Handwriting is messy. It loops, smudges, and slants in a hundred different ways depending on who’s holding the pen. And yet, we expect machines to read it — accurately, instantly, and at scale.
Whether you’re building an OCR engine, transcribing historical archives, or training a model to spot forged signatures, it all starts with the right data. A good handwriting dataset doesn’t just show characters — it captures the quirks of human expression in ink.
In this guide, we’ll walk through:
- What makes a handwriting dataset useful (and what to avoid)
- How to choose one based on task, format, and language
- A curated list of 20 datasets worth your time in 2025
Let’s get into it.
How to Choose the Right Dataset
Picking a handwriting dataset isn’t about size alone. You want the right mix of realism, annotation quality, and task alignment. Here’s what actually matters:
Writing style
Cursive or printed? Block letters or slanted scrawl? Match it to your application.
Granularity
Do you need just characters, or full sentences with layout data? Some datasets go pixel-deep. Others just tag words.
Language and script
Latin, Cyrillic, Chinese, Bangla? Multilingual datasets are out there — but not all are balanced.
License
Open-source is great, but some historical datasets need permissions. Always check before you train.
Capture format
Offline (scanned paper) or online (stylus-tracked strokes)? Choose based on how your model will be used.
Digits and Basic Characters
Let’s start simple. If your model can’t reliably tell a 3 from an 8, you’ve got bigger problems down the line. These datasets are built for that first step: recognizing single digits and characters in controlled settings. Clean, compact, and surprisingly competitive when pushed to the edge.
1. MNIST
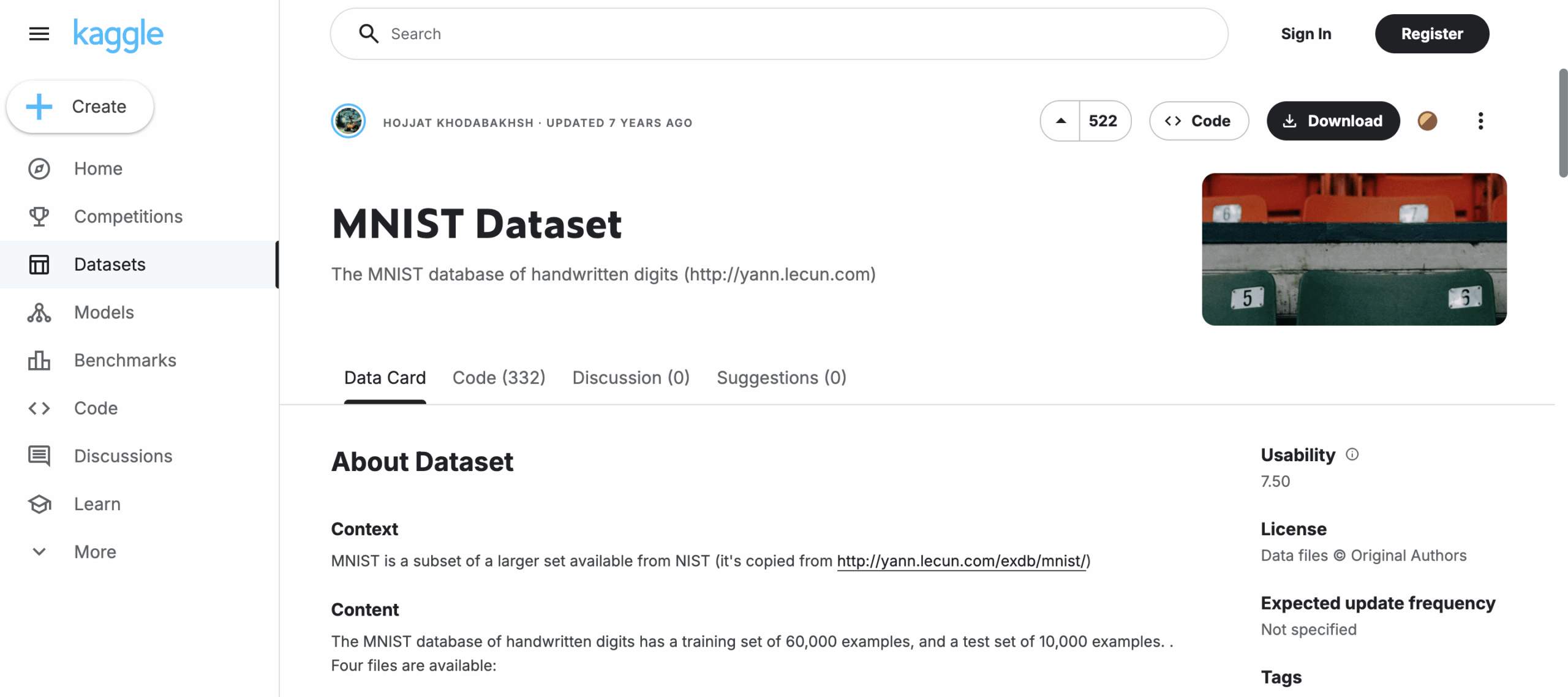
Type: Digits
Language: English
Volume: 70,000 images (28×28)
Format: Offline scans
Access: Free (commercial use permitted)
Annotations: Single-digit labels
This is the “hello world” of handwriting datasets. Despite its age, MNIST remains a staple for testing classification models. Its simplicity is a strength: everything’s clean, centered, and well-labeled. If your system can’t nail MNIST, it’s not ready for the real world.
2. EMNIST
Type: Digits + Letters
Language: English
Volume: 800,000+ samples
Format: Offline
Access: Free (commercial use permitted)
Annotations: Characters (upper/lower/digits), multiple splits
EMNIST picks up where MNIST stops. It includes letters — upper and lower case — and keeps the digit class for continuity. With multiple splits available, you can tailor the dataset to your use case. It’s a better fit for mixed-input tasks like license plate readers or digit-letter combo fields.
🧠 Dataset Spotlight: EMNIST
dataset_name: EMNIST
type: Digits + Letters
access: Free (commercial use permitted)
format: Offline scanned images
ideal_for: Digit-letter classification, OCR training, license plate parsing
3. Chars74K

Type: Characters
Languages: English, Kannada
Volume: 74,000+ images
Format: Offline (scene + hand-drawn)
Access: Free (commercial use permitted)
Annotations: Character labels by source (scene, synthetic, handwriting)
If MNIST is tidy, Chars74K is wild. Pulled from photos, digital drawings, and scanned docs, this set challenges your model with real-world noise. It’s a great dataset to move from lab conditions to unpredictable environments — especially in multilingual settings or domain adaptation.
4. HASYv2
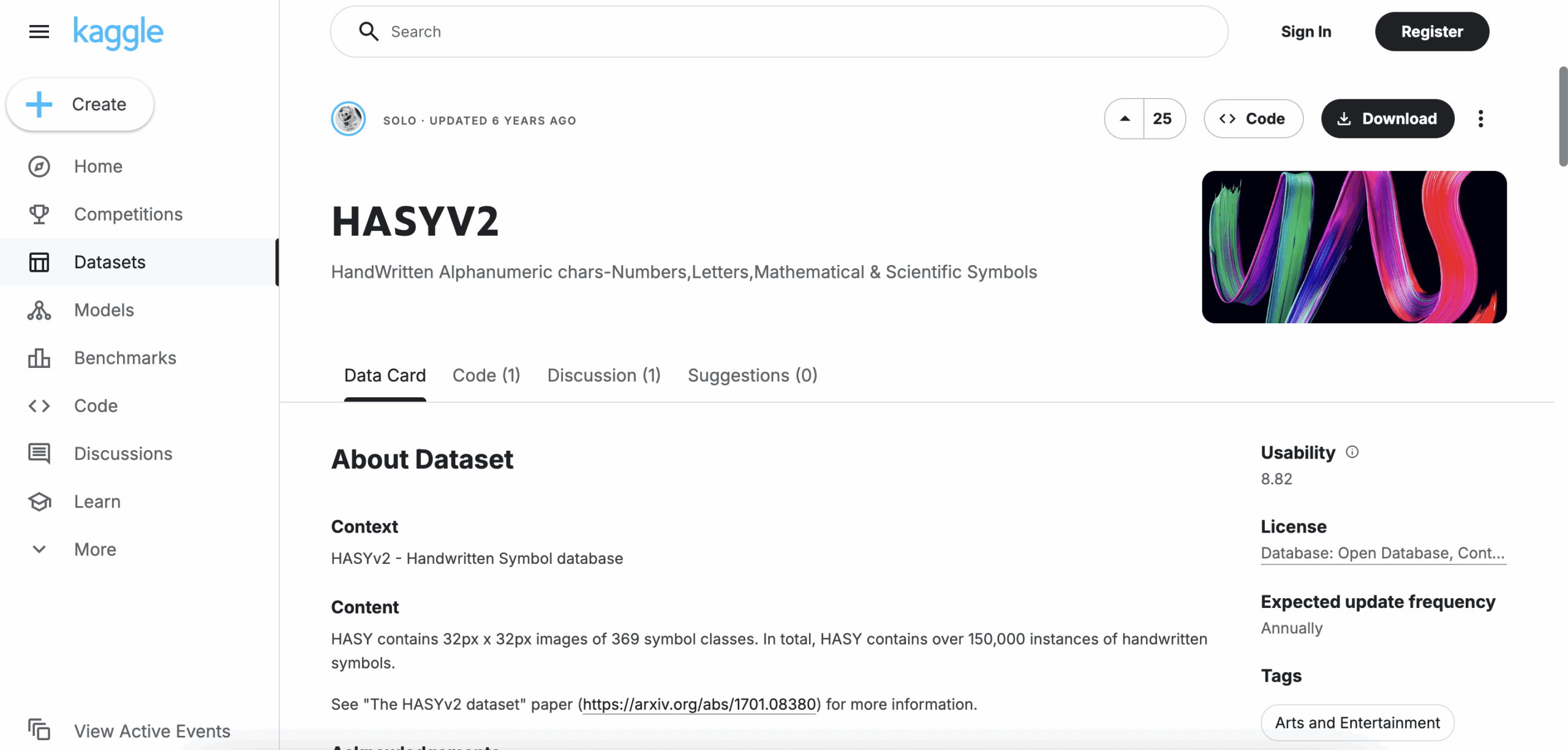
Type: Symbols
Language: LaTeX-style Math
Volume: 168,000 images
Format: Offline (binary 32×32)
Access: Free (commercial use permitted)
Annotations: 369 math symbol classes
Most OCR tools break down when math enters the picture. HASYv2 gives you a head start. Each image is a crisp 32×32 black-and-white render of handwritten math symbols. Great for academic tools, equation parsing, or any workflow involving formulas.
Words and Sentences
Once your model graduates from isolated digits, it needs to tackle full words and connected cursive. These datasets teach it how humans actually write — across lines, with varied pressure, spacing quirks, and all the delightful chaos of real handwriting. Ideal for building transcription systems, smart OCR, or full-page text recognition.

Type: Sentences, Words, Characters
Language: English
Volume: 1,539 pages from 657 writers
Format: Offline (scanned forms)
Access: Free (academic only)
Annotations: Sentences, words, characters (bounding boxes + transcripts)
This is the most cited offline handwriting dataset — and for good reason. IAM is the gold standard for full-line recognition in English. It’s neatly segmented, well-annotated, and large enough to train deep models. If you’re building anything from a smart scanner to a handwriting-to-text pipeline, start here.
📝 Dataset Spotlight: IAM Handwriting
dataset_name: IAM Handwriting Database
type: Sentences, Words, Characters
access: Free (academic only)
format: Offline scans with bounding boxes and transcripts
ideal_for: Full-line OCR, handwriting-to-text models, segmentation tasks
6. RIMES
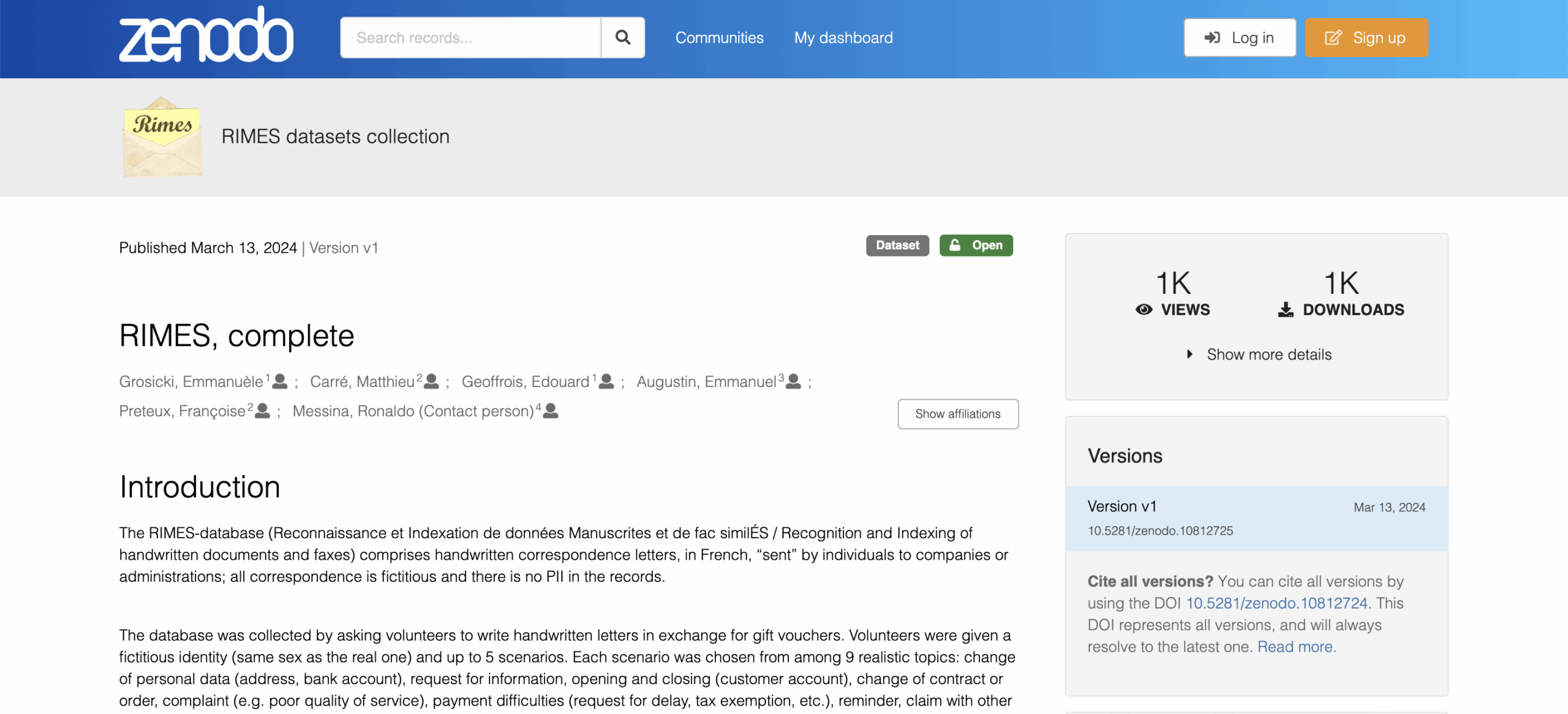
Type: Documents, Sentences, Words
Language: French
Volume: Thousands of letters and forms
Format: Offline (realistic business letters)
Access: Free (academic only)
Annotations: Word-level segmentation, transcripts, metadata
Need French handwriting data? RIMES delivers. It’s built from simulated business mail — letters, invoices, forms — and mimics how handwriting appears in real-world documents. It’s excellent for training document-level models that work across layouts and writing styles, especially in multilingual deployments.

Type: Full documents
Language: Primarily German + multilingual
Volume: Historical archives
Format: Offline scans (historic papers)
Access: Free (academic only)
Annotations: Lines, baselines, region segmentation, full transcripts
Designed for the handwriting competition at ICFHR 2016, this dataset is a playground for layout-aware models. The documents are historical, messy, and packed with structure. If you’re doing handwritten layout analysis, line segmentation, or want to simulate archival OCR — this is a strong candidate.
Historical Manuscripts
Modern handwriting is messy. Old handwriting? It’s a puzzle. From faded ink to century-old flourishes, these datasets are built for models that need to work with historical documents. Whether you're digitizing archives, training transcription engines, or building paleographic tools — this is where you train them to read the past.
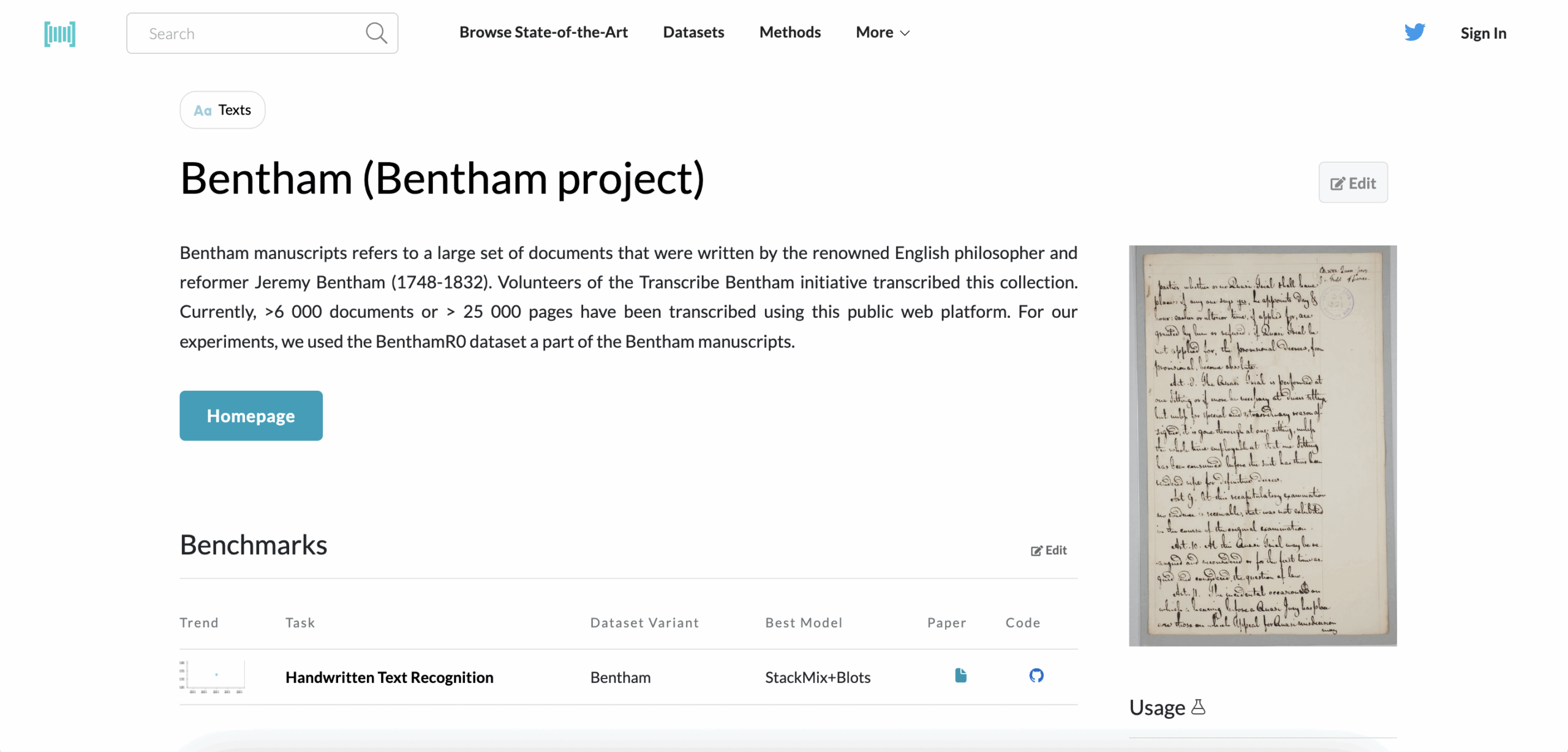
Type: Pages, Lines, Words
Language: English (18th–19th century)
Volume: 6,000+ page images
Format: Offline scans (manuscripts)
Access: Free (via Transkribus platform)
Annotations: Full transcripts, structured line segmentation
Handwriting gets harder when it’s 200 years old. The Bentham dataset gives you digitized manuscripts from philosopher Jeremy Bentham’s archive — complete with dense cursive, old spellings, and vintage quirks. A strong testbed for training models on historical material, especially with a clean transcription pipeline already in place.
🏛️ Dataset Spotlight: Bentham
dataset_name: Bentham Dataset
type: Pages, Lines, Words
access: Free (via Transkribus)
format: Scanned historical manuscripts with structured annotation
ideal_for: Historical OCR, cursive transcription, digital humanities
9. Saint Gall
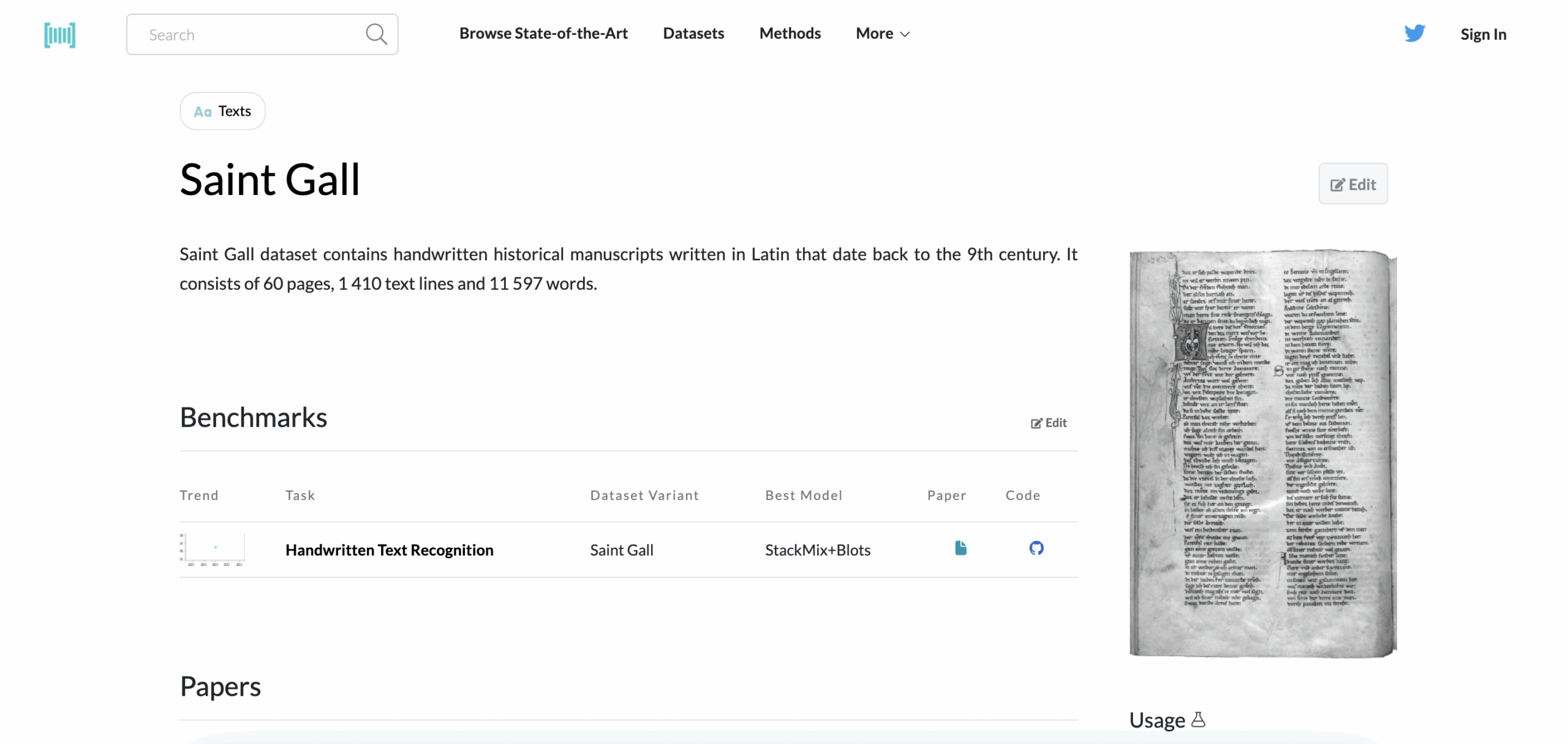
Type: Pages, Lines
Language: Latin
Volume: 60 manuscript pages (9th century)
Format: Offline scans
Access: Free (research use only)
Annotations: 1,410 lines, full transcripts, word boundaries
This dataset brings medieval Latin to machine-readable form. Sourced from a 9th-century monastic manuscript, Saint Gall is dense, handwritten, and historically significant. It’s ideal for training models on ancient scripts, historical OCR systems, or building tools for digital humanities research.
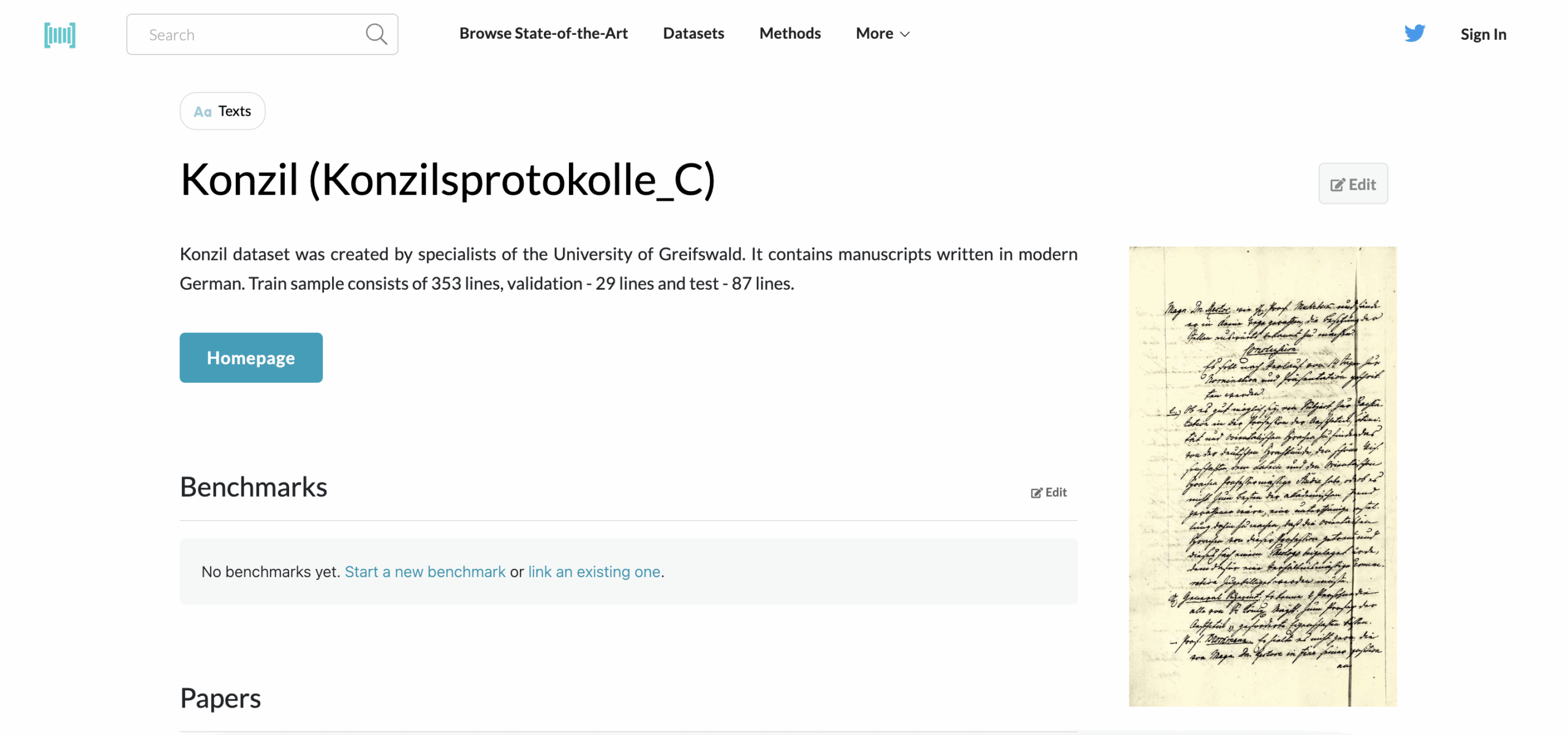
Type: Full documents
Language: German (old variants)
Volume: 100+ archival files
Format: Offline scans
Access: Paid / Restricted (project-based academic access)
Annotations: Region layouts, lines, transcripts, metadata
These are raw, handwritten German archival documents — legal records, council notes, historical letters. Konzil and Patzig challenge your model with shifting layouts, inconsistent line spacing, and period-specific language. Best for testing layout robustness and handling
11. Digital Peter
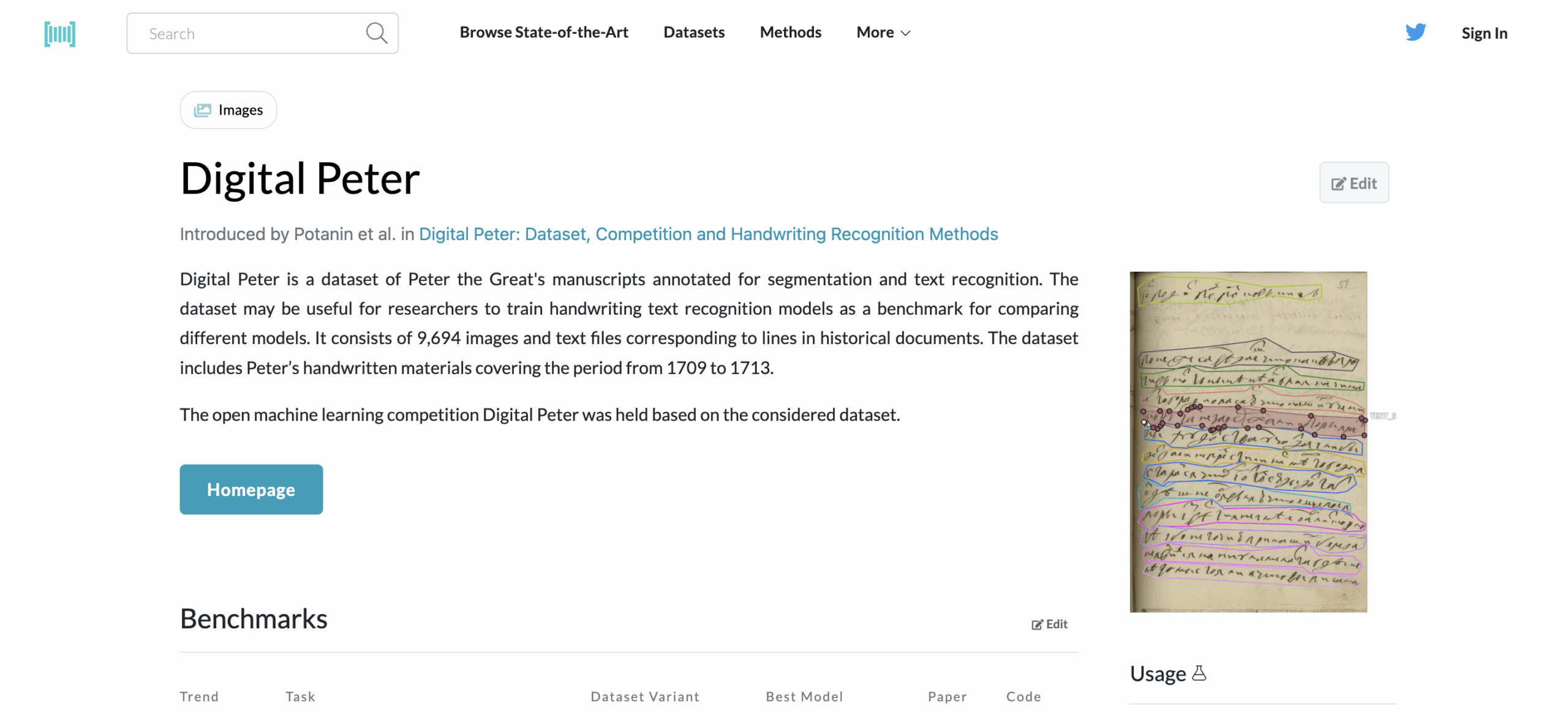
Type: Lines, Pages
Language: Russian cursive (18th century)
Volume: 9,694 images
Format: Offline (digitized manuscripts)
Access: Free (project-based open access)
Annotations: Line-level segmentation, transcript metadata
Peter the Great’s handwriting — yes, literally. This dataset captures early modern Russian script across nearly 10,000 scanned lines. It’s excellent for training models in Cyrillic cursive, working with historical Slavic texts, or enhancing language-specific document digitization pipelines.
Online Handwriting (Stylus-based)
Instead of scanning paper, these datasets capture how handwriting is created — stroke by stroke. Used for digital ink recognition, handwriting input systems, and behavioral biometrics, they’re ideal when timing, pen pressure, and pen paths matter more than pixels.
12. BRUSH
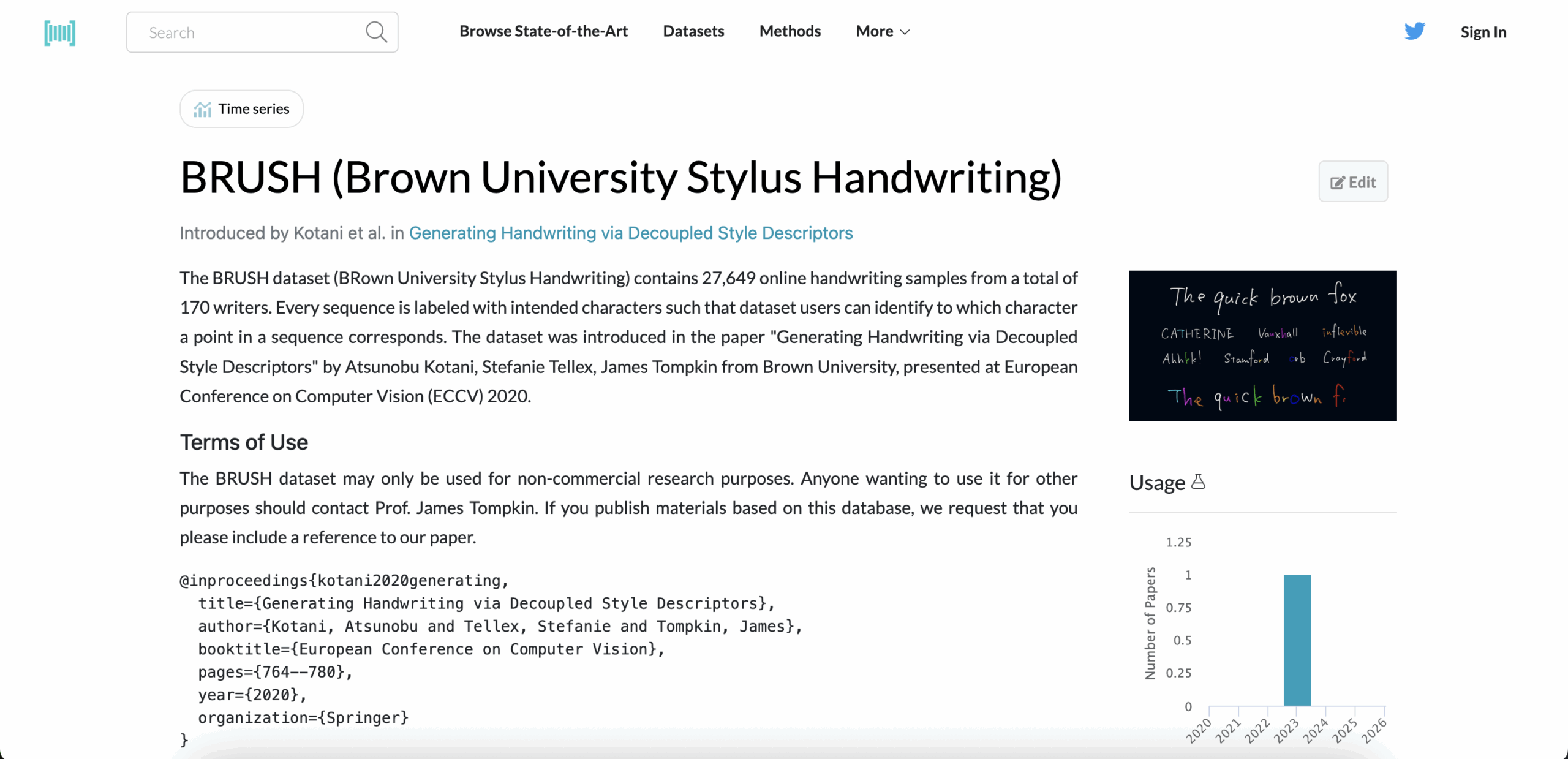
Type: Online strokes
Language: English
Volume: 27,649 word samples from 170 writers
Format: Stylus-tracked trajectories
Access: Free (commercial use permitted)
Annotations: Character and word-level transcripts, stroke order
BRUSH records how people write, not just what they write. It tracks pen movement, speed, and order — making it a solid foundation for building stylus input engines or gesture-aware handwriting systems. If you’re working on smart tablets, signature apps, or custom keyboards, this is a practical start.
✍️ Dataset Spotlight: BRUSH
dataset_name: BRUSH
type: Online strokes
access: Free (commercial use permitted)
format: Stylus-tracked stroke trajectories
ideal_for: Stylus input engines, stroke-aware OCR, behavioral biometrics
13. DeepWriting
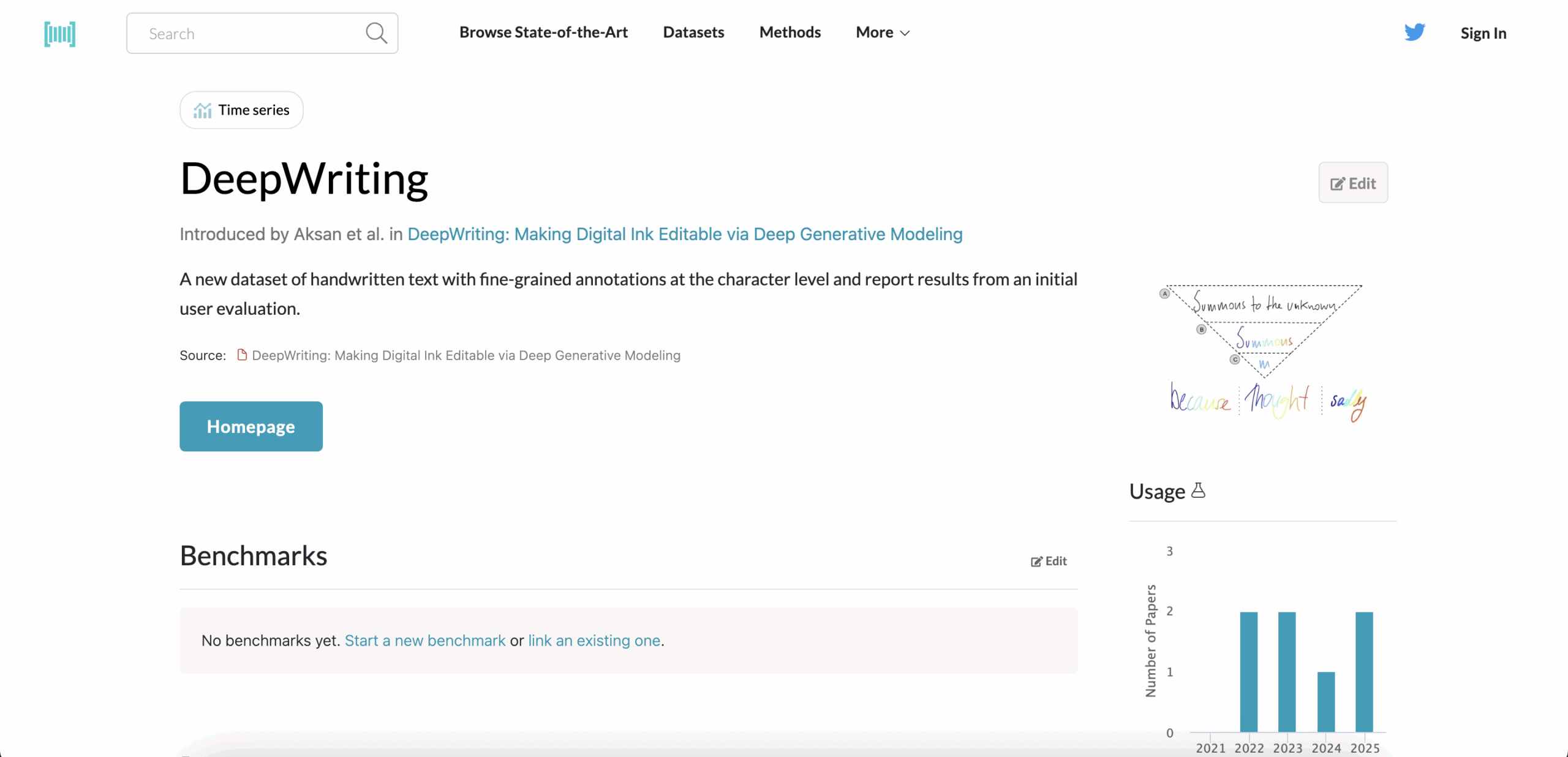
Type: Online strokes
Language: English
Volume: ~30,000 sequences (varied tasks)
Format: Pen trajectories (x, y, pressure, time)
Access: Free (research use only)
Annotations: Stroke-level time series, writing samples across tasks
Built for writer-specific modeling, DeepWriting is less about decoding text and more about understanding how people write. It’s a great fit for behavioral authentication, stroke prediction, and training personalized handwriting input models.
14. CASIA-OLHWDB

Type: Online strokes
Language: Chinese
Volume: 1.5M+ characters
Format: Stylus-captured stroke sequences
Access: Free (academic only)
Annotations: Character-level with stroke timing, direction
For Chinese handwriting, CASIA is a powerhouse. It captures both the order and dynamics of writing over a massive vocabulary. If your system needs to handle non-Latin scripts, complex stroke composition, or multilingual handwriting on touchscreens — start here.
Multilingual and Non-Latin Datasets
Latin script isn’t the whole story. Models deployed in the real world need to handle complex curves, stacked characters, and unfamiliar writing systems. These datasets are built for that challenge — whether it’s decoding Bengali newspapers, handwritten Chinese homework, or mixed Kazakh-Russian text.
15. BanglaLekha-Isolated

Type: Isolated characters
Language: Bangla
Volume: 166,105 samples from 2,000+ writers
Format: Offline scans
Access: Free (commercial use permitted)
Annotations: Unicode character labels, demographics (age, gender, district)
BanglaLekha is one of the largest open handwriting datasets in Bengali. It includes digits, basic characters, and compound forms — all labeled and scanned from real handwritten samples. For Bangla OCR systems, it’s the most accessible starting point available today.
16. BN-HTRd

Type: Documents and words
Language: Bangla
Volume: 786 pages, 108,181 words
Format: Offline scans of printed and handwritten text
Access: Free (academic only)
Annotations: Word and line-level transcriptions
Where BanglaLekha isolates characters, BN-HTRd goes full-document. It combines dense paragraph-level data with accurate ground truth — making it better suited for full-page OCR, paragraph recognition, and real-world layout handling in Bengali text workflows.
17. CASIA-HWDB

Type: Characters (offline)
Language: Chinese
Volume: 1.17 million images
Format: Offline scans
Access: Free (academic only)
Annotations: Character labels, writer ID, style metadata
If you’re working with Chinese, this is your training ground. CASIA-HWDB contains over a million handwritten characters covering thousands of classes. It’s the default for handwritten Chinese recognition and scales well from digit-level to large vocabulary models.
🌐 Dataset Spotlight: CASIA-HWDB
dataset_name: CASIA-HWDB
type: Chinese Characters (offline)
access: Free (academic use only)
format: Scanned handwritten images with writer and style metadata
ideal_for: Non-Latin OCR, Chinese script training, large-vocabulary handwriting recognition
18. HKR (Kazakh-Russian Handwriting)
Type: Sentences
Languages: Kazakh, Russian
Volume: 63,000+ sentences
Format: Offline scans
Access: Free (research use only)
Annotations: Sentence-level transcriptions, mixed-script tags
HKR is one of the few modern handwriting datasets that mixes languages and scripts. Collected from over 200 native speakers, it reflects how Kazakh and Russian are used side by side — perfect for multilingual recognition systems and research into script-switching behavior.
Scene Text and Natural Images
Not all handwriting sits neatly on paper. In the wild, it appears on whiteboards, shop signs, menus, product labels — usually under bad lighting and weird angles. These datasets teach your model to recognize text when it's embedded in the visual noise of real life.
19. IIIT 5K-Word
Type: Word images from scene photos
Language: English
Volume: 5,000 word crops
Format: Cropped natural scene photos
Access: Free (commercial use permitted)
Annotations: Word-level transcripts, bounding boxes
Sourced from Google image search, IIIT 5K is a compact but widely used dataset for scene-text recognition. It’s great for evaluating how well your system handles diverse fonts, occlusions, and background clutter — without having to process full-page documents.
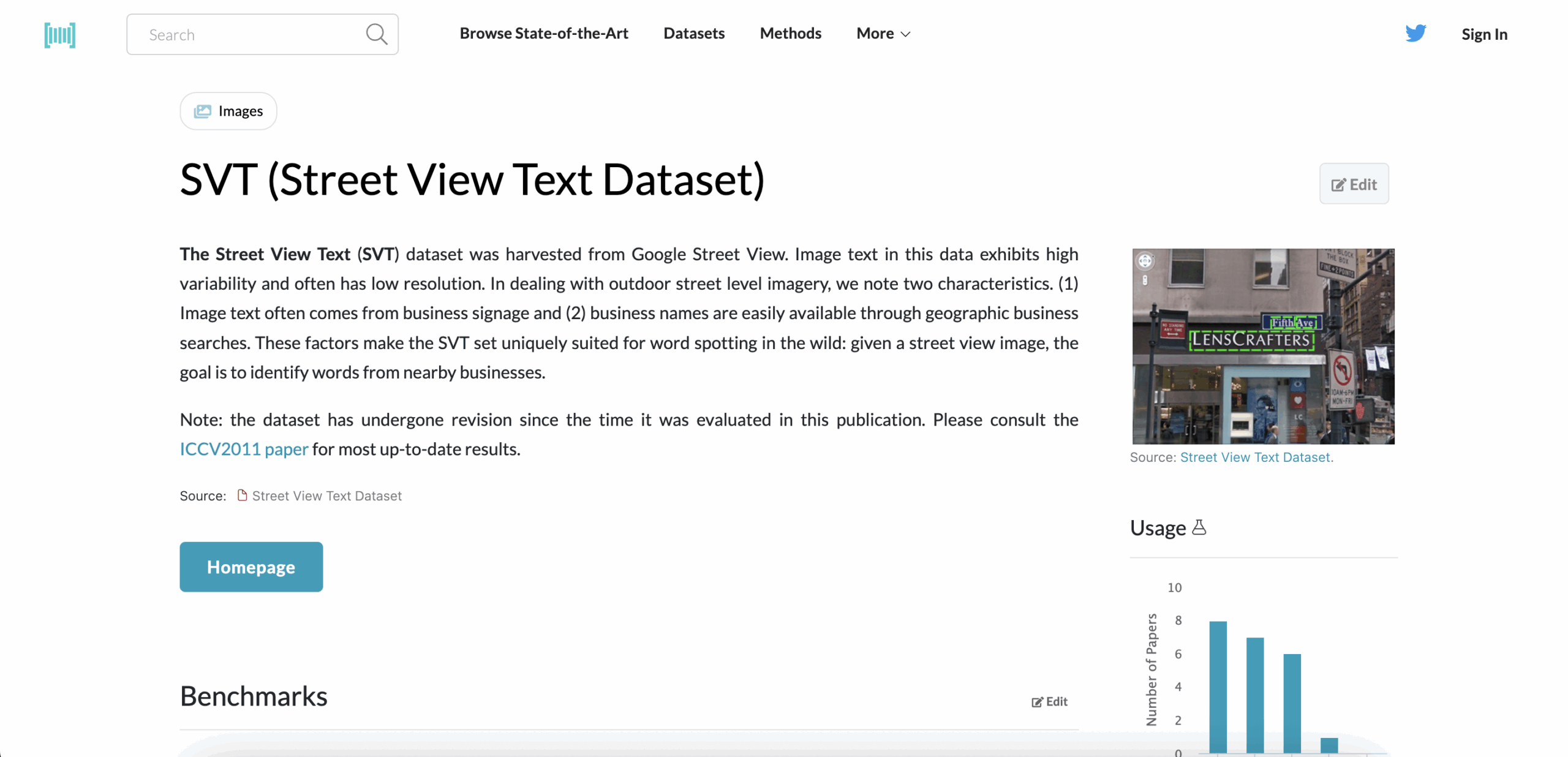
Type: Street sign words
Language: English
Volume: 647 images, 8,000+ words
Format: Scene text from Google Street View
Access: Free (commercial use permitted)
Annotations: Word crops, transcripts, location metadata
Pulled from Google Street View, SVT captures text as it really appears in public spaces — on signs, storefronts, and billboards. Ideal for building AR systems, mobile OCR apps, or smart navigation tools that read the environment on the fly.
🧾 Dataset Spotlight: Street View Text (SVT)
dataset_name: Street View Text (SVT)
type: Scene Text (street signs)
access: Free (commercial use permitted)
format: Natural image crops with bounding boxes and metadata
ideal_for: Scene text recognition, smart navigation, AR text detection
Final Takeaways
Handwriting comes in many forms — digits, sentences, scripts, symbols. The best dataset depends on what your model needs to learn. Start with clean data, match the format to your use case, and scale up from there. The right training set will do more for your system than any tweak downstream.
🗂️ Cheat Sheet: All 20 Handwriting Datasets
- dataset_name: MNIST
type: Digits
access: Free (commercial use permitted)
format: Offline scans (28×28)
ideal_for: Digit classification, baseline testing
- dataset_name: EMNIST
type: Digits + Letters
access: Free (commercial use permitted)
format: Offline
ideal_for: Digit-letter recognition, OCR training
- dataset_name: Chars74K
type: Characters
access: Free (commercial use permitted)
format: Offline (scene + hand-drawn)
ideal_for: Multilingual OCR, character classification
- dataset_name: HASYv2
type: Symbols
access: Free (commercial use permitted)
format: Offline (binary 32×32)
ideal_for: Math OCR, symbol classification
- dataset_name: IAM Handwriting Database
type: Words + Sentences
access: Free (academic only)
format: Offline scans
ideal_for: Full-line OCR, handwriting-to-text models
- dataset_name: RIMES
type: Documents, Sentences, Words
access: Free (academic only)
format: Offline (business letters)
ideal_for: French handwriting OCR, document modeling
- dataset_name: READ 2016
type: Full documents
access: Free (academic only)
format: Offline scans
ideal_for: Layout-aware OCR, archival transcription
- dataset_name: Bentham Dataset
type: Pages, Lines, Words
access: Free (via Transkribus platform)
format: Offline scans (manuscripts)
ideal_for: Historical OCR, digital humanities
- dataset_name: Saint Gall
type: Pages, Lines
access: Free (research use only)
format: Offline scans
ideal_for: Latin OCR, medieval script recognition
- dataset_name: Konzil and Patzig
type: Full documents
access: Paid / Restricted (project-based academic access)
format: Offline scans
ideal_for: Layout analysis, old German script OCR
- dataset_name: Digital Peter
type: Lines, Pages
access: Free (project-based open access)
format: Offline (digitized manuscripts)
ideal_for: Cyrillic cursive OCR, Slavic text recognition
- dataset_name: BRUSH
type: Online strokes
access: Free (commercial use permitted)
format: Stylus-tracked trajectories
ideal_for: Stylus input, behavioral biometrics
- dataset_name: DeepWriting
type: Online strokes
access: Free (research use only)
format: Pen trajectories
ideal_for: Stroke modeling, personalized handwriting
- dataset_name: CASIA-OLHWDB
type: Online strokes
access: Free (academic only)
format: Stylus-captured sequences
ideal_for: Chinese stroke recognition, handwriting input
- dataset_name: BanglaLekha-Isolated
type: Isolated characters
access: Free (commercial use permitted)
format: Offline scans
ideal_for: Bangla OCR, character classification
- dataset_name: BN-HTRd
type: Documents and words
access: Free (academic only)
format: Offline scans
ideal_for: Full-page Bangla OCR, layout-aware systems
- dataset_name: CASIA-HWDB
type: Characters (offline)
access: Free (academic only)
format: Offline scans
ideal_for: Chinese OCR, large vocabulary modeling
- dataset_name: HKR
type: Sentences
access: Free (research use only)
format: Offline scans
ideal_for: Multilingual OCR, script-switching recognition
- dataset_name: IIIT 5K-Word
type: Scene word crops
access: Free (commercial use permitted)
format: Cropped natural scene photos
ideal_for: Scene-text OCR, image word spotting
- dataset_name: Street View Text (SVT)
type: Street sign words
access: Free (commercial use permitted)
format: Scene text from Google Street View
ideal_for: AR navigation, street OCR