
Audio transcription is the backbone of many modern workflows, transforming spoken words into text to make content accessible, searchable, and structured. With the rapid advancements in artificial intelligence (AI), this process has become more efficient, accurate, and scalable. Whether you’re a seasoned data scientist or a newcomer exploring this field, understanding audio transcription—from its fundamentals to the latest AI-powered tools—is essential.

What is Audio Transcription?
At its core, audio transcription is the process of converting spoken language from audio recordings into written text. This seemingly simple concept has profound applications in industries like healthcare, legal, media, and technology.
It is worth mentioning that there are two broad forms of audio transcription – speech-to-text (STT) and text-to-speech (TTS).
STT converts spoken language into text, facilitating tasks like transcription and real-time captions, while TTS transforms text back into spoken language, making content accessible to visually impaired users or aiding language learning. For example, STT is instrumental in creating accurate subtitles for videos, while TTS enriches interactive voice response (IVR) systems, creating a seamless bridge between textual and auditory content. Together, these technologies ensure accessibility, preserve critical information, and expand the potential use cases of audio data across various domains.
Traditional vs. AI-Powered Transcription
Historically, transcription relied heavily on human effort. Transcribers would listen to audio, pause, rewind, and type out spoken words. While accurate, this method was time-consuming and labor-intensive.
Today, AI transcription leverages machine learning (ML) models and automatic speech recognition (ASR) systems to automate this process. Tools like Whisper by OpenAI and Google Speech-to-Text offer real-time transcription with impressive accuracy, transforming the industry landscape.
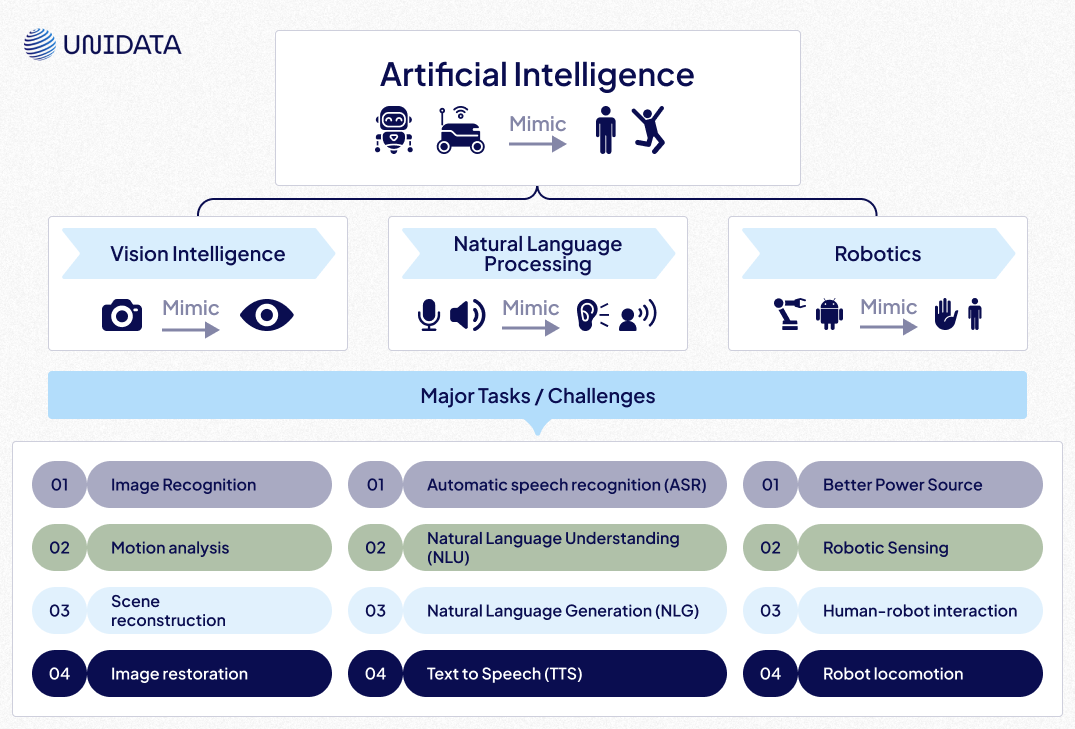
How Audio Transcription Works

To better understand the transcription process, let’s break it down into three key approaches:
1. Manual Transcription
Human transcribers play a vital role in ensuring contextually accurate and grammatically correct transcripts. Tools like foot pedals and specialized software can aid their efficiency, but the process remains labor-intensive and costly for large-scale projects.
2. Automated Transcription
AI transcription systems use ASR technology to analyze audio signals, identify speech patterns, and convert them into text. These systems rely on advanced ML models trained on vast datasets to recognize accents, handle background noise, and even distinguish between multiple speakers.
3. Hybrid Transcription
This approach combines the speed of automated transcription with the precision of human editing. AI generates a preliminary transcript, which a human transcriber refines for errors or nuances that machines might miss.
Organization of Work in Our Team
Our team specializes in manual transcription projects, emphasizing quality and attention to detail. We adapt to the specific requirements of each project, working either within the client’s environment or using our proprietary tools. Often, our work involves editing pre-annotated data, where annotators refine the output of automated transcription systems.
However, we also handle projects requiring transcription from scratch—particularly in challenging scenarios such as:
| Scenario | Challanges |
|---|---|
| Low-Quality Audio | Cases with poor audio clarity or significant background noise. |
| Overlapping Speech | Transcribing parallel conversations accurately. |
| Complex Speech Patterns | Handling difficult-to-discern dialogue or specialized terminologies. |
Requirements for Annotators
To ensure high-quality results, annotators must meet specific requirements:
- A quiet workspace to minimize external distractions.
- High-quality headphones for precise audio analysis.
- Normal hearing capability, as auditory impairments can hinder transcription accuracy.
Examples of Our Projects
Our expertise spans a wide range of transcription scenarios:
- Telephone Conversations: The most common use case involves transcribing phone calls, often for customer service or business analysis.
- Medical Dialogues: Transcribing conversations between doctors and patients, often recorded using wearable devices like badge microphones.
- Airport Interactions: Documenting discussions, frequently focused on banking or financial transactions, captured in busy airport environments.
Tools We Use
Depending on the project, we work with:
- LabelStudio: Our preferred tool for transcription when using proprietary software.
In LabelStudio it’s possible to pick any audio from the list for transcription regardless of the status of the previous task. It can be both convenient and a bit confusing for annotators and the manager not to get lost in the multitude of tasks. So we organize the work process by submitting particular audio ranges to each annotator, for example: audio files from “0001” to “0101”.
This is how the transcribing process works:
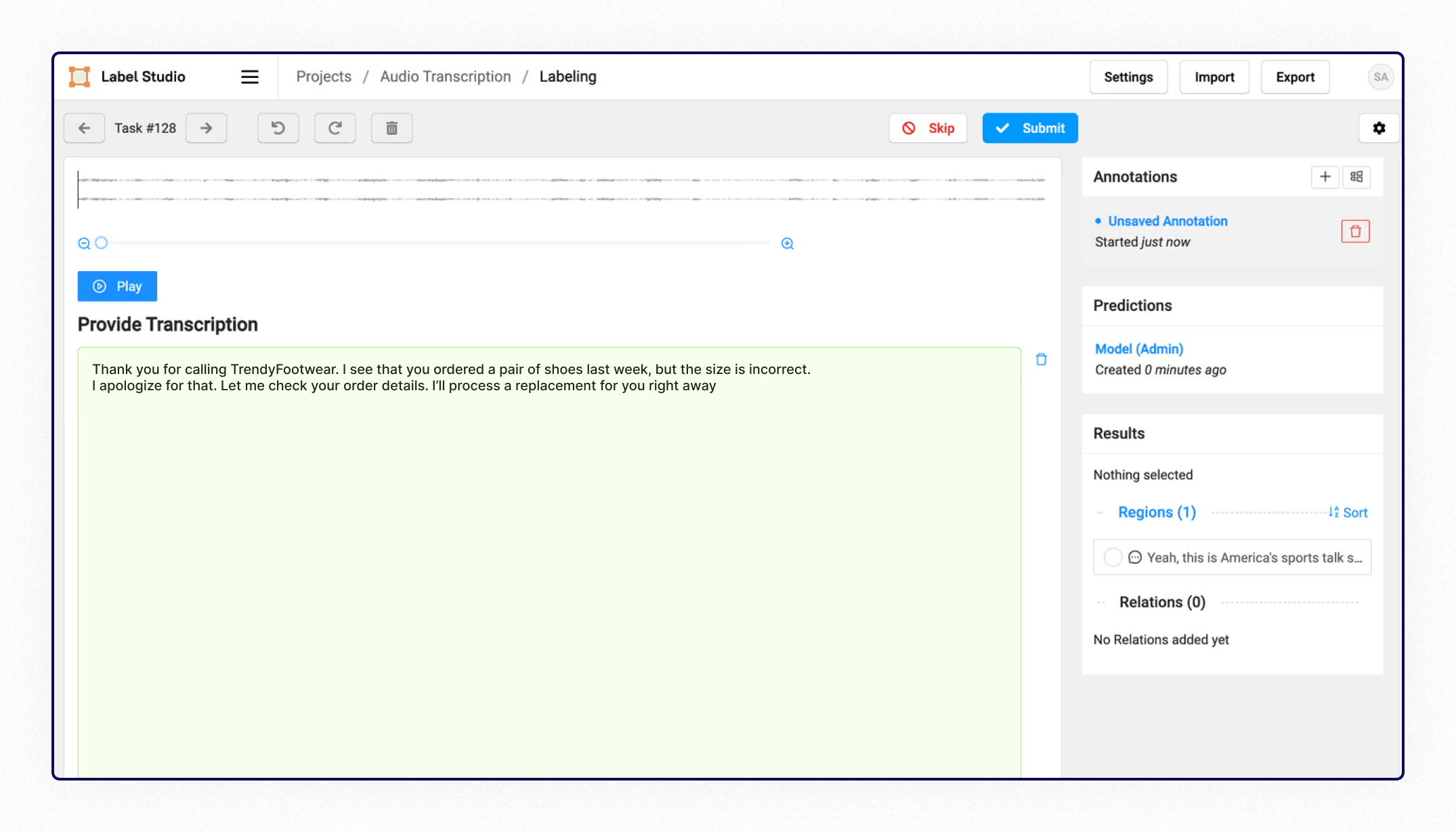
There can be tasks involving annotating audio tracks by different speakers, which we also do:
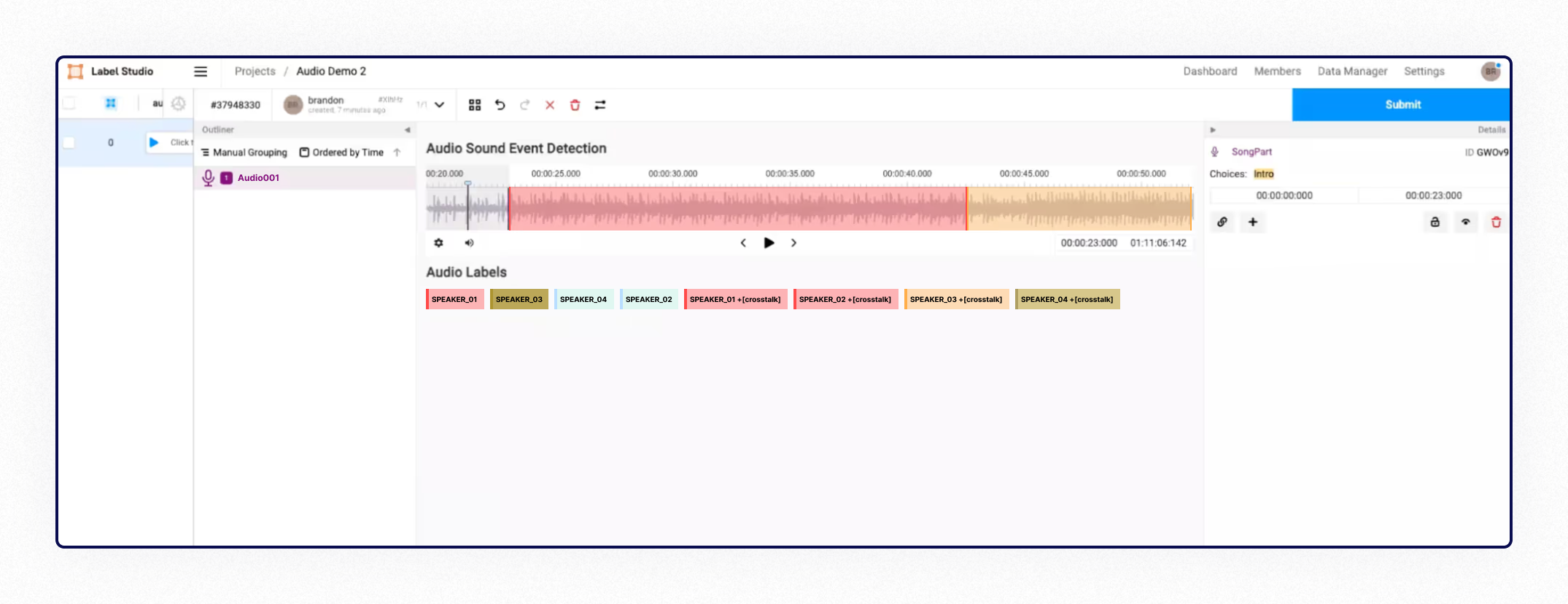
- Client-Specified Platforms: We are quite adaptable to working with clients’ preferred tools as well:
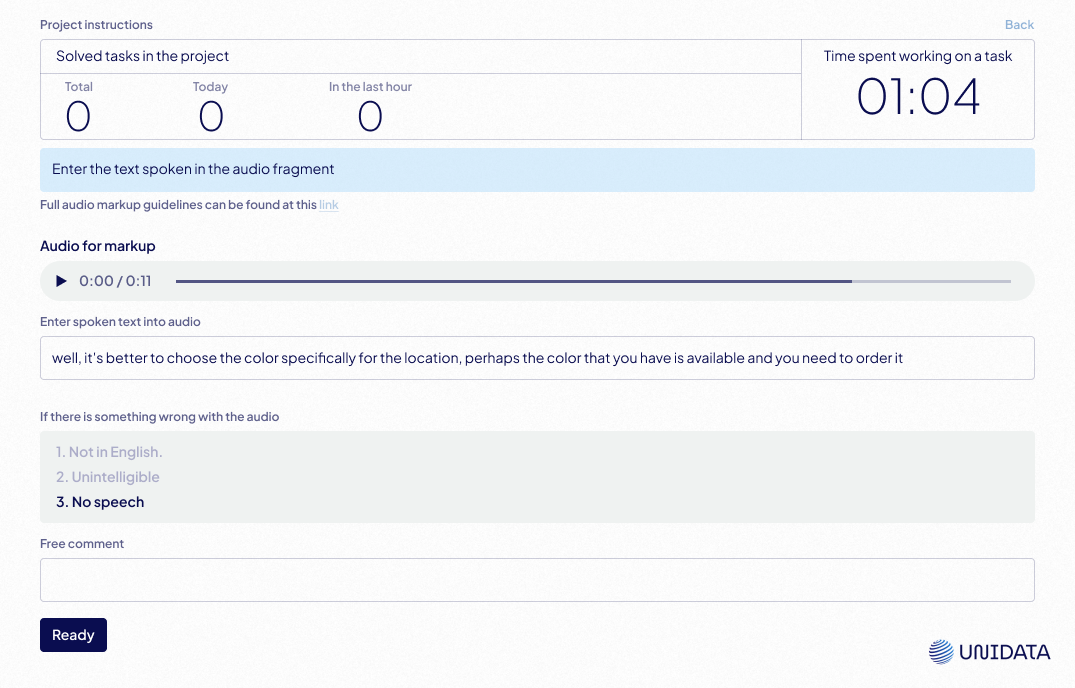
Tips for Effective Transcription
Multi-Highlight Tools: These tools highlight words or characters to improve focus and speed.
Audio Amplifiers: Essential for handling low-volume audio files.
Unique Considerations
Each project comes with its own set of challenges. For instance, technical guidelines may dictate whether to transcribe non-verbal sounds such as coughing or laughter. Our team customizes the transcription process to align with the specific requirements of each client, ensuring precision and consistency.
AI Technologies Behind Audio Transcription
Natural Language Processing (NLP)
Natural Language Processing (NLP) is a multifaceted field that enables machines to process, understand, and generate human language. It encompasses several components, including syntax analysis, sentiment detection, and semantic understanding, all of which contribute to making machine interactions with human language more natural and meaningful. Within the transcription context, NLP plays a crucial role in interpreting idioms, resolving ambiguities, and understanding the speaker's intent.
Automatic Speech Recognition (ASR):
ASR is a specialized subset of NLP dedicated to converting spoken language into text by analyzing audio waveforms. It bridges the gap between raw audio and structured text using sophisticated techniques like phoneme recognition, acoustic modeling, and language modeling. Innovations such as Whisper's transformer-based architecture have brought significant advancements to ASR, enabling it to handle noisy environments, diverse accents, and complex linguistic structures.
Tools and Platforms for Audio Transcription
Choosing the right transcription tool depends on your needs, budget, and technical expertise. Here are some top options:
AI-Powered Tools
- Whisper by OpenAI: Known for handling complex accents and noisy backgrounds, Whisper provides customizable solutions tailored to technical specifications. For example, it can be configured to include or exclude non-verbal sounds like laughter, based on project requirements.
- Google Speech-to-Text: Offers robust multilingual support and easy integration into various platforms. Customization options allow users to adapt the tool for domain-specific terminology, enhancing transcription accuracy.
- Otter.ai: Ideal for collaborative transcription with real-time capabilities. It includes features like speaker identification and the ability to adjust the transcript for specific contextual nuances.
- Rev.ai: Delivers high accuracy with an intuitive interface. The platform also supports customization for punctuation styles, speaker tagging, and other specific formatting needs.
Open-Source Libraries
- Wav2Vec: A powerful framework for building custom ASR models. Its adaptability makes it suitable for projects requiring high precision, such as transcribing medical terminologies or handling regional accents.
- Kaldi: Favored by researchers for its flexibility and extensive community support. It allows fine-tuning to include specific technical details, such as transcribing ambient noises or ignoring them based on client requirements.
| Tool | Key Features | Ideal For |
|---|---|---|
| Whisper | Multilingual, noise-resistant | Researchers |
| Otter.ai | Real-time, collaborative | Teams |
| Google Speech | Easy integration, scalable | Developers |
| Rev.ai | High accuracy, user-friendly | Businesses |
Practical Comparison with Manual Transcription
When comparing these tools to manual transcription, none fully match the nuanced understanding and contextual adaptability humans bring to the process. However, some tools come closer than others:
- Closest to Manual Transcription: Whisper and Rev.ai. Both tools demonstrate a strong ability to handle complex audio scenarios and offer customization features that align well with specific project requirements.
- Moderately Comparable: Google Speech-to-Text and Otter.ai. These tools perform well for general transcription tasks but fall short in handling intricate or ambiguous cases.
- Least Comparable: Wav2Vec and Kaldi. While powerful in specific contexts, their effectiveness depends heavily on customization and technical expertise, making them less accessible and adaptable than manual transcription for diverse projects.
Challenges in Audio Transcription
While AI transcription offers numerous benefits, it’s not without its share of challenges. These hurdles underscore the importance of tailoring transcription solutions to specific use cases and employing a hybrid approach where necessary. Some of the primary challenges include:
- Audio Quality: Factors like background noise, subpar recording equipment, and overlapping speech significantly impact transcription accuracy. Poor audio quality often requires manual intervention to achieve reliable results, especially in critical applications.
- Accents and Dialects: The diversity of accents and regional dialects poses challenges for transcription models, particularly those trained on limited datasets. Addressing this requires continuous training and fine-tuning of models with diverse audio samples.
- Multiple Speakers: In conversations with overlapping speech, distinguishing between individual speakers remains a technical hurdle for AI systems. Manual transcription or advanced speaker diarization tools are often necessary to ensure clarity.
- Domain-Specific Jargon: Fields like medicine, law, and technology frequently involve specialized terminology. Handling such jargon requires models trained on domain-specific datasets or the inclusion of human expertise to ensure contextual accuracy.
Best Practices for Accurate Transcription
To mitigate these challenges and achieve high-quality transcription, consider the following best practices:
1. Ensure High-Quality Recordings
High-quality recordings form the foundation of accurate transcription. Using reliable microphones and recording in controlled, quiet environments minimizes background noise and enhances the clarity of spoken words. Encouraging speakers to articulate clearly can also improve results.
2. Use Speaker Identification
In scenarios with multiple speakers, using tools or techniques for speaker identification can add significant clarity to transcripts. Tagging individual speakers ensures the transcript reflects the conversation’s flow and structure accurately.
3. Leverage Contextual Training
Customizing transcription models with domain-specific datasets can greatly enhance their performance. For instance, training a model on medical conversations equips it to handle terms like “echocardiogram” or “pulmonary embolism,” which might otherwise be misinterpreted by general-purpose systems.
Use Cases
Audio transcription plays a pivotal role across various industries. Below are some key project types, ranked from most to least applicable based on the significance of transcription accuracy and accessibility:
- Media Production: Creating subtitles for videos, podcasts, and films ensures broad accessibility and audience engagement. Accurate transcripts also enable better content indexing for search engines.

- Education: Transcribing lectures, webinars, and training sessions provides learners with detailed materials for review and study, ensuring no vital information is missed.
- Healthcare: Medical transcription plays a critical role in documenting doctor-patient interactions, improving patient care, and ensuring compliance with legal standards.
- Legal Proceedings: Courtroom recordings and legal depositions require meticulous transcription for accurate documentation and case analysis. AI tools can assist, but human verification remains essential.
- Market Research: Transcripts of focus groups and interviews are invaluable for analyzing consumer behavior, identifying trends, and gaining insights from qualitative data.
- Corporate Meetings: Documenting internal discussions supports better decision-making, provides a reliable record of key points, and ensures transparency within teams.

- Customer Service Calls: Transcripts enable the analysis of customer needs, improvement of service quality, and adherence to regulatory compliance, particularly in industries like banking and telecommunications.
Each of these applications demonstrates the versatility and value of transcription in transforming audio content into actionable insights.
Future Trends in Audio Transcription
Enhanced AI Models
Emerging models like GPT-based systems promise greater contextual understanding and error handling.
Real-Time Transcription
Real-time applications, such as live event subtitling and virtual meetings, are becoming more sophisticated.
Integration with Broader AI Ecosystems
Transcription tools are increasingly integrated with virtual assistants, customer service chatbots, and data analysis platforms.
How to Implement Audio Transcription Using AI
For Machine Learning Practitioners
- Data Collection: Gather diverse, high-quality audio datasets.
- Model Training: Use frameworks like TensorFlow or PyTorch to train ASR models.
- Evaluation: Test performance using metrics such as Word Error Rate (WER).
For Beginners
- Choose a Tool: Start with user-friendly platforms like Otter.ai.
- Upload Audio: Prepare and upload recordings for transcription.
- Refine Output: Edit the transcript for accuracy and formatting.
Conclusion
Audio transcription has evolved from manual labor to AI-driven precision, offering faster, more scalable solutions. By understanding the tools, techniques, and challenges involved, you can leverage transcription to streamline workflows, enhance accessibility, and unlock new possibilities in data analysis. Whether you’re a seasoned professional or just starting, the future of transcription is undoubtedly shaped by AI. Start exploring today to stay ahead of the curve!
Frequently Asked Questions (FAQ)
AI tools achieve up to 90-95% accuracy, depending on audio quality and complexity.
Otter.ai and Rev.ai are excellent options due to their intuitive interfaces.
Yes, tools like Wav2Vec and Kaldi allow practitioners to build custom ASR models.
Advanced models use speaker diarization to distinguish between speakers, though this may require further refinement.
Healthcare, legal, media, and education are leading adopters of transcription technology.










