
What is Synthetic Data?
What if we could create data that didn’t even exist yet, but still reflected the complexities of the real world? As the digital landscape continues to evolve, synthetic data has emerged as a revolutionary tool in industries ranging from healthcare to finance. Synthetic data is artificially generated information that mirrors the statistical and mathematical properties of real-world datasets. This data serves as a powerful tool for training machine learning models, testing software, and enabling research, all while safeguarding privacy and reducing costs. Among the major problems that synthetic data solves are Privacy, Data Scarcity, and Bias.
The global synthetic data market is projected to grow significantly in the coming years, as more companies recognize the value of this data in enhancing privacy, scalability, and cost-efficiency. In this guide, we’ll explore how synthetic data is generated, its methods, tools, industry applications, and best practices to help you leverage it effectively.
Types of Synthetic Data
There are several types of synthetic data, each serving different purposes:
Fully Synthetic Data
This type of synthetic data has no direct link to actual data points. It’s entirely generated from random processes or models. Fully synthetic data is used in situations where the real-world scenario is too complex or sensitive to replicate with actual data.
Partially Synthetic Data
To create partially synthetic data, developers modify or replace some aspects of real data with generated content. This type of data is used to protect sensitive information while retaining some level of real-world accuracy.
Hybrid Synthetic Data
This is a combination of real and synthetic data, where the latter is used to fill in gaps or expand datasets in a controlled manner. Hybrid synthetic data is great for enhancing diversity in datasets and improving ML model training process while maintaining confidentiality and privacy.
Methods for Generating Synthetic Data
Statistical Distribution-Based Generation
This method relies on statistical models to generate data with similar distributions (like normal, binomial, or exponential) to the original dataset. Techniques like Monte Carlo simulations or bootstrapping are used to create large datasets that statistically resemble the actual data in terms of mean, variance, and other properties.
Industry Applications
Finance
In the financial industry, statistical methods for generating synthetic data are used for risk modeling and financial simulations. By leveraging this method, banks and investment firms can analyze market behaviors without exposing sensitive financial information.
Market research
Synthetic data is often used to simulate consumer behavior and preferences, helping companies to predict market trends and evaluate the potential success of products.
Agent-Based Modeling (ABM)
ABM is used to create complex, interactive simulations of individual agents (like cells in biology, consumers in economics, or vehicles in traffic systems) and their interactions within a defined environment. These individual agents operate based on a predetermined set of rules. Agent-based modeling can produce dynamic and unpredictable datasets and is useful for understanding complex dynamics and nuanced systems or organisms.
Industry Applications
Urban Planning and Transportation
ABM helps in simulating traffic patterns, urban development scenarios, or public transportation systems. This data is then used to optimize city planning and mobility solutions.
Epidemiology
This method is applied to model the spread of diseases and the impact of public health interventions. ABM aids in pandemic planning and response strategies.
Neural Network Techniques
Variational Autoencoders (VAEs)
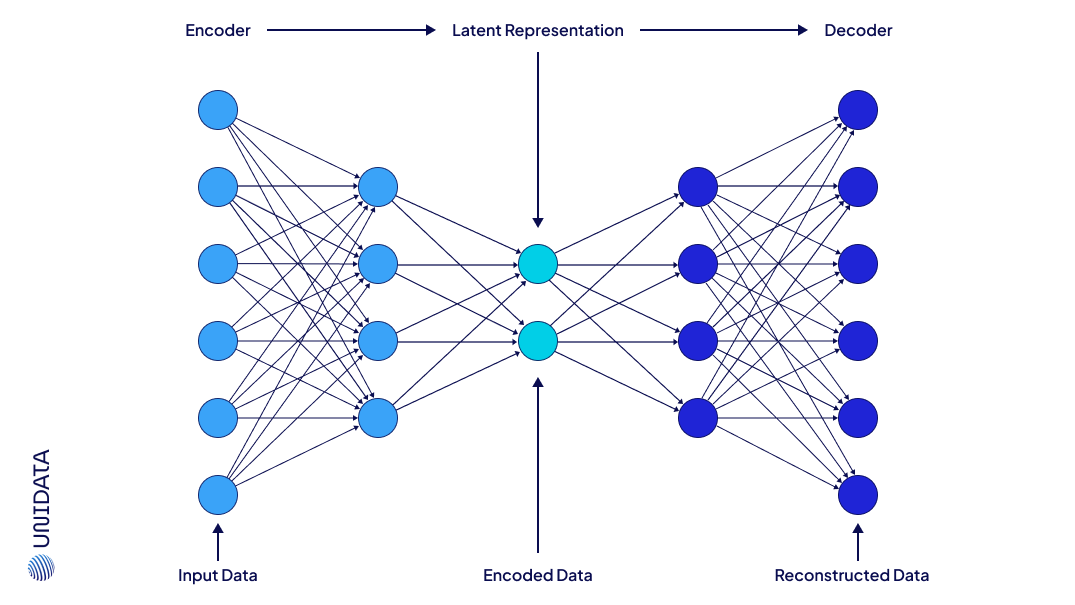
VAEs use deep learning to encode data into a compressed representation. They employ the input data distribution to generate new data points. VAEs do so while maintaining the statistical characteristics of the original dataset. Variational Autoencoders are particularly useful for capturing the underlying structure and variability within complex datasets.
Industry Applications
Biotechnology
VAEs are applied to create genomic sequences or protein structures for research. This significantly facilitates discoveries without compromising sensitive genetic information.
Content Creation
With the help of variational autoencoders creators can generate realistic textures, graphics, or other digital assets for video games and virtual reality environments.
Generative Adversarial Networks (GANs)
GANs consist of two neural networks – a generator and a discriminator. These neural networks are employed in a competitive setting to produce data: the generator creates data, while the discriminator evaluates its authenticity. This refines the generator's capability over time and produces highly realistic synthetic data.
Industry Applications
Entertainment and Media
GANs produce lifelike audio, video, or images for movies, music, and art. This method is also applied in special effects when generating realistic characters and environments.

Fashion and Retail
Generative adversarial networks can design virtual fashion items or inventory for online retail. This aids in product visualization and marketing strategies while saving time and money on real photoshoots.
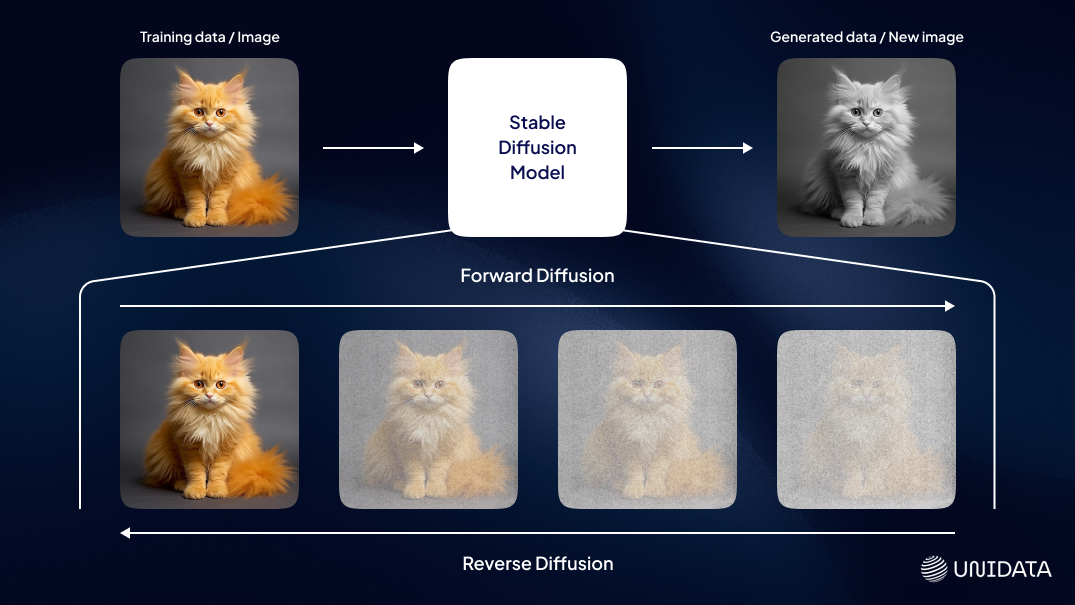
Diffusion Models
This method starts with a dataset, gradually adds noise to it, and then learns to reverse the process to create new, high-quality synthetic instances. Diffusion models are known for generating high-quality, incredibly detailed images or audio.
Industry Applications
Audio and Speech Processing
Creates realistic speech or environmental sounds that can be employed in telecommunications, media, and AI-driven customer service applications.
Climate Modeling
Diffusion models are capable of simulating weather patterns or climate phenomena. This can be applied to predict changes, impacts, or help in planning and response strategies.
Other techniques for synthetic data generation
Rules engine, entity cloning, and data masking can be used in the process of generating or handling synthetic data, although they are not synthetic data generation methods in the traditional sense of creating new data from scratch. Here's how they fit into the context of synthetic data:
Rules Engine
This technique created data via user-defined business policies. This means that a defined set of rules or logic dictates how data should be generated or modified. While it can be used to create synthetic data, it often serves more as a method for transforming or manipulating existing data.
Example: A company in the financial industry could use a rules engine to generate synthetic data for simulating transactions. The rules engine might define policies like "if the transaction amount exceeds $10,000, flag it as suspicious" or "generate 10% of transactions with a high risk score." This allows the company to create datasets of transactions that follow these rules, enabling them to test fraud detection systems or other business applications without using real customer data.
Entity Cloning
In the context of synthetic data, entity cloning involves copying and modifying existing data entities to create new, synthetic versions. Entity cloning uses duplication and altering of real data to protect sensitive information rather than generating entirely new datasets from statistical models or algorithms.
Example: In healthcare, entity cloning could be used to generate synthetic patient records. For instance, an entity like a patient record—comprising name, age, medical history, and medication prescriptions—could be cloned, then modified by adjusting attributes such as medication types or medical conditions. This would help create datasets for testing new healthcare management software while ensuring no real patient data is exposed.
Data Masking
This technique is utilized to hide or obscure sensitive information in a dataset. Data masking can be integrated into the process of preparing synthetic data when the goal is to create a version of the original dataset with the same structural and statistical characteristics but without revealing any sensitive information.
Example: In a retail scenario, data masking can be used to protect sensitive customer information like credit card numbers or addresses. For example, a dataset containing actual customer transaction data could be masked so that real customer names and purchase details are replaced with pseudonyms or randomized data, yet the overall statistical characteristics of the dataset remain intact. This allows for testing or analysis without compromising sensitive data.
Deep Learning for Computer Vision
Learn more
Tools for Creating Synthetic Data
There are various tools designed for synthetic data creation that adhere to different projects’ needs and requirements. Here are some of them:
MOSTLY.AI
A synthetic data generator that excels in creating realistic and detailed datasets. MOSTLY AI generates anonymized datasets that maintain the statistical properties of the original data. It employs advanced machine learning techniques, particularly GANs, to produce data that is useful for testing, analytics, and training purposes. MOSTLY AI is set on creating data without compromising personal privacy.
- Best for generating anonymized customer data, transactional data, and healthcare data for testing, analytics, and model training, while preserving privacy.
Datomize
This tool uses advanced algorithms to generate synthetic data that closely mirrors the original data’s structure and statistical properties. Datomize is popular in the financial sector where it simulates banking transactions and customer data while maintaining privacy.
- Best for generating synthetic banking transactions, credit card data, and financial customer information for financial institutions, ensuring data privacy and regulatory compliance.
Mimesis
A Python library that generates high-quality data for testing and filling databases during development. Mimesis supports multiple languages and provides a wide range of data categories – from personal information to business-related data.
- Best for generating synthetic personal information, address data, company profiles, and e-commerce product data for testing and database population in various development environments.
Hazy
Hazy allows organizations, especially in the financial sector, to perform effective data analysis, testing, and development. The platform enables companies, particularly in fintech, to scale their data operations without exposing sensitive customer information.
- Best for generating synthetic financial data, including bank account data, transaction records, and loan data for data analysis, testing, and product development, while ensuring privacy and security.
Best Practices in Synthetic Data Generation
Define the Objective
You need to understand the purpose of generating synthetic data. Understanding the goal helps tailor the synthetic data to meet specific requirements.
Choose the Right Technique
Select the synthetic data generation method that best fits the data requirements and intended use. Simple datasets can be created with statistical modeling, while complex data requires advanced neural network approaches like GANs and VAEs.
Ensure Data Diversity
To avoid bias and improve the training process of machine learning models, make sure that your data covers a wide range of scenarios. Also, include edge cases that may not be well represented in real data.
Continuously Refine Data
Synthetic data generation should be an iterative process. The output should be continuously monitored, evaluated, and refined to improve the quality and relevance of synthetic data.
Use Quality Metrics
Employ metrics to assess the quality of synthetic data, including similarity to real data, diversity, and privacy preservation.
Involve Industry Experts
Collaboration with specific industry experts can help set realistic and relevant parameters for synthetic data generation.
Common Pitfalls When Generating Synthetic Data and How to Avoid Bias
While synthetic data offers great potential for training machine learning models and simulating real-world scenarios, its generation must be approached carefully to avoid introducing bias and inaccuracies into models. Here are common pitfalls and strategies to ensure the integrity of synthetic data:
1. Lack of Diversity in Synthetic Data
One of the most significant risks when generating synthetic data is creating datasets that lack diversity. If synthetic data does not adequately represent the full range of possible scenarios or edge cases, it can result in biased models that fail to generalize well to real-world situations.
How to Avoid It:
- Ensure Data Coverage: When creating synthetic data, it's essential to cover a wide range of scenarios, including rare or edge cases that may not be well represented in the original dataset.
- Incorporate Variability: Use techniques like Monte Carlo simulations or agent-based modeling to introduce variability in the generated data, ensuring that synthetic datasets reflect a broader spectrum of possible outcomes.
2. Overfitting to a Specific Dataset
Synthetic data is often created based on statistical properties or distributions derived from an existing dataset. If the synthetic data is too closely modeled on the original data, it may inadvertently introduce overfitting, where the model learns to fit the synthetic data too precisely, leading to poor performance when applied to new, unseen data.
How to Avoid It:
- Introduce Controlled Noise: Adding controlled noise or perturbations to the synthetic data can prevent overfitting by making the data more generalized and less specific to the original dataset.
- Cross-Validation: Use cross-validation techniques to test synthetic data against various subsets of real-world data to ensure that the generated dataset does not lead to overfitting or inaccurate results.
3. Ignoring Imbalanced Data
Real-world datasets often contain class imbalances, where certain outcomes or categories are underrepresented. If synthetic data is generated without considering these imbalances, it may exacerbate bias by over-representing the majority class and under-representing minority classes, leading to models that perform poorly for the less-represented groups.
How to Avoid It:
- Incorporate Class Balancing: Ensure that synthetic data generation methods take into account the class distribution of the real-world dataset. Use techniques like SMOTE (Synthetic Minority Over-sampling Technique) to generate balanced datasets that reflect both the majority and minority classes appropriately.
- Monitor Bias During Generation: Regularly check the balance of categories in the synthetic dataset and adjust the generation process to ensure fairness.
4. Failure to Preserve Real Data Characteristics
Another pitfall is failing to accurately replicate the statistical properties, correlations, and relationships present in the real data. If synthetic data doesn't preserve these key characteristics, models trained on it may fail to make accurate predictions or generalizations when exposed to actual data.
How to Avoid It:
- Use Advanced Modeling Techniques: Employ advanced synthetic data generation methods such as Variational Autoencoders (VAEs) or Generative Adversarial Networks (GANs) to preserve the statistical properties of the original dataset while generating new instances.
- Evaluate Data Quality: Regularly assess the quality of synthetic data by comparing it with the original data using statistical tests (e.g., mean, variance, correlations) and visual methods (e.g., histograms, scatter plots) to ensure that key patterns are maintained.
5. Ethical and Privacy Concerns
When creating synthetic data, particularly in sensitive domains like healthcare or finance, there’s a risk that the generated data might inadvertently reveal private or confidential information. While synthetic data aims to protect privacy, poorly generated data might still retain traceable patterns from the original dataset that could lead to privacy violations.
How to Avoid It:
- Use Differential Privacy: Implement differential privacy techniques during data generation to ensure that the synthetic data cannot be reverse-engineered to reveal any sensitive details.
- Test for Re-identification Risks: Perform re-identification risk assessments to ensure that synthetic data does not expose personal or confidential information, particularly when it is based on sensitive real-world datasets.
Case studies
Waymo’s training of self-driving cars
Waymo is an autonomous driving technology development company that stands out in its innovative use of synthetic data. The company uses synthetic data to enhance the development and safety of its autonomous vehicles.
A sophisticated simulation system is used to create detailed virtual environments. What’s crucial is that it mirrors the complexities of real-world driving conditions. Waymo’s system generates synthetic data that provides a diverse array of driving scenarios – it includes rare and potentially hazardous situations.
Waymo employs this synthetic data to train its ML models extensively. The data helps the models to learn and predict various outcomes based on different driving conditions, traffic scenarios, pedestrian interactions, and environmental factors. Synthetic data helps Waymo test and refine the decision-making algorithms of self-driving cars.
Synthetic Data in Healthcare
Synthetic data in the healthcare sector is used to enhance research, education, and the development of health information technology (IT) systems. Synthetic data suits perfectly in the healthcare industry since it’s imperative to maintain patients’ privacy and confidentiality.
Access to real health data and patient records is often restricted due to privacy concerns. Synthetic data allows for broader sharing and accessibility, facilitating the development of new products, services, and research methodologies.
Healthcare applications of synthetic data are diverse, including simulation and prediction research, hypothesis testing, epidemiological studies, health IT development, and educational purposes. For instance, synthetic data enables researchers to expand sample sizes or include variables absent from original datasets. This significantly improves the accuracy of disease-specific simulations and health policy evaluations.
Synthetic data also serves as a practical tool for teaching data science and healthcare analytics: it provides medical students with realistic yet confidential datasets to learn from. In health IT development, synthetic data is used for testing and validating software applications.
HSBC’s “Synthetic Data as a Service” Initiative
HSBC has implemented a project named "Synthetic Data as a Service": it aims to generate synthetic datasets that maintain the utility and privacy of data. The bank is committed to using synthetic data for rapid prototyping, experimentation, and fostering external collaborations with startups, academics, and technology partners.
HSBC's approach combines in-house development of synthetic data engines with expertise from leading academic institutions and vendors. The bank has made significant progress, establishing conceptual architectures, data flows, and APIs to generate synthetic data. Their initiative allows users to upload real data and receive information on the bank's capabilities while ensuring privacy and utility.
HSBC’s Platform as a Service (PaaS) solution strives to enhance its data analytics and business intelligence capabilities. This serves as an example of a forward-thinking approach to data management and utilization in the financial services sector.
Conclusion
Generating synthetic data is a multifaceted process: it requires careful consideration of the objectives and selection of suitable generation tools and methods to ensure the resulting datasets are both useful and ethical. As industries continue to recognize the value of synthetic data, its generation and use are set to become more prevalent.










