
Quick Summary
Your model hits the word “cell.” Biology? Prison? Power source? That instant hesitation — that’s Word Sense Disambiguation (WSD) at work, steering context toward the right meaning.
It’s how machines figure out what a word really means — when it could mean ten different things. No labels, no cheat sheet. Just raw context and some serious linguistic logic.
This guide breaks it down: how WSD works, why it matters, and where it powers the tools you use every day.
What Is Word Sense Disambiguation?
Words lie. Or at least — they multitask.
“Crane” might be a bird. A machine. A neck movement. For us? Easy. We get the meaning from the sentence. For machines? Total guesswork — unless you give them WSD.
Word Sense Disambiguation is the process of teaching models to pick the right meaning of a word, based on context.
It’s one of the oldest problems in natural language processing — and still one of the most important. Without it, systems misfire. Translations go wrong. Searches fall flat. Chatbots sound weird.
In short: WSD is how machines stop sounding like machines.
Why Words Need Disambiguation
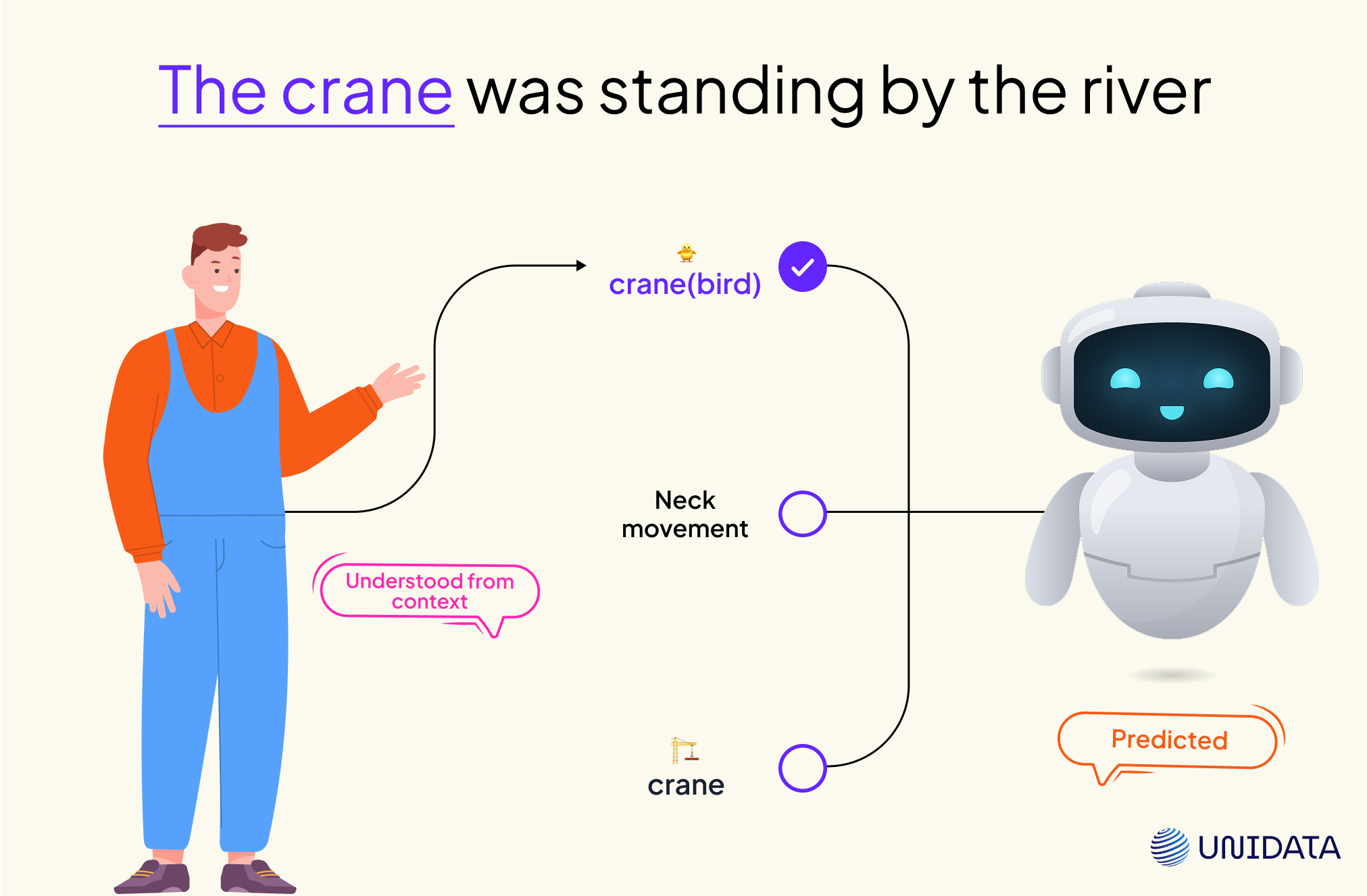
Because words are messy.
Take “charge.” It could mean: swipe your card, lead a team, or run toward someone yelling. Now imagine you're coding a voice assistant. Someone says: “She took charge.” Is she managing? Stealing? Attacking?
Without WSD, your system guesses. Badly. With it, it reads the room — and nails the intent.
That’s why WSD shows up in search (“Apple support” better know you mean tech, not fruit), translation (“suit” in “He filed a suit” isn’t about clothes), and chatbots (“I feel blue” needs emotional context, not a color palette).
Disambiguation isn’t just a bonus. It’s the difference between sounding smart and sounding lost.
How WSD Works: Step-by-Step
Let’s zoom in on what actually happens when a model encounters an ambiguous word. Think of it as a mini workflow — each step bringing it closer to the correct meaning.
1. Tokenization
First, the input sentence is broken down into individual tokens: words, punctuation, sometimes even subword units.
For example:
“She played the bass in a jazz band.” →
[She] [played] [the] [bass] [in] [a] [jazz] [band]

At this point, “bass” is just a string. The model doesn’t know if it’s a fish or an instrument — but it’s ready to find out.
Tokenization is basic — but critical. Models need clean input to align context windows and match known patterns.
2. Context Capture

Now the model turns its attention to the surrounding words. The goal is to collect clues that help narrow down the sense of the ambiguous token.
It zooms in on “played” and “jazz band” — words that scream music, not fishing. This context radically shifts the odds in favor of the “instrument” interpretation.
The model might also factor in:
- POS tags: “bass” is a noun
- Syntactic role: object of the verb “played”
- Collocations: “play bass” is a known phrase
If the sentence were “She caught the bass in a lake,” everything would shift — “caught” would activate fishing-related meanings instead.
This step is where linguistic signals meet real-world patterns.
3. Sense Inventory Lookup
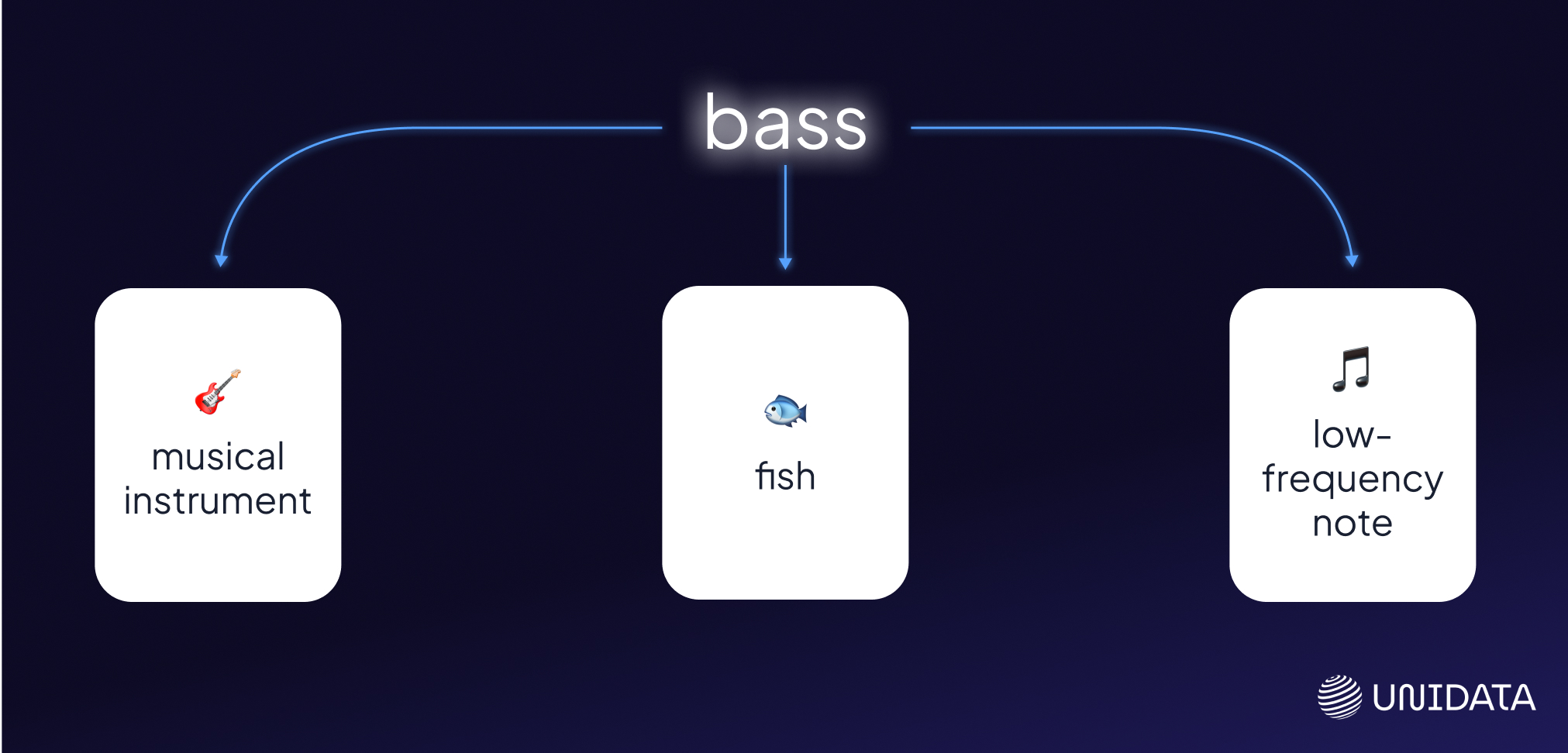
Now that context is in place, the system pulls all known meanings of “bass” from a lexical database.
For “bass,” it might pull:
- bass#1 – a low-frequency musical note
- bass#2 – an electric or acoustic instrument
- bass#3 – a type of freshwater fish
Popular sense inventories include:

- WordNet – classic, hierarchical, human-curated

- BabelNet – multilingual, broader coverage
- Custom glossaries – for industry-specific models
At this stage, the model knows the options — but not yet which one fits.
4. Scoring and Sense Ranking

Here’s the heart of the operation. The model evaluates how well each candidate sense fits the context, assigning each one a score.
In our example:
- “Played” overlaps semantically with musical glosses in bass#1 and bass#2
- “Jazz band” adds weight — this is strong domain evidence
- bass#3 (fish) scores poorly due to low overlap with musical terms
How it scores depends on the method:
- Knowledge-based models: Compare word overlap between context and sense definitions (“play” overlaps with music-related glosses).
- Supervised models: Learn from annotated data to link context with meaning. This includes classic classifiers and modern neural networks, which encode sentences and senses as vectors and compare them via cosine similarity or attention.
Some models even factor in global coherence — i.e., if multiple ambiguous words appear, does choosing certain meanings across the sentence make more sense as a whole?
5. Disambiguation Decision
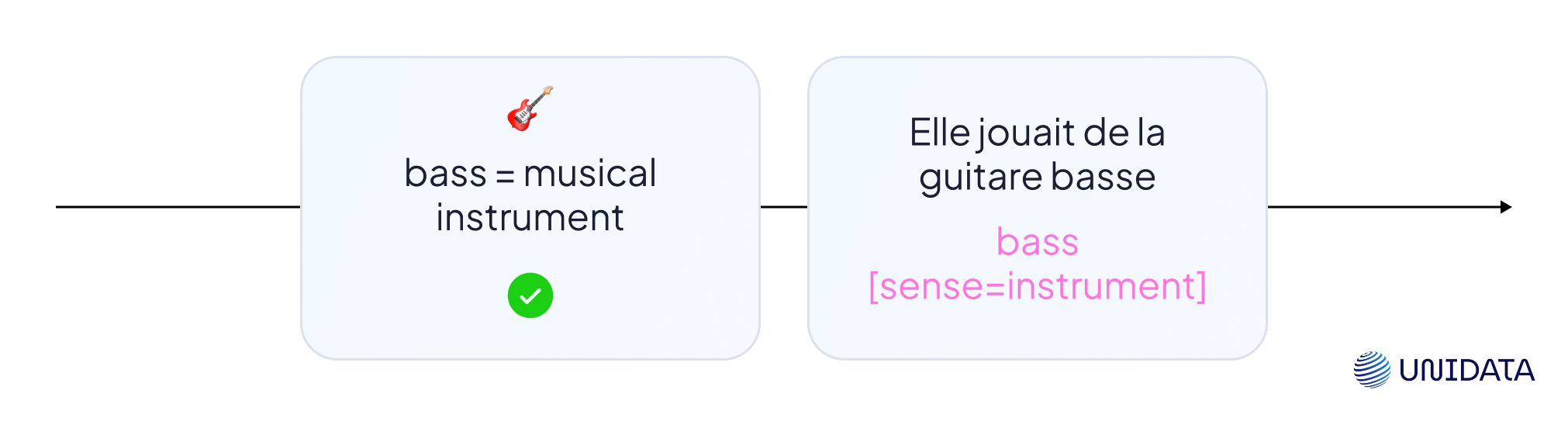
Finally, the system selects the top-ranked sense and moves on.
For “bass” in this sentence, the model selects:
bass#2 – a musical instrument
This result might be:
- Returned in a translation: “She played the guitare basse...”
- Used to annotate a corpus: bass [sense=instrument]
- Passed downstream to improve entity linking, music genre inference, or semantic search
If confidence was low (say, jazz band was missing), the system could fallback to:
- The most common meaning in training data
- A handcrafted rule like “If verb = play, default to instrument”
This entire pipeline happens in milliseconds — behind the scenes, every time your phone, assistant, or NLP app needs to know what you really meant.
Common WSD Techniques

Not all models approach WSD the same way. Over the years, NLP has thrown just about everything at this problem — some methods simple and intuitive, others deeply data-driven.
Here’s how the main families break down:
Knowledge-Based Methods
These use dictionaries, semantic networks, and rules — no training data needed. Think WordNet, BabelNet, or even Wikipedia. The model compares how semantically close the meanings are to the words around them.
Pros: transparent, no training data.
Cons: struggles with nuance and domain-specific use.
Supervised Methods
These treat WSD as a classic classification task. You feed the model labeled examples: “bass” in music context, “bass” in biology. It learns patterns and predicts the right sense on new inputs.
Pros: high accuracy with good data.
Cons: needs lots of annotated examples — which are expensive to get.
Unsupervised (and Semi-Supervised) Methods
These skip explicit labels. Instead, they cluster word usages based on how they appear across huge corpora. The model “notices” that “bass” near “guitar” acts differently than “bass” near “river.”
Pros: low maintenance.
Cons: fuzzier results, harder to evaluate.
Today, most production systems use a hybrid. A little world knowledge. A lot of training data. And a neural net or two to smooth the edges.
Key Challenges in WSD
WSD sounds neat in theory. In practice? It’s messy. Here’s what makes it hard — even for state-of-the-art models.
1. Ambiguity isn’t always obvious.
Some sentences don’t offer much to work with. “He sat by the bank.” That’s it. No river, no money, no clue. Humans can ask follow-ups. Models can’t.
2. Senses shift with domain.
Take “deposition.” In geology, it’s about sediment. In law, it’s a witness statement. In pharma, it’s about how drugs settle in the body. Same word. Wildly different realities.
3. Dictionary senses ≠ real-world use.
Most databases break words into dozens of micro-definitions. But real people don’t think that way. They blend meanings. They invent new ones. WSD models have to cope with that fuzziness.
4. Data is limited and skewed.
Supervised WSD needs labeled examples for each sense — but those are hard to come by. And even when you get them, they’re often biased toward formal, well-edited text.
Bottom line? Context isn’t just king — it’s chaos. And WSD models have to make sense of it.
Real-World Use Cases
WSD might sound academic — but it powers systems you probably use every day. Here’s where it shows up behind the scenes.
Search Engines

Type “Jaguar speed” into Google. You could mean the car or the animal. Disambiguation helps pick the right results.
Machine Translation

In French, “batterie” can mean drums or a battery. Without WSD, a sentence like “he charged the batterie” could come out hilariously wrong.
Voice Assistants

When you say “play bass sounds,” Alexa needs to know you don’t mean fish noises. WSD keeps commands coherent.
Information Extraction

News scanners and legal bots often run entity extraction. They need to know whether “suit” means a person, clothing, or a legal action — fast.
Chatbots and Virtual Agents

When users say things like “I need a light fix,” your bot better not recommend therapy for depression if they’re just talking about a lamp.
Wherever language gets tricky — WSD is there, keeping meaning sharp.
WSD vs. Similar NLP Tasks
Word Sense Disambiguation often gets mistaken for other NLP tools — but it solves a different problem. While POS tagging, NER, and coreference focus on structure and reference, WSD is all about meaning.
POS tagging tells you what kind of word you’re dealing with — noun, verb, adjective. For example, “light” as a noun. But it won’t say which noun: a lamp or something not heavy? WSD makes that call.
Named Entity Recognition identifies names of people, places, and companies — like spotting that “Apple” is a brand. But if the word isn’t capitalized, or it’s used metaphorically, NER may miss it. WSD still kicks in and asks: fruit or tech?
Coreference resolution links words like “he” or “it” back to earlier mentions. But it doesn’t care about the sense of the word — just that it refers to the same thing. WSD, meanwhile, zooms in on what exactly that thing is in context.
In short:
- POS = grammatical type
- NER = named thing
- Coref = who’s who
- WSD = what does this word mean
They’re not rivals — they’re teammates. But WSD’s the one doing the semantic heavy lifting.
Best Tools and Libraries
You don’t need to build WSD from scratch. There’s a small but mighty stack of libraries and APIs that do the heavy lifting:

NLTK (Python)
Includes a basic Lesk algorithm implementation. Great for learning and quick tests, but not production-grade.
pyWSD
An extended WSD toolkit for Python, built on top of NLTK. Offers multiple algorithms and dictionary options.

Babelfy
A powerful multilingual API by the creators of BabelNet. It combines entity linking and word sense disambiguation, using semantic graphs. Works surprisingly well out of the box.
UKB
A knowledge-based WSD system using graph algorithms and WordNet. Old-school but respected in academia.
Most modern NLP stacks (think Hugging Face, spaCy) don’t focus on WSD directly — but you can plug in these tools when you need semantic precision.
What’s Next for WSD?
The future of WSD isn’t in bigger dictionaries. It’s in a smarter context.
Large Language Models (LLMs) like GPT and BERT already perform WSD implicitly. They don’t need to look up word senses — they feel them, based on billions of examples. When fine-tuned, they can rival (and often beat) traditional disambiguation tools without even being told they’re doing WSD.
But the catch? It’s hard to see why they chose a meaning. No scores, no graphs, no rules — just a giant black box of language intuition.
That’s why hybrid models are gaining ground: deep neural nets with explainable layers. Graph-based WSD with transformer features. Contextual embeddings with symbolic fallback. The goal? Smarts and control.
Expect to see WSD pop up more often in niche NLP pipelines — especially in low-resource languages, legal-tech, healthcare, and anything where misunderstanding a word could cost more than just embarrassment.
Final Takeaways
Word Sense Disambiguation may sound niche, but it quietly powers smarter search, cleaner translation, and more human-like conversations. If your NLP system deals with ambiguous words — and most do — WSD helps cut through confusion and deliver clarity where it matters.
Start small: test Babelfy, explore pyWSD, or fine-tune a transformer for your domain. You don’t need perfection — just enough precision to stop sounding robotic.
When your system understands not just words, but which words mean what — that’s when it starts to sound smart.
Frequently Asked Questions (FAQ)
Yes. LLMs can disambiguate implicitly, but they’re not always consistent — and hard to interpret.
Not always. Knowledge-based tools like Babelfy work without supervision.
Definitely. Tools like BabelNet and Babelfy support multilingual disambiguation.
In tasks where ambiguity can break the output — like search, translation, voice interfaces, or domain-specific NLP.










