
OCR explained—from history to AI breakthroughs. Learn how Optical Character Recognition works, its types, benefits, and cutting-edge use cases across industries. Discover the future of OCR powered by AI and LLMs.

1. Introduction: Why OCR is the Hidden Hero of the Digital Age
Let’s start with a quick thought experiment. Imagine a world where every receipt, contract, form, or handwritten note had to be manually typed into a computer. Even in our hyper-digital age, this isn’t far-fetched—many organizations still sit on decades of paper records. That’s exactly where OCR (Optical Character Recognition) shines. It’s the unsung hero that reads, understands, and digitizes printed and handwritten text, effectively turning paper into searchable, analyzable data.
Understanding it is not only essential for data scientists but also for businesses aiming for seamless automation.
2. A Brief History: From Manual Typing to Machine Vision
OCR’s story goes back over a century—and trust me, it’s far from boring. Its origins can be traced to the early 1900s when telegraph operators needed machines to read and interpret Morse code automatically. The first serious OCR system was patented in 1929 by Gustav Tauschek, a German engineer. His mechanical system could "read" printed text using templates and matching techniques—primitive, but groundbreaking for its time.
Fast forward to 1974, and Ray Kurzweil introduced a reading machine for the blind, marking the first real commercial success for OCR. By the 1990s, with businesses scrambling to digitize records, OCR cemented its place as a core automation tool. The arrival of deep learning in the 2010s turbocharged its accuracy, allowing OCR to handle messy handwriting, distorted scans, and even multilingual content.

3. How OCR Works: Peeking Under the Hood
Optical character recognition might seem like magic, but under the surface, it’s a carefully orchestrated process. Modern OCR combines computer vision, machine learning, and language modeling, making it a tech cocktail worth understanding.
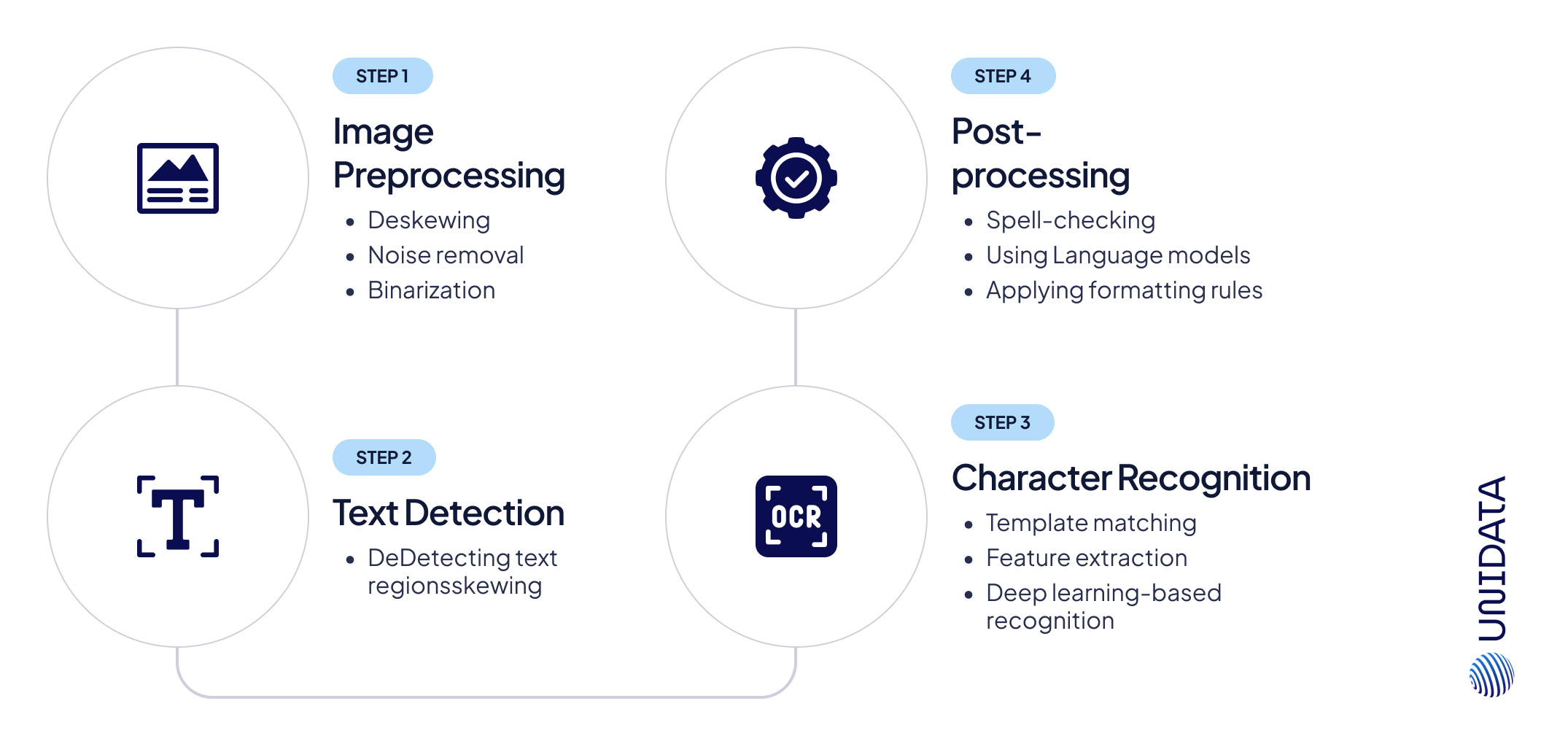
Step 1: Image Preprocessing – Cleaning the Input
OCR works best with clean, high-quality input, but real-world documents are rarely perfect. They might be skewed, faded, or noisy. To compensate, OCR systems use:
- Deskewing: Aligning the document properly if it was scanned at an angle.
- Noise removal: Getting rid of smudges, stains, and speckles that might interfere with recognition.
- Binarization: Converting color or grayscale images into a simple black-and-white format for sharper contrast.
However, no amount of preprocessing can fully recover text that has been severely degraded, handwritten in poor quality, or obstructed by stains. This is where human annotation reinforces OCR’s effectiveness.
Step 2: Text Detection – Finding What to Read
OCR doesn’t read everything blindly; it first detects text regions within the image. This step is crucial for handling:
- Documents with tables, stamps, or mixed text formats.
- Handwritten annotations alongside printed text.
- Complex layouts (multi-column PDFs, receipts with logos, etc.).
OCR systems use deep learning models like EAST and CRAFT to locate text regions, but these models can miss handwritten notes, misalign words, or incorrectly segment multi-column content.
Step 3: Character Recognition – Reading the Text
This is where the real challenge begins. OCR models recognize characters using:
- Template matching (comparing scanned characters to known fonts).
- Feature extraction (analyzing shape patterns to recognize text).
- Deep learning-based recognition (like CRNNs, which handle sequential dependencies).
Yet, OCR still struggles with:
- Handwriting variations (e.g., cursive vs. block letters).
- Lookalike characters (e.g., O vs. 0, l vs. I, 5 vs. S).
- Uncommon symbols or mixed languages.
Even the most advanced optical character recognition models can misinterpret rare symbols or handwritten text, especially in legal, financial, and medical documents.
Step 4: Post-processing – Cleaning the Output
Even after OCR extracts text, errors still slip through. That’s why post-processing applies:
- Spell-checking to fix common OCR mistakes.
- Language models to predict missing words or fix contextual errors.
- Formatting rules to maintain document structure (like keeping phone numbers or dates intact).
Yet, post-processing isn’t foolproof—OCR doesn’t always understand what it’s reading. It might misplace decimal points in invoices, swap words in legal contracts, or break structured tables into unreadable text blocks.
In cases where OCR errors can cause serious business consequences (e.g., incorrect billing or misfiled legal records), human reviewers validate the output.
Training OCR Models: The Role of Manual Annotation
OCR models don’t learn automatically—they must be trained with high-quality, manually labeled datasets. Here’s how the training process works:
1. Creating Ground Truth Data
OCR models need millions of training examples covering different:
- Fonts, text sizes, and styles.
- Languages.
- Handwriting variations.
Manual annotators type out and align the text from images, creating a dataset that the OCR model uses to learn.
2. Correcting OCR Mistakes for Continuous Learning
OCR models continue learning after deployment by incorporating real-world corrections from human reviewers.
Manual annotation fixes:
- Misinterpreted characters (e.g., “O” vs. “0”).
- Unrecognized handwriting (manual transcription feeds new samples into the model).
- Errors in structured data (e.g., misreading table headers).

Case Studies from Our Projects
Manual annotation for optical character recognition is not just about recognizing text—it involves handling poor image quality, overexposed or faded scans, and difficult-to-read handwritten text. Below are key real-world projects where our team tackled complex annotation challenges, ensuring high-quality OCR model training and document digitization.
Case 1: Invoice Annotation
Invoices should be straightforward, but in reality, they come in all shapes and sizes—printed, handwritten, mixed-language, and often completely unstructured. In this project, we manually labeled key details such as the contracting party, the associated company, the second party within the invoice, and the services provided.
The challenge? Every invoice looked different, with no standardized format. Some contained handwritten notes that were barely legible, while others featured Chinese characters alongside English text, requiring careful verification to ensure accuracy. Since OCR struggles with handwriting and unfamiliar scripts, we manually identified and categorized these elements, ensuring a clean dataset for future automation.
In some cases, external factors—like ink smudges or coffee stains—made the text nearly unreadable. Our careful annotation ensured that no critical information was lost, allowing businesses to later automate invoice processing with confidence.
Case 2: Annotation of Legal Contract Documentation
Legal document annotation presented an entirely different challenge. Contracts are dense, filled with legal jargon, and every clause matters. Our task was to manually identify and classify nearly hundred different legal entities, ensuring that contractual elements were clearly defined and aligned with legal norms. Instead of making legal teams sift through massive agreements to find critical clauses, our annotation work allowed OCR systems to later recognize and extract key terms automatically.
One major focus was on liability limitation clauses—these had to be precisely labeled so that businesses could quickly identify risk factors without combing through entire contracts. Our work made it possible for companies to streamline contract reviews, ensuring that crucial legal terms were always accounted for.
Document Annotation for Financial Services
- Financial Industry
- 6,000 documents, 20 task types
- Ongoing project
Case 3: Annotation of Customer Complaints
Customer complaints were another tricky area. We started annotation directly from raw, unstructured documents, meaning we had to deal with all sorts of formatting inconsistencies right from the start. The goal was to help businesses automate complaint logging and categorization, making it easier to track issues over time.
Here’s how the manual annotation works in CVAT:
First, you outline the region for annotation.
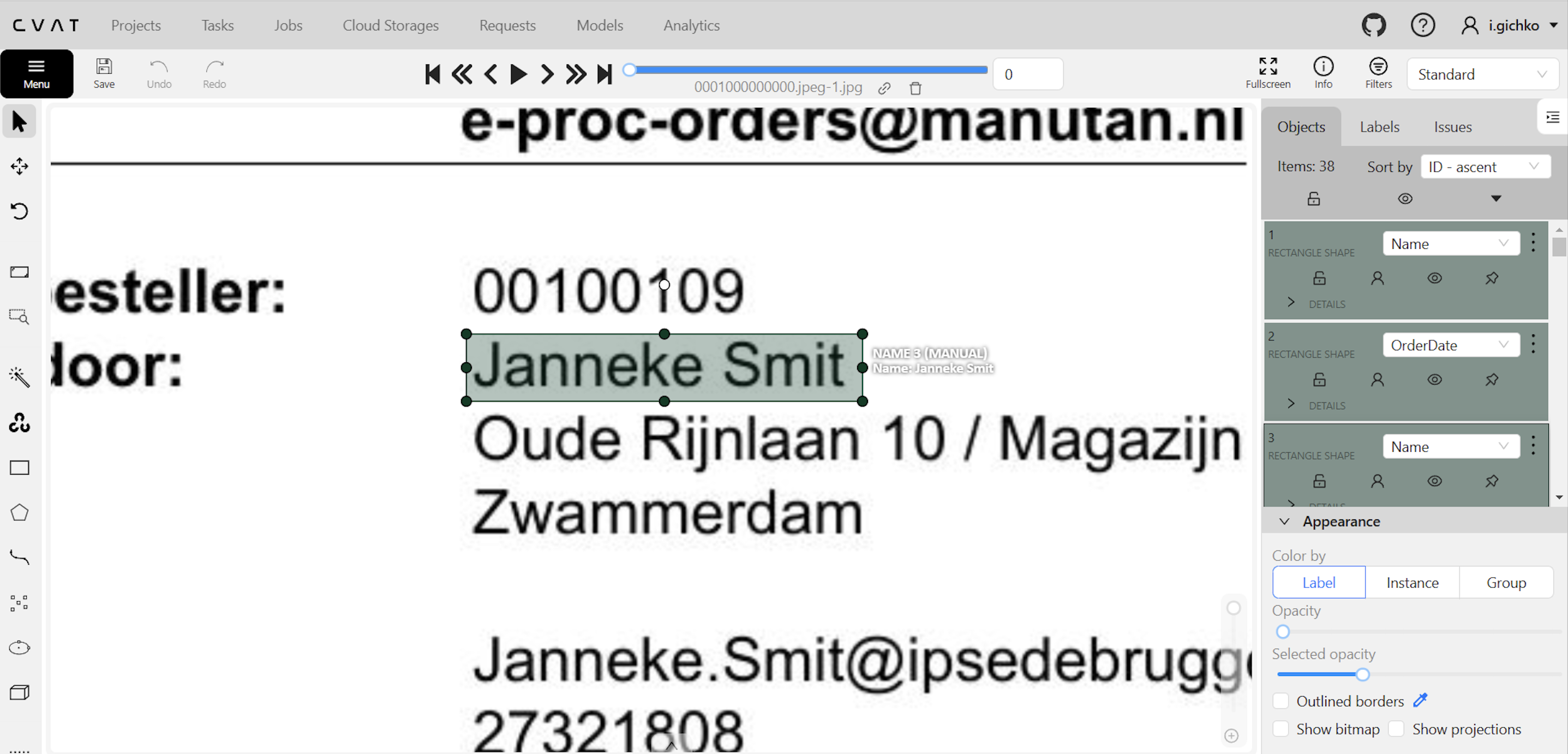
Then fill in the text in the form.
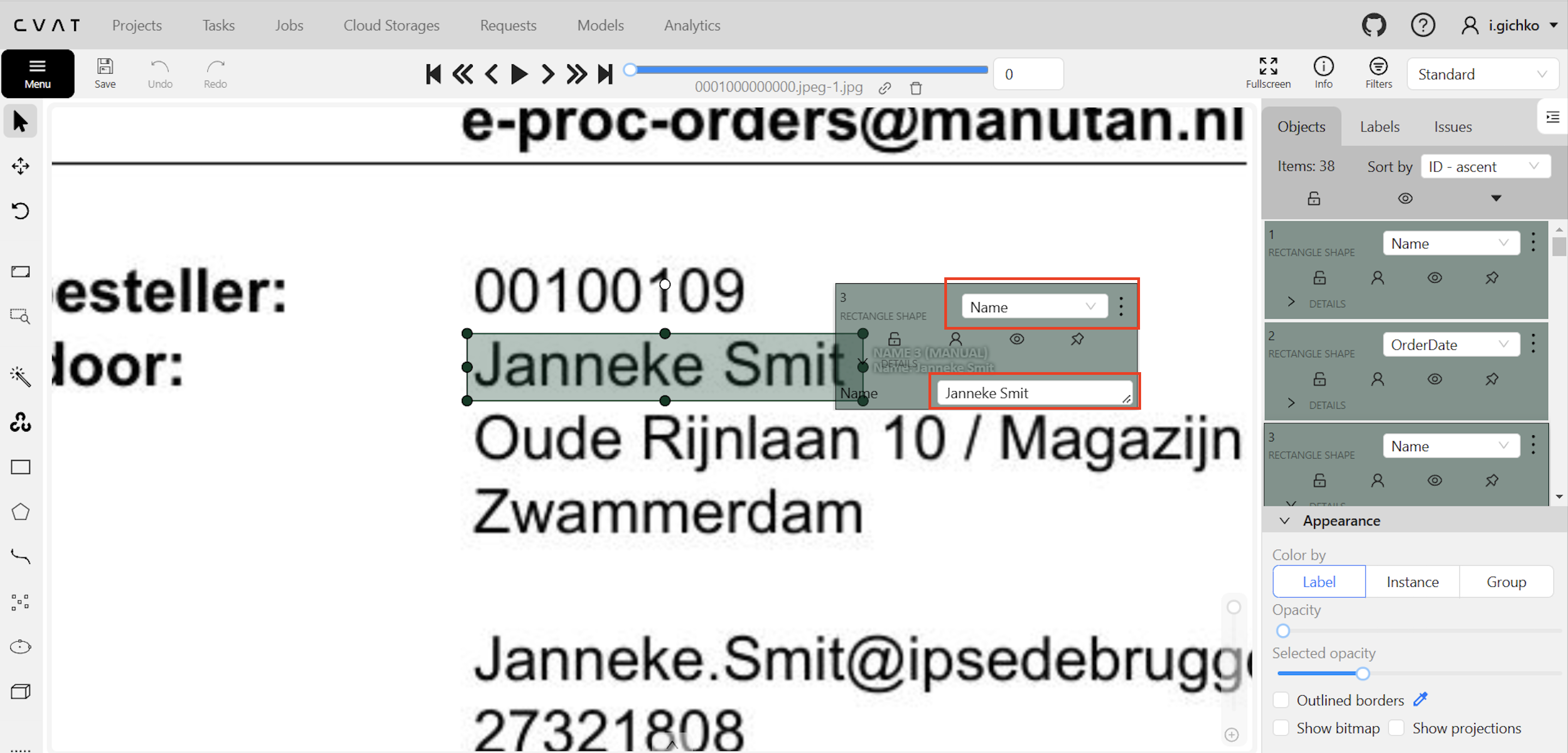
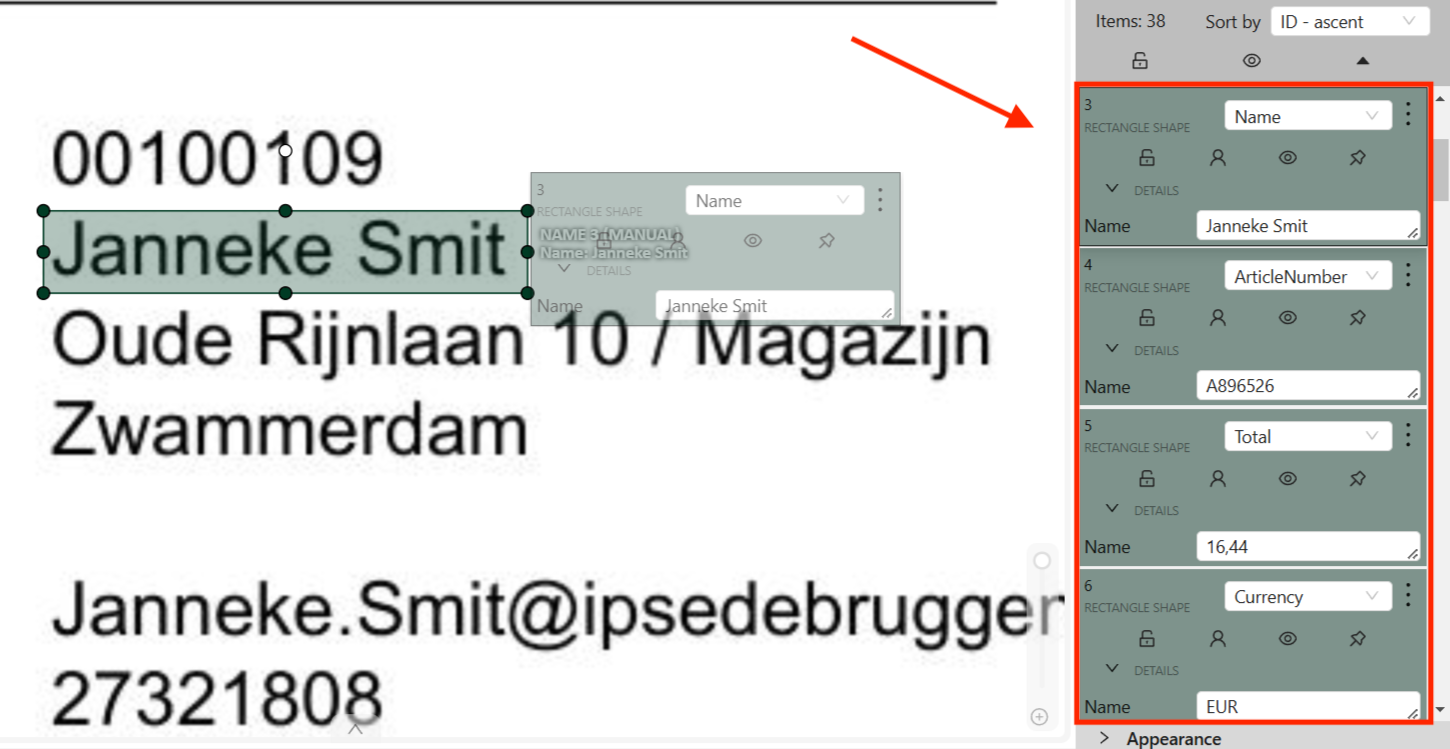
On the right, you can see the way text data is stored in the tool.
4. Types of OCR: Beyond Simple Text Extraction
OCR isn’t one-size-fits-all. Depending on the document type, different OCR methods ensure efficient and accurate text extraction.
Full Page OCR – Scan Everything, No Questions Asked
Full Page OCR captures all text within a document, making it ideal for bulk digitization of books, legal archives, and historical records. It ensures that everything is preserved in a searchable format, which is essential for libraries and legal firms managing large document collections.
However, it lacks precision when dealing with structured documents like invoices or bank statements. Since it extracts all text without distinguishing key sections, additional processing is often required to organize and validate the data.
Best for: Large-scale document digitization.
Limitations: Extracts all text but doesn’t differentiate structured data.
Zonal OCR – Targeted Data Extraction
Zonal OCR focuses on specific sections of a document rather than reading everything. It is widely used in invoice processing, ID verification, and application forms, where only key fields—such as names, dates, or totals—need to be captured.
For example, businesses processing thousands of invoices use Zonal OCR to extract just the invoice number, amount due, and date, avoiding unnecessary text clutter. Similarly, hospitals use it to pull patient names and test results from medical reports without capturing unrelated details.
Best for: Extracting specific data from structured documents like invoices, forms, and bank statements.
Limitations: Requires predefined templates, making it less flexible for varied layouts.
ICR (Intelligent Character Recognition) – Reading Handwriting
ICR takes OCR a step further by recognizing handwritten text, an area where traditional OCR struggles. It is commonly used in banking for check processing, healthcare for digitizing prescriptions, and government agencies for transcribing handwritten forms.
However, handwriting varies greatly, making ICR less reliable than printed text recognition. A single cursive stroke or a hurriedly written letter can lead to errors, requiring human validation in high-stakes applications like medical data processing.
Best for: Processing handwritten documents, checks, and prescriptions.
Limitations: Accuracy depends on handwriting clarity; may require human verification.
OMR (Optical Mark Recognition) – Detecting Marks, Not Text
OMR isn’t about recognizing characters—it’s about detecting filled-in bubbles, checkboxes, or marks. It’s commonly used in standardized tests, surveys, and voting ballots, where users indicate choices rather than writing words.
Unlike traditional OCR, OMR can quickly process large volumes of forms, ensuring fast and accurate results. However, it requires clean, structured formatting—poorly filled bubbles or stray marks can cause misinterpretations.
Best for: Exam sheets, surveys, and structured forms with checkboxes.
Limitations: Can’t interpret text, only detects selections. Needs clean, standardized formatting.
| OCR Type | Best For | Limitations |
|---|---|---|
| Full Page OCR | Capturing all text in books, legal documents, archives | Extracts everything, lacks structured data precision |
| Zonal OCR | Extracting key details from invoices, forms, and structured documents | Requires predefined templates, struggles with unstructured layouts |
| ICR (Handwriting OCR) | Processing handwritten text in checks, prescriptions, and forms | Less accurate than printed text OCR, struggles with messy handwriting |
| OMR (Mark Recognition) | Detecting checkmarks and selections in exams, surveys, and ballots | Can’t read text, only detects filled marks, needs clean formatting |
5. Benefits and Limitations: OCR's True Colors
OCR is undeniably powerful, but it’s not all rainbows. Let’s break down the pros and cons.
Benefits
- Automation and Cost Savings: Reduces manual data entry drastically.
- Data Unlocking: Makes previously trapped paper data searchable.
- Language Agility: Modern OCR supports multi-language text, even mixed within a document.
- Scalability: Processes millions of documents quickly.
Limitations
- Quality Dependency: Poor scans or unconventional fonts cause headaches.
- Context Blindness: OCR sees characters, not meaning (though NLP integration is improving this).
- Handwriting Challenges: Even the best ICR struggles with illegible handwriting.
- Privacy Concerns: OCR applied to sensitive documents raises data protection risks.
Real-World OCR Failure Stories: Why It’s Not Always Perfect
While OCR has revolutionized industries by automating text extraction, real-world cases often reveal its shortcomings, especially when dealing with historical documents, low-quality scans, and multilingual texts. These stories highlight why human intervention and AI-driven enhancements are still crucial.
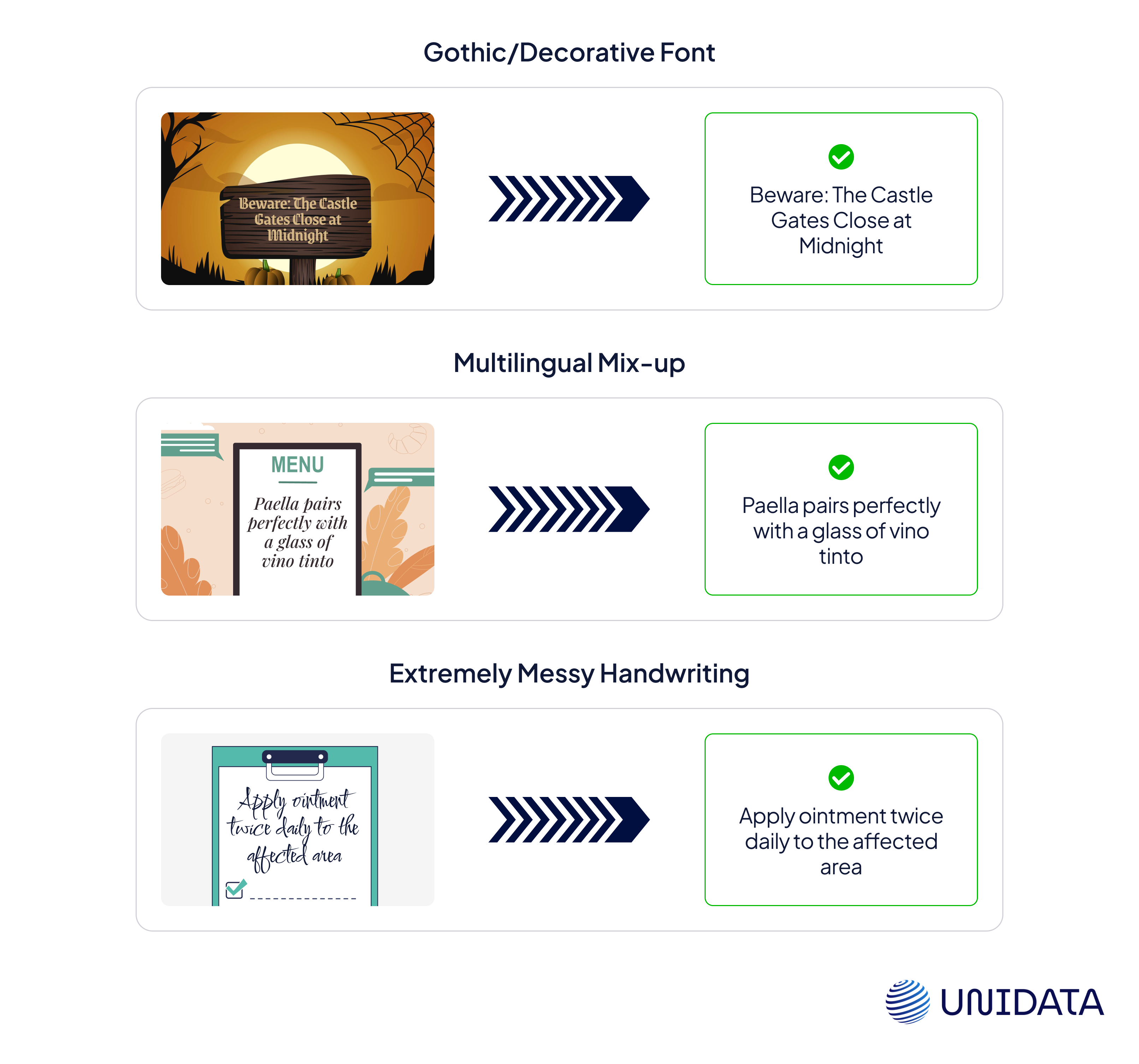
The Curse of Ancient Handwriting
Digitizing old books and legal records is where OCR meets one of its toughest challenges. Elaborate handwriting, faded ink, and obsolete letterforms confuse standard OCR models, leading to bizarre misreads. For example, in a 19th-century legal records project, OCR mistook nearly 40% of characters, misreading the long "s" (ſ) as "f" and failing to recognize ligatures. Instead of "House of Lords," the output read "H0ufe 0f L0rds", rendering the text almost useless.
To fix this, manual annotators labeled thousands of misrecognized characters, training OCR on historical fonts like Blackletter and Fraktur. AI-assisted handwriting reconstruction further helped smooth inconsistencies before recognition, significantly boosting accuracy. With these refinements, the OCR system adapted to old scripts, reducing errors and making historical texts searchable and readable.
The Grocery Receipt Disaster
Retail OCR struggles with receipts, which vary in formatting, fonts, and abbreviations. One frustrated customer in France scanned a receipt for expense reimbursement, only for OCR to misread "3x Baguette" as "38 Aguette." In another case, column misalignment caused a discount to apply to the wrong item, leading to incorrect totals, small errors that can cause financial discrepancies in accounting automation.
To solve this, pre-trained receipt parsers were introduced, trained on thousands of receipts to recognize common item names and pricing structures. LLMs were also integrated to infer product categories, correct brand names, and align numerical values properly, reducing error rates and ensuring receipts were digitized accurately.
The Multilingual Mess-Up
OCR is great for single-language documents but struggles when multiple languages are mixed. In one government digitization project, OCR failed to distinguish between surnames and visa categories in bilingual passports, leading to thousands of misfiled records. In another case, OCR mistakenly translated "Gift" (which means "poison" in German) as an English word, creating a serious translation error.
The fix involved a hybrid OCR + AI approach, where LLM-powered models detected language shifts dynamically and applied the correct dictionaries in real-time. This method improved accuracy by over 25%, ensuring that bilingual documents were processed correctly without critical misinterpretations.
Why OCR Needs Help
OCR is powerful but far from perfect—struggling with historical handwriting, messy receipts, and multilingual texts. Without manual annotation, errors persist, from misread characters to misclassified data.
Human reviewers correct OCR mistakes, retrain models, and validate extractions, ensuring continuous improvement. However, even with manual intervention, OCR still lacks true contextual understanding—it recognizes text but doesn’t fully grasp its meaning. Enter AI-powered enhancements like LLMs, which bring context-awareness, helping OCR correct errors, understand structure, and improve accuracy.
OCR in the Age of LLMs: Can GPT-like Models Boost OCR Accuracy?
OCR has always been about recognizing characters, but what if it could also understand what it’s reading?

Think about it: OCR sees words, but it doesn’t "know" what they mean. This often leads to classic errors, such as confusing similar-looking characters like “1” and “l” or “O” and “0.” It also struggles with abbreviations, sometimes misreading "Dr." as "Drive" instead of "Doctor." When faced with complex documents, OCR can misinterpret structure, failing to distinguish between headings, footnotes, and tables.
Now, enter LLMs + OCR—a dynamic duo that drastically improves accuracy by adding context. LLMs provide contextual error correction, meaning that if OCR misreads “1ntelligent Recognit1on,” the model can infer that the correct phrase should be "Intelligent Recognition." They also enhance multi-language support, detecting shifts within a document and predicting translations, even when OCR struggles with low-quality scans.
Beyond that, LLMs introduce semantic awareness, allowing OCR to understand meaning rather than just recognizing characters. For example, they can distinguish between “Washington” as a city and “Washington” as a last name based on the sentence structure. Similarly, structural interpretation improves, enabling OCR + LLMs to recognize that “Table 1: Revenue Report” refers to a data table rather than plain text, making document parsing more reliable.
Real-world impact? This combo is already being used in:
- Legal document processing: Identifying case numbers, contracts, and legal references accurately.
- Medical OCR: Recognizing medication names, even with bad handwriting.
- Financial reports: Detecting numerical inconsistencies using language-based reasoning rather than just OCR output.
6. Use Cases Across Industries: OCR in Action
OCR isn’t some niche technology hiding in the back office. It’s actively transforming industries, from retail to healthcare. Let’s explore.
Banking & Finance – The Paper Killer
OCR automates:
- Check processing
- KYC document verification
- Loan application data capture
Healthcare – From Forms to Insights
Medical records, prescriptions, lab reports—OCR digitizes patient data, feeding it into EHR systems for faster, safer care.
Legal & Government – Archiving at Scale
From digitizing court records to processing immigration forms, OCR turns paper mountains into searchable digital archives.
E-commerce & Retail – Invoice and Receipt Power
Every invoice and delivery note gets OCR’d, feeding into accounting systems without human touch.
Interesting Fact: Google Books used OCR to digitize over 40 million books, making literature from centuries past available to everyone.
Final Thoughts: OCR is Evolving—Are You Keeping Up?
OCR started as a glorified scanner. Today, it’s a sophisticated AI-powered system blending computer vision, NLP, and machine learning to read documents smarter, faster, and more accurately. And tomorrow? Expect OCR to understand document context, adapt to new fonts and languages instantly, and maybe even predict missing text.
OCR might not be glamorous, but in a data-driven world, it’s essential. If you’re a data scientist, mastering OCR will make you indispensable in document-heavy industries. If you’re a business leader, deploying smart OCR could unlock data goldmines hiding in your archives.










