

Picture your ML project as an engine. The dataset is its fuel. Just like drivers debate whether to refine their own gasoline or buy it at a station, ML teams wrestle with whether to build bespoke datasets or purchase data from third‑party vendors. This seemingly simple decision ripples through budget, timeline, ethical standing, and final product quality. Get it wrong, and the engine sputters; get it right, and it purrs.
In the sections that follow, we’ll unpack the pros and cons of building versus buying datasets, exploring costs, time‑to‑market, fairness, and compliance. We’ll end with a decision checklist that helps teams steer toward the right option for their needs.
Why the Decision Matters
Your dataset choice shapes cost, speed, risk, and machine learning (ML) model quality. It also shapes ethics, consent, and long-term intellectual property (IP) control. In face recognition, weak data can hardwire unfair errors into production models. The National Institute of Standards and Technology (NIST) tested nearly 200 face algorithms and found large accuracy gaps. In some tests, false positives for Asians and African Americans were 10–100 times higher than other groups.
Pros of Building Your Own Dataset
Building means designing the fuel, not just the engine. Upfront, it is slower and costlier, yet it can pay back later. More importantly, teams define what quality means in their domain.

1. Complete Control over Content and Labeling
Teams decide what enters the dataset, what each label means, and how quality checks run. That control matters when labels must match business rules, not a vendor’s defaults. A strong workflow starts with clear labeling guidelines, tested on a small batch before scaling. Agreement checks across labelers expose unclear definitions early and keep decisions consistent. Edge cases need written rules, so rare examples stop turning into random labels. When product needs change, guidelines can evolve without renegotiating contracts. Error correction and revision tracking also stay in-house, supporting reproducibility during audits.
2. Competitive Differentiation and IP Ownership
A custom dataset can become a durable competitive advantage that competitors struggle to replicate. Ownership covers the collection plan, label rules, and the final curated asset. A 2025 GroupBWT post notes custom datasets can match languages, regions, and regulatory conditions for better accuracy. That fit matters when narrow requirements define success, like regulated onboarding or safety workflows. Data ownership can support pricing power because models learn from unique signals. It also reduces dependency on a vendor’s roadmap, pricing changes, or sudden policy shifts.
3. Alignment with Domain Realities
Public datasets often miss the messy realities of production. Users, cameras, sensors, lighting, and workflows shape what “normal” looks like. Building lets teams match that context, instead of hoping general data transfers cleanly. Failure modes can be sampled deliberately, then labeled with domain-specific rules. A CMSWire example describes firms building contact databases by scanning warranty cards and loyalty programmes. That kind of first-party capture can align with internal systems.
4. Ethical and Fairness Assurance
When your audience is diverse, training data must be diverse too. Teams can plan coverage by age, gender, and skin tone, then measure gaps during quality assurance (QA). NIST found demographic error differences, including higher false positives for some groups.
5. Security and Privacy Compliance
Building can simplify privacy planning when data includes personal or sensitive information. Strong collection workflows capture consent, retention, and deletion rules from day one. That supports laws like the General Data Protection Regulation (GDPR) and similar frameworks.
6. Potential Long-Term Cost Savings
Building costs more upfront, but reuse can spread that cost across many model cycles. A stable dataset can reduce repeated vendor fees, re-labeling, and surprise pricing jumps. It can also lower retraining cost because refresh timing and sampling strategy stay under your control. Over time, the dataset becomes shared infrastructure for new projects. Amortising collection across products can drop the cost per use sharply. This is most true when frequent updates and long product lifetimes are expected.
Cons of Building Your Own Dataset
Building is powerful, but it demands money, time, and patience. Many teams underestimate the hidden work between collection and training. The hardest part is often governance, not the first prototype.
1. Significant Upfront Cost
High-quality data is expensive before the first model ships. Coherent Solutions estimates sourcing 100,000 samples can cost ≈ $70,000. They report 80–160 hours for cleaning and 300–850 hours for annotation. A full dataset may cost $10,000–$90,000 depending on complexity. Those figures include broader AI development, but dataset creation is often a major component. Smaller companies can struggle to allocate that capital without a clear ROI path.
2. Time-Consuming Development Cycle
Building is not just costly; it is slow. The work includes planning, collection, QA, annotation, storage, and legal review. Dataset creation is cumbersome and time-consuming, requiring careful design and thorough documentation. Tight deadlines can kill the business case before the model is ready. Delays also stack, because each iteration needs new samples, new labels, and new checks.
3. Need for Diverse Expertise
A good dataset needs more than engineers and a labeling tool. It also needs data owners, domain experts, privacy reviewers, legal counsel, and quality leads. MSBC highlights specialised roles, including data scientists, ML engineers, ethicists, legal counsel, and development operations (DevOps). Without that mix, teams miss edge cases, write vague labels, or skip key checks. Hiring this talent can be harder than buying the data. Even with strong talent, coordination cost rises as reviewers and annotators grow.
4. Infrastructure and Maintenance Overhead
Teams must store, version, secure, and serve the dataset for training and evaluation. That means pipelines, access control, backups, and monitoring. Governance is also needed for changes, like schema shifts and label guideline updates. MSBC notes annual maintenance for custom solutions at $100k–$700k. Even if data is the focus, upkeep still costs real money. Without version tracking, reproducibility fades, and results become harder to defend.
5. Risk of Poor Quality or Bias If Not Done Properly
Owning the dataset does not guarantee quality. Sampling can skew, labels can drift, and edge cases can vanish. NIST’s demographic findings show how biased or narrow data can produce unequal errors. Without coverage checks, systems can fail quietly for some users. Fixing those gaps later is slower and more expensive. Quality failures also hurt trust, because stakeholders blame the product, not the dataset.
6. Opportunity Cost
Dataset work pulls focus from shipping features and winning users. Teams can spend months polishing labels while competitors ship workable products. That lost time is often the biggest cost, and it rarely shows on a budget sheet. When the market moves fast, speed may matter more than perfect data. Leaders should ask what the team is not building during collection.
Pros of Buying a Dataset
Buying can be the shortest path from idea to baseline model. It trades control for speed and lower upfront effort. For many teams, that trade is rational in early stages.

1. Speed to Market
Buying lets teams start training in days instead of months. Vendors often provide ready-made data, labels, and basic documentation. This helps prove value fast, then refine later with targeted custom data. For pilots and proofs, speed is often the point. Once gaps are clear, teams can build only what they truly need.
2. Lower Upfront Cost
Purchased data can reduce the first cash hit. MSBC lists purchased solutions at $100k–$400k upfront, with $15k–$80k annual maintenance. That is still serious money, but it can fit budgets better than a full build. It also spreads cost through subscriptions instead of large one-time spends. For cash-tight teams, that shift can keep the project alive. Teams can also buy smaller slices, then expand after validation.
3. Access to Diverse and Large-Scale Data
Many vendors aggregate data from many places and many scenarios. This helps when teams need volume fast, like language or vision tasks. Diversity can improve, too, if the vendor measures coverage and reports it clearly. For global products, that scale can be hard to match internally. In biometrics, some vendors package testing evidence to reduce buyer risk.
4. Expert Annotation and Documentation
Good vendors bring trained labelers, QA flows, and stable guidelines. Some also provide datasheets, label taxonomies, and version notes for traceability. That can save teams weeks of setup and rework. Fit still needs review, but the baseline is often usable. For standard tasks, vendor labels may be adequate for first deployment. For niche tasks, vendor work can still be a strong starting point.
5. Reduced Infrastructure Burden
Vendors may host data, manage access, and handle updates. That reduces internal storage, pipeline work, and security operations. It also lowers the burden of long-term version control. Teams can focus on modeling and product integration. This is useful when core strength is product, not data engineering. It also lowers staffing risk when key people leave.
6. Predictable Costs and Scalability
Pricing is often fixed per licence, subscription, or volume tier. That makes planning easier than open-ended collection and labeling budgets. When teams need more data, another tranche is often available. Scaling becomes a contract decision, not a hiring sprint. Predictable costs help leaders compare projects across a portfolio. They also reduce temptation to cut corners on QA to save short-term money.
Cons of Buying a Dataset
Buying is fast, but it can mask risks behind a tidy contract. The biggest issues are fit, rights, and trust. Blind purchases can lock in long-term technical debt.
1. Less Customization and Context Relevance
A vendor dataset is built for the average customer, not your edge cases. The label set may be too broad, too shallow, or simply different. Domain shifts then show up as brittle model behaviour in production. Extra collection is often needed to cover real conditions. When vendors cannot explain sampling, failure modes become harder to predict. This is why small evaluation sets matter before any big purchase.
2. Uncertain Licensing and IP Limitations
Vendor contracts often restrict reuse, resale, and derivative works. Some forbid model training for certain uses, or demand extra fees for new products. The OECD highlights how scraping and unclear rights can lead to disputes over training data use. Unclear rights can create legal exposure for buyers. Always map licence terms to the exact use case. Also, check termination clauses, because access loss can break retraining plans.
3. Dependence on Vendor Availability
Vendor access can change through pricing shifts, data removals, or shutdowns. Label rules can change too, which can break reproducibility. When models depend on that stream, teams inherit vendor business risk. This is especially painful when retraining is frequent. Dependence also shows up during urgent fixes, when vendor response is slow.
4. Hidden Costs and Data Quality Issues
Buying does not remove cleaning, filtering, and QA work. Duplicates, wrong labels, or missing fields still require internal time. Legal review, security checks, and integration work also add cost. Those costs can turn a low-priced dataset into an expensive project. The worst case is paying twice: once to buy, then again to rebuild. Plan time for sampling audits, label review, and data leakage checks.
5. Limited Competitive Advantage
When competitors buy the same dataset, the data stops differentiating products. Teams may end up competing only on model tweaks and compute. For many markets, that advantage is thin and short-lived. Unique data often matters more than minor architecture changes. If differentiation is the strategy, bought data may not be enough. Teams may need to build a distinctive data slice anyway.
Cost Breakdown Comparison
Cost is more than the purchase price. It includes time, staffing, maintenance, and the cost of being wrong. The numbers below show typical ranges, not guaranteed quotes.
Speed-to-Market Implications
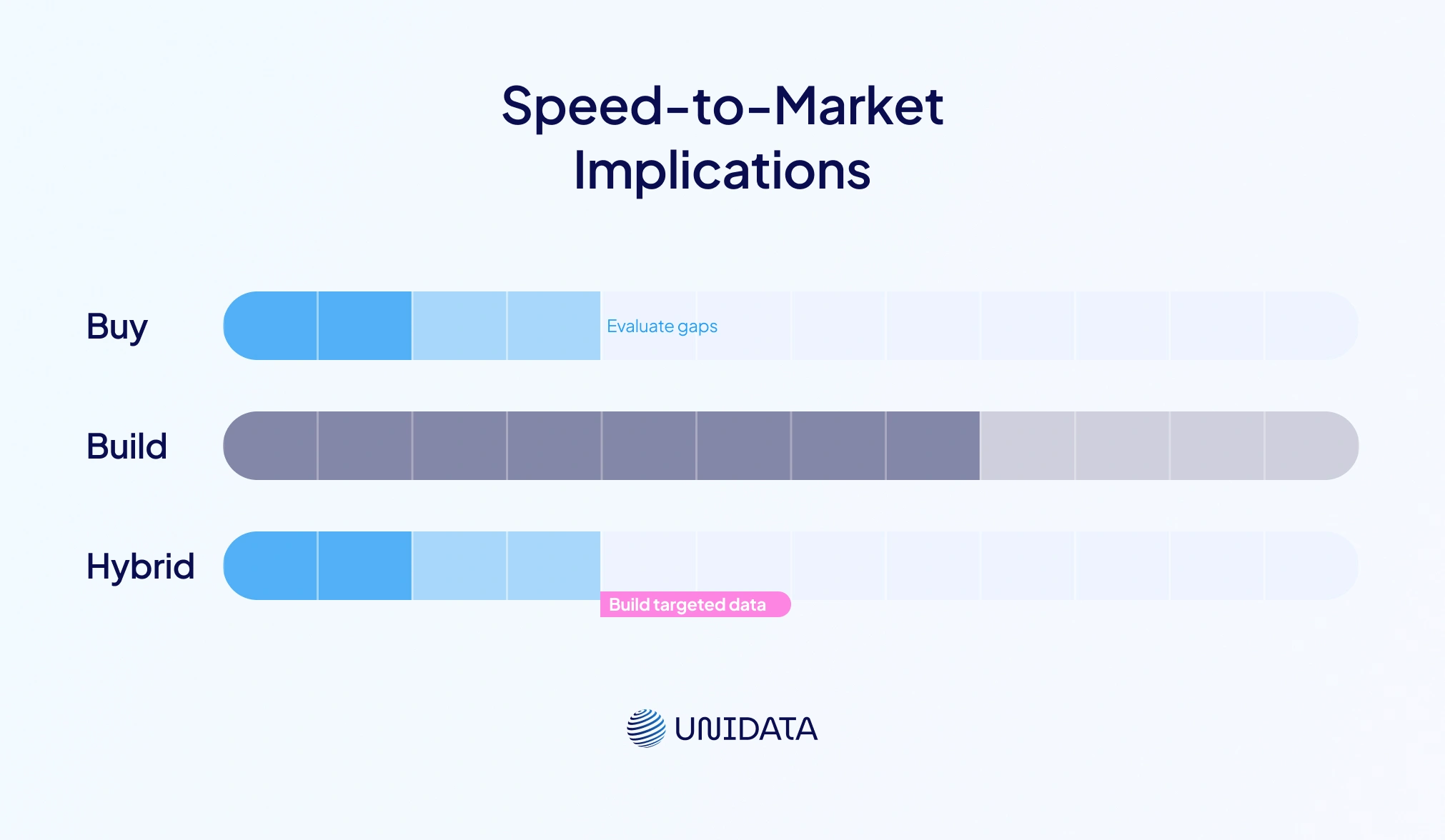
Speed can beat perfection, especially in early markets. Building can take three to four times longer than buying. That delay affects funding, hiring, and customer trust. However, buying can still slow things down if data needs heavy cleanup. So, compare true time to usable training data, not just contract signing time. Also, compare time to reach target metrics, not only time to first model. Many teams start with buying, then build targeted data to remove the last blockers. That hybrid path often balances speed with differentiation.
Data Diversity and Fairness Considerations
Fairness is no longer optional in many products. It affects user trust, legal exposure, and approval in regulated sectors. In its Face Recognition Vendor Test (FRVT), NIST reported a key pattern. Non-diverse training data can drive higher false positives for Asian and African American faces. The National Academies emphasise that more diverse training data reduces demographic false positive disparities. They also discuss reducing bias by equalising feature distributions through loss functions during training.
Common checks include:
- Disparate impact ratio
- Equal opportunity difference
- Average odds difference
Differential privacy audits can also reduce leakage risk in sensitive datasets. Subgroup measurement matters whether you build or buy, not only overall metrics. Treat fairness as a cycle: measure, fix, re-measure, and document every change. Without subgroup metrics, teams cannot claim the system works for everyone.
Privacy, Compliance, and IP Considerations
Data is not just a technical asset; it is a legal object. Teams must plan for consent, security, licences, and audits from day one. These rules apply to collection, storage, training, evaluation, and deletion.
Privacy and Consent
Collecting personal data requires clear consent and lawful basis. This is critical for faces, voices, health records, and location traces. Building gives direct control over consent language and data handling steps. Buying demands vendor due diligence on consent, retention, and deletion policies. Record consent, collection context, and the full technical setup used for capture. Also, plan cross-border transfers, because privacy rules vary by jurisdiction. Missing consent records should be treated as a major risk.
Intellectual Property and Licensing
Building still requires rights from contributors and data owners. Buying requires following the vendor’s licence, even after models are trained. The OECD notes that scraped data can trigger disputes over copyright, database rights, trade secrets, and contracts. So, treat licence terms as product requirements, not legal afterthoughts. Rights chains must be explainable to defend a model later. Also, confirm whether fine-tuning, sharing, or benchmarking is allowed.
Use Cases Where Building Makes Sense
Building tends to win in these cases:
- Highly Regulated Domains: Best when strict consent control, audit trails, and local compliance are non-negotiable.
- Specialized Sensors or Inputs: Ideal for custom cameras, LiDAR (Light Detection and Ranging), medical devices, or unique logs.
- Low Tolerance for Errors: Strong fit where false positives create legal risk, safety risk, or severe customer harm.
- Long-Term IP Strategy: Works when the dataset is a core asset planned for reuse and long-term defence.
- Research and Innovation: Great for novel labels, rare edge cases, or new data types.
Use Cases Where Buying Wins
Buying tends to win in these cases:
- Rapid Prototyping and MVPs: Buying works when you need a minimum viable product (MVP) fast to test product-market fit.
- Generic ML Tasks: Purchased datasets suit sentiment, generic object detection, or standard text classification.
- Budget Constraints: Buying helps when upfront build costs are too high and subscriptions fit planning better.
- Short-Lived Projects: Buying suits models with short lifetimes where ownership adds little value.
- Supplemental Diversity: Buying can fill gaps, then first-party data can cover core users.
Final Decision Checklist
Review before making a final choice
- Define the goal – Is this a pilot, production system, or regulated product needing audit-ready evidence?
- Check data fit – Does the dataset match your domain, devices, and edge cases, or will you fight domain shift?
- Audit rights – Do you have consent and licences for collection, storage, training, and future reuse?
- Measure fairness – Test subgroup performance, not just overall accuracy, and plan mitigation if gaps appear.
- Estimate full cost – Include cleaning, labeling, governance, storage, security, and annual maintenance.
- Plan for change – Decide how you will refresh data, handle drift, and track versions over time.
- Assess dependency – What happens if access ends, prices rise, or label rules change?
- Pick a hybrid if needed – Buy for speed, then build the slices that drive differentiation and trust.
Conclusion
Choosing between building and buying an ML dataset isn’t binary. It’s a strategic trade-off. Building offers control, bespoke quality, and long-term IP. It comes at the cost of time, money, and complexity. Buying provides speed, lower upfront costs, and expert annotation. It may lack domain specificity and fairness guarantees. Start with your project’s constraints. Then set clear goals. Next, check fairness and compliance requirements. Plan for long-term maintenance, too.
This helps you make an informed decision. In some cases, the best answer is both: buy now, build later, and always prioritise ethical, diverse, and legally compliant data. With the right dataset fueling your engine, your machine learning project will go farther and faster.
Frequently Asked Questions (FAQ)
Buy a ready-made training dataset when you need fast dataset sourcing for a standard use case (classification, detection, NLP basics). Build a custom dataset when you need proprietary data, a unique label taxonomy, stronger data governance, or when domain shift would force heavy relabeling.
Check dataset licensing (commercial rights), data provenance, and dataset documentation (data card/datasheet). Then review annotation quality: annotation guidelines, quality assurance (QA), inter-annotator agreement, class balance, edge cases, plus privacy/PII and security compliance.
Beyond annotation hours: data collection, data cleaning, data preprocessing, tooling (labeling platform), human-in-the-loop ops, QA review cycles, and dataset versioning. Costs rise with domain expert labeling, changing guidelines, and ongoing updates to handle data drift.
Yes, if you align schemas, label definitions, and formats, and avoid data leakage across train/validation/test splits. Watch distribution shift between external data and real production inputs. A common approach is transfer learning with bought data, then fine-tuning on in-domain labeled data.










