Client Request
The client—a major player in the classifieds space—sought to develop a message filtering system that could:
- Prevent the spread of inappropriate or restricted content
- Improve overall conversation quality on the platform
- Protect users from violations such as:
- Offensive or abusive language
- Personal data disclosure
- Negative or harmful speech
To achieve this, Unidata was brought in to annotate and validate the dataset, providing the foundation for a model that could reliably detect and categorize sensitive content.
Our Approach
-
- 01
-
Technical Requirements and Pilot Phase
The client provided a detailed technical brief outlining classification requirements. Our team proposed additional refinements to ensure a more precise and layered annotation process.
During the pilot phase, we collaborated closely with the client to:
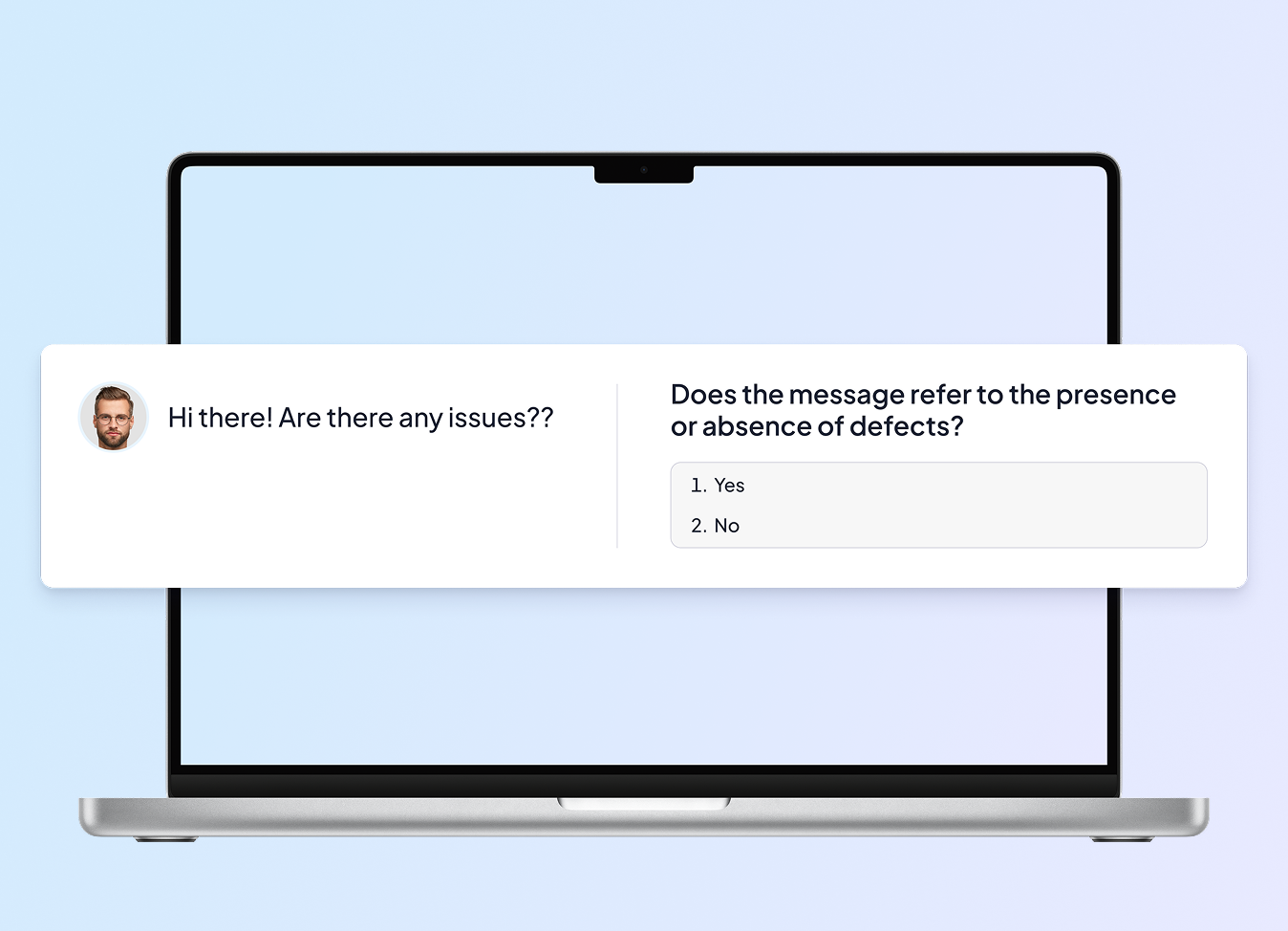
- Clarify classification rules for key categories, including:
- Insults and abusive language
- Mentions of personal information
- References to meeting arrangements
- Negative sentiment directed at the platform
- Address complex edge cases, such as:
- Implicit mentions of meeting locations (e.g., vague geographic references without full addresses)
-
- 02
-
Annotation and Quality Control Process
Our annotation team at Unidata handled classification by carefully considering:
- Platform-specific communication patterns
- Informal language use typical in peer-to-peer messaging
- The context of each message, not just isolated phrases
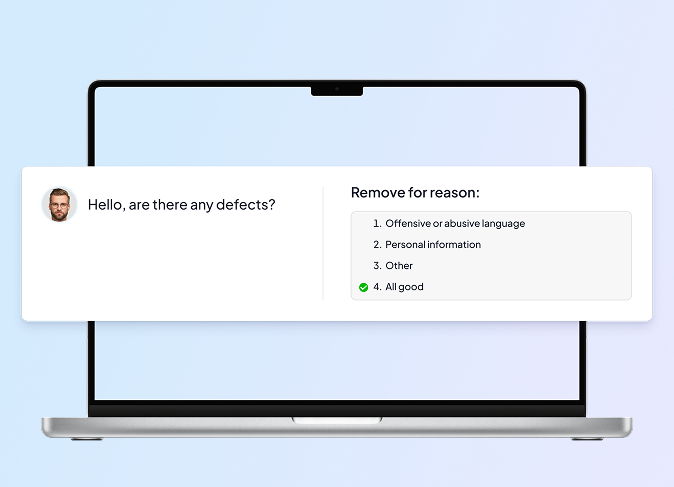
Messages were annotated across several primary categories:
- Use of profanities or slurs
- Disclosure of personal or sensitive information
- Various forms of direct and indirect insults
- Mentions of meeting points or negotiation outside the platform
-
- 03
-
Data Validation
To ensure the highest level of annotation accuracy, we implemented a robust validation workflow:
- Involved experienced validators to review annotated samples
- Introduced an interactive error analysis process, which included:
- Team discussions of edge cases
- Targeted surveys to refine judgment on difficult categories
We also conducted training and testing sessions with annotators focused on:
- Eliminating errors in high-complexity cases
- Aligning the team on annotation logic and edge-case handling
- Ensuring consistent interpretation of classification criteria
Results
The model trained on our annotated data was successfully tested and deployed on the client’s platform. Internal testing involved evaluating model performance against randomly selected user messages
The initial testing phase showed promising results:
- The model accurately blocked inappropriate or restricted content
- Responses remained contextually appropriate across various scenarios