
In the realm of machine learning (ML), datasets are like the foundation of a skyscraper—everything rests upon their strength and structure. Without quality data, even the most sophisticated algorithms falter. Machine learning thrives on patterns and insights derived from data, making datasets pivotal for model accuracy, performance, and reliability.

But why does data matter so much? The quality of data directly impacts how well a model learns and generalizes. Imagine training a model with incomplete or irrelevant data—it’s like teaching a child with mismatched flashcards. This article will explore the nuances of datasets in ML, from their types to their transformation into actionable insights.
Understanding Datasets in Machine Learning
What is a dataset? At its core, a dataset is a collection of data points structured to be analyzed or processed. Think of it as a giant spreadsheet where rows represent individual entries and columns denote features.

Datasets can take many forms:
- Structured data: Organized in tables, such as sales records or customer databases.
- Unstructured data: Information like images, audio files, or social media posts, lacking a predefined format.
- Semi-structured data: Falling between the two extremes—think of JSON or XML files.
Real-world examples showcase the versatility of datasets:
- In healthcare, electronic health records (EHR) and imaging data fuel diagnostic tools.
- In finance, stock market datasets drive predictive algorithms.
- In e-commerce, purchase histories and reviews refine recommendation systems.
Every ML project typically uses the data as:
- Training data: The lifeblood of a model, training data allows algorithms to identify patterns. For instance, a spam filter learns email characteristics using tagged samples.
- Validation data: Often overlooked, this dataset fine-tunes model parameters, ensuring it’s neither underfitting nor overfitting.
- Test data: The ultimate judge of a model’s success, test data evaluates how well a model performs on unseen data.
Key Characteristics of High-Quality Datasets
Not all datasets are created equal. High-quality datasets exhibit:
- Completeness: Missing data leads to blind spots in predictions.
- Consistency: Data free from contradictions ensures smoother training.
- Accuracy: Faulty data introduces bias and errors.
- Relevance: Irrelevant data bloats models without adding value.
- Volume: While more data is generally better, it must be representative of the problem domain.
Imagine building a chatbot using inconsistent conversational data—it would lead to nonsensical responses, underscoring the importance of quality.
Dataset Size and Its Impact on Model Performance
Bigger datasets often translate into better models, but there’s a catch. Beyond a certain point, the returns diminish. For example, in natural language processing (NLP), models like GPT-3 are trained on massive datasets, but smaller, curated datasets can outperform if well-aligned with the task.
In computer vision, small datasets augmented with transformations (like flipping or cropping images) can mimic larger sets, achieving remarkable results.
How to Choose a Dataset
Choosing the right dataset is critical for the success of a machine learning project. Follow these steps to ensure an optimal choice:
- Define Your Problem Statement
Clearly outline the problem your model aims to solve—whether it’s classification, regression, or clustering. Ensure the dataset aligns with the task. For example, object detection tasks require annotated images with bounding boxes. - Evaluate Dataset Quality
- Completeness: Verify that all relevant features are present.
- Accuracy: Ensure the data has minimal errors or inconsistencies.
- Consistency: Avoid datasets with conflicting information.
- Relevance to Your Objective
Use datasets closely related to your project domain. For instance, a healthcare model might need patient records like MIMIC-III, while e-commerce recommendation systems benefit from Amazon or Instacart datasets. - Dataset Size and Diversity
Ensure the dataset size matches the complexity of your task. Larger datasets with diverse samples reduce overfitting and improve generalization. - Understand Licensing and Compliance
Check if the dataset permits commercial use and complies with regulations like GDPR or HIPAA if personal data is involved. - Consider Preprocessing Needs
Review how much cleaning or transformation the dataset requires. Time spent on preprocessing could affect project timelines. - Check for Domain-Specific Attributes
Look for datasets offering unique attributes critical to your domain. For example, finance datasets might include market trends or sentiment analysis scores. - Explore Community Support and Documentation
Datasets with active communities or comprehensive documentation reduce the learning curve and troubleshooting time. - Perform Exploratory Data Analysis (EDA)
Conduct an initial analysis to identify missing values, outliers, or imbalanced classes. - Test for Scalability
Choose datasets that can scale with your project’s growth. For instance, consider datasets that can integrate additional features or expand geographically.
How to Prepare a Dataset?
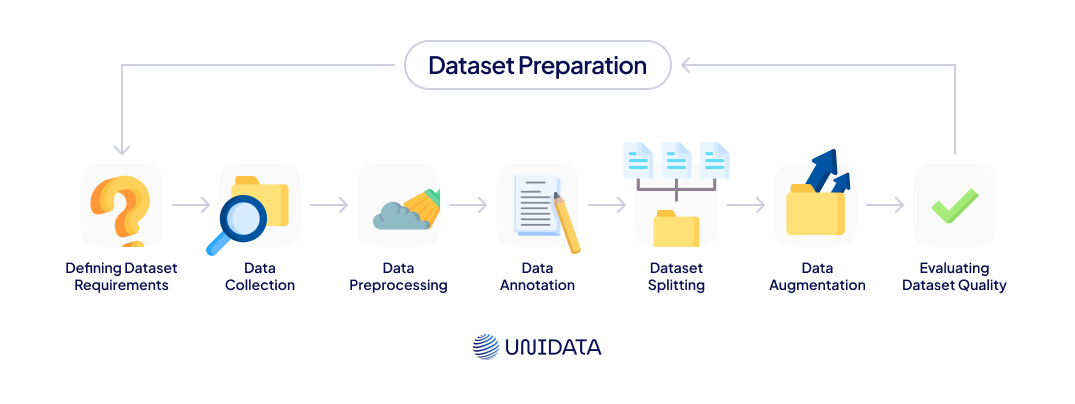
Before diving into data collection, it’s essential to define your goals. Every ML model serves a unique purpose, so understanding its objectives helps identify what data is required.
- Determine the use case: Are you building a predictive model, a classification algorithm, or a recommendation system? The data you need will depend on this.
- For example, a customer churn model requires historical customer behavior data.
- A computer vision model might need labeled images for object detection.
- Define data characteristics: What are the critical features your data must include? For instance:
- In healthcare, datasets must have diagnostic accuracy.
- In finance, data latency might be a concern for real-time applications.
By clearly outlining these requirements, you save time, avoid redundant collection, and streamline the preparation process.
Data Collection and Acquisition
Acquiring the right data is often one of the most challenging steps in an ML project. Here’s how you can tackle it:
- Open datasets: Publicly available datasets are a great starting point. Repositories like Kaggle, UCI Machine Learning Repository, and Google Dataset Search host diverse datasets for various applications.
- Kaggle provides datasets for image classification (e.g., CIFAR-10) and text analysis (e.g., IMDb reviews).
- UCI Repository offers datasets like “Heart Disease” for healthcare research.
- Commercial datasets: For industry-specific needs, paid sources such as Statista or private providers can offer curated data with a higher level of detail and accuracy.
- Synthetic data: In cases where real-world data is limited, synthetic data generation tools like GANs (Generative Adversarial Networks) can simulate realistic datasets.
- Domain-specific data sources: Industry data—like financial reports, IoT logs, or genomics databases—provides context-rich datasets. For example:
- Finance: Quandl for stock market data.
- Healthcare: MIMIC for patient records.
- Third-party data providers
Regardless of the source, always prioritize data relevance and quality over quantity.
Data Cleaning and Preprocessing
Once data is collected, it’s rarely ready for modeling as is. Cleaning and preprocessing ensure that the dataset is consistent, accurate, and usable.
- Addressing missing values: Techniques like imputation (mean, median, or mode) or removal can handle missing entries.
- Removing duplicates: Redundant data skews models and wastes resources.
- Standardizing entries: Uniform formats are crucial, especially for categorical data (e.g., using “Male” instead of “M” or “m”).
- Normalization and scaling: These techniques adjust numerical data for better model performance, especially in distance-based algorithms like k-Nearest Neighbors.
- Example: Scaling age and income to a range of 0–1 ensures equal weight.
Pro Tip: Visualizations like histograms and scatterplots can reveal anomalies and guide cleaning efforts.
Data Transformation and Formatting
Machine learning models often require data in a specific format. Transforming raw data into a usable form bridges this gap:
- Converting data types: Some models can’t process categorical data, requiring conversion to numerical forms through encoding.
- One-hot encoding: Converting categorical variables into binary columns.
- Label encoding: Assigning unique numbers to each category.
- Text processing for NLP tasks: Tokenization, stemming, and lemmatization refine text data for models like sentiment analyzers.
- Standardizing numerical data: Scaling features like height or weight prevents bias, especially in models sensitive to magnitude.
Proper transformation not only optimizes model performance but also reduces computational overhead.
Data Annotation Tools and Techniques
Annotated data is critical for supervised learning models. Accurate labels are the backbone of tasks like classification or object detection. Here are tools and techniques to streamline annotation:
- Annotation tools:
- Labelbox and SuperAnnotate: Great for general image and text labeling.
- CVAT (Computer Vision Annotation Tool): Tailored for computer vision tasks like object detection.
- Labeling methods:
- Manual annotation: Ensures precision but is time-intensive.
- Crowdsourced labeling: Platforms like Amazon Mechanical Turk enable large-scale annotations quickly.
- Accuracy in labeling: Poorly annotated data can cripple a model. For instance, mislabeled images in a self-driving car dataset could lead to dangerous predictions.
Investing time in accurate annotations directly correlates to improved model outcomes.
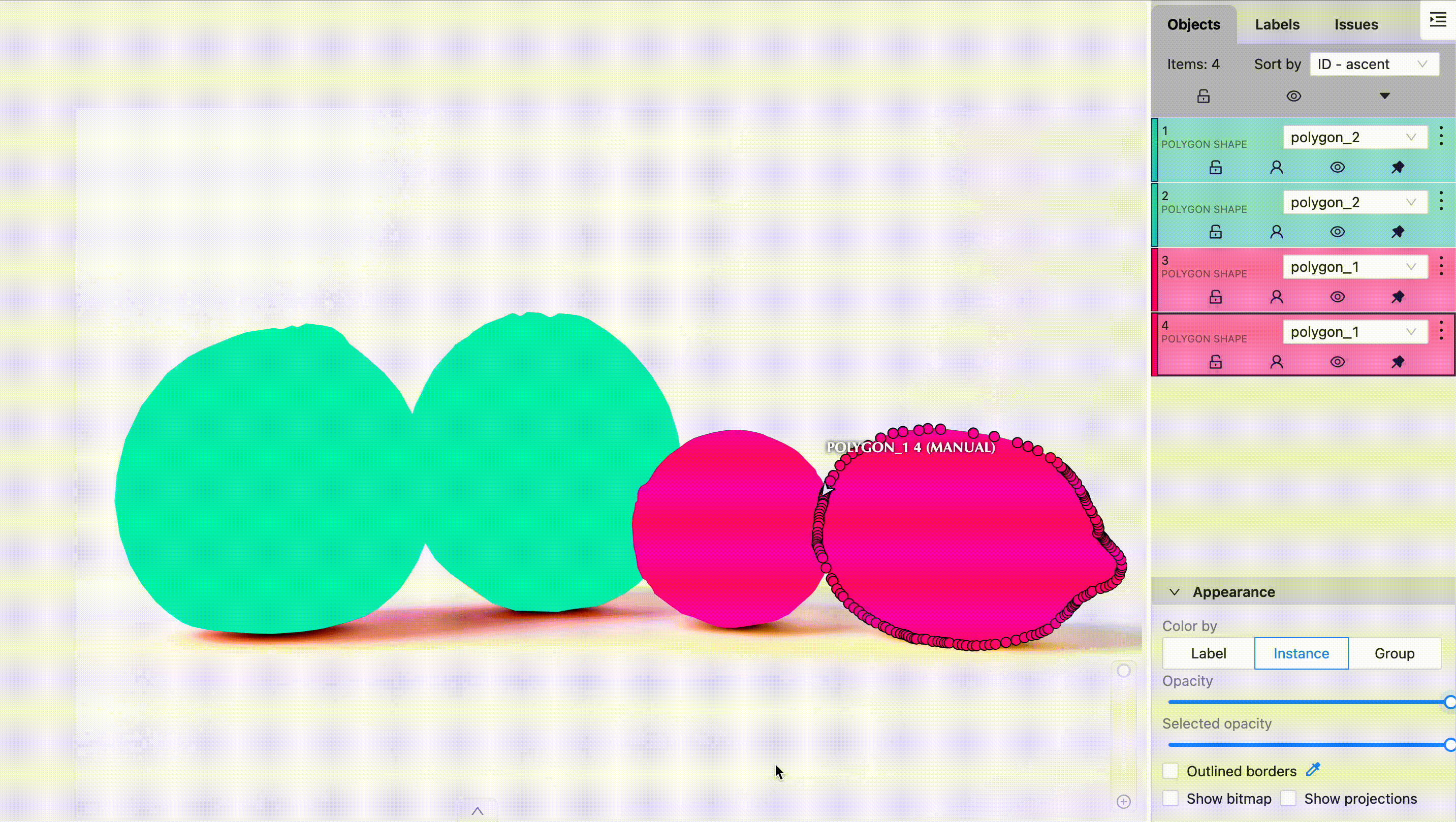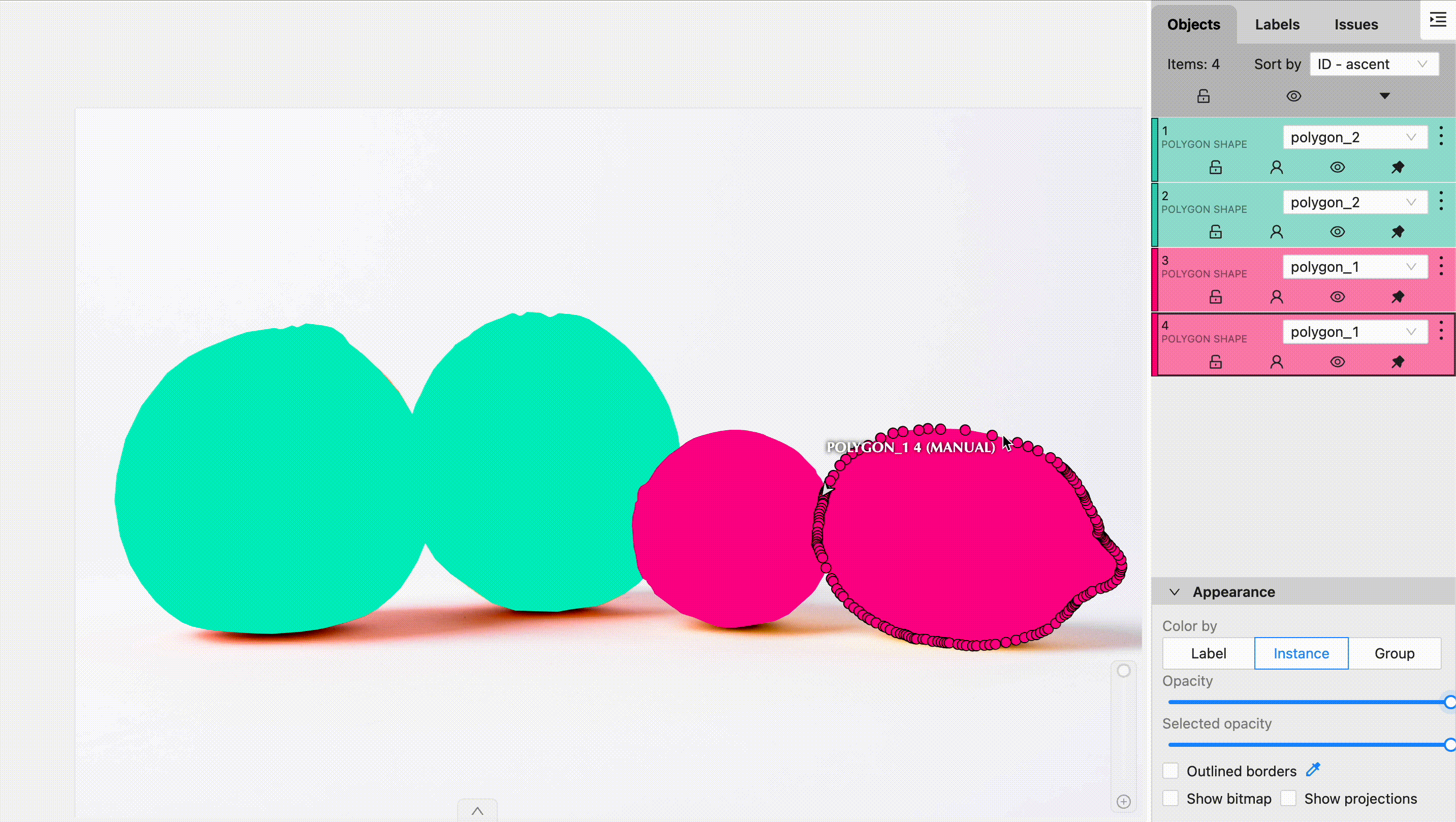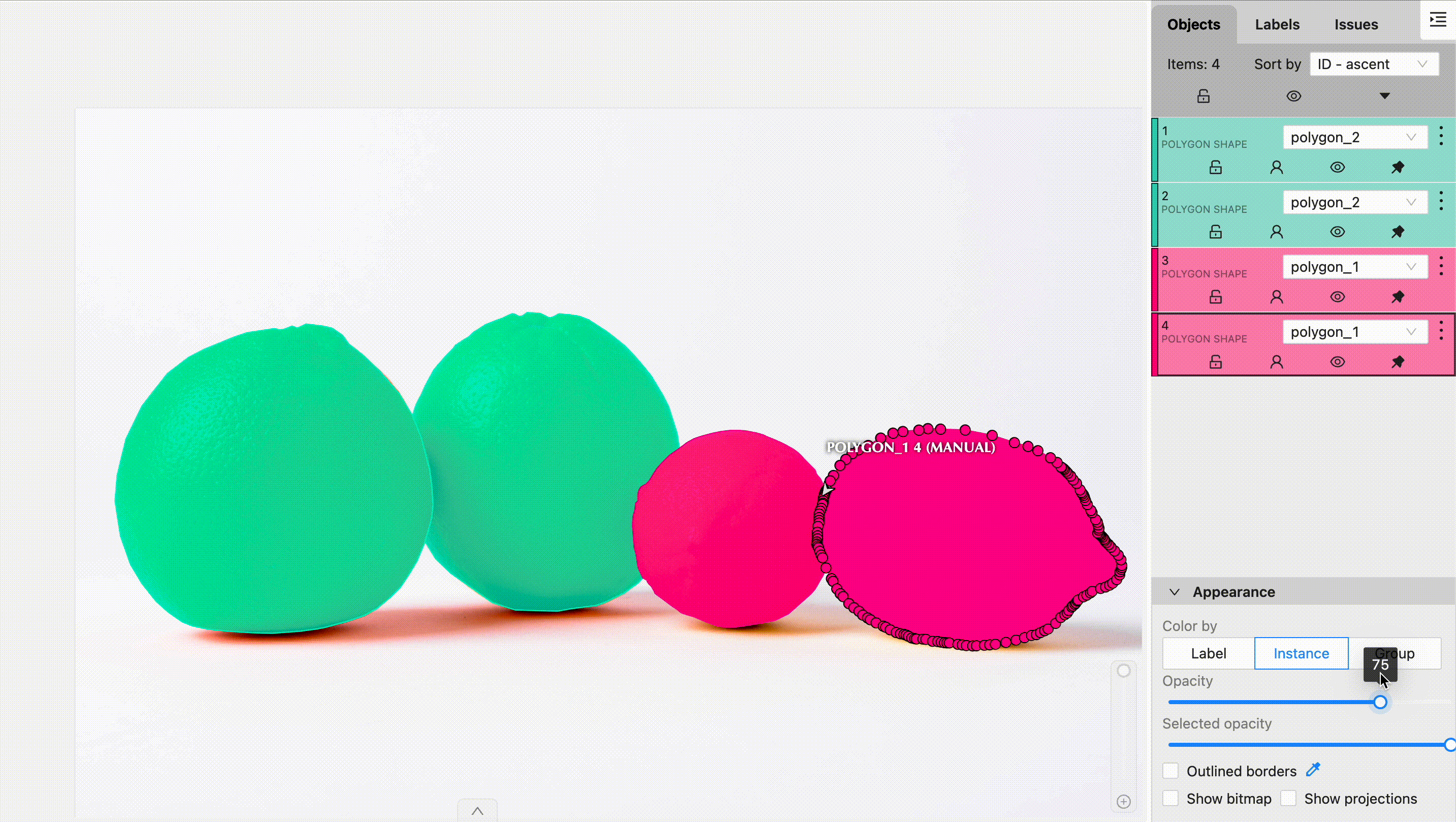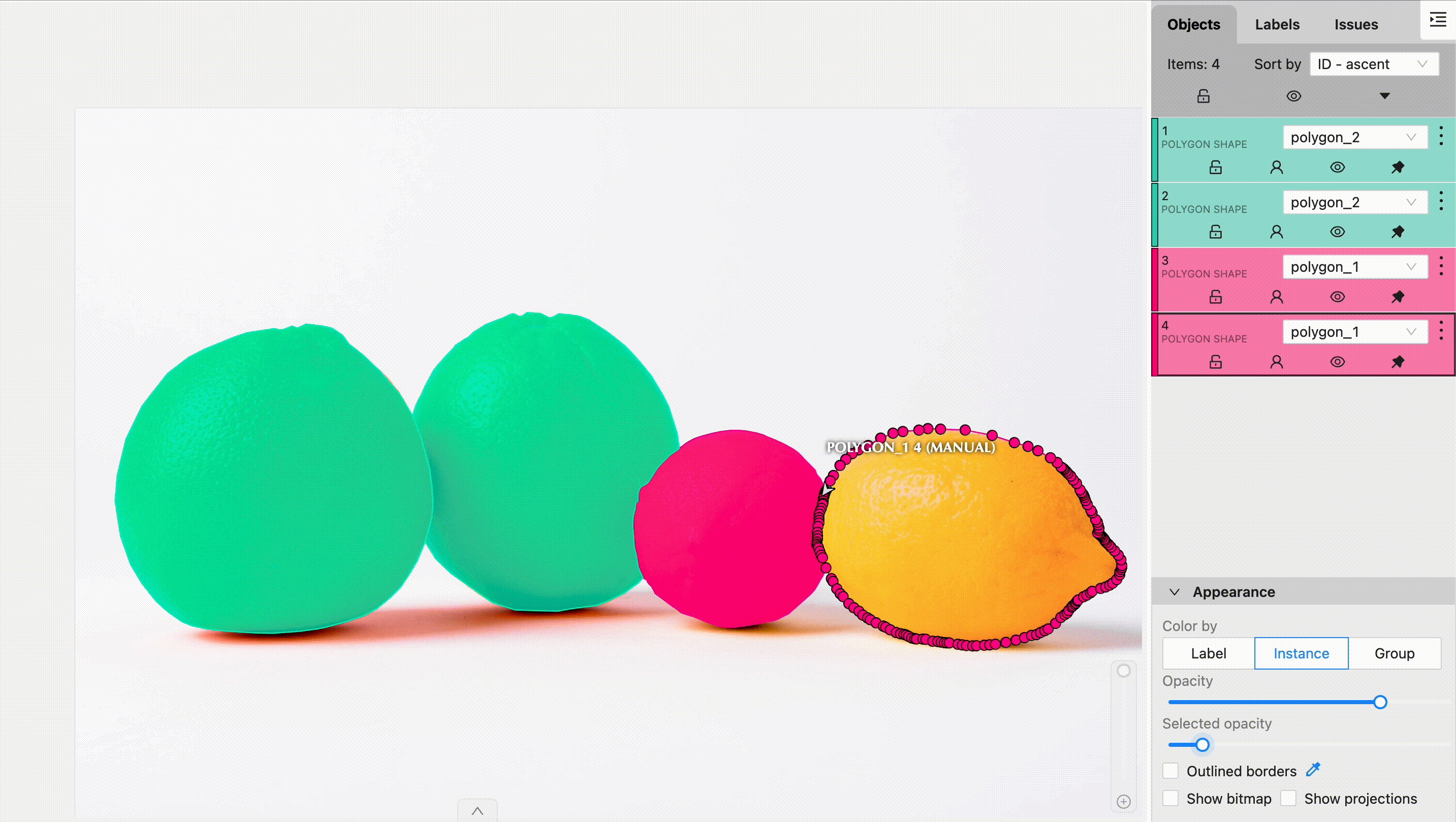
Dataset Splitting
Splitting a dataset into training, validation, and test sets is more than just a formality; it’s a safeguard against overfitting and ensures a model’s generalizability.
- Typical ratios:
- Training: 60–70%.
- Validation: 10–20%.
- Test: 20–30%.
- Cross-validation: Instead of a single split, techniques like k-fold cross-validation divide the data into k subsets, training and validating on each fold to ensure robust performance.
- Stratified sampling: For imbalanced datasets, stratification ensures that each subset maintains the same distribution of classes, preventing bias.
By carefully splitting your data, you build models that perform consistently across unseen data.
Data Augmentation Techniques for Enhanced Dataset Quality
Data augmentation involves creating new data samples from existing ones, helping improve model performance and reducing overfitting. This is especially useful when dealing with small datasets.
- Image data augmentation:
- Common techniques include flipping, rotation, cropping, and adding noise.
- Tools like OpenCV and TensorFlow’s ImageDataGenerator make augmentation straightforward.
- Example: Training an autonomous vehicle model might involve flipping road images to simulate left- and right-hand driving scenarios.
- Text data augmentation:
- Synonym replacement, word shuffling, and back translation (translating text to another language and back) are effective methods.
- Tools like TextAugment simplify augmentation for NLP tasks.
- Time-series augmentation:
- Techniques like jittering (adding noise) and window slicing are used in applications like stock price prediction or ECG analysis.
Data augmentation not only enhances diversity but also improves a model’s ability to generalize across new scenarios.
What is Data Augmentation? Complete Guide
Learn more
Evaluating Dataset Quality and Suitability
Before committing to a dataset, rigorous evaluation is essential to ensure it meets project requirements.
- Assessing completeness: Are all critical features included? Missing attributes can reduce model accuracy.
- Relevance and representativeness: A dataset must reflect the real-world scenarios it aims to predict. For instance, a healthcare model trained on data from one demographic may fail in another.
- Statistical analysis and visualization:
- Use tools like Pandas, Matplotlib, or Seaborn to analyze distributions.
- Techniques such as histograms, boxplots, and scatter matrices highlight potential biases or inconsistencies.
These steps guarantee that your dataset aligns with your objectives and supports reliable model outcomes.
Challenges in Dataset Collection and Preparation
Collecting and preparing datasets often come with hurdles that can hinder an ML project. Common challenges include:
- Bias in data: If a dataset overrepresents certain groups or scenarios, the resulting model can become biased. For instance, facial recognition systems have faced criticism for poor performance on underrepresented ethnic groups.
- Missing values: Gaps in data introduce inaccuracies, especially in time-series datasets.
- Labeling inconsistencies: Mislabeled data, such as incorrect image tags, can mislead a model.
Mitigation strategies:
- Bias: Increase diversity in data sources.
- Missing values: Use advanced imputation methods or collect supplementary data.
- Labeling inconsistencies: Adopt rigorous annotation practices and validation checks.
Being proactive about these challenges can save significant time and effort downstream.
Overview of Open Datasets
Here are some of the most relevant and widely used open datasets for machine learning across various domains. These datasets are publicly accessible and cater to different needs, from computer vision and natural language processing to industry-specific applications:
Natural Language Processing (NLP)
- IMDB Reviews Dataset
A dataset with 50,000 labeled movie reviews for sentiment analysis.
Applications: Sentiment analysis, opinion mining, and text classification. - 20 Newsgroups Dataset
Text documents categorized into 20 topics for NLP tasks.
Applications: Topic modeling, clustering, and classification. - Sentiment140 Dataset
Tweets annotated for sentiment (positive, neutral, negative).
Applications: Social media analysis, trend tracking, and real-time sentiment prediction. - Common Crawl
Massive raw text data extracted from billions of web pages.
Applications: Language modeling, text summarization, and NLP research. - Wikipedia Text Corpus
Extracted abstracts from Wikipedia articles.
Applications: Text summarization, question-answering, and training language models.
Computer Vision (CV)
- ImageNet
A large-scale image database with over 14 million labeled images.
Applications: Image classification, object detection, and visual recognition. - COCO Dataset
A rich dataset with images annotated for object detection and segmentation.
Applications: Contextual image understanding, segmentation, and visual reasoning. - CIFAR-10 and CIFAR-100
Small 32x32 images for classification tasks across 10 or 100 categories.
Applications: Benchmarking deep learning models for vision tasks. - MNIST Handwritten Digits Dataset
A dataset of 70,000 grayscale images of handwritten digits.
Applications: Optical character recognition (OCR) and digit classification. - Google Open Images
A diverse dataset of labeled images for object detection and segmentation.
Applications: Advanced CV tasks like multi-object detection.
Time-Series and Tabular Data
- UCI Machine Learning Repository
A repository of datasets for various ML tasks, including time-series.
Applications: Predictive modeling, regression, and clustering. - Electricity Load Diagrams
Time-series data on electricity consumption.
Applications: Forecasting and energy modeling. - Financial News Dataset
News headlines with sentiment scores for finance.
Applications: Predictive modeling in financial markets.
Speech and Audio Processing
- Mozilla Common Voice
A dataset with diverse human voice recordings in multiple languages.
Applications: Speech-to-text systems, language models. - LibriSpeech
1,000 hours of speech data from audiobooks.
Applications: Automatic speech recognition, voice-controlled applications. - VoxCeleb
Audio data for speaker identification and verification.
Applications: Biometric systems, speaker verification. - AudioSet
Over 2 million human-labeled sound clips.
Applications: Sound recognition, environmental audio analysis. - Free Spoken Digit Dataset
Audio recordings of digits spoken in English.
Applications: Speech recognition and classification.
These datasets are just the starting point for building and testing machine learning models, providing good opportunities for both academic and commercial applications
Ethical and Regulatory Considerations in Dataset Use
Ethics and compliance are non-negotiable when working with datasets, particularly in sensitive fields like healthcare or finance.
- Fairness and bias mitigation: Algorithms trained on biased data can perpetuate systemic inequalities. Implementing techniques like reweighting and adversarial debiasing helps promote fairness.
- Data privacy and security: Regulations like GDPR (General Data Protection Regulation) and HIPAA (Health Insurance Portability and Accountability Act) mandate strict controls on data collection, storage, and sharing.
- Privacy-preserving strategies:
- Data anonymization: Removing identifiable attributes while retaining utility.
- Differential privacy: Adding noise to datasets to obscure individual identities.
Adhering to ethical and regulatory standards ensures responsible data practices and fosters trust in AI systems.
Case Studies of Datasets in Real-World Applications
Datasets drive innovations across industries. Let’s explore some notable examples:
- Healthcare:
- Dataset: MIMIC-III, a publicly available critical care database.
- Used for developing AI models to predict patient outcomes and optimize treatment plans.
- Finance:
- Dataset: Quandl’s stock market data.
- Used for training predictive algorithms for stock price forecasting.
- Retail:
- Dataset: Amazon reviews dataset.
- Powering recommendation systems to improve customer satisfaction and increase sales.
These case studies highlight the transformative impact of high-quality datasets when properly utilized.
Future Directions in Dataset Development for Machine Learning
As technology evolves, so do the trends in dataset creation and utilization. Key advancements include:
- Synthetic data generation:
- GANs and VAEs (Variational Autoencoders) are being used to create realistic synthetic datasets for training without compromising privacy.
- Example: Simulating customer behavior in retail.
- Federated learning:
- A decentralized approach where models train across multiple devices without sharing raw data, preserving privacy.
- Application: Healthcare systems where patient data is sensitive.
- Real-time data processing: Edge computing enables models to learn from streaming data in real-time, revolutionizing areas like IoT and autonomous vehicles.
- Self-supervised learning: By reducing the reliance on labeled datasets, this approach leverages vast amounts of unlabeled data, paving the way for breakthroughs in NLP and computer vision.
These trends signal a future where data is not just abundant but also responsibly and innovatively utilized.
Conclusion
Datasets are the lifeblood of machine learning, underpinning every model's success or failure. From defining data requirements to navigating ethical complexities, each step in the dataset lifecycle is critical. As the field advances, emerging technologies like synthetic data and federated learning promise to redefine how we collect, manage, and utilize data.
To build impactful ML solutions, prioritize high-quality, ethically sourced data. By doing so, you set the foundation for innovation while ensuring trust and compliance in a rapidly evolving landscape.
Frequently Asked Questions (FAQ)
Completeness and accuracy are crucial. A dataset missing critical features or containing errors can mislead models, reducing performance and reliability.
Techniques like oversampling, undersampling, and synthetic data generation (e.g., SMOTE) can help balance classes in datasets, ensuring fair model training.
Data augmentation increases dataset diversity, helping models generalize better and reducing the risk of overfitting.
Key considerations include avoiding bias, ensuring fairness, respecting privacy, and complying with data regulations like GDPR and HIPAA.
Open datasets from platforms like Kaggle or UCI Repository are excellent starting points. Small businesses can also generate synthetic data or use crowdsourcing for annotation.










