

1. What Is Automatic Speech Recognition?
Talk to your phone. Rant to your car. Whisper to your smart speaker. And somehow, it answers—translating sound into text like it speaks human. That’s automatic speech recognition (ASR). And it’s everywhere.
From subtitles on YouTube to voice commands in your car, ASR powers the silent understanding behind our loud, messy speech. It doesn’t just hear you—it decodes fast mumbling, background noise, regional slang, and emotional tone, all in real time.
Under the hood? A choreography of signal processing, deep learning, and language modeling working in sync to turn your voice into clean, readable data.
2. Why ASR Matters (and Where It’s Used)
And it’s not just cool tech—it’s big business. The ASR market is projected to grow from $10.7 billion in 2020 to 49 billion by 2029 (Statista, 2024). That’s because speech is still the fastest, most natural way we interact—and ASR is finally accurate enough to keep up.
So where is it already making a real-world impact?

- Virtual Assistants
Siri, Alexa, Google Assistant — ASR powers them all. You ask, they respond. No buttons, no typing. - Live Captioning
Real-time subtitles on YouTube, Zoom, and phones help make content accessible — especially for deaf or hard-of-hearing users. - Healthcare
Doctors use voice to update patient records, dictate notes, and speed up documentation with less burnout. - Customer Service
IVR menus and voicebots now parse full sentences, not just “press 1” — cutting wait times and human load. - Automotive UX
Voice-controlled GPS, calls, and media keep drivers focused where it matters: the road. - Language Learning
Duolingo-style apps listen to your pronunciation and correct you in real time—turning passive lessons into practice.
Whether it’s about saving time, boosting access, or just reducing clicks, ASR is already doing the work behind the scenes.
3. How Automatic Speech Recognition Works: Step-by-Step
ASR doesn’t just “listen”—it processes. Fast. In real time. Here’s what actually happens behind the mic, turning raw sound into something you can read, search, and act on.
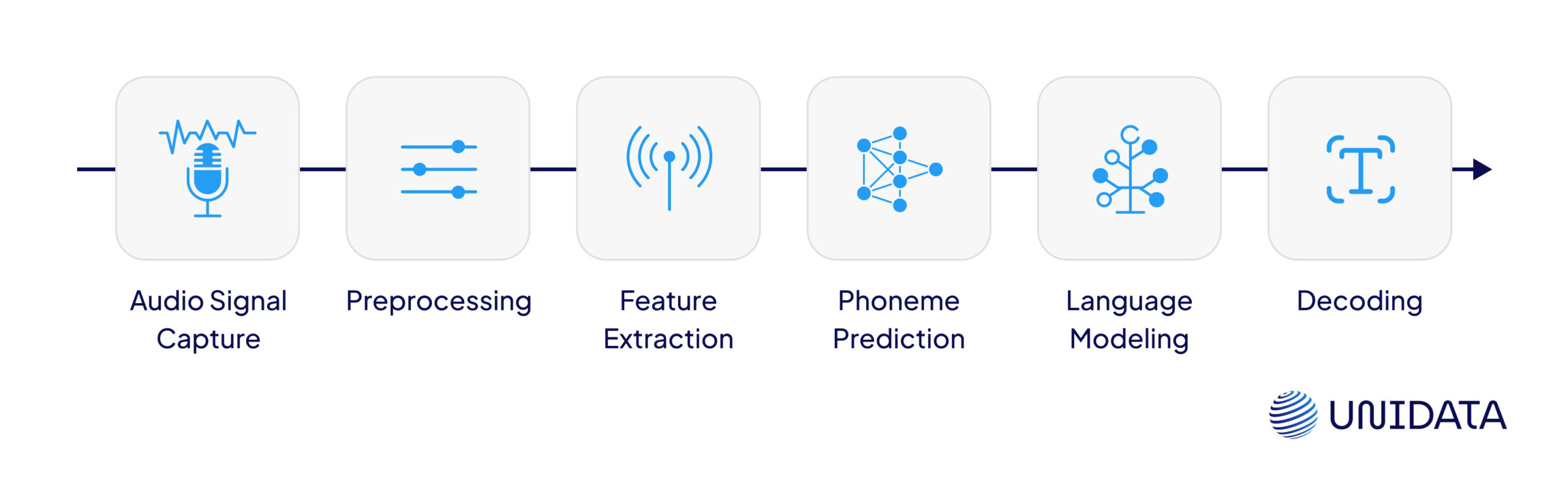
1. Audio Signal Capture
Everything begins with sound hitting the microphone. Your voice gets converted into an analog waveform— just variations in air pressure over time.
The microphone turns that analog signal into digital data the system can process. And already, things get tricky. Mic quality, background noise, how far you're standing, what direction you’re facing—all of that affects how clean or messy the captured audio will be. A good ASR system can adjust for those variables, but it can’t fix a totally broken input.
2. Preprocessing
Next comes cleanup. The raw waveform goes through a series of filters to reduce unwanted noise—like background chatter, fan hum, or traffic—and trim long pauses or silence. This step also normalizes volume and pitch so the model hears you consistently whether you're whispering or shouting.
Think of it as wiping the fog off a windshield: the better this stage, the easier it is for downstream models to “see” what’s really being said.
3. Feature Extraction
Once the signal is cleaned, it's time to break it down. The audio is sliced into tiny time frames—usually 10 to 25 milliseconds each—so the model can catch every dip, spike, and pause in your voice.
For every frame, the system extracts acoustic features that describe the shape, tone, and texture of the sound. The most common? MFCCs—Mel-Frequency Cepstral Coefficients. These are compact numerical fingerprints that approximate how the human ear perceives pitch and tone.
Before feature extraction kicks in, the signal often goes through additional smoothing:
- A high-pass filter removes low-frequency noise like background hum (using something like a Butterworth filter at 100 Hz).
- The signal is then normalized to keep loud and quiet speech on equal footing:
- Silence trimming helps cut out long pauses or dead space before and after the actual speech.
Here’s a snippet of what that cleanup looks like in code:
import librosa
import numpy as np
import scipy.signal as signal
import matplotlib.pyplot as plt
# Load raw audio
y, sr = librosa.load("your_audio_file.wav", sr=None)
# 1. High-pass filter (remove low-frequency noise)
sos = signal.butter(10, 100, 'hp', fs=sr, output='sos') # 100 Hz cutoff
y_filtered = signal.sosfilt(sos, y)
# 2. Normalize amplitude
y_normalized = y_filtered / np.max(np.abs(y_filtered))
# 3. Trim silence (optional)
y_trimmed, _ = librosa.effects.trim(y_normalized, top_db=25)
# Plot cleaned waveform
plt.figure(figsize=(10, 2))
plt.title("Cleaned Signal")
plt.plot(y_trimmed)
plt.tight_layout()
plt.show()
# 4. Extract MFCCs from cleaned audio
mfccs = librosa.feature.mfcc(y=y_trimmed, sr=sr, n_mfcc=13)
4. Phoneme Prediction from Audio Features
This is where machine learning kicks in. Models take the extracted features and predict which phonemes (basic sound units like /k/, /t/, /a/) are likely being spoken. Older systems used statistical models like HMMs, but most modern ASR pipelines rely on deep neural networks:
- CNNs help detect local shifts and edges in sound data.
- RNNs and LSTMs model how those sounds evolve over time, which is critical for handling connected speech.
- Transformer-based models offer parallel processing and longer context awareness, making them ideal for large-vocabulary, noisy, or fast-paced audio.
A well-trained acoustic model can distinguish between subtle differences like "pen" and "pin"—even when spoken quickly or with an accent.
5. Language Modeling
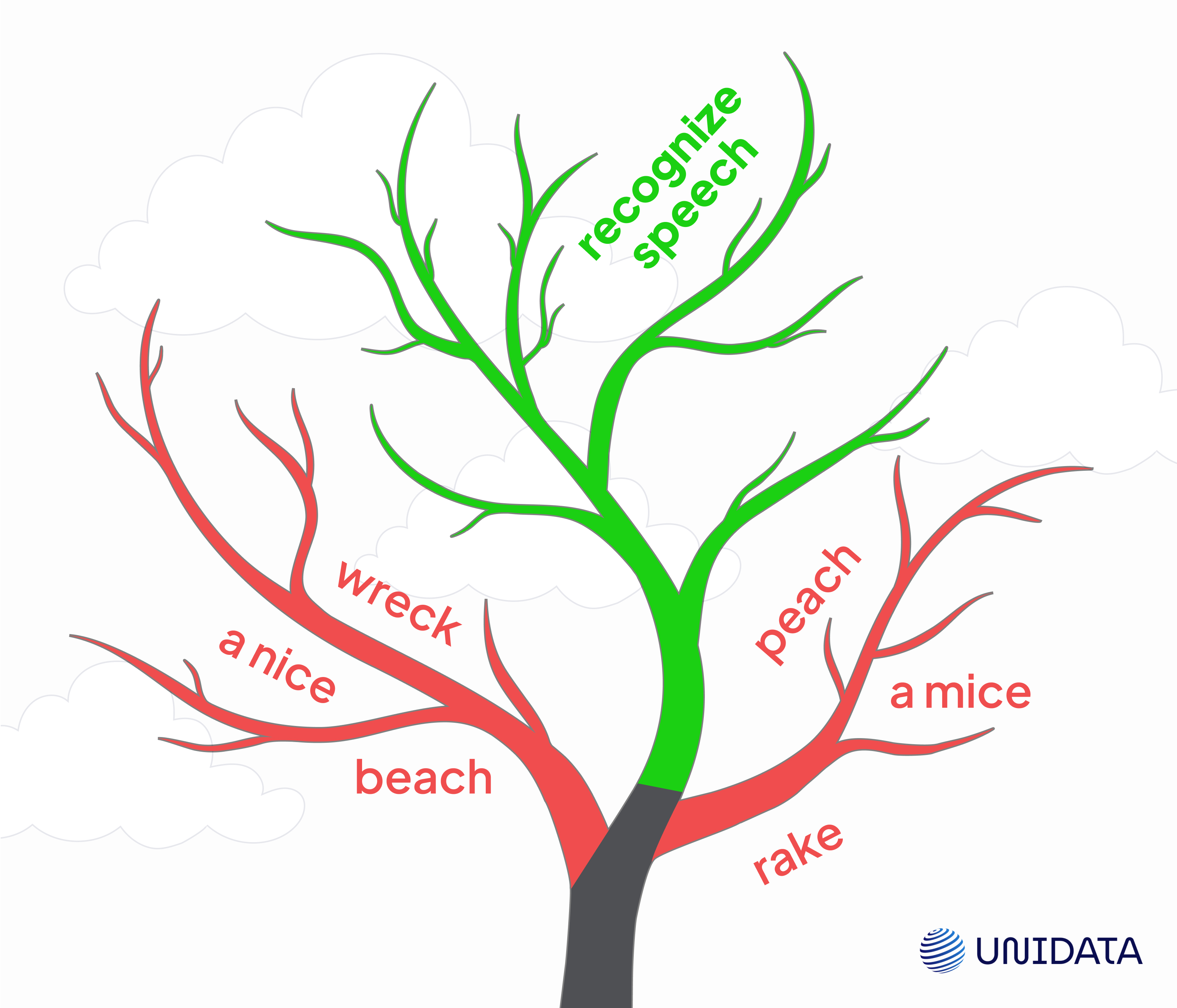
Recognizing phonemes isn’t enough. You need to string them into actual words—and make sure those words make sense together. That’s the job of the language model, which scores and ranks possible word sequences based on context. It helps disambiguate phrases like “recognize speech” vs. “wreck a nice beach,” especially when the audio is imperfect.
Models can be:
- n-gram-based, which are fast but limited to short word windows.
- Neural (LSTM-based), which can track longer sequences.
- Transformer-based, which see the whole sentence or paragraph at once—allowing more accurate predictions even in complex, overlapping speech.
This step is where ASR systems go from phonetic to semantic.
6. Decoding
Finally, the decoder pulls everything together. It takes the acoustic model’s phoneme predictions, the language model’s context scores, and outputs the final transcription. This step may also include confidence scoring, timestamp alignment, or even speaker diarization (figuring out who said what). In real-time applications — like voice assistants or live captions — this all happens in milliseconds.
And just like that, noise becomes language.
4. Key Technologies Powering ASR
No transcripts without tech. Let’s break down the models doing the heavy lifting—from raw sound to fluent output.
Processing Speech Input

These models map audio features to phonemes—the basic sound units like /p/, /k/, or /aa/.
Old-school systems used Hidden Markov Models (HMMs)—linear, rule-based, and easy to break in the wild.
Modern systems rely on neural networks:
- CNNs for detecting localized patterns in sound (edges, bursts, transitions).
- RNNs and LSTMs to model how sounds evolve over time.
- DNNs for robust classification of frame-level features.
Neural acoustic models can adapt to accent shifts, filler sounds, or overlapping speech—HMMs can’t.
Predicting Word Sequences
Phonemes are just noise until we guess the right words. Language models rank possible word sequences and reject gibberish.
- n-gram models are fast but shallow—great for simple domains.
- Neural LMs (RNN-based) add basic context-awareness.
- Transformer LMs like BERT, GPT, and Conformer read the whole sentence at once and predict what makes the most sense.
That’s how ASR avoids misfires like “recognize speech” turning into “wreck a nice beach.”
Full-Pipeline Speech Models
Instead of stitching multiple systems together, these models learn the full pipeline—from waveform to transcript—in a single network.

Leading architectures:
- RNN-T: Built for streaming speech, low latency, mobile-first.
- LAS (Listen, Attend, and Spell): Uses attention to improve alignment.
- Whisper: Trained on huge, multilingual, real-world data. Strong even in noise, accents, or poor-quality audio.
Fewer moving parts. Better generalization. Easier to scale.
5. Accuracy, Bias, and Challenges
Even the best ASR model can still turn “recognize speech” into “wreck a nice beach.” That’s not just a meme—it’s a reminder that accuracy isn’t optional. Especially when the transcript drives search, legal records, or medical notes.
But “accuracy” means more than just getting the words right. Here’s how it’s actually measured:
Key Metrics
| Metric | What It Measures |
|---|---|
| Word Error Rate (WER) | % of substitutions, deletions, and insertions in the transcript. Lower is better. |
| Real-Time Factor (RTF) | How fast the system runs vs. real-time audio. RTF < 1 means it processes faster than speech is spoken. |
| Latency | Delay between someone finishing a sentence and the system displaying it. Critical for live apps. |
WER is the industry standard—but it doesn’t catch everything. A transcript can be 98% correct and still completely wrong in tone or meaning. That’s why performance in edge cases matters just as much.
Major Challenges in ASR (Still Unsolved)
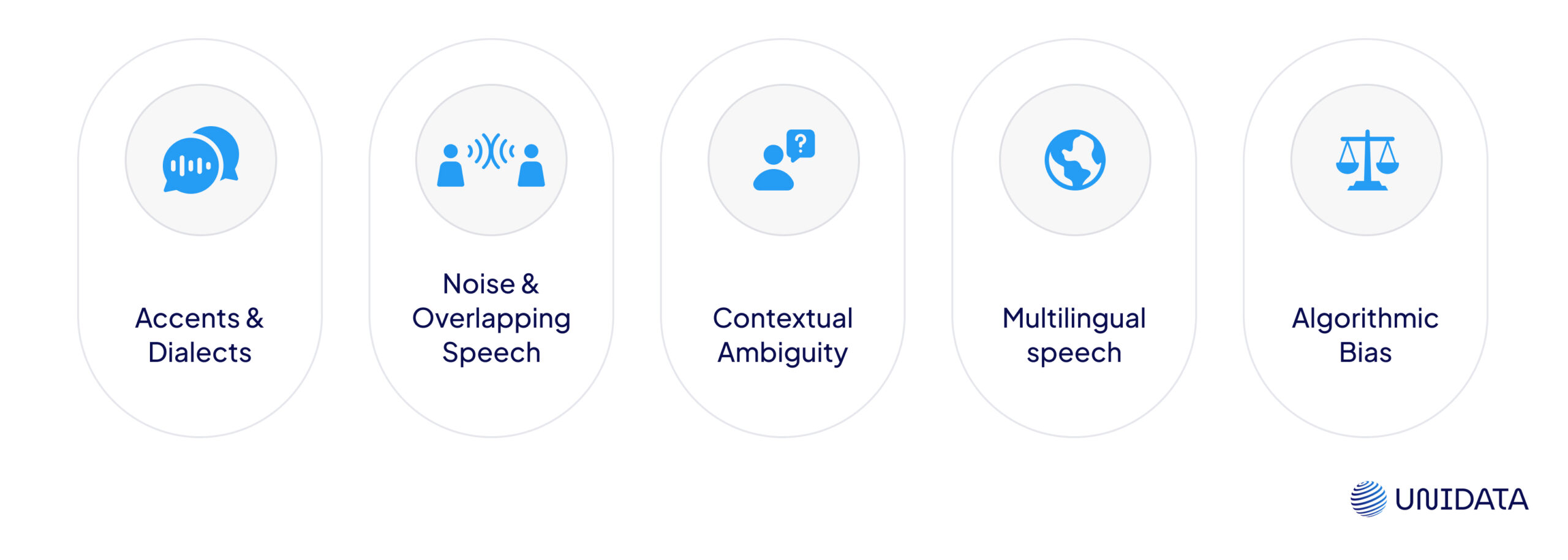
1. Accents & Dialects
Most ASR systems perform well in “standard” English. But throw in a Glaswegian, Nigerian, or deep Southern accent—and performance drops hard. Low-resource accents often get little training data, which skews model understanding.
2. Noise & Overlapping Speech
Background traffic. People talking over each other. Bad microphones. ASR struggles when the signal-to-noise ratio dips—even a little. Meetings, interviews, and phone calls are particularly tough.
3. Contextual Ambiguity
Words that sound the same don’t always mean the same:
“Bass” (music) vs. “bass” (fish). “Write a check” vs. “right a check.” Without strong context modeling, ASR fumbles homophones and specialized jargon.
4. Multilingual Speech
Code-switching mid-sentence—like jumping from English to Spanish—is still a weak spot. Most systems either stick to one language per input or fail when they hear both.
5. Algorithmic Bias
Here’s the uncomfortable part. ASR doesn’t perform equally for everyone.
- Women’s voices are often underrepresented in training data.
- Non-native speakers face elevated error rates.
- Minority dialects (AAVE, Chicano English, etc.) are frequently misrecognized.
A 2020 Stanford study found that commercial ASR systems had nearly 2x the error rate for Black speakers compared to white speakers (Koenecke et al., PNAS, 2020). That’s not just a glitch — it’s an equity issue.
Accuracy isn’t just a metric—it’s a trust factor. And trust breaks fast when certain voices are left behind.
6. Real-World Applications Across Industries
Healthcare
Doctors now dictate notes during exams instead of typing them afterward. This change alone cuts documentation time by up to 40%, improves record accuracy, and helps reduce burnout. Platforms like Nuance’s Dragon Medical One are tailored for medical speech, integrating directly with EHR systems.
Finance
ASR is powering both security and compliance. Voice biometrics replace traditional PINs with spoken phrases for faster, safer identity checks. In call centers, conversations are transcribed and analyzed in real time to flag compliance risks, detect fraud, or assess customer sentiment.
Automotive
Voice control is becoming essential—not optional. Drivers can operate navigation, adjust temperature, or send messages without touching the dashboard. Modern ASR systems are trained to handle fast speech, background noise, and multilingual commands—all in real time.
Education
Live captioning tools like Zoom’s ASR, Google Meet, or Verbit make learning more inclusive and efficient. Students with hearing impairments follow lessons in real time. Transcripts allow learners to revisit lectures later. Language learning apps use ASR to evaluate pronunciation and give instant feedback.
Customer Service
Voicebots powered by ASR now handle common requests like scheduling, password resets, or order status. They don’t just transcribe—they analyze. Calls are scanned for tone, urgency, and keywords so that human agents can jump in faster or let automation take over.
7. The Future of ASR
ASR isn’t just getting better—it’s getting broader, bolder, and more aware of the real world around it.
Multilingual & Code-Switching
Models are learning to handle fluid, mixed-language conversations—like jumping from English to Spanish and back again, mid-sentence. Instead of asking users to choose a language, the system adapts on the fly. This is key for global apps, multilingual families, and borderless workplaces.
Emotion & Sentiment Awareness
The next generation of ASR won’t just transcribe—it’ll understand tone. Was the speaker angry? Confused? Joking?
Emotion-aware models can unlock smarter virtual assistants, better customer service triage, and even mental health monitoring—without the user needing to say anything “explicitly.”
Low-Resource Language Expansion
Right now, ASR works best in major languages. But tools like Facebook’s XLS-R and other self-supervised models are helping systems learn from smaller datasets.
That means ASR could soon support endangered, indigenous, or niche languages—with minimal training examples. A big leap for digital inclusion.
On-Device Processing (Edge ASR)
ASR is also moving closer to users. Models are being compressed and optimized to run directly on phones, cars, and wearables.
Apple’s on-device Siri is one example—no cloud needed, which means faster responses and tighter privacy controls. Voice stays local.
8. Ethical Considerations
As ASR becomes part of high-trust spaces—therapy sessions, financial calls, private notes—ethics can’t be an afterthought. Voice data is deeply personal. Who owns it? How long is it stored? What consent is really being given?
Responsible ASR development means putting guardrails in place: clear data policies, opt-in defaults, and transparency around how transcripts are used.
Accuracy without accountability isn’t progress. It's a risk.
9. Final Thoughts
ASR isn’t just about getting words on a screen. It’s about making tech keep up with how people actually speak—messy, fast, emotional, and all over the map.
It’s already changing workflows across industries. But if it can’t adapt to real voices, protect real privacy, and deliver real fairness, it’s not solving the right problem.
The tech is ready. Now it’s the standards that need to catch up.
Frequently Asked Questions (FAQ)
Top-tier models like Whisper or Google’s latest reach 90–95% word accuracy in clean audio. In noisy, real-world settings, that number drops—especially for accented or overlapping speech.
Yes. On-device ASR (a.k.a. Edge ASR) runs entirely without cloud access. Apple’s Siri and some Android keyboards already do this for speed and privacy.
It depends on the system. Whisper covers 50+ languages. Commercial tools usually support 10–30 well, with varying quality across dialects.
Only if it’s built that way. On-device models offer better privacy. Cloud-based systems depend on encryption, data handling policies, and whether your voice data is stored or deleted.
ASR converts speech to text. Voice assistants go further—they interpret meaning, take action, and sometimes talk back. ASR is just the ears.
Yes. Especially for accuracy in noisy environments or non-standard accents. That’s why modern systems use self-supervised learning on massive audio corpora.










