
Imagine training an AI on a Shakespearean dataset but asking it to interpret Gen Z slang on Twitter. It’s going to fail—miserably. That’s why picking the right NLP dataset matters. Whether you’re building a chatbot, sentiment analyzer, or machine translation model, using a high-quality dataset is the first step toward creating an NLP system that doesn’t sound stuck in 2005.
This guide explores some of the best NLP datasets across various categories, from must-haves for any AI researcher to a few unexpected, fun datasets that could make your project stand out.

How to Pick the Right NLP Dataset?
Here’s what you should consider before diving headfirst into training:
1. Size Matters, But Not Always
Many assume that bigger is always better when it comes to datasets. While having millions of text samples can boost model performance, size alone won’t save a dataset if it’s full of junk.
When bigger is better: Tasks like machine translation, language modeling, and speech recognition thrive on large datasets, as more examples help the model learn patterns better.
When smaller is smarter: If the dataset is highly specialized (e.g., legal or medical text), a smaller but high-quality dataset annotated by experts will outperform a giant, loosely curated dataset.Pro tip: Always check how well-balanced the dataset is. If it’s 90% one category and 10% another, your model is going to be biased.
Pro tip: Always check how well-balanced the dataset is. If it’s 90% one category and 10% another, your model is going to be biased.
2. Task-Specific Focus: One Size Doesn’t Fit All
Not all NLP tasks are the same, and neither are the datasets designed for them. A dataset meant for sentiment analysis (where you classify whether text expresses positive, neutral, or negative sentiment) isn’t useful for named entity recognition (NER), which focuses on tagging entities like people, places, and brands.
3. Data Diversity: Avoiding a Narrow-Minded AI
Language isn’t static—it evolves. If your dataset is too one-dimensional, your model will struggle when faced with text outside its comfort zone. Imagine training an AI on formal news articles and then expecting it to understand TikTok comments. It won’t get it.
A real-world example? Google's BERT model was initially trained on Wikipedia and BooksCorpus. But when adapted for conversational AI, they had to use a more diverse dataset—including forum discussions and Q&A platforms—so it wouldn’t sound overly formal in casual conversations.
4. Annotation Quality: Garbage In, Garbage Out
Poorly labeled data = bad models. Sentiment mislabeled? Named entities inconsistent? That’s a fast track to flawed AI. Opt for human-annotated datasets with clear documentation (e.g., SQuAD for Q&A models).
Essential NLP Datasets by Category
Here’s a mix of gold-standard, widely used datasets and some fun, unique ones that could add extra creativity to your NLP projects.
Text Classification
With over 8.5 million reviews of 160,000 businesses, this dataset offers rich insights into customer sentiments and business reputations across various industries.
This dataset comprises over 1 million news articles categorized into four classes: World, Sports, Business, and Sci/Tech. It's widely used for training models in topic classification and information retrieval.
Containing 50,000 movie reviews labeled as positive or negative, this dataset is a staple for sentiment analysis tasks, helping models understand nuanced opinions in text.
Named Entity Recognition (NER)
This benchmark dataset contains annotated text for NER tasks, focusing on entities like persons, locations, organizations, and miscellaneous names, making it foundational for entity extraction research.
Offering a large-scale corpus with diverse annotations, including NER, coreference resolution, and word sense disambiguation, this dataset supports comprehensive language understanding models.
This data could be useful for NER tasks and services.
Question Answering
SQuAD provides over 100,000 question-answer pairs derived from Wikipedia articles, challenging models to comprehend and extract precise information from passages.
Developed by Google, NQ includes real user queries and corresponding Wikipedia pages, reflecting genuine information-seeking behavior and enhancing open-domain QA systems.
Text Summarization
This dataset consists of news articles paired with multi-sentence summaries, serving as a standard benchmark for abstractive and extractive summarization techniques.
Containing around 10 million news articles, Gigaword is used for developing models that generate concise summaries from longer texts, aiding in information condensation.
Text Generation

Comprising over 11,000 unpublished books, this dataset is utilized to train models in generating coherent and contextually relevant text, contributing to advancements in language modeling.
Sentiment Analysis
With millions of product reviews across various categories, this dataset helps models learn to discern sentiments and opinions expressed by consumers.
Containing 1.6 million tweets labeled for sentiment, this dataset captures the informal and concise nature of social media language, posing unique challenges for sentiment analysis.
Paraphrase Identification
MRPC includes sentence pairs with human annotations indicating whether they are semantically equivalent, aiding in the development of models that recognize paraphrases.
This dataset contains over 400,000 question pairs from Quora, labeled to indicate if they have the same intent, supporting the development of duplicate question detection systems.
Dialogue Systems
Developed by Google, Taskmaster-1 consists of over 13,000 task-based dialogues across six domains, including ordering food and making reservations. This chatbot dataset captures natural conversations, both written and spoken, providing rich material for training dialogue systems.
This dataset includes dialogues where each participant is assigned a persona, consisting of a few sentences describing characteristics. It encourages the development of models that can generate more engaging and personalized responses by considering the persona information.
Featuring multi-turn dialogues from Ubuntu chat logs, this dataset is instrumental in training models for technical support and troubleshooting conversations.
Commonsense Reasoning
SWAG presents multiple-choice questions about everyday situations, challenging models to apply commonsense reasoning to select the most plausible continuation.
This dataset tests pronoun resolution in ambiguous sentences, serving as a benchmark for evaluating a model's understanding of commonsense reasoning.
Reading Comprehension
RACE consists of English exam questions from Chinese students, providing a challenging dataset for evaluating reading comprehension and reasoning abilities.en.wikipedia.org

This multiple-choice reading comprehension dataset is designed to test a model's ability to understand and reason about stories, with questions requiring inference and synthesis.
Coreference Resolution
A large-scale dataset focused on coreference resolution, PreCo offers rich annotations that help models learn to identify and link co-referring expressions in text.
Semantic Role Labeling
PropBank adds a layer of predicate-argument information to the Penn Treebank, aiding models in understanding the roles played by various sentence constituents, crucial for semantic parsing.
FrameNet provides a lexicon of semantic frames, offering examples and annotations that help models grasp the relationships between words and their meanings in context.
Speech Recognition

Derived from audiobooks, LibriSpeech offers approximately 1,000 hours of speech data, serving as a valuable resource for training and evaluating speech recognition systems.
An initiative by Mozilla, Common Voice is a crowdsourced project that has amassed thousands of hours of speech data in over 100 languages. This dataset is instrumental in training and improving speech recognition systems, especially for underrepresented languages.en.wikipedia.org
This dataset comprises approximately 2,400 two-sided telephone conversations among 543 speakers from across the United States, totaling around 260 hours of speech. It has been pivotal in advancing research in conversational speech recognition.
Speech Synthesis
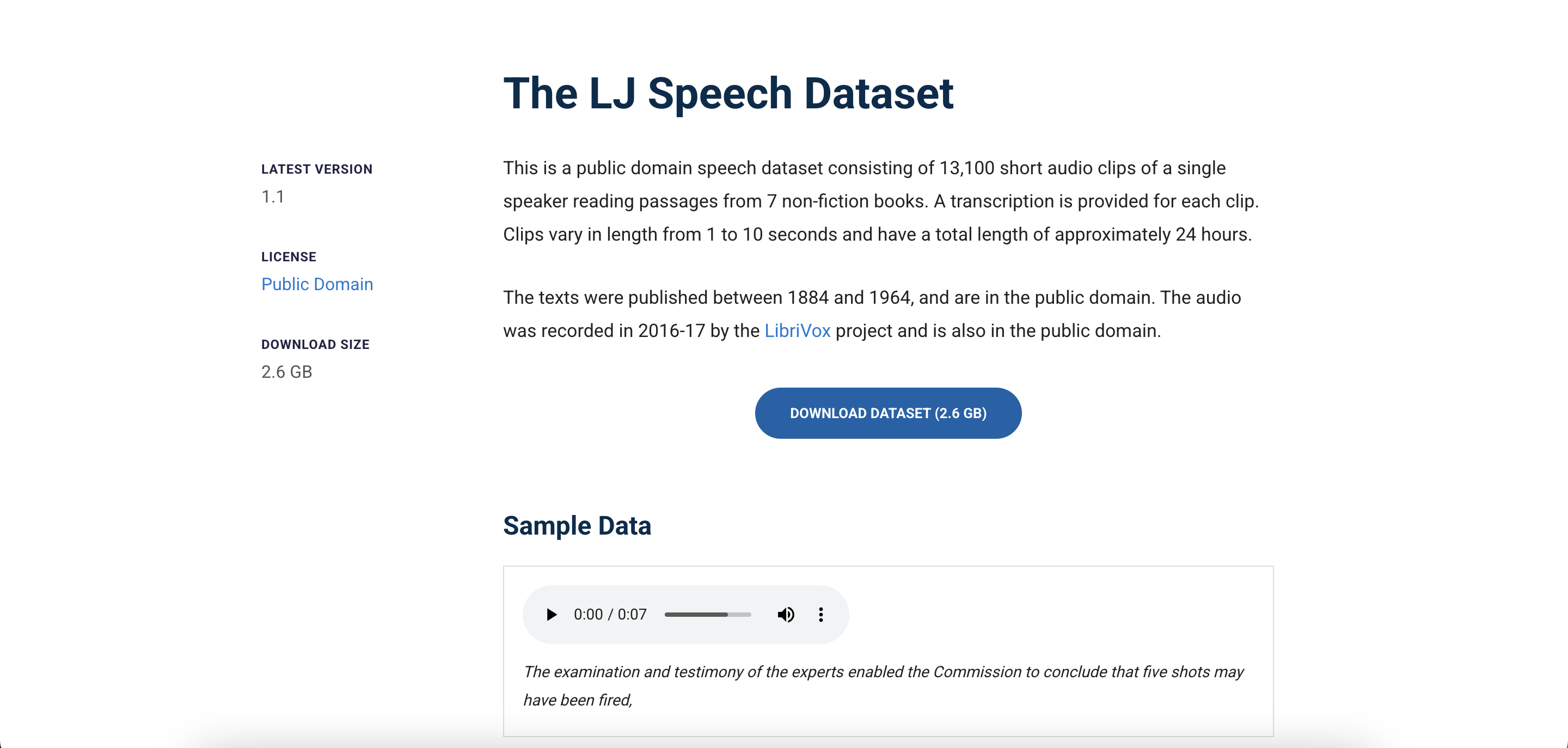
A single-speaker corpus of English audiobook recordings, the LJSpeech Dataset contains 13,100 short audio clips of a female speaker reading passages from 7 non-fiction books. It's widely used for training text-to-speech systems.twine.net
This dataset provides about 300 hours of English speech data from a single speaker, along with corresponding texts. It's used in the Blizzard Challenge, which evaluates the performance of speech synthesis systems.
Emotion Recognition
This dataset contains approximately 12 hours of audiovisual data, including speech and facial expressions, from scripted and improvised scenarios. It's widely used for research in emotion recognition and affective computing.
Comprising over 110,000 video clips annotated with 26 emotion labels, this dataset is used to study emotional reactions in children and is valuable for developing models that understand and predict human emotions.
Speaker Recognition
Containing over 100,000 utterances from 1,251 celebrities, VoxCeleb1 is used for speaker identification and verification tasks. The dataset includes a wide range of accents and recording conditions, making it ideal for robust speaker recognition models.
These datasets, collected over multiple years, are designed to support the development and evaluation of speaker recognition technologies. They include conversational telephone speech and are widely used benchmarks in the field.
Conclusion
Selecting the appropriate dataset is a critical step in developing effective NLP models. By understanding the unique characteristics and applications of each dataset, practitioners can tailor their models to specific tasks and domains, leading to more accurate and reliable outcomes. As the NLP field continues to evolve, staying informed about emerging datasets and their potential applications will be essential for advancing research and industry practices.










