
Introduction
Computer vision, the interdisciplinary field enabling machines to interpret and understand visual data, has seen remarkable transformations over the decades. From the pixel-based methods of traditional computer vision to the data-driven power of deep learning, the evolution has been nothing short of revolutionary. Today, deep learning has elevated computer vision to unprecedented levels, powering applications from autonomous vehicles to facial recognition systems.
This article delves into the journey of computer vision, contrasting traditional techniques with deep learning’s advancements, and explores how modern frameworks and models continue to redefine this domain.

Brief History and Evolution of Traditional Computer Vision
The origins of computer vision date back to the 1960s, with its initial focus on enabling machines to recognize simple patterns and geometric shapes. Early algorithms relied heavily on handcrafted features and rule-based systems to process and interpret images. For instance, techniques like thresholding and edge detection aimed to segment and outline key elements in an image. While these methods were groundbreaking at the time, their dependency on manually designed features limited their flexibility and accuracy.
The 1990s and early 2000s saw the introduction of more sophisticated techniques like feature descriptors, including SIFT (Scale-Invariant Feature Transform) and SURF (Speeded-Up Robust Features), which enhanced the robustness of object recognition. However, these traditional approaches struggled with complex and unstructured data, such as the variability in lighting, perspective, and occlusions present in real-world images. Enter deep learning—a paradigm shift that leveraged neural networks’ ability to learn features directly from data, marking the dawn of a new era in computer vision.
Core Techniques in Traditional Computer Vision
While traditional computer vision methods may seem outdated, they laid the foundation for modern advancements. Let’s explore two cornerstone techniques:
Thresholding
Thresholding is one of the simplest segmentation techniques used to separate objects from the background based on pixel intensity. For instance, binary thresholding converts grayscale images into binary images by applying a fixed threshold value. While effective for high-contrast images, it falters in scenarios with uneven lighting or complex textures.
Edge Detection
Edge detection identifies the boundaries within an image by detecting changes in intensity. Algorithms like the Canny Edge Detector are widely used for tasks such as object detection and feature extraction. Despite its effectiveness in controlled settings, edge detection often produces noisy results in real-world applications where images are cluttered or contain subtle transitions.
These limitations underscored the need for more adaptive and robust techniques, paving the way for deep learning’s ascendancy.
Steps for Working with Images and Models in Computer Vision
To successfully develop and deploy a computer vision system using deep learning, it is essential to follow a structured workflow. Here’s a detailed breakdown of the steps involved:
- Data Collection. The foundation of any computer vision task lies in obtaining a high-quality dataset. This involves:
- Collecting diverse and representative images relevant to the task.
- Ensuring sufficient data volume to prevent overfitting.
- Augmenting data with transformations such as rotation, flipping, and cropping to increase diversity, as there is often a shortage of data, posing challenges for effective model training.
- Defining the Task. Clearly identify the objective of the project. Typical tasks include:
- Image classification: Categorizing images into predefined classes.
- Object detection: Identifying and localizing objects within an image.
- Semantic segmentation: Assigning a class label to every pixel.
- Image generation: Creating synthetic images.
- Selecting the Model. Choose a deep learning model architecture suited to the task. For instance:
- Use CNNs like ResNet or VGG for classification tasks.
- Employ YOLO or Faster R-CNN for object detection.
- Opt for U-Net for semantic segmentation tasks.
- Leverage GANs for image generation.
- Choosing a Framework. Select a framework based on the project requirements:
- TensorFlow or PyTorch for flexibility and scalability.
- Keras for rapid prototyping and ease of use.
- OpenCV for integrating traditional and deep learning methods.
- Training and Evaluation. Train the model on the dataset and evaluate its performance using appropriate metrics:
-
- Image Classification: Use accuracy, precision, recall, and F1 score.
-
- Object Detection: Evaluate Intersection over Union (IoU) and mean Average Precision (mAP).

-
- Semantic Segmentation: Measure IoU or Dice Coefficient.

-
- Image Generation: Employ metrics like Inception Score (IS) and Fréchet Inception Distance (FID).
This structured approach ensures that every aspect of the computer vision pipeline is addressed, leading to robust and efficient models.
Deep Learning Models for Computer Vision
Deep learning’s transformative impact on computer vision is largely due to the development of innovative neural network architectures. Below are ten of the most impactful models, with their advantages, challenges, and contributions.
The first three models represent the foundational efforts in deep learning for computer vision, primarily addressing classification tasks. These models laid the groundwork for more sophisticated architectures that followed:
AlexNet
- Description: AlexNet marked the beginning of deep learning’s dominance in image classification by winning the ImageNet competition in 2012. It introduced convolutional neural networks (CNNs) to the mainstream.
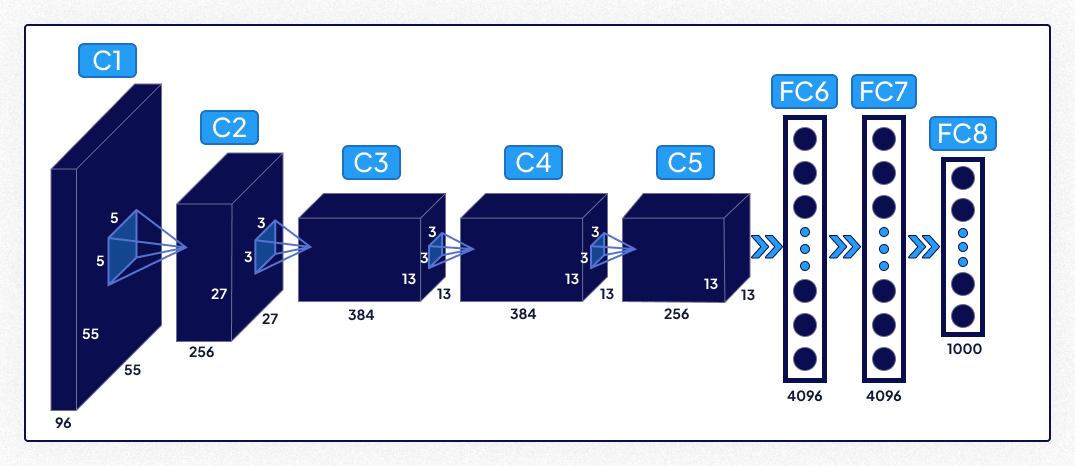
- Key Features:
- Relu activation function to address vanishing gradients.
- Dropout for regularization to prevent overfitting.
- GPU acceleration for faster training.
- Most Suitable for: General image classification tasks where moderate computational resources are available.
- Impact: AlexNet’s success demonstrated the potential of deep learning, setting the stage for more complex architectures.
VGGNet
- Description: VGGNet is known for its simplicity and uniform structure, using small convolutional filters (3x3) stacked together to increase depth.
- Key Features:
- Uniform design with consistent filter sizes.
- Deep network architecture with 16 or 19 layers.
- High feature extraction capability.
- Most Suitable for: Image recognition tasks requiring detailed feature extraction.
- Impact: VGGNet’s emphasis on depth influenced the design of subsequent architectures.
ResNet (Residual Networks)
- Description: ResNet introduced residual connections, allowing networks to train effectively even with hundreds of layers.
- Key Features:
- Skip connections to prevent vanishing gradients.
- Scalability to extremely deep architectures (e.g., ResNet-152).
- High accuracy for both classification and detection tasks.
- Most Suitable for: Scenarios requiring very deep networks, such as image segmentation and medical imaging.
- Impact: ResNet set a benchmark for performance, becoming a standard for many tasks.
Next comes an introduction to core computer vision tasks: segmentation, object detection, and localization, among others. Each task is tailored to address specific challenges and has seen models developed chronologically, with newer approaches tackling increasingly complex problems.
Image Classification
Inception (GoogleNet) (2014)
Inception introduced the concept of "inception modules," combining convolutions of varying sizes to efficiently capture multi-scale features. Its innovative architecture reduced computational costs while maintaining high accuracy.
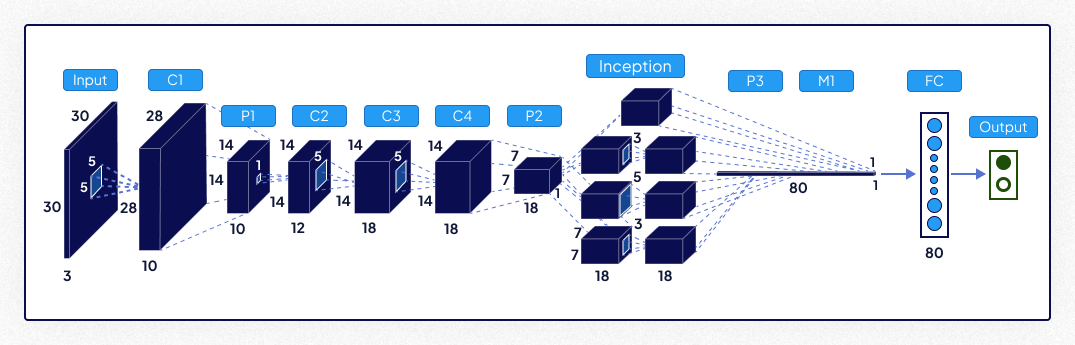
- Key Features:
- Multi-scale feature extraction within a single module.
- Reduced computational cost compared to similar networks.
- Auxiliary classifiers to combat vanishing gradients and improve training.
- Most Suitable for: Applications requiring efficient computation, such as mobile vision tasks or scenarios with limited resources.
- Impact: Inception significantly enhanced computational efficiency and accuracy in image classification, setting a new standard in deep learning research.
MobileNet (2017)
MobileNet is tailored for mobile and embedded systems, utilizing depthwise separable convolutions to dramatically reduce computational complexity while maintaining competitive accuracy.
- Key Features:
- Lightweight architecture for resource-constrained devices.
- Scalable for various performance levels using hyperparameters.
- Competitive accuracy with reduced parameters and operations.
- Most Suitable for: Mobile applications like AR/VR, IoT devices, and other edge-computing tasks.
- Impact: MobileNet enabled AI deployment on edge devices, transforming on-the-go applications in computer vision.
Object Detection
Faster R-CNN (2015)
Faster R-CNN builds upon its predecessor, R-CNN, by introducing a Region Proposal Network (RPN) for efficient region generation, followed by object classification.
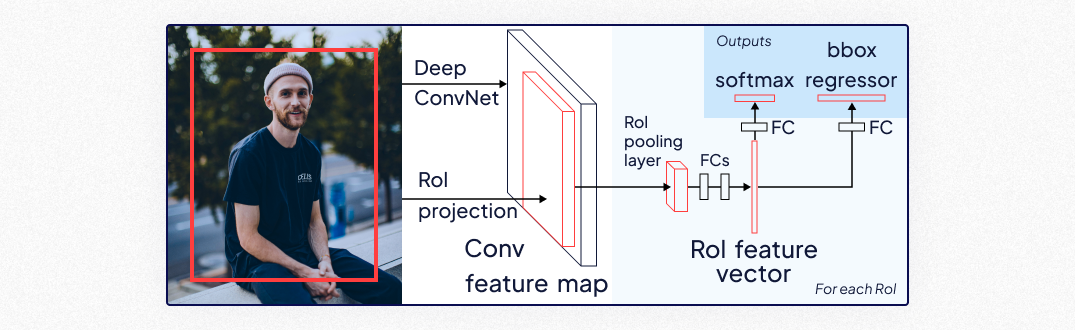
- Key Features:
- RPN for generating region proposals, speeding up the detection process.
- High accuracy, especially for small object detection.
- Balanced trade-off between speed and precision compared to earlier models.
- Most Suitable for: Tasks demanding high accuracy, such as facial recognition, document analysis, and traffic management.
- Impact: Faster R-CNN set a benchmark for precision in object detection, influencing numerous subsequent advancements in the field.
YOLO (You Only Look Once) (2016)
- Year: Introduced in 2015 by Joseph Redmon and Santosh Divvala.
- Description: YOLO revolutionized object detection with its single unified architecture, processing entire images in one forward pass to achieve real-time performance.
- Key Features:
- Unified architecture that integrates detection and classification.
- Real-time inference capabilities for practical applications.
- Strong speed-accuracy trade-off, suitable for low-latency tasks.
- Most Suitable for: Real-time applications like surveillance, robotics, and autonomous vehicles.
- Impact: YOLO became synonymous with real-time object detection, making complex tasks more accessible for industrial applications.
Semantic Segmentation
U-Net (2015)
U-Net’s symmetric encoder-decoder architecture, augmented with skip connections, excels in pixel-wise classification. Initially designed for biomedical imaging, it has found applications across various domains.
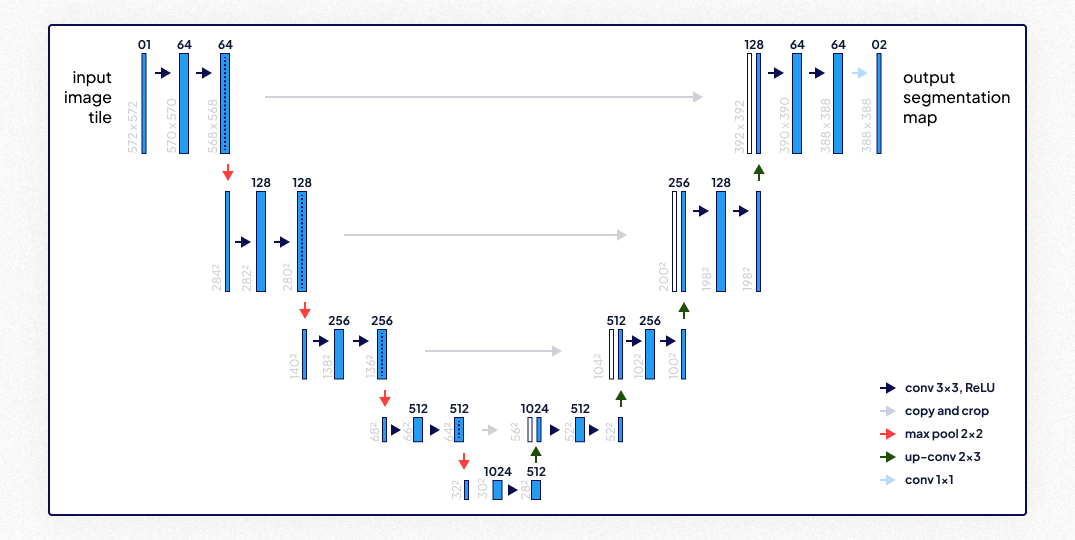
- Key Features:
- Skip connections that preserve spatial information across layers.
- High performance on small and imbalanced datasets.
- Designed specifically for pixel-perfect classification tasks.
- Most Suitable for: Semantic segmentation tasks, particularly in medical imaging, satellite data processing, and urban planning.
- Impact: U-Net became the de facto standard for segmentation tasks, especially in healthcare and specialized domains.
Generative Models
GANs (Generative Adversarial Networks) (2014)
GANs consist of two competing networks—the generator and discriminator—that work together to create realistic synthetic data, redefining image generation.
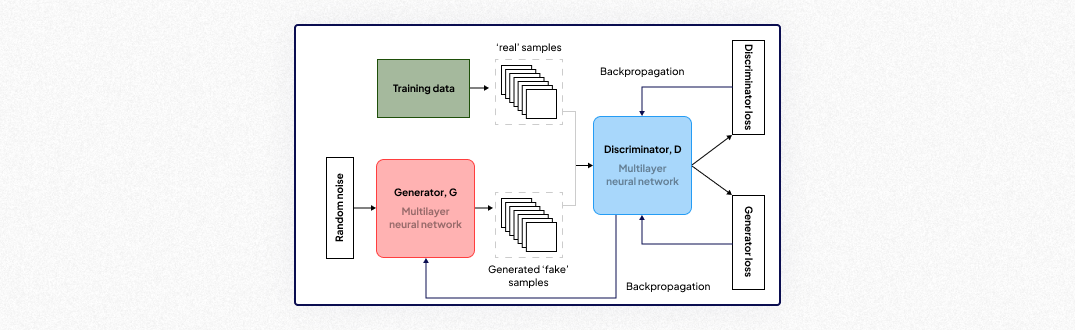
- Key Features:
- Ability to generate highly realistic images from random noise.
- Flexible architecture suitable for various domains, such as style transfer and super-resolution.
- Wide applicability across creative and technical tasks.
- Most Suitable for: Data augmentation, creative content generation, super-resolution, and image-to-image translation.
- Impact: GANs revolutionized creative applications in computer vision, fostering advancements in art, entertainment, and data simulation.
Multi-Task Models
Vision Transformers (ViTs) (2020)
ViTs adapted transformer models from natural language processing to vision tasks, leveraging self-attention mechanisms to capture global context in images.
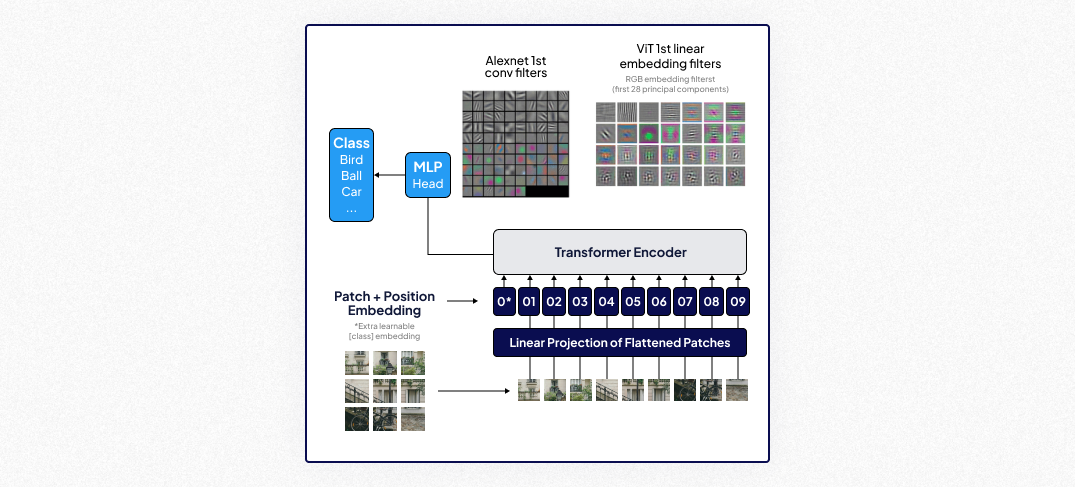
- Key Features:
- Self-attention mechanisms for understanding global feature relationships.
- High performance when trained on large datasets.
- Suitable for tasks involving complex spatial and contextual understanding.
- Most Suitable for: Scene understanding, complex segmentation, and classification tasks that require interpreting intricate spatial relationships.
- Impact: ViTs bridged the gap between transformers and computer vision, opening new avenues for handling diverse and complex tasks with enhanced global context comprehension.
Popular Frameworks for Deep Learning in Computer Vision
Deep learning frameworks serve as the backbone of modern computer vision applications, providing tools for development, training, and deployment:
This library is used for image preprocessing, like removing noise and smoothing contours. The images are processed with this library before being fed into deep learning frameworks for model access.

OpenCV
OpenCV (Open Source Computer Vision Library) is a powerful toolset originally created for traditional computer vision tasks like image processing, feature detection, and object tracking. Over time, OpenCV has incorporated deep learning capabilities, allowing users to integrate neural networks with its extensive library of computer vision functions. OpenCV's compatibility with TensorFlow and PyTorch enhances its versatility, making it a popular choice for hybrid approaches combining traditional and deep learning methods. It is widely used for tasks like video analysis, facial recognition, and real-time image processing.
They are all for deep learning models. These libraries are designed for the same tasks.

TensorFlow
TensorFlow, developed by Google, is a versatile and comprehensive framework widely adopted for deep learning applications. It supports both high-level and low-level APIs, enabling users to create custom architectures or quickly implement pre-designed models. TensorFlow is known for its scalability, capable of running on CPUs, GPUs, and TPUs, making it suitable for projects of all sizes, from academic experiments to industrial-scale applications. Its ecosystem includes TensorFlow Hub, where developers can access a variety of pre-trained models for tasks like object detection, image segmentation, and more. TensorFlow Lite enables efficient deployment of models on mobile devices and edge hardware, ensuring broader usability across platforms.

PyTorch
PyTorch, developed by Facebook AI, has become a favorite among researchers due to its ease of use, dynamic computation graph, and flexibility. Unlike TensorFlow, which traditionally relied on static computation graphs, PyTorch allows for on-the-fly graph creation, making it easier to debug and adapt during development. PyTorch is particularly well-suited for experimentation and prototyping, and its adoption has grown rapidly in the academic community. Features like TorchScript enable seamless model deployment in production environments, bridging the gap between research and practical implementation. The framework also includes libraries like torchvision, which provides tools for handling image data and pre-trained models.

Keras
Keras is a high-level neural network API written in Python and runs on top of frameworks like TensorFlow. Designed with user-friendliness in mind, Keras simplifies the process of building and training deep learning models. Its intuitive syntax and modular design make it an excellent choice for beginners and those working on rapid prototyping. Although it lacks the flexibility of lower-level frameworks like PyTorch, Keras integrates seamlessly with TensorFlow, offering access to TensorFlow’s robust functionalities. Keras is often used in applications requiring fast experimentation and deployment without delving into intricate details.
Each framework caters to different needs, empowering developers to innovate without reinventing the wheel.
Uses of Deep Learning in Computer Vision
The applications of deep learning in computer vision are vast and transformative, with its influence spreading across numerous industries and domains:
Healthcare: Deep learning models analyze medical images with remarkable precision, enabling early disease detection such as cancer diagnoses from CT scans or the identification of neurological conditions through MRI analysis. For example, convolutional neural networks (CNNs) are widely used to detect tumors and anomalies, significantly improving diagnostic accuracy and patient outcomes.

Agriculture: Advanced AI-powered drones and imaging systems leverage deep learning to monitor crop health, detect pest infestations, and optimize irrigation strategies. By analyzing spectral data from drone-captured images, these models help farmers make informed decisions, increasing yields and reducing waste.

Automotive: Autonomous vehicles depend heavily on computer vision systems powered by deep learning. These systems interpret road signs, detect pedestrians, and identify potential hazards in real-time. For instance, Tesla's Autopilot uses object detection and semantic segmentation to navigate complex traffic environments safely.
Retail: Facial recognition technology enhances security measures and improves customer experience by enabling personalized shopping. Retailers use deep learning-based recommendation systems to analyze customer behavior and suggest relevant products, revolutionizing how businesses interact with consumers.

Art and Culture: AI tools like GANs (Generative Adversarial Networks) are employed to restore deteriorated historical artifacts, generate realistic portraits, and even create entirely new art styles. Deep learning bridges the gap between traditional craftsmanship and modern technology, ushering in a new era of cultural preservation and creativity.
Manufacturing: In industrial settings, deep learning models are used for quality control, detecting defects in assembly lines with precision. For example, vision-based systems can identify cracks or irregularities in materials, ensuring higher production standards.
Entertainment and Media: In the gaming and film industries, deep learning aids in creating realistic characters, environments, and effects. Technologies like motion capture are enhanced through vision-based models to generate lifelike animations and immersive experiences.
These examples demonstrate how deep learning has not only addressed longstanding challenges but also unlocked unprecedented opportunities across diverse fields. As the technology continues to evolve, its potential applications in computer vision will expand, shaping the future of industries and enhancing human experiences.
Conclusion
The journey from traditional computer vision to deep learning represents more than a technological evolution—it’s a paradigm shift in how we teach machines to see. While traditional techniques laid the groundwork, deep learning has unlocked unparalleled possibilities, making complex visual tasks feasible and scalable. As frameworks and models continue to evolve, the synergy between cutting-edge research and practical applications ensures that computer vision remains at the forefront of AI innovation.










