Image segmentation is a core task in computer vision that involves dividing an image into multiple segments or regions, typically to simplify its analysis. The goal is to label pixels of similar characteristics together, making it easier to analyze objects or areas within the image. These segmented regions often represent different objects, boundaries, or elements that are crucial for object recognition, detection, and further tasks in machine learning models.
The types of image segmentation can be broadly classified into semantic segmentation, instance segmentation, and panoptic segmentation.
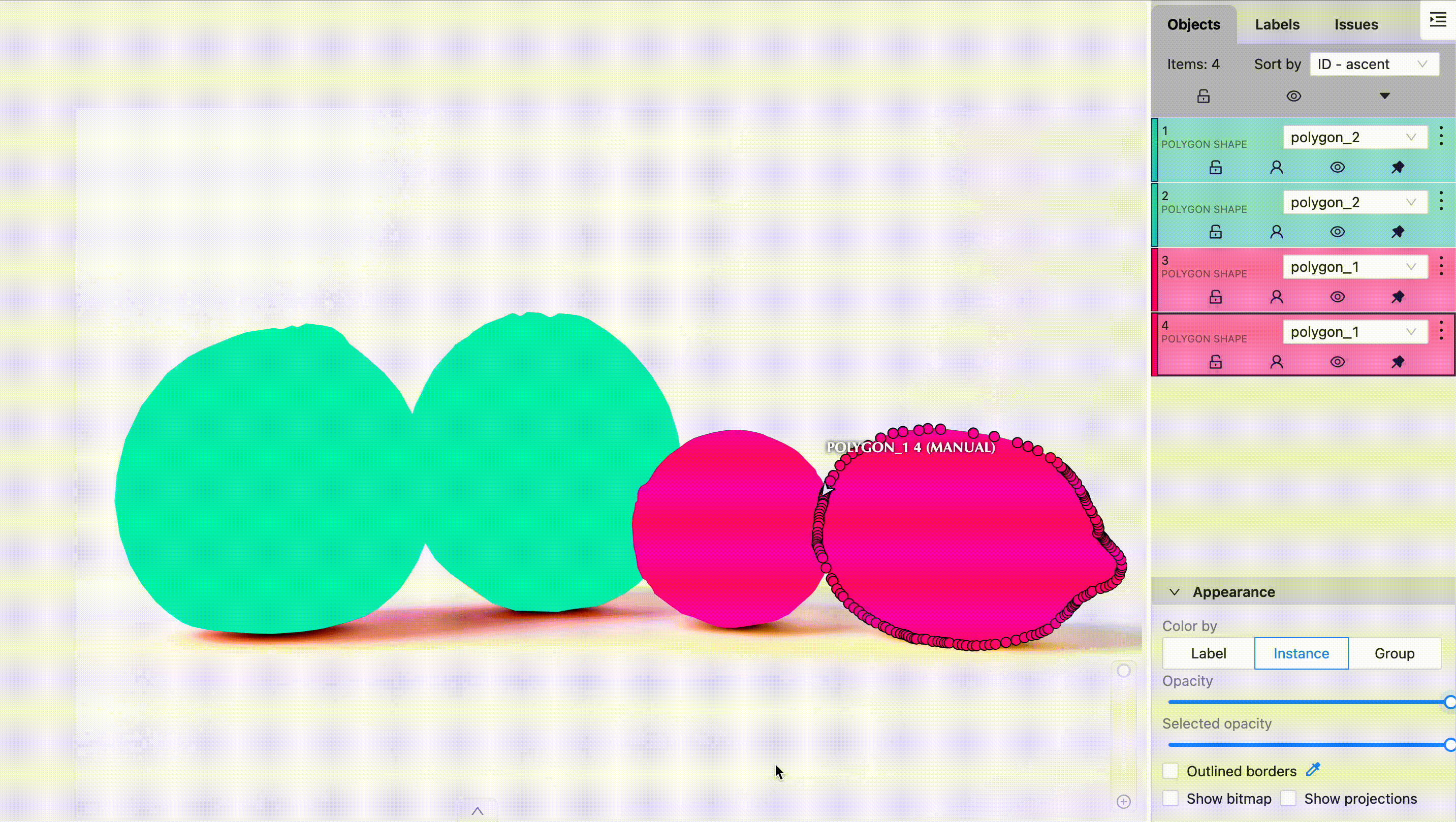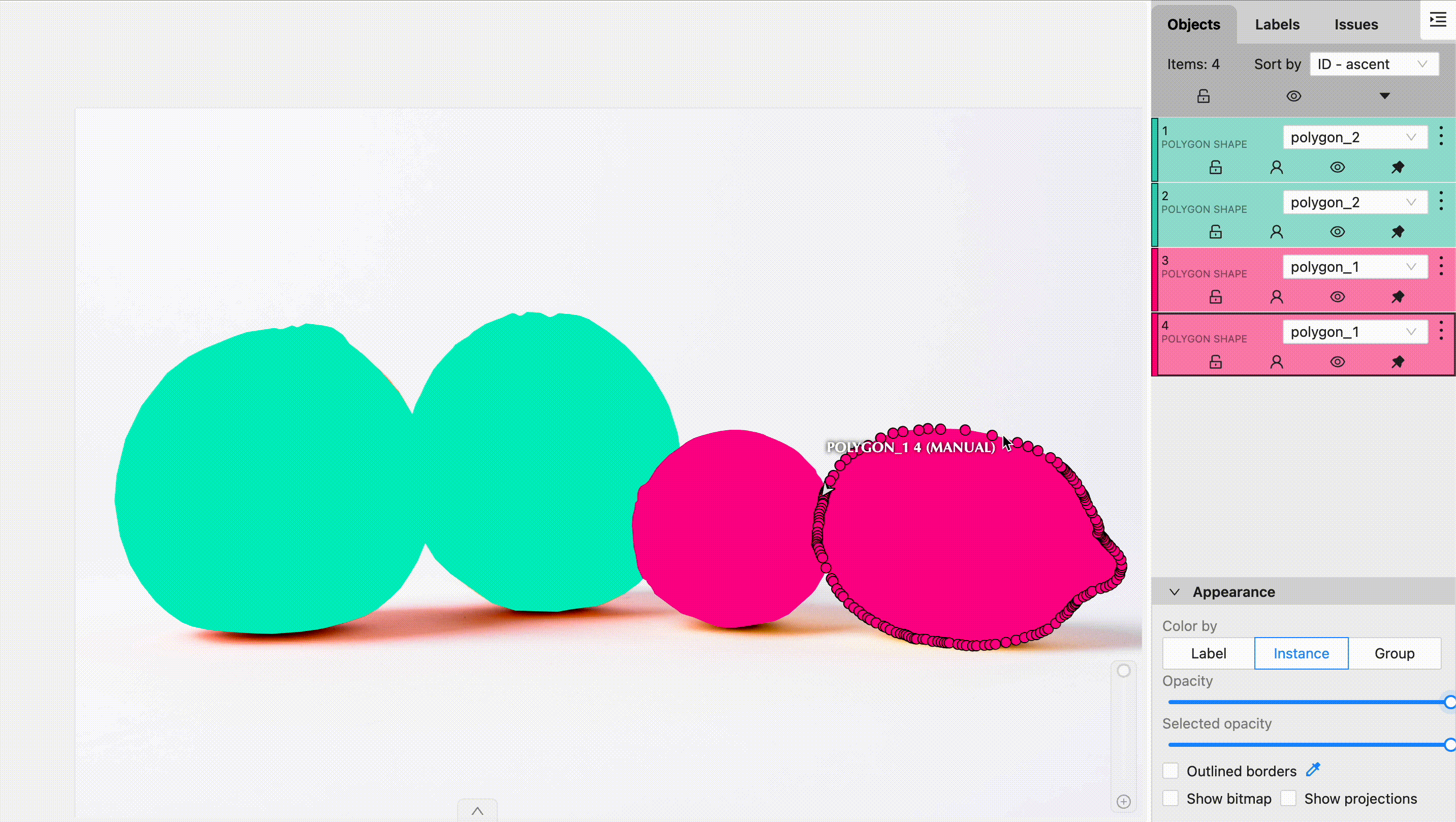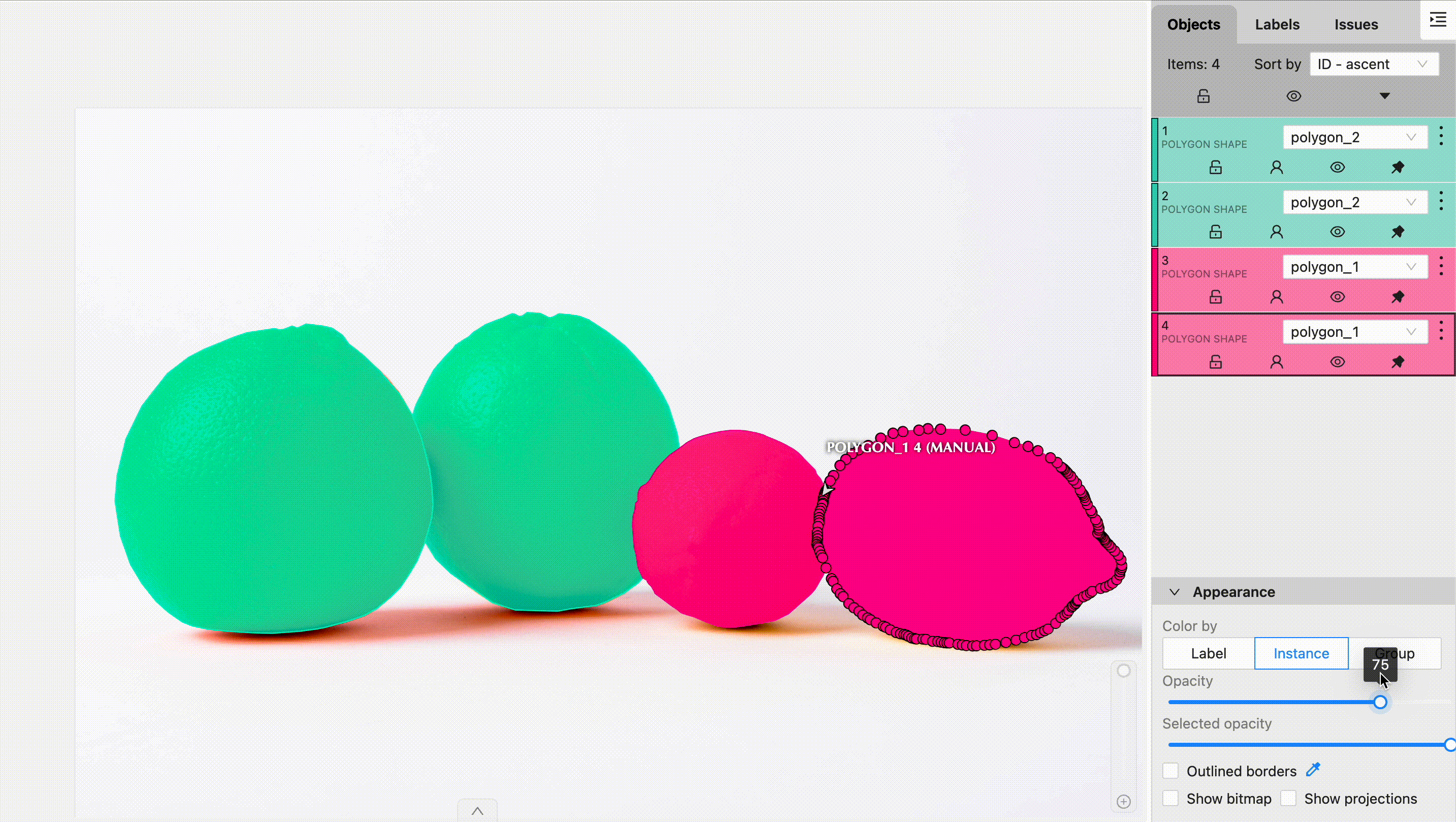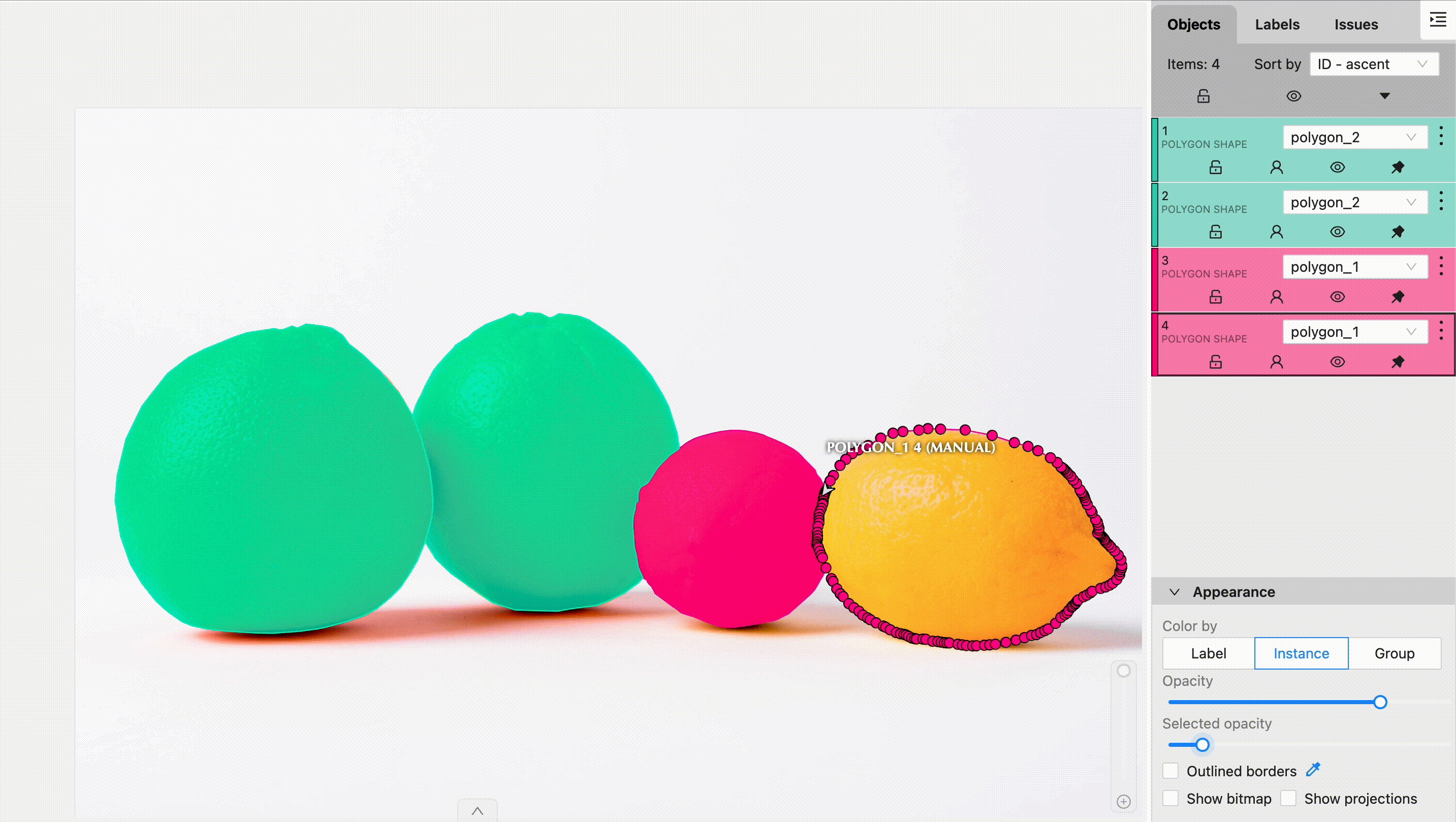
What is Semantic Segmentation and Why is it Important?
Semantic segmentation is a type of image segmentation where each pixel in an image is classified into a predefined class. Unlike object detection, which places bounding boxes around objects, semantic segmentation performs pixel-level classification. This means that it labels every pixel in an image as belonging to a particular class (e.g., road, car, tree).

Why is Semantic Segmentation Important?
Semantic segmentation plays a crucial role in tasks requiring an in-depth understanding of an image’s context. Its importance lies in applications like autonomous driving, where it helps identify objects like pedestrians, road signs, and vehicles with high accuracy.
Similarly, in medical imaging, semantic segmentation enables precise identification of different organs or anomalies like tumors.
Without pixel-level understanding, these systems would lack the resolution needed to operate reliably in real-world scenarios.
Semantic Segmentation vs. Object Detection
Object detection involves detecting objects in an image by placing a bounding box around them and classifying the box as belonging to a certain category. While effective in identifying object locations, object detection doesn't offer precise boundary-level details about objects.
- Key difference: Object detection works at the bounding box level, while semantic segmentation works at the pixel level.
- Use case: In autonomous vehicles, object detection might be used to locate other cars, while semantic segmentation provides more granular detail, such as classifying every pixel of the road, sidewalks, and vehicles for more accurate navigation.


Semantic Segmentation vs. Instance Segmentation
Instance segmentation goes one step further than semantic segmentation by not only classifying each pixel but also distinguishing between multiple instances of the same object class. For example, in an image of a street with several cars, instance segmentation would classify all pixels belonging to cars and further differentiate each car as a separate instance.
- Key difference: While semantic segmentation labels every pixel with a class, instance segmentation distinguishes between different instances of the same class.
- Use case: In medical imaging, semantic segmentation may label all tumors in an image as "tumor" while instance segmentation could differentiate between multiple tumors.
Semantic Segmentation vs. Panoptic Segmentation
Panoptic segmentation is typically used in scenarios that require both class-level and instance-level differentiation, such as autonomous driving, aerial photography, or robotics. It integrates semantic segmentation (labeling object classes like roads, trees, etc.) with instance segmentation (differentiating individual objects like specific cars or buildings). In contrast, instance segmentation alone is often applied in tasks where identifying and distinguishing individual objects is critical, such as object detection in retail or inventory management.
Spheres of Use for Semantic Segmentation
- Robotics: Used for navigation where robots need to understand general object categories like obstacles or pathways.
- Satellite and Aerial Imagery: Labeling large geographic features such as forests, rivers, or urban areas for environmental monitoring.
- Agriculture: Identifying different types of crops, soil types, or pest-affected areas in fields.
- Autonomous Driving: Used to label road elements such as lanes, sidewalks, and traffic signs.
Spheres of Use for Panoptic Segmentation
- Urban Planning (Aerial Photography): Identifying and labeling roads, buildings, and vehicles while distinguishing individual cars or structures.
- Retail Analytics: Detecting and counting individual products on shelves while also understanding the general layout of shelves and aisles.
- Surveillance and Security: Identifying people or objects of interest (e.g., multiple individuals in a crowd) while also classifying objects like bags, vehicles, or weapons.

Image Segmentation for Retail Applications
- E-commerce and Retail
-
1,000 high-resolution annotated images
30+ object classes per image - 6 weeks
Popular Models for Semantic Segmentation
Several models have been developed for high-performance semantic segmentation tasks. Here’s a brief overview of some widely used models:
| Model | Description |
|---|---|
| FCN (Fully Convolutional Networks) | One of the earliest models used for semantic segmentation, replaces fully connected layers with convolutional ones. |
| U-Net | Popular for biomedical image segmentation; employs skip connections for better localization accuracy. |
| DeepLab | Known for its atrous convolution layers, which allow for a larger receptive field without losing spatial resolution. |
| Mask R-CNN | Though primarily used for instance segmentation, Mask R-CNN can be adapted for semantic segmentation tasks. |
| SegNet | Employs an encoder-decoder architecture, which is efficient for tasks requiring pixel-level predictions. |
Annotation Methods for Semantic Segmentation
Annotating data for semantic segmentation involves labeling every pixel in an image, which can be a complex and time-consuming task. The annotation process can be manual, automated, or a combination of both:
Manual Annotation:
Human annotators manually label every pixel in the image according to a predefined class. This is highly accurate but labor-intensive and time-consuming.
Automated Annotation:
Automated tools use algorithms to predict the segmentation mask. These tools are faster but often need refinement, especially for complex or noisy images.
Human-in-the-Loop Annotation:
A combination of automated methods with human oversight, where the model makes initial predictions and human annotators refine the output. This hybrid method is more efficient than purely manual annotation and more accurate than automated approaches alone.
The difference between manual, automated, and human-in-the-loop (HITL) annotation approaches is influenced by several key factors:
- Budget: Manual annotation typically requires more human resources, making it more costly, while automated approaches can reduce costs but may require significant initial investment in AI development. HITL strikes a balance by using automation with human oversight, offering cost-efficiency depending on the level of human intervention needed.
- Model Maturity: Automated annotation is more effective when the model is well-trained and capable of producing high-quality results. In contrast, manual annotation is often necessary when the model is in its early stages or for complex tasks. HITL is useful when the model needs human correction or guidance to improve its predictions.
- Workload Volume: Large-scale datasets may favor automated or HITL approaches to handle the volume efficiently, while smaller or more intricate datasets may rely on manual annotation for higher precision. HITL can be especially beneficial when the workload is large but still requires periodic human input for quality control.
These factors determine which annotation approach is most suitable for a given project.
Steps of Manual Annotation for Semantic Segmentation
Manual annotation of semantic segmentation is highly detailed and requires expert-level precision. Here are the steps involved:
- Data Preparation: Organize the images into a format suitable for annotation. Ensure that the dataset contains a variety of objects, backgrounds, and lighting conditions.
- Class Definition: Define the set of classes (e.g., sky, car, road) for labeling each pixel.
- Annotation Tools: Use specialized software tools that allow pixel-level drawing, polygon annotations, or paintbrush-style tools.
- Drawing Masks: Annotators carefully outline each object within the image, ensuring accurate pixel-level labeling for each class.
- Quality Assurance: After the initial annotation, a QA process is implemented, where annotators or supervisors review the labels for accuracy and consistency across the dataset.
- Refinement: If necessary, correct any mistakes or inconsistencies, ensuring high-quality labels.
Use Cases for Semantic Segmentation
Semantic segmentation has a wide range of real-world applications across various industries such as Autonomous Driving, Photography and Media, Medical Imaging, Agriculture, and more.
Here are some of the Unidata Cases of Manual Annotation for Semantic Segmentation:
Human Segmentation from Background (Webcam Scenario)
Use Case: Separating a person from the background in webcam footage using CVAT, where the person is labeled with one color and the background with another.
Task: Annotators had to create clear polygonal outlines around the person in each image, focusing on fine details like hair strands, especially for women, where gaps between hair strands made it challenging. The goal was to capture the maximum possible contour in 2 iterations over 10,000 images each. There were 2 classes of annotation: person and 0 class for the background.
Complexity: Handling small gaps in hair and ensuring precise boundary segmentation.
Solution: Our tech team developed an automated solution for annotating areas between hair by creating a script that detects hair gaps in the background as a third class. By combining this automated process with manual annotation, we achieved highly accurate results that satisfied the client, leading to the project's successful completion.
Urban Street Segmentation for Delivery Robots
Use Case: Full segmentation of urban street images, including buildings, trees, roads, etc., for use in autonomous delivery robots.
Task: The task required annotators to label all visible objects in the images with precision, often involving hundreds of classes.
Complexity: The project was resource-intensive due to the large number of objects and high accuracy requirements. The platform sometimes experienced overloads due to the complexity of the task, and annotators required specialized knowledge for accurate labeling.
Challenges: Handling system performance issues, requiring specialized hardware, high image quality, and managing over 100 classes for semantic segmentation.
MMA Fight Segmentation (Cage Environment)
Use Case: Full segmentation of MMA fights, including annotating the cage, fighters, referee, and other elements.
Task: Annotators needed to carefully segment all components within the scene, including complex elements like cage structures and human figures, requiring high attention to detail.
Challenges: A significant challenge in the MMA fight segmentation project was dealing with changes in technical specifications after the pilot phase. This required flexibility and efficient communication to ensure the project stayed on track while maintaining accuracy and meeting the client's evolving needs.
Topographic Map Annotation
Use Case: Annotating topographic map images using new software, with approximately 10 classes defined by the client.
Task: The task involved manually segmenting large topographic maps into different classes (e.g., land types, and water bodies) based on instructions provided by the client.
Complexity: Learning the new software from scratch. The map data files were very large, requiring them to be split into smaller parts to distribute the workload among more annotators. After annotation, these smaller parts had to be merged back together, adding complexity to the task.
An additional challenge was the lack of ability to track annotators’ progress online, which complicated oversight and project management.
Solution: Despite these challenges, the client offered several features that helped reduce errors and allowed for easy corrections, which were crucial for ensuring high-quality segmentation. However, the team had to invest significant effort in self-learning and troubleshooting to utilize these tools effectively.
Conclusion
Semantic segmentation is a fundamental component in advancing machine learning and computer vision applications. Its ability to provide pixel-level classification makes it critical for industries like healthcare, autonomous driving, and agriculture, where a fine-grained understanding of an image is essential. The future of semantic segmentation includes more sophisticated models, improved annotation methods, and more efficient computation, making it a continuously evolving field with immense potential.
Frequently Asked Questions (FAQ)
Semantic segmentation is a type of image segmentation where every single pixel in an image is classified into a predefined category — such as “road,” “car,” “tree,” or “pedestrian.” Unlike object detection, which draws bounding boxes around objects, semantic segmentation provides pixel-level understanding of an entire scene. All pixels belonging to the same object class receive the same label, regardless of how many instances of that object are present.
Object detection works at the bounding box level — it identifies where objects are and draws rectangles around them, but says nothing about the exact shape or boundary. Semantic segmentation works at the pixel level — every pixel in the image is classified, providing precise boundary information. In autonomous driving, for example, object detection locates other vehicles, while semantic segmentation classifies every pixel of roads, sidewalks, lanes, and signs for more accurate navigation.
Both techniques classify every pixel, but with an important distinction. Semantic segmentation assigns the same label to all pixels of the same category — all cars in a scene are simply labeled “car.” Instance segmentation goes further by differentiating between individual objects of the same class — Car 1, Car 2, Pedestrian 1, etc. In medical imaging, semantic segmentation labels all tumors as “tumor,” while instance segmentation identifies each tumor as a separate entity.
The most widely used models include:
- FCN (Fully Convolutional Networks) — one of the earliest pixel-wise classification approaches;
- U-Net — popular in biomedical imaging for its encoder-decoder architecture and precise localization;
- DeepLab — uses atrous (dilated) convolutions to capture large context without losing spatial resolution;
- SegNet — efficient encoder-decoder model suited for pixel-level prediction tasks;
- Mask R-CNN — primarily for instance segmentation but adaptable for semantic tasks.
Annotation for semantic segmentation requires labeling every pixel in an image, which can be done via three approaches:
- Manual annotation — human annotators outline objects with high accuracy but it is time-intensive.
- Automated annotation — algorithms predict segmentation masks faster but often require refinement.
- Human-in-the-loop (HITL) — AI makes initial predictions and humans correct errors, balancing efficiency and accuracy. The right approach depends on budget, dataset size, and required precision.
Manual semantic segmentation annotation follows six key steps:
- data preparation — organizing images in a variety of scenes and conditions;
- class definition — establishing the set of labels (e.g., sky, road, person);
- tool selection — using software with pixel-level drawing or polygon tools;
- drawing masks — annotators carefully outline each object at the pixel level;
- quality assurance — reviewing labels for accuracy and consistency;
- refinement — correcting any errors before finalizing the dataset.