

In the vast world of machine learning (ML), the quality of your dataset is like the foundation of a skyscraper—get it wrong, and everything above it risks crumbling. A well-crafted dataset is not only crucial for building accurate models but also for ensuring their real-world applicability.
Let’s dive into the step-by-step process of dataset preparation that can set your ML project up for success.
Why Is a Good Dataset Important?
Imagine you’re trying to teach a toddler how to differentiate between cats and dogs. If your examples are blurry images of animals or stuffed toys instead of real pets, the toddler’s understanding will be incomplete or misleading. Similarly, a machine learning model needs high-quality, relevant, and diverse data to learn effectively. Here’s why:
- Accuracy: High-quality data improves model predictions.
- Bias Mitigation: Properly curated data reduces the risk of biases.
- Real-World Relevance: Diverse datasets ensure applicability across scenarios.
The 80/20 Rule: Did you know? Data scientists spend 80% of their time cleaning and preparing data, with only 20% left for actual modeling. This emphasizes how crucial the dataset foundation is.
Step 1: Define Your Problem and Goals
A great dataset starts with a clear understanding of the problem you're trying to solve. Ask yourself:
- What’s the objective? Are you predicting house prices, detecting spam emails, or something else?
- What kind of output do you need?
- Classification: Sorting data into predefined categories (e.g., spam vs. not spam).
- Regression: Predicting continuous values (e.g., stock prices, temperature trends).
- Clustering: Grouping similar data points (e.g., customer segmentation).
- Ranking: Ordering items by priority (e.g., search engine results).
- Who will use the model? Understanding your target audience helps ensure the dataset meets their needs.
Clearly defining these elements creates a roadmap for what data to collect and how to process it.
By clearly outlining these goals, you create a roadmap that informs the type of data you’ll need and the methods you’ll use to process it.
Step 2: Determine Data Requirements
Once you've clearly defined the problem, the next important step is to determine your data requirements. This involves breaking down what’s needed to train and validate your model effectively. Here are the key components to consider:
- Features: These are the input variables or characteristics that your model will analyze. For instance, if you're predicting house prices, features could include location, square footage, and the number of bedrooms.
- Labels: For supervised learning tasks, labels represent the target output. In the case of house prices, the label would be the price itself for regression tasks.
- Data Volume: It’s essential to determine how much data is needed for training and validation. Generally, more complex problems require larger datasets, but remember that quality should always outweigh quantity.
By addressing these considerations, you can make sure your dataset is aligned with the objectives of your machine learning project, while avoiding unnecessary complexities and ensuring robust model performance.
Step 3: Data Collection
3.1 Sources of Data
Data can come from various sources, each with its pros and cons:
- Existing Datasets: Public repositories like Kaggle, UCI Machine Learning Repository, Google Dataset Search, and Hugging Face Datasets offer ready-made datasets for different applications. Here’s a quick comparison:
| Repository | Ease of Use | Types of Datasets | Licensing |
|---|---|---|---|
 | High | Diverse (images, text, etc.) | Varies |
 | Moderate | Classic datasets for ML | Open |
 | High | Aggregated global datasets | Varies |
 | High | NLP-focused datasets | Open/Custom |
Each platform offers unique strengths. For instance, Kaggle often has active communities sharing insights and kernels.
- Crawling and Web Scraping: Use tools like Beautiful Soup and Scrapy to extract data from websites. For example, scraping IMDb for movie titles and reviews can help create a recommendation dataset. Ensure you respect website terms of service and comply with legal and ethical standards.

Crawling involves systematic navigation through websites to gather information. Tools like Scrapy enable automated crawling and scraping for hierarchical structures, such as e-commerce product categories or blog networks.
- APIs: Platforms like Twitter or OpenWeather provide structured data for collection. For example, you can use the Twitter API to gather sentiment data.
- Surveys and User Input: Tailored insights can come directly from your audience, though this requires careful design and incentivization.
- Third-party Data Providers: These companies specialize in aggregating, cleaning, and structuring datasets from various sources.
- Sensors and IoT Devices: For applications like predicting traffic patterns, sensors and IoT devices provide valuable real-time data.
- Research Papers: Extracting data or methodologies from academic research can provide valuable insights for niche problems.
3.2 Challenges in Data Collection
When it comes to data collection, there are several challenges to consider.
Incomplete data is one of the most common issues, where missing values can undermine the reliability of your models. These gaps can cause inconsistencies and make it difficult to draw accurate conclusions.
Another challenge is dealing with unstructured data, such as raw text, images, or videos. These types of data often require significant preprocessing to be useful in analysis or modeling.
Lastly, legal and ethical issues are crucial in ensuring that data collection is done responsibly. It's essential to comply with data privacy regulations, like GDPR or HIPAA, to protect sensitive information and avoid legal complications.
Step 4: Data Cleaning and Preprocessing
This step is where the magic happens. Even the best raw data needs refining. Think of it like polishing a diamond—necessary to reveal its true value. It is essential to remove noise and inconsistencies to make the data ready for effective model training.
4.1 Handle Missing Data
Missing data can arise for various reasons, such as user non-response, faulty sensors, or incomplete data collection. Addressing these gaps is crucial:
- Imputation: Replace missing values with the mean, median, or mode for numerical data. For categorical data, consider using the most frequent category or even predictive models like k-NN imputation.
- Removal: If the missing data is extensive and cannot be reliably imputed, omit rows or columns. However, ensure the dataset remains representative of the problem space.
Tip: Advanced methods like matrix factorization or deep learning-based imputers (e.g., autoencoders) can handle complex missing data patterns effectively.
45% of real-world datasets contain gaps. A robust handling strategy ensures your model doesn’t falter due to these voids.
4.2 Remove Duplicates
Duplicates can arise due to repeated data entries or merging datasets. Detect and remove them using tools like Pandas’ drop_duplicates() function in Python. Always validate removal to ensure no critical data points are lost.
Example: For text data, deduplication can involve semantic similarity checks using tools like spaCy or Sentence Transformers.
4.3 Normalize and Standardize Data
Machine learning algorithms often assume numerical features follow specific distributions. Rescaling ensures algorithms converge effectively:
- Normalization: Rescales values to a [0, 1] range or [-1, 1] for certain algorithms. This approach is particularly useful for distance-based models like k-NN or k-Means.
- Standardization: Centers data around a mean of 0 with a standard deviation of 1. This method benefits algorithms sensitive to feature scaling, such as Support Vector Machines (SVM) or Principal Component Analysis (PCA).
Tip: Use libraries like Scikit-learn for robust scaling techniques. For example, MinMaxScaler handles normalization, while StandardScaler simplifies standardization.
4.4 Handle Outliers
Outliers can disproportionately influence certain models, leading to skewed results. Address them using:
- Detection: Boxplots, z-scores, or interquartile range (IQR) methods identify extreme values. For multivariate datasets, Mahalanobis distance works well.
- Treatment: Options include transformation (e.g., log scaling), capping to specific thresholds, or excluding outliers altogether.
A GPS dataset mistakenly placed the Leaning Tower of Pisa at various altitudes due to normalization errors, leading to absurd predictions. Always double-check preprocessing to avoid similar pitfalls.
Step 5: Annotate the Data
An annotation provides the ground truth for supervised machine learning tasks. High-quality labels are essential for effective model training.
Methods of Annotation
When it comes to labeling data, several methods are used, each offering its own set of benefits and challenges:
- Manual Annotation: This method involves having human experts directly label data points, which ensures a high level of accuracy. It's often regarded as the most reliable approach for mission-critical applications.
- Crowdsourcing: Platforms such as Amazon Mechanical Turk or Figure Eight enable the rapid scaling of annotation efforts by tapping into a broad, distributed workforce. While this can expedite the labeling process, it may occasionally lead to lower precision compared to expert-driven methods.
- Semi-Automatic Labeling: This approach integrates machine-generated labels with human verification to improve efficiency. Tools like SuperAnnotate and CVAT make this process more streamlined, combining the speed of algorithms with the oversight of human annotators to ensure accuracy.
- Automated Labeling: For large-scale datasets, fully automated labeling methods utilize machine learning models to apply labels to data. While this can dramatically reduce manual effort and accelerate workflows, it may not always match the precision of manual annotation, especially in complex contexts.
By strategically selecting and combining these methods, you can find the best approach that meets the specific needs of your project, balancing factors like accuracy, cost, and speed.
Challenges and Tips
Data annotation comes with its own set of challenges. One of the key issues is subjectivity, particularly for tasks like sentiment analysis, where individual interpretations can vary. To address this, it's crucial to establish clear labeling guidelines to minimize inconsistencies and ensure annotations are as objective as possible.
Another challenge is scalability—as your dataset expands, keeping up with the annotation process can be overwhelming. Tools like Prodigy help solve this by utilizing active learning, where the model suggests labels and humans correct them, making the process faster while maintaining accuracy.
A useful tip for larger projects is to log annotation decisions and track edge cases to ensure consistency and provide a reference for future decisions.
Step 6: Data Quality Control
Ensuring high-quality data is crucial not only for training accurate models but also for maintaining fairness and reliability. Poorly curated datasets can introduce biases, degrade model performance, and lead to unintended consequences in real-world applications.
Key Aspects of Data Quality Control
Maintaining consistency in data is essential to ensure reliability. This means making sure that all data follows expected formats and conventions, standardizing categorical variables and date formats, and validating consistency across different sources.
Another critical aspect is handling label noise, which can arise from mislabeling. Using statistical techniques or model-based anomaly detection can help identify errors, while active learning allows human annotators to review uncertain labels for better accuracy.
Bias detection and mitigation is equally important—examining data distributions helps identify imbalances that could lead to biased models, ensuring fairer and more accurate outcomes.
Step 7: Augment the Dataset
Data augmentation enriches datasets without additional data collection, especially for tasks like image recognition or NLP.
Techniques by Data Type
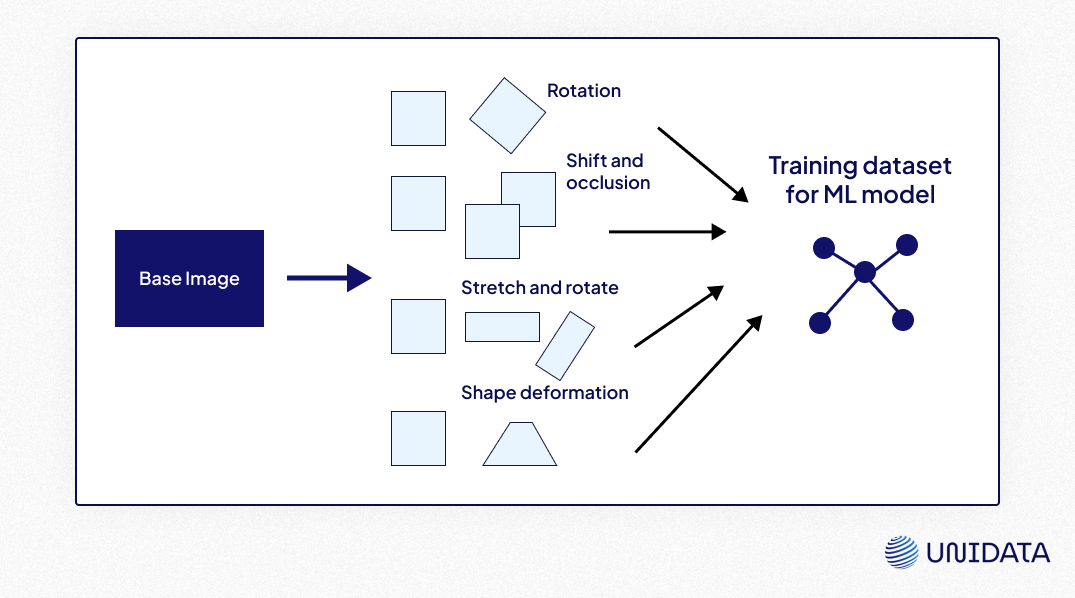
- Image Data:
- Apply transformations such as rotation, flipping, cropping, or color adjustments.
- Libraries like Albumentations or TensorFlow’s ImageDataGenerator simplify augmentation.
- Text Data:
- Use synonym replacement, back-translation, or random insertion of words.
- Tools like TextAugment can help.
- Time-Series Data:
- Introduce noise, apply scaling, or shift time frames.
- Libraries like tsaug offer specialized functions.
Benefits
Data augmentation offers several key benefits. It enhances model robustness by helping algorithms generalize better to real-world variations, reducing overfitting. It also improves cost efficiency, as generating augmented data is far more affordable than collecting entirely new datasets while still increasing diversity.
To ensure reproducibility and scalability, it's a good idea to use augmentation pipelines from libraries like imgaug, which streamline the process and maintain consistency across experiments.
What is Data Augmentation? Complete Guide
Learn more
Step 8: Split the Dataset
Splitting ensures that your model generalizes well to unseen data. Follow these guidelines:
Types of Splits
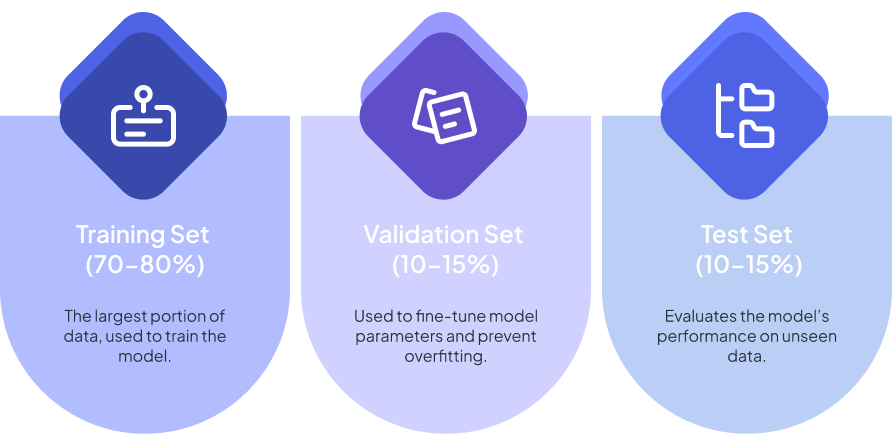
- Training Set (70-80%): Used for learning patterns in the data.
- Validation Set (10-15%): Helps fine-tune hyperparameters and prevents overfitting. Techniques like cross-validation can enhance reliability.
- Test Set (10-15%): Provides an unbiased evaluation of the model’s performance.
When working with data, several key considerations ensure efficiency and reliability. Stratified sampling is crucial for imbalanced datasets, such as those involving rare diseases, to maintain proportional representation across all splits. For time-series data, using temporal splits is essential—keeping training data earlier than validation and test sets prevents data leakage and ensures realistic model evaluation. Tools like Scikit-learn’s train_test_split or StratifiedShuffleSplit automate splitting while ensuring reproducibility.
Step 9: Data Storage
Efficient data storage is fundamental for managing large datasets, ensuring accessibility, and maintaining scalability.
Storage Options
- Relational Databases (SQL): Ideal for structured data, enforcing schema consistency with robust querying capabilities. Popular choices include PostgreSQL and MySQL.
- NoSQL Databases: Suitable for semi-structured or unstructured data, offering flexibility and scalability. Examples include MongoDB for document storage and Apache Cassandra for distributed databases.
- Cloud Storage: Services like Amazon S3, Google Cloud Storage, and Azure Blob Storage provide scalable, pay-as-you-go solutions.
Scalability is another important factor—choosing a solution that can handle growing data volumes prevents bottlenecks. Optimizing storage formats like Parquet or ORC improves performance by enabling faster data access. Security also plays a major role, requiring proper access controls, encryption, and compliance to protect sensitive information.
Use data versioning tools like DVC to track dataset changes efficiently.
Datasheet for Datasets: Transparency Standards for Responsible AI
Learn more
Example
A large e-commerce company handling millions of product images and user-generated content might use Amazon S3 for raw image storage, PostgreSQL for structured metadata, and Elasticsearch for fast search indexing, ensuring a seamless experience for users while maintaining efficient data retrieval.
Real-World Use Case: Building a Movie Recommendation Dataset

Imagine designing a personalized movie recommendation system—similar to what Netflix or Letterboxd uses. The foundation of such a system is a well-structured dataset, carefully curated from diverse sources.
To build this dataset, structured movie data is gathered from platforms like IMDb, leveraging its API, or using web crawling tools like Scrapy to extract crucial details such as titles, genres, ratings, and reviews. Since user-generated opinions shape recommendations, data from forums like Reddit or Letterboxd can provide authentic, diverse perspectives.
A recommendation model also relies on user interaction logs—but when starting from scratch, this historical data doesn’t exist. A solution is to simulate user behavior by incorporating surveys, collecting preference inputs, or utilizing synthetic datasets like MovieLens, which already contains structured user ratings and interactions.
Once the data is collected, the next step is preprocessing. Raw text reviews often contain unnecessary elements such as HTML tags, emojis, or special characters, which can be cleaned using BeautifulSoup. Ratings from different sources may follow different scales, so normalizing them to a common range (e.g., 0 to 1) ensures consistency. Duplicate records can distort insights, and tools like Pandas’ drop_duplicates() function help maintain dataset integrity. Feature engineering further enhances the dataset, for example, by extracting sentiment scores from user reviews using VADER or NLP models like spaCy.
For datasets that require labels, annotation plays a critical role. Sentiment analysis labels—positive, neutral, or negative—can be generated manually or outsourced to crowdsource platforms like Amazon Mechanical Turk. Similarly, movie genres can be manually categorized or assigned using semi-automated classifiers.
Before training begins, the dataset must be properly split. Typically, a 70-15-15 rule is followed: 70% for training, 15% for validation, and 15% for testing. Stratified sampling ensures balanced representation across genres or sentiments, while for time-sensitive recommendations, chronological splitting prevents data leakage.
To enhance model performance, data augmentation techniques can be applied. For text-based data, back translation—translating text into another language and back—helps improve model generalization, which can be done via the Google Translate API. Generative Adversarial Networks (GANs) can create synthetic reviews that mimic real-world language patterns, and small variations can be introduced in user ratings to simulate diverse preferences.
The final step is validation and iteration. Training a quick collaborative filtering model using Surprise provides initial insights into dataset effectiveness, helping to refine preprocessing, annotation, and augmentation strategies. Iterating through these steps ensures that the dataset evolves into a robust, scalable foundation for personalized recommendations.
Tools for Dataset Creation
Here are some tools to streamline your workflow:
- Data Cleaning:
- Pandas (https://pandas.pydata.org/) for handling tabular data.
- OpenRefine (https://openrefine.org/) for cleaning large datasets interactively.
- Annotation Tools:
- LabelImg (https://github.com/heartexlabs/labelImg) for image data.
- Prodigy (https://prodi.gy/) for active learning in text annotation.
- RectLabel (https://rectlabel.com/) for video annotation.
- Augmentation Libraries:
- TextAugment (https://github.com/dsfsi/textaugment) for NLP augmentation.
- Albumentations (https://albumentations.ai/) for image transformations.
- Version Control:
- DVC (https://dvc.org/) ensures traceability and reproducibility of datasets.
- Git LFS (https://git-lfs.github.com/) for handling large files.
- Exploratory Analysis:
- Tableau (https://www.tableau.com/) or Power BI (https://powerbi.microsoft.com/) for visualizing patterns and insights in the dataset.
By leveraging these tools, you’ll ensure a smooth, efficient, and scalable dataset creation process for machine learning applications.










