacy.
- DataRobot: Offers AI and data science solutions, including synthetic data capabilities. It's designed for businesses looking to build predictive models without risking sensitive data exposure.
- Hazy: A commercial tool that generates synthetic datasets that statistically resemble your original data, allowing for safe sharing and analysis while protecting sensitive information.
- MOSTLY AI: A tool specialized in generating synthetic tabular data, ideal for customer data privacy and compliance. It uses AI to create data that is structurally similar to the original dataset but doesn’t contain any real user information.
- Mockaroo: A flexible tool for developers and testers to create realistic datasets up to 1,000 rows for free with SQL and JSON download options. It's ideal for smaller projects or initial testing phases.
- Tonic: Targets businesses needing to create synthetic versions of their databases for development, testing, or analytics purposes. Tonic offers fine-grained control over the data anonymization and synthesis process, ensuring that the synthetic data remains useful for its intended purpose while eliminating personal information.
- Artbreeder: Focused on creating synthetic images, Artbreeder allows users to blend and modify images using GANs, making it useful for creating varied visual content without real-world limitations.
How To Generate Synthetic Data: Full Guide
Learn more
How Good is the Quality of Synthetic Data? Ways to Measure It
Assessing the quality of synthetic data is crucial for ensuring it can effectively support machine learning models. Synthetic data quality determines how well the trained model will perform when applied to real-world data. Here are key indicators and methods used to measure synthetic data quality:
- Statistical Similarity: One of the primary ways to measure synthetic data quality is by checking its statistical similarity to the real-world dataset. Metrics like mean, variance, and distribution shape are compared between synthetic and real data to ensure alignment. Techniques such as the Kolmogorov-Smirnov test and Wasserstein distance can quantitatively measure how closely the distributions match.
- Correlation Preservation: Real-world data often contains correlations between variables that are essential for accurate predictions. Synthetic data should maintain these relationships to ensure the ML model understands the underlying patterns. Pearson or Spearman correlation coefficients can be used to assess whether the synthetic data maintains similar variable relationships.
- Diversity and Variability: Good synthetic data should capture the diversity found in real-world data. Diversity metrics assess how well the synthetic data represents different segments or categories within the data, such as demographics in healthcare or types of purchases in retail. The Simpson diversity index or entropy-based measures can help evaluate this variability.
- Performance on ML Models: One of the most practical ways to assess synthetic data quality is by training and testing an ML model on synthetic data and then evaluating its performance on real data. If the model trained on synthetic data performs comparably on real-world data, this indicates that the synthetic data quality is high. Metrics like accuracy, precision, recall, and F1 score are typically analyzed.
- Privacy and Anonymization Quality: To ensure privacy, synthetic data must differ sufficiently from real data while retaining meaningful patterns. Differential privacy metrics measure how much the synthetic data protects against the re-identification of individuals. The privacy loss parameter (epsilon) in differential privacy frameworks is one such metric, with lower values indicating stronger privacy protection.
- Domain-Specific Metrics: In certain fields, specific domain metrics are essential to assess the relevance and usability of synthetic data. For instance, in financial synthetic data, tracking transaction flow and fraud pattern similarity is important. In healthcare, disease progression and treatment response patterns must be accurately represented. Domain experts often tailor quality metrics to meet specific industry requirements.
- Visualization Techniques: Plotting synthetic and real data can reveal visual differences or similarities, allowing for an intuitive quality check. Scatter plots, histograms, and heatmaps enable quick assessments of data distribution, outliers, and clustering patterns, providing valuable visual feedback.
High-quality synthetic data requires careful generation and validation to ensure it aligns well with real-world data characteristics while upholding privacy standards. Each quality measurement approach ensures that the synthetic data is not only realistic but also valuable for robust and ethical ML model development.
Common applications
Synthetic data has a wide range of applications across various industries and research fields., It is quite applicable across contexts due to its ability to simulate real-world data overlooking the associated privacy concerns or the limitations of scarce datasets. Let’s dive into some of the real-world applications of synthetic data.
Training machine learning models
One of the most prevalent uses of synthetic data is in training and testing machine learning and AI models, especially when real data is limited, sensitive, or expensive to collect. Synthetic data can help in creating robust models by providing diverse and extensive datasets.
Data privacy and anonymization
Synthetic data enables the use of realistic data sets without compromising individual privacy, making it ideal for industries governed by strict data protection regulations, such as healthcare, finance, and education.
By generating data that mimics real-world scenarios, businesses can test and train AI models while adhering to privacy laws like the General Data Protection Regulation (GDPR) in Europe or the Health Insurance Portability and Accountability Act (HIPAA) in the United States. This ensures that sensitive personal information remains protected while still allowing organizations to leverage valuable data for innovation and decision-making.
Software testing and development
Developers use synthetic data to test new software, applications, and systems in a controlled environment. This allows for the identification and rectification of bugs and vulnerabilities without exposing real user data. For example, industries (e.g., fintech, gaming) where synthetic data is commonly used in software testing, provide more context.
Healthcare research
In the healthcare industry, synthetic data can simulate patient records, genetic information, and disease outbreaks, facilitating research and development while ensuring patient confidentiality is maintained.

Financial modeling
Banks and financial institutions utilize synthetic data for stress testing, fraud detection models, and risk assessment without the risk of exposing real customer data or violating privacy laws. Synthetic financial data can also be used for training machine learning (ML) models to detect anomalies, predict trends in financial markets, and improve decision-making in areas like asset management or market forecasting.
Autonomous vehicle training
The development of autonomous vehicles relies heavily on synthetic data for training algorithms in object recognition, decision-making, and scenario simulation. This method provides a safe and efficient way to cover diverse driving conditions and scenarios that may be difficult or dangerous to replicate in the real world. Moreover, synthetic data is invaluable for generating corner cases or rare event simulations—such as unusual weather conditions or road hazards—enabling autonomous systems to better respond to unpredictable situations.
Retail and e-commerce
Synthetic data helps in customer behavior analysis, product recommendations, and market research, allowing retailers to enhance customer experience and optimize inventory management without relying on sensitive customer data.
Cybersecurity
Synthetic data is used in cybersecurity to simulate network traffic, attack patterns, and security threats for testing and improving security systems. It is especially useful for training intrusion detection systems (IDS) and malware analysis tools, helping to detect and respond to cyberattacks like phishing, denial-of-service, or ransomware without compromising real data.
Avatar Creation for AR/VR
In AR and VR, synthetic data aids in creating realistic simulations for training, entertainment, and education. Lifelike portraits are used to design customizable avatars in augmented and virtual reality platforms, enhancing user experiences in gaming, virtual meetings, and training simulations.
Generated portraits demonstrate the realism achievable with synthetic data, ideal for industries like AR/VR and marketing.

With its various applications, synthetic data helps solve business problems at scale. In this section, we have provided examples of 3 use cases of synthetic data for machine learning.
Case 1: Facial recognition systems for airport security
Airports need highly accurate facial recognition systems for security screenings but collecting diverse facial images across various ethnicities, lighting conditions, and angles while ensuring privacy is challenging.
- Synthetic data solution: Generative Adversarial Networks (GANs) are leveraged to generate a large, diverse dataset of synthetic faces. This dataset simulates real-world variations by including a wide spectrum of ethnicities, ages, and facial expressions, along with various occlusions and accessories. Each synthetic image is created with variations in lighting, background, and angle to mirror real-life airport environments accurately. This diversity enables the model to learn to identify and distinguish faces under challenging conditions, improving robustness.
- Results: The enhanced facial recognition system, trained on this comprehensive synthetic dataset, shows significantly improved accuracy and reduced bias in real-world tests, leading to faster, more secure airport screenings without compromising passenger privacy.
Case 2. Financial fraud detection scenarios for banks
Financial institutions face significant challenges in detecting fraud due to the rarity and constantly evolving nature of fraudulent transactions. Additionally, the need to safeguard customer data privacy limits access to large, diverse datasets required for robust fraud detection.
- Synthetic Data Solution: A simulation model is developed to generate synthetic banking transaction data, including both normal and fraudulent scenarios (e.g., identity theft, unusual large transfers, money laundering patterns). This model leverages historical fraud patterns and other known behaviors to create realistic, yet entirely synthetic, transaction data. By doing so, machine learning models can be trained to detect subtle fraud signals without compromising real customer data.
- Results: Machine learning models trained on this synthetic dataset become adept at identifying fraudulent transactions with high precision, reducing false positives and enhancing the bank's ability to protect customer accounts, all while maintaining compliance with data privacy regulations.
Case 3. Healthcare diagnostics with synthetic medical imaging
Medical research and diagnostics training require large datasets of medical images, such as X-rays or MRI scans, which are limited due to patient privacy concerns and the rarity of certain conditions.
- Synthetic data solution: Implement a combination of deep learning techniques to generate synthetic medical images showcasing a wide range of conditions, including rare diseases, with variations in patient demographics. These images are annotated with accurate diagnostic information for training purposes.
- Results: Diagnostic models trained on this synthetic dataset show improved accuracy in detecting and diagnosing a wide range of conditions, including those not frequently observed in available real patient datasets. This leads to better patient outcomes through earlier and more accurate diagnoses.
Advantages of synthetic data
Synthetic data offers numerous benefits across various domains, from improving data privacy to enhancing machine learning model training. Here are some key advantages:
- Privacy and security
Synthetic data enables the use of realistic data sets without exposing real-world sensitive information, thus maintaining privacy and complying with data protection regulations like GDPR.
- Data accessibility
It provides access to data where real data might be scarce, expensive to collect, or subject to ethical concerns, particularly in fields like healthcare, finance, and social research.
- Bias reduction
By carefully generating synthetic data, it's possible to mitigate biases present in real-world datasets, leading to fairer and more equitable AI and machine learning models.
- Improved model training
Synthetic data can be used to train machine learning models where real data is insufficient, especially for rare events or scenarios, enhancing the models' robustness and accuracy.
- Testing and validation
It allows for the thorough testing of systems, software, and algorithms in a controlled but realistic environment, identifying potential issues before deployment with real-world data.
- Cost efficiency
Generating synthetic data can be more cost-effective than collecting and cleaning real-world data, especially when considering the costs associated with data privacy compliance and the potential risks of data breaches.
- Customizability
It offers the flexibility to create datasets with specific characteristics or conditions that might be difficult to capture with real data, allowing for targeted research and development efforts.
- Ethical use of data
It addresses ethical concerns associated with using real data, especially in sensitive fields, by providing an alternative that doesn't involve real individuals' data.
| # | Advantages | Disadvantages |
|---|---|---|
| 1 | Enhanced privacy and security | Accuracy and realism concerns |
| 2 | Accessibility of data | Potential for bias and misrepresentation |
| 3 | Bias reduction | Ethical and legal considerations |
| 4 | Improved model training | Complexity and resource requirements |
| 5 | Testing and validation machine learning models | Verification and validation challenges |
| 6 | Cost efficiency | Generalization issues |
| 7 | Customizability | Dependency on quality of input data |
| 8 | Ethical use of data | Public perception and trust Issues |
Challenges and limitations
While synthetic data presents numerous advantages, it also comes with its own set of challenges and limitations that must be carefully navigated. These include:
- Accuracy and realism
One of the primary challenges is ensuring that synthetic data accurately reflects the complexity and nuances of real-world data. There's always a risk that synthetic datasets may oversimplify or fail to capture critical patterns and anomalies present in the original data, potentially leading to misleading analysis or model training outcomes.
- Bias and representation
Although synthetic data can help reduce bias, the algorithms used to generate it can inadvertently introduce new biases or perpetuate existing ones if not properly monitored and adjusted. Ensuring that synthetic data is representative of diverse populations and scenarios is crucial but challenging.
- Ethical and legal considerations
The generation and use of synthetic data, especially when derived from real individuals' data, raise ethical questions regarding consent, privacy, and the potential misuse of synthetic data. Additionally, the legal landscape around synthetic data is still evolving, with uncertainties about data rights and responsibilities.
- Complexity and resource requirements
Creating high-quality synthetic data often requires sophisticated algorithms and significant computational resources. The development and maintenance of these systems can be complex and costly, potentially limiting access for smaller organizations or individual researchers.
- Verification and validation
Verifying that synthetic data is a valid substitute for real data involves comprehensive testing and validation. This process can be time-consuming and requires expertise to ensure that the synthetic data maintains the integrity of the original data's statistical properties.
- Generalization
There's a risk that models trained on synthetic data may not perform well on real data due to overfitting or underestimation of real-world variability. Ensuring that synthetic data leads to models that generalize well to new, unseen data is a significant challenge.
- Data dependency
The quality of synthetic data is heavily dependent on the quality of the input data or the assumptions made during its generation. Poor quality or inaccurate input data can lead to synthetic data that is misleading or of limited utility.
- Public perception and trust
There may be skepticism or lack of trust in synthetic data and the models trained on it, especially in critical applications like healthcare and public policy. Building trust in synthetic data's reliability and ethical use is essential but can be challenging.
Synthetic Data and Privacy
Privacy is one of the foremost reasons organizations adopt synthetic data, especially when working with sensitive information:
- Privacy-Preserving Synthetic Data: By generating data that mimics real-world patterns without directly copying actual data, synthetic data ensures that individual identities remain protected. In healthcare, for example, synthetic data can be used to simulate patient records for medical research without violating HIPAA (Health Insurance Portability and Accountability Act) compliance.
- Differential Privacy Techniques: Some synthetic data generation processes incorporate differential privacy, a technique that adds "noise" to data to prevent reverse-engineering of individual information. This ensures that data remains statistically useful while safeguarding personal information.
- Legal Compliance: Synthetic data helps organizations adhere to data privacy laws, including GDPR in the EU and CCPA in California. By using synthetic data, companies can reduce the risk of data breaches and fines related to non-compliance.
Ethical and Regulatory Considerations
The rise of synthetic data has led to a need for ethical standards and regulatory oversight to prevent misuse and maintain transparency:
- Avoiding Bias and Discrimination: Poorly generated synthetic data can inherit biases from original datasets, leading to models that reinforce unfair patterns. For instance, a model trained on synthetic HR data that contains gender or racial biases could result in discriminatory hiring practices.
- Transparency and Explainability: Synthetic data should be transparent to users, with clear information on how it was generated and how closely it resembles real data. This is particularly important in regulated industries like finance and healthcare, where explainability and trust are essential.
- Regulatory Compliance: Regulatory bodies worldwide are beginning to recognize the importance of synthetic data. New guidelines, such as those from the European Data Protection Supervisor (EDPS), outline best practices for generating synthetic data that protects privacy while ensuring statistical accuracy.
- Ownership and Accountability: Ethical questions arise around ownership and accountability, such as who owns the design of synthetic data when it didn’t exist before, and who is responsible in the event of misuse or errors.
Conclusion
Synthetic data is rapidly becoming a cornerstone of modern ML and AI applications. By offering an effective solution to data scarcity, privacy concerns, and ethical issues, synthetic data is empowering organizations to advance their models and technologies more safely and effectively. From healthcare to autonomous driving, synthetic data is reshaping the ML landscape, enabling faster innovation and more ethical data usage.
As technology and techniques continue to evolve, synthetic data is poised to become a standard tool for data scientists, especially in privacy-sensitive fields. Its role in future AI developments—whether through improved generative models, digital twins, or new regulatory frameworks—will be fundamental, driving progress and setting new standards for ethical data practices.