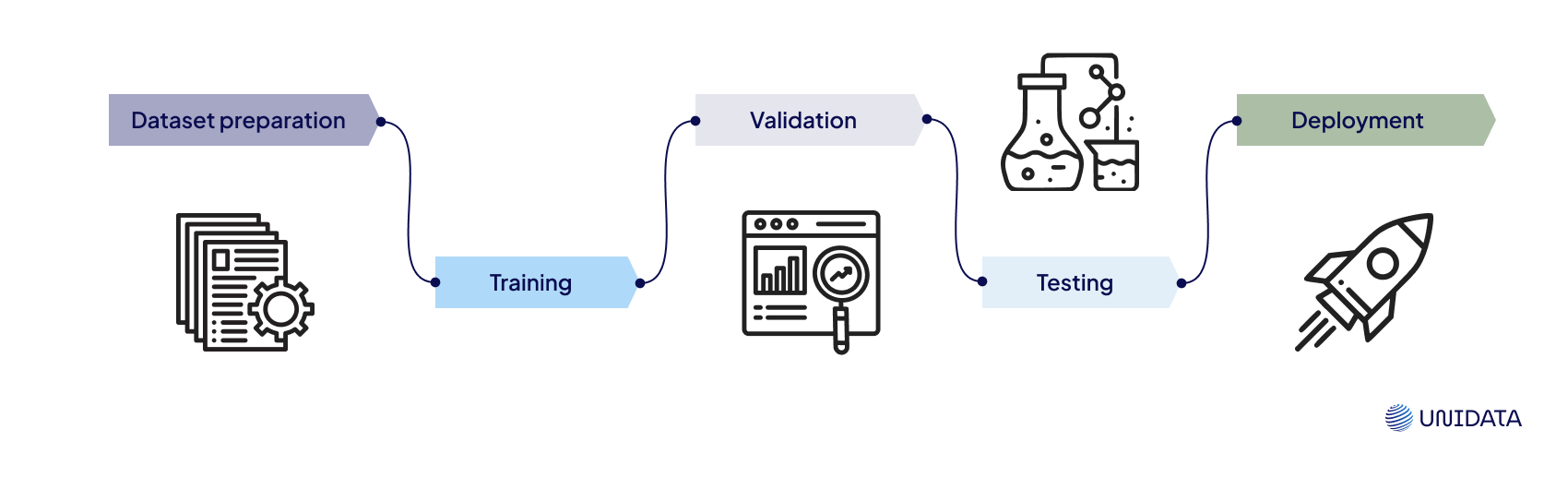
Overview of Datasets Used in ML
In the world of machine learning (ML), datasets play a fundamental role in building, training, and validating models. These data collections are not just random sets of information but carefully curated arrays that fuel the learning process of algorithms. They serve as the foundation from which insights are drawn, patterns are identified, and predictions are made.
These datasets are typically divided into three categories: training, validation, and test datasets.
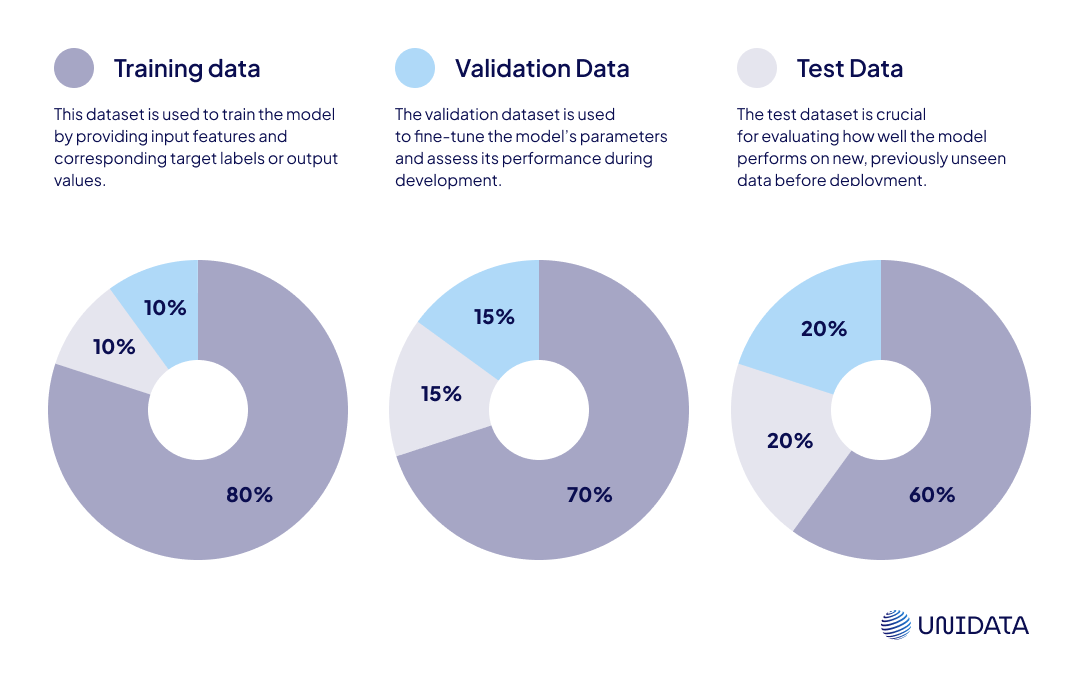
Let’s explore these dataset types in more detail.
Training Data in ML
Training data serve as the information source for model learning. This dataset consists of various input features, each associated with a corresponding target label or outcome. In supervised learning, algorithms analyze these connections, identify patterns, and generate predictions.
Characteristics of Training Datasets
Training datasets are typically large, containing thousands to millions of records. A broad dataset is necessary for the model to learn from diverse examples and apply its knowledge to new data effectively.
As mentioned earlier, training datasets include labels for each known target value or outcome. Data annotation plays a key role in helping the model establish relationships between input features and outputs. Proper annotation ensures that the model learns accurate associations.
It is also essential that training data reflect real-world scenarios the model may encounter. The dataset should be relevant and generalizable across different contexts, achieved by carefully selecting diverse and representative data.
Training datasets may contain noise, outliers, or missing values, requiring preprocessing and data cleaning. Effectively handling these issues improves data quality and enhances the accuracy of machine learning models.
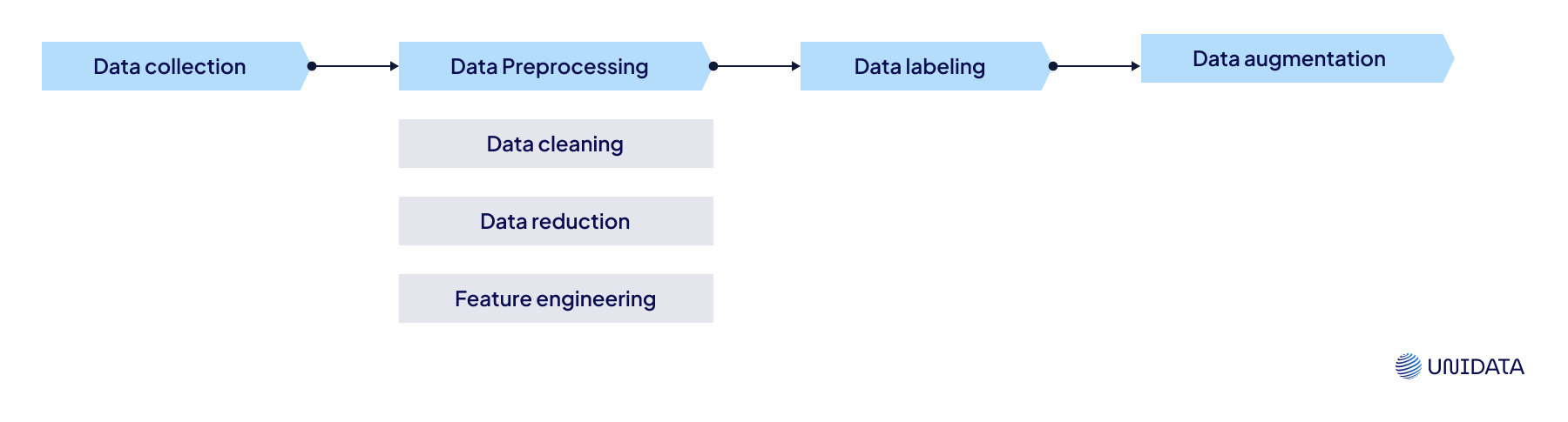
How Training Data is Prepared and Preprocessed
Data preparation and preprocessing are crucial stages in machine learning, directly impacting model quality and performance. Before being fed into an algorithm, data undergo several key processes:
Validation Data
Definition and Role of Validation Data in ML
Validation data in machine learning is a subset used to evaluate model quality during training but is not included in the training dataset. These datasets play a crucial role in tuning hyperparameters and preventing overfitting.
- Hyperparameter Tuning – During model training, hyperparameters (e.g., learning rate, number of layers in a neural network, number of trees in a random forest) can be optimized using validation data.
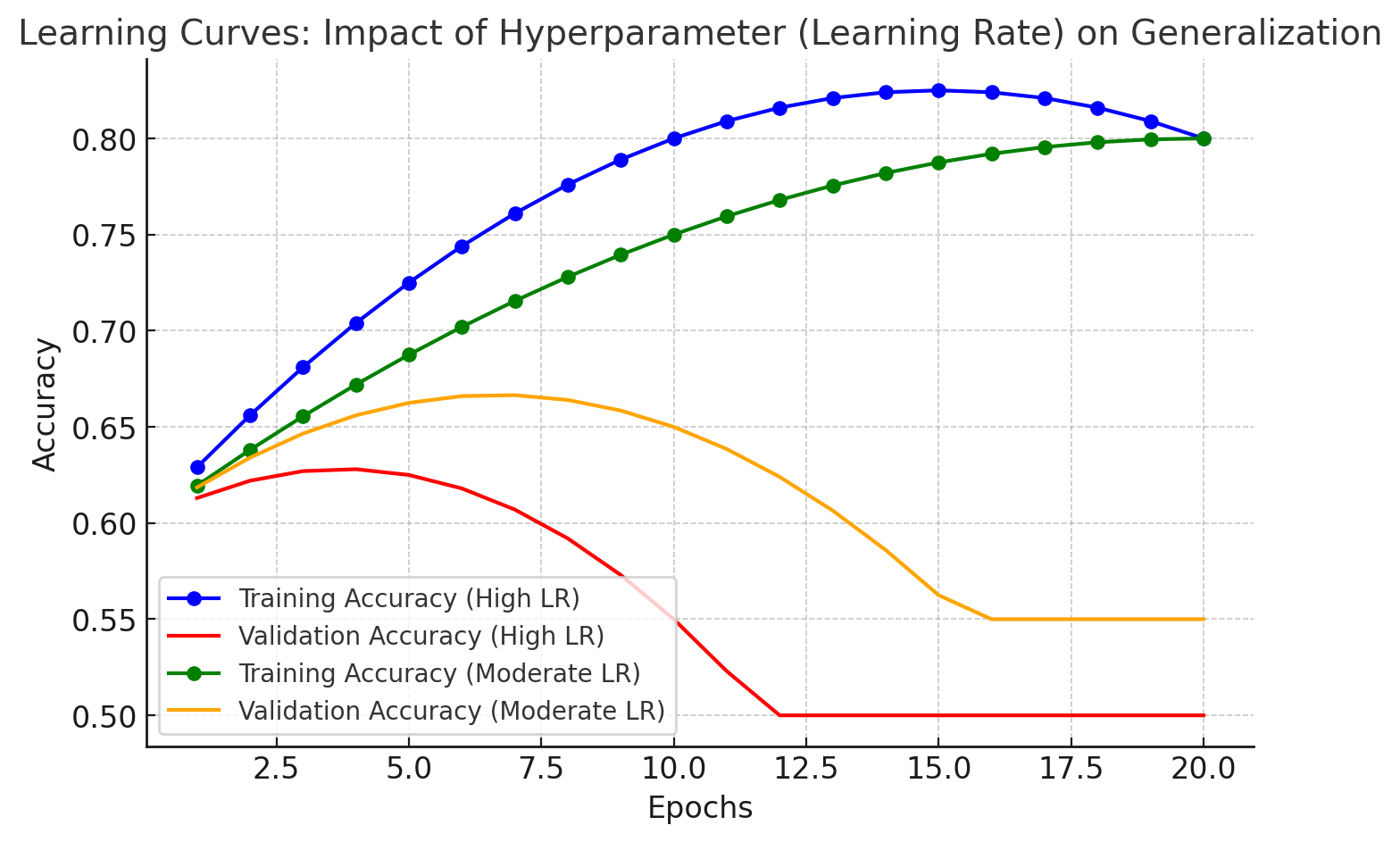
In this line chart, we compare the performance of two models: one with a high learning rate and another with a moderate learning rate. Notice how the model with a high learning rate shows rapid improvement at first but then overfits (validation accuracy drops). The model with a moderate learning rate maintains better generalization, as indicated by the closer alignment between training and validation accuracy curves.
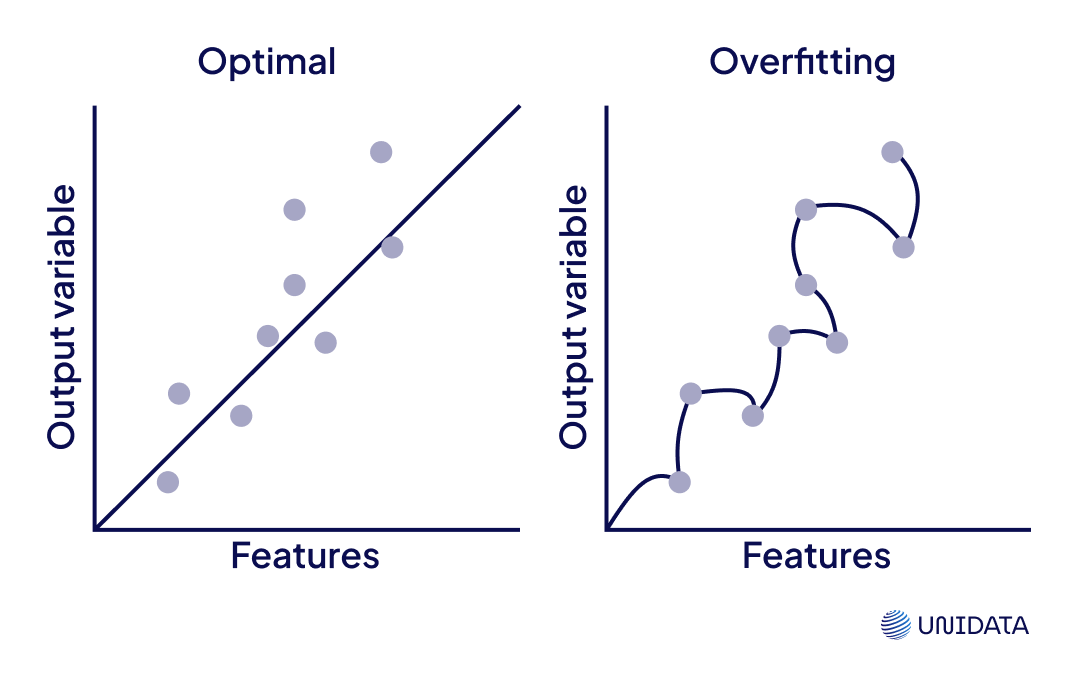
- Overfitting Prevention – Validation data are essential for detecting early signs of overfitting. If a model performs exceptionally well on training data but poorly on validation data, it may be too specifically fitted to the training set.
In the early stages, both the training and validation accuracies improve as the model learns. However, as the model starts to memorize the training data too well (overfitting), the validation accuracy begins to drop. This is where the model starts performing well on the training set but poorly on new, unseen data, indicated by the gap between the blue (training) and red (validation) curves.
This graph serves as a reminder that achieving high accuracy on training data isn’t enough – we need models that generalize well to unseen data!
Characteristics of Validation Datasets
Validation datasets share some similarities with training data but also have distinct features. Like training data, validation sets contain input features and corresponding labels, making them useful for supervised learning tasks. However, they are smaller in size since their primary purpose is model evaluation rather than training.
For accurate assessment, the validation dataset should be a representative sample of the full dataset, ensuring the model is evaluated under conditions similar to real-world applications.
How Validation Data is Created
Validation data are generated by splitting the original dataset into training and validation subsets. Common approaches include:
Holdout Method – A portion of data is set aside for validation, while the rest is used for training.
K-Fold Cross-Validation – The dataset is divided into k equal parts, with each subset serving as validation data in turn.
Recent research highlights the importance of external validation datasets in predictive modeling. For instance, in drug response prediction for acute myeloid leukemia, ensemble models validated on external datasets (Clinseq and LeeAML) demonstrated higher predictive accuracy. This suggests that incorporating additional test datasets can significantly improve a model's generalization ability.
Validation Dataset in Machine Learning
Learn more
Test Data
Definition and Role of Test Data in ML
Test data are used in the final evaluation stage to provide an unbiased assessment of a model’s performance on previously unseen data. Unlike training and validation datasets, the test dataset remains completely separate until the model’s final assessment.
The primary goal of test data is to determine how well the model generalizes to new data and how accurately it can make predictions in real-world scenarios.
Characteristics of Test Datasets
Test datasets contain examples unknown to the model, allowing an objective evaluation of its real-world applicability. These datasets should reflect the overall structure of the original data and maintain the distribution of the full dataset to ensure performance metrics are accurate and meaningful.
How Test Data is Created
Test datasets are formed during the preprocessing phase by separating a portion of the data exclusively for final evaluation. It is crucial to keep test data isolated from training and validation data throughout model development.
Additionally, experts may use external test datasets or real-world data collected in operational environments. This helps assess how well the model performs beyond its initial dataset and in practical applications.
Comparing training, validation, and test sets
Let's overview the differences between training, validation, and test sets. All of these datasets have their distinctive roles in the life cycle of a machine learning model. The training set is primarily employed in the initial training phase – it's used to teach the model patterns and behaviors embedded in the dataset. In contrast, the validation set helps fine-tune the model after the initial training phase by adjusting hyperparameters, detecting and correcting overfitting issues during training. Finally, the test set is reserved for the final stage of the ML process: it helps evaluate how well the model performs in real-world scenarios by providing an unbiased assessment of its generalization capabilities in terms of new data.
While these sets have their differences, they also share some common points, especially regarding the indispensable role they all play throughout the machine learning process. All three sets are usually extracted from a single initial dataset via data splitting. Training, validation, and test sets are essential for developing, refining, and assessing the model to ensure effective learning, correct generalization, and consistent performance across unseen situations. Maintaining the integrity and coherence of these datasets is critical as they collectively contribute to creating a well-rounded machine learning model.
| Aspect | Training Data | Validation Data | Test Data |
|---|---|---|---|
| Purpose | Used to train the model, allowing it to learn and adapt to the data | Used to tune hyperparameters and avoid overfitting by providing an unbiased evaluation of the model during training | Used to assess the final performance of the model after training and validation, providing an unbiased assessment of its predictive power in real-world scenarios |
| Timing of Use | Used throughout the initial phase of the machine learning pipeline | Used after the model has been initially trained on the training data | Used after the model has been trained and validated, at the very end of the machine learning process |
| Characteristics | Should represent the full spectrum of data and scenarios the model will encounter | Should be representative of the dataset to validate the model's ability to generalize | Representative of real-world data the model will encounter post-deployment to accurately assess its performance |
Common Mistakes in Data Splitting
Since data splitting is a critical stage in ML model development, certain common mistakes can negatively impact a model's reliability and accuracy. Here are some of the most frequent pitfalls:

Conclusion
In summary, the training, validation, and test sets play crucial roles in creating, assessing, and implementing machine learning models. It's important to understand the distinctions between these subsets and choose the most fitting data partitioning methods to ensure the accuracy and dependability of ML systems. As machine learning continues to advance, advancements in data splitting techniques will be essential for driving progress and enhancing the development of powerful ML systems.
Frequently Asked Questions (FAQ)
Unsupervised learning is a machine learning approach that works with unlabeled datasets, allowing algorithms to discover hidden patterns, structures, or relationships without predefined outputs. While training, validation, and test datasets are typically used in supervised learning, unsupervised learning focuses on exploring data structure, often before labeling or model training begins.
Validation data refers to a subset of a dataset used to evaluate and fine-tune a model during training. It is not used to train the model directly but helps optimize hyperparameters and detect overfitting. In both supervised workflows and pipelines that include unsupervised learning, validation data ensures the model generalizes well to unseen data.
A common data validation example is splitting a dataset into training and validation sets using the holdout method or k-fold cross-validation. For instance, a model trained on customer data may be evaluated on validation data to check whether it performs well on new samples and avoids overfitting.
The main difference is that unsupervised learning uses unlabeled data, while supervised learning relies on labeled datasets divided into training, validation, and test sets. Unsupervised learning identifies patterns without guidance, whereas supervised learning uses validation data to measure accuracy and tune performance.
Even in workflows involving unsupervised learning, validation data plays a role when models are later evaluated or combined with supervised steps. It helps ensure that patterns discovered in data can generalize to real-world scenarios and supports model tuning when unsupervised features are used in predictive models.
In machine learning workflows that may include unsupervised learning, datasets are typically split into:
- Training data: used to teach the model patterns
- Validation data: used to tune hyperparameters and prevent overfitting
- Test data: used for final, unbiased performance evaluation
Each dataset plays a critical role in ensuring the model performs well on unseen data.
Yes, unsupervised learning is often used before dataset splitting to explore data, detect patterns, or reduce dimensionality. Techniques like clustering or PCA can help improve feature selection, making subsequent training, validation, and testing phases more effective and accurate.