Imagine reading “Paris” in a sentence. Are we talking about the capital of France, Paris Hilton, or the ancient hero from Greek mythology? Humans use context. Machines? They use entity linking.
Entity linking is the process of taking a mention in text — like “Paris” — and matching it to a unique entry in a structured knowledge base like Wikidata or DBpedia.
Unlike Named Entity Recognition (NER), which just spots the name, EL figures out who or what it actually is. That’s the core difference.
Mini Infobox: NER vs EL vs Coreference
| Task | Goal | Example |
|---|---|---|
| Named Entity Recognition | Detect that “Apple” is an entity | “Apple” = Organization |
| Entity Linking | Link it to a specific node in a KB | “Apple” → Apple_Inc. in Wikidata |
| Coreference Resolution | Track that “it” refers back to “Apple” | “Apple released a new iPhone. It sold out fast.” |
EL also leans heavily on knowledge bases — structured databases that define entities, their types, and their relations. Without them, linking would be guesswork.
Why It Matters
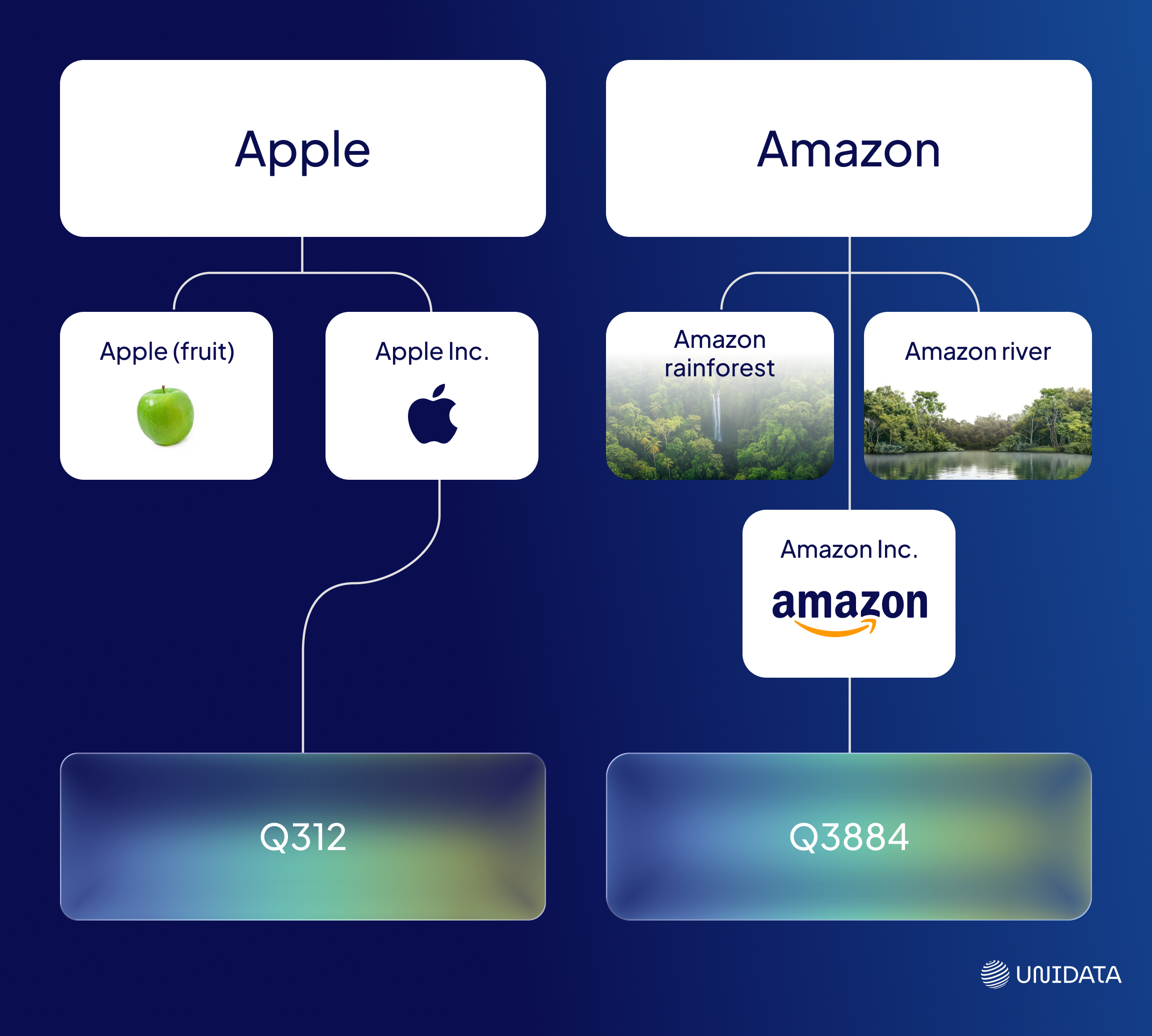
Labeling is easy. Linking is smart. Modern systems don’t just want to tag “Apple” or “Amazon” — they need to know whether the user means the brand, the river, or the rainforest.
And they need to know it fast, across millions of documents, in dozens of languages, and often with zero room for error.
That’s where entity linking shines. It’s the layer of intelligence that turns raw text into actionable knowledge. Not just words, but grounded, referenceable concepts. Not just “Barack Obama,” but Q76 in Wikidata. Not just “HPV,” but the exact UMLS concept in a patient record.
Entity linking is what powers:
- Smarter search that understands what you meant — not just what you typed
- Cleaner knowledge graphs where “Paris Hilton” and “Paris, Texas” don’t get lumped together
- More personalized recommendations, based on precise connections between people, places, products, and interests
- Accurate analytics that group mentions correctly, even when the phrasing varies wildly
In other words: if your NLP pipeline stops at NER, you're leaving clarity — and business value — on the table.
The Business Case
Entity linking doesn’t just improve machine understanding. It boosts discoverability, visibility, and user experience at scale.
In SEO, it underpins semantic search. By tying your content to recognized entities (via Schema.org tags like sameAs, about, or @id), you’re speaking Google’s native language. That can mean:
- Richer snippets
- Higher CTRs
- Faster indexing
- Eligibility for knowledge panels
When Google can confidently map your content to a real-world entity, your ranking improves. Your reach grows. And your competition? They’re still playing catch-up.
Even the Knowledge Panel — the holy grail of brand presence — is built on top of structured entity linking.
So yes, it’s technical. But it’s also commercial. And in a world drowning in content, clarity wins.
How Entity Linking Works (Step by Step)
Let’s break it down like a recipe. Four steps, one goal: turn ambiguous words into unambiguous meaning.
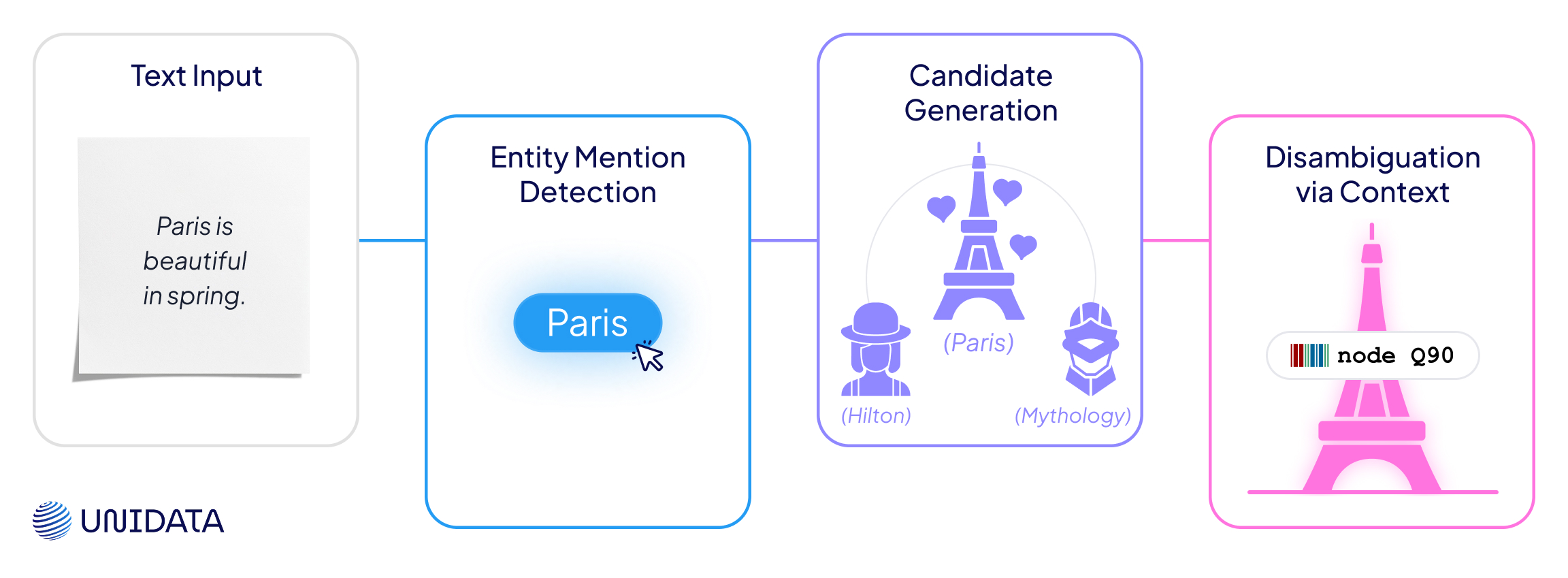
- Entity Mention Detection
First, the system needs to spot the thing we might want to link. This could be a name, a place, a product — anything that might correspond to a real-world entity.
This step is often handled by NER models or pattern-based rules.
Input: “Paris is beautiful in spring.”
Output: ["Paris"]
Nothing fancy yet — we’re just saying, “This might be something important.”
- Candidate Generation
Now the model pulls in a list of possibilities from a knowledge base. For “Paris,” it might surface:
- Paris, France
- Paris Hilton
- Paris (Greek mythology)
- Paris, Texas
This is like brainstorming everything the mention could mean.
- Candidate Ranking
Here’s where context kicks in.
The system looks at surrounding words (“Eiffel Tower,” “Seine,” “spring”) and asks: Which of these candidates makes the most sense here? It might also check for global coherence — do other mentions in the text support one interpretation over another?
If “France,” “Europe,” or “Louvre” appear nearby, that’s a strong signal.
Clue: “Eiffel Tower” nearby → boost score for Paris, France.
- Disambiguation and Linking
The top-scoring candidate wins. The mention is now linked to a specific entity in a knowledge base.
Final link: “Paris” → wd:Q90 (Paris, France)
From vague string to precise knowledge. Just like that.
Popular Methods and Models
So how do systems actually pull this off — finding the right “Paris” or linking “Apple” to the tech giant and not the fruit?
There’s no one-size-fits-all formula. Over the years, researchers and engineers have taken three main paths — each shaped by the same goal: link fast, link right, and don’t break under pressure.
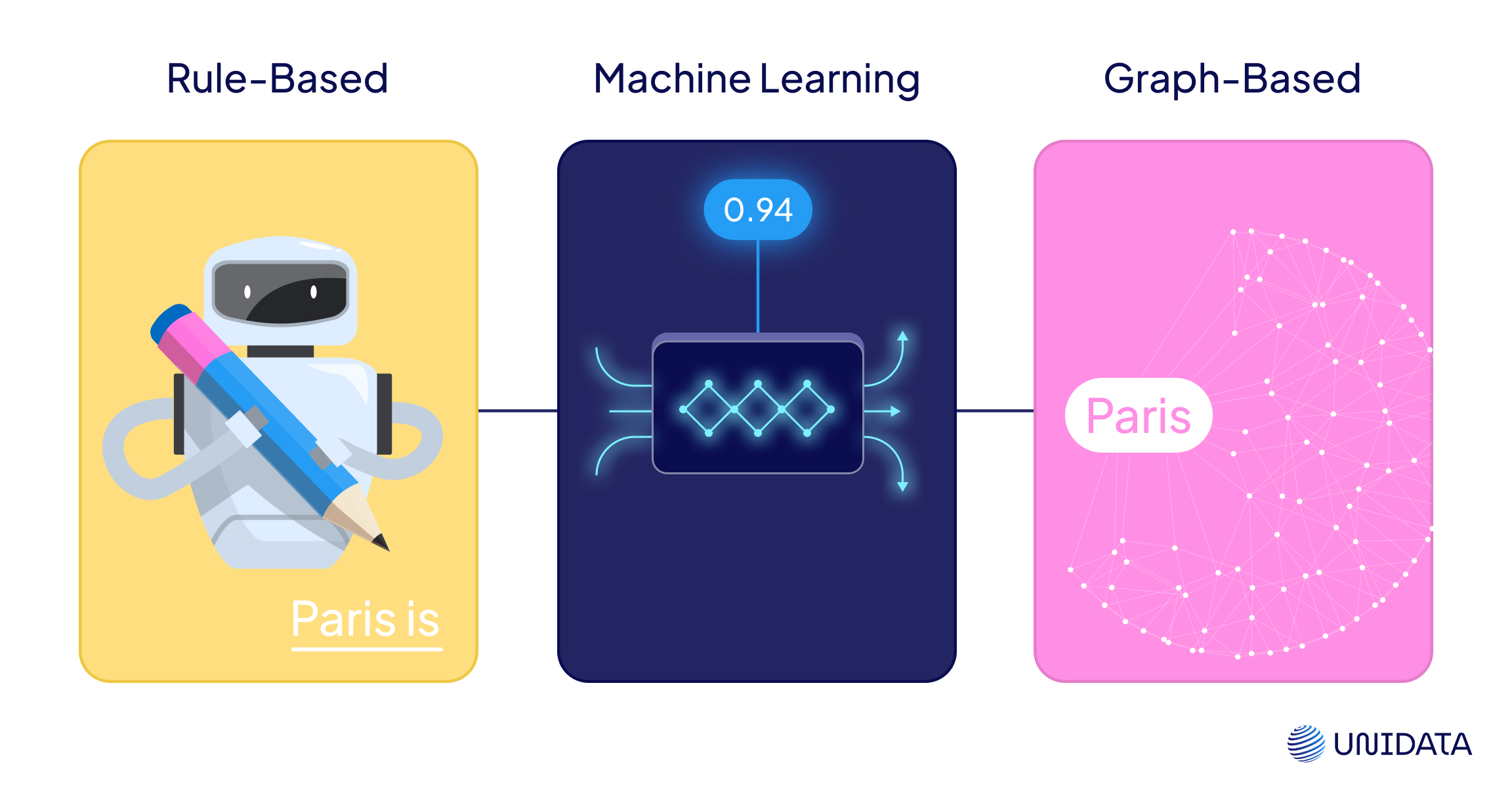
Rule-Based Methods
The original approach to entity linking was all about logic, not learning. These systems relied on hard-coded rules, string matchers, and curated alias lists to match mentions to entities. And in tightly controlled environments, they still hold their own.
What makes them work: They’re fast, predictable, and easy to debug. You can trace exactly why a mention was linked — or why it wasn’t. This level of transparency is critical in regulated fields like law, healthcare, or government, where auditability matters.
Where they fall short: Rule-based systems don’t scale well to open-ended language. They’re brittle when faced with noisy input, typos, or unfamiliar phrasing. Adapting them to new domains means rewriting logic and expanding dictionaries — often by hand.
Where they shine: In well-bounded domains with fixed vocabularies — like legal clauses, pharma product catalogs, or internal enterprise data — rules are still remarkably effective.
Machine Learning & Deep Learning
The machine learning approach turns entity linking into a ranking game. Given a mention and its context, the model learns to choose the right entity from a pool of candidates — based on patterns it finds in labeled data.
What makes them work: These models are domain-flexible and can handle noisy, ambiguous text with impressive accuracy. Transformers like BERT and RoBERTa changed the game by allowing systems to understand nuanced context and work across languages.
Where they fall short: ML models need large, high-quality datasets to reach their potential. They can also be opaque — when something goes wrong, debugging is far from straightforward. You’re trading rule transparency for probabilistic power.
Where they shine: For general-purpose NLP pipelines — news feeds, social media, customer support, enterprise search — ML-based EL is the go-to. It adapts, scales, and performs well in production, especially when trained on relevant data.
Graph-Based Models
Graph-based methods use structure, not just context. Entities are treated as nodes in a graph; relationships between them form edges. Linking is guided by how well a mention fits into the wider network of meaning.
What makes them work: These models capture global coherence — the idea that all entities in a document should make sense together. Graph neural networks (GNNs) take this even further, modeling dependencies and reinforcing entity choices based on the broader graph structure.
Where they fall short: They require a high-quality, richly connected knowledge base. Setting up and maintaining that graph isn’t trivial — and the computational load can be heavy. But if the KB is solid, the gains in accuracy are real.
Where they shine: When your data already lives in a graph — think biomedical ontologies, enterprise taxonomies, or Wikidata — graph-based linking can outperform everything else, especially in tasks that need fine-grained disambiguation and explainable connections.
This is where things start feeling like knowledge engineering again — but smarter.
Model Snapshot: Who’s Leading the Pack?
| Model | Strengths | Weaknesses | Best Use Case |
|---|---|---|---|
| BLINK (Facebook) | Fast, multilingual, robust | Tied to static Wikipedia data | QA systems, real-time linking |
| ReFinED (Google) | Lightweight, zero-shot friendly | Less tunable for niche domains | Scalable SaaS, API-first deployments |
| AIDA | Stable, well-documented | Lacks deep learning capabilities | Teaching, benchmarking |
| NCEL | Uses graph structure + context window | Slower, compute-heavy | Structured domains, research graphs |
TL;DR:
- Need a plug-and-play solution? → Use ReFinED
- Working across news, forums, or multi-language corpora? → Go with BLINK
- Building your own knowledge base? → Try NCEL
- Just testing your model against a gold standard? → AIDA still delivers
Where It’s Used: Real-World Applications
Legal Tech

Law firms use EL to link cases, parties, and laws across documents. It powers smarter search, contract review, and legal research automation.
“Section 230” → U.S. Communications Decency Act
“Smith vs. Jones” → Court database entity
Healthcare
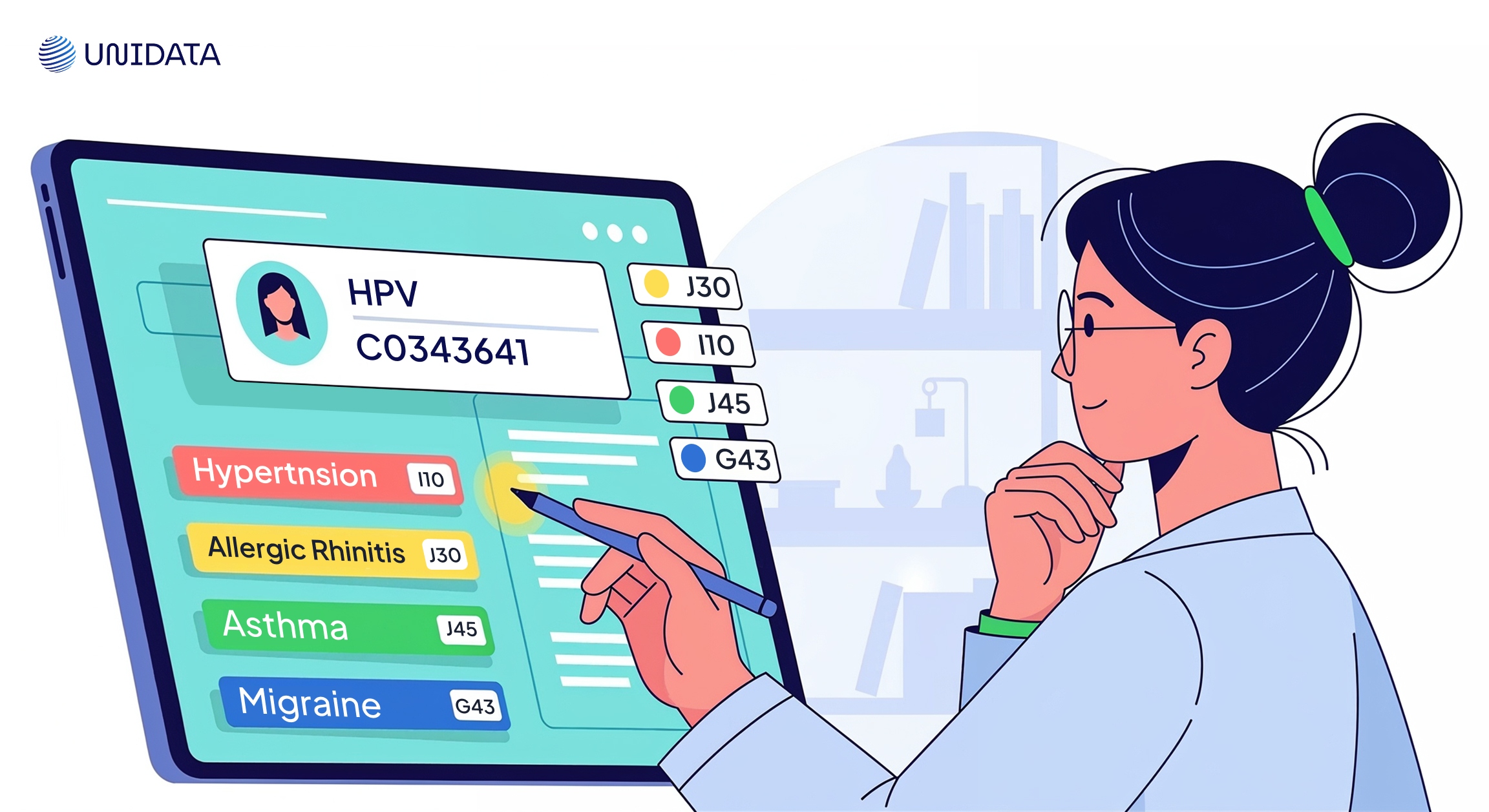
Medical records and research papers are dense with mentions like “HPV,” “insulin,” or “Stage III melanoma.” EL links these to ontology-backed codes (e.g., SNOMED CT), improving interoperability and clinical decision support.
“HPV” → C0343641 in UMLS
SEO & Schema.org
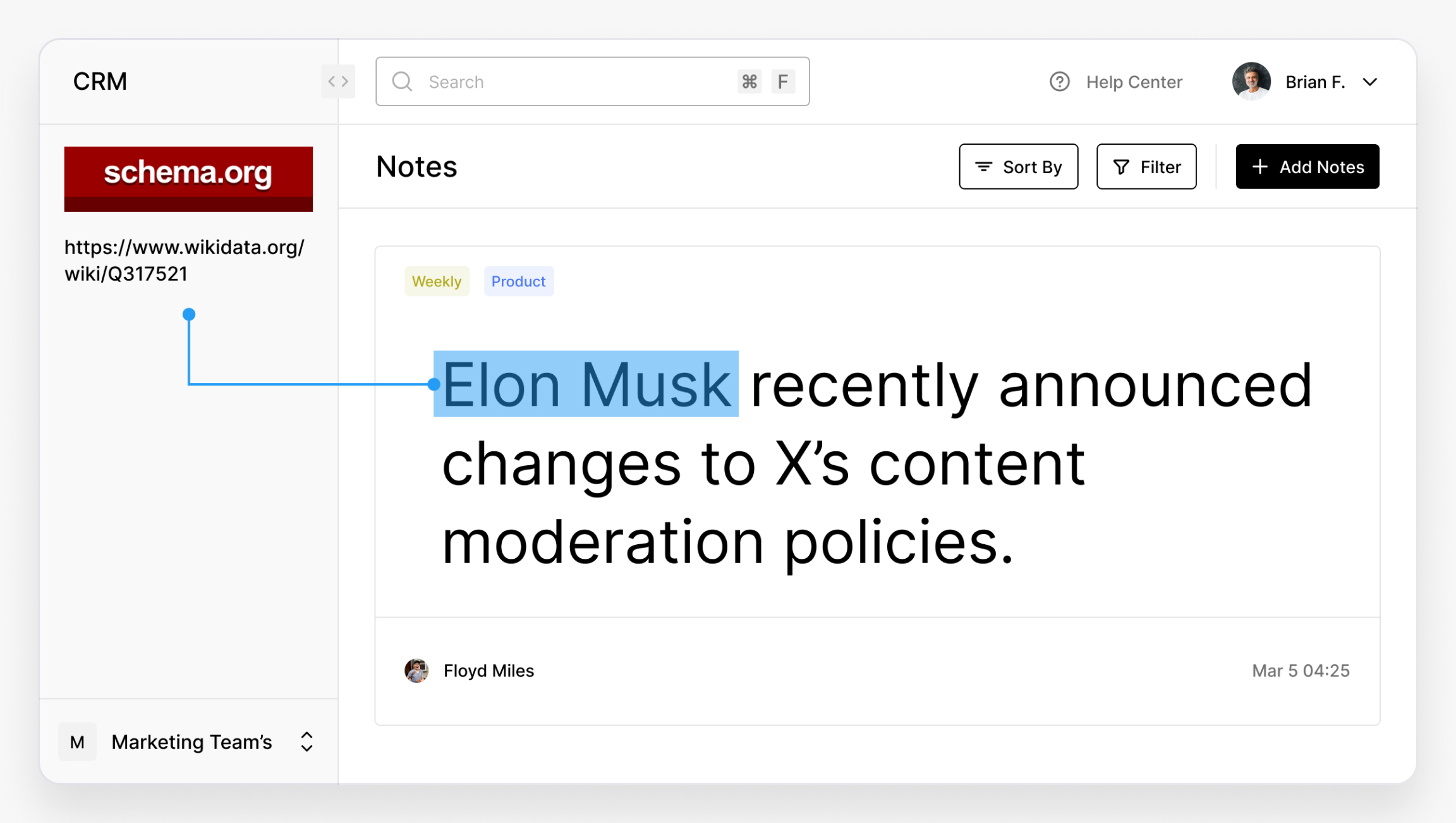
Content marketers use EL to improve structure, rich results, and indexing. Linking terms to Schema.org or Wikidata entities enables enhanced search features.
“Elon Musk” → https://www.wikidata.org/wiki/Q317521
News & Media Monitoring
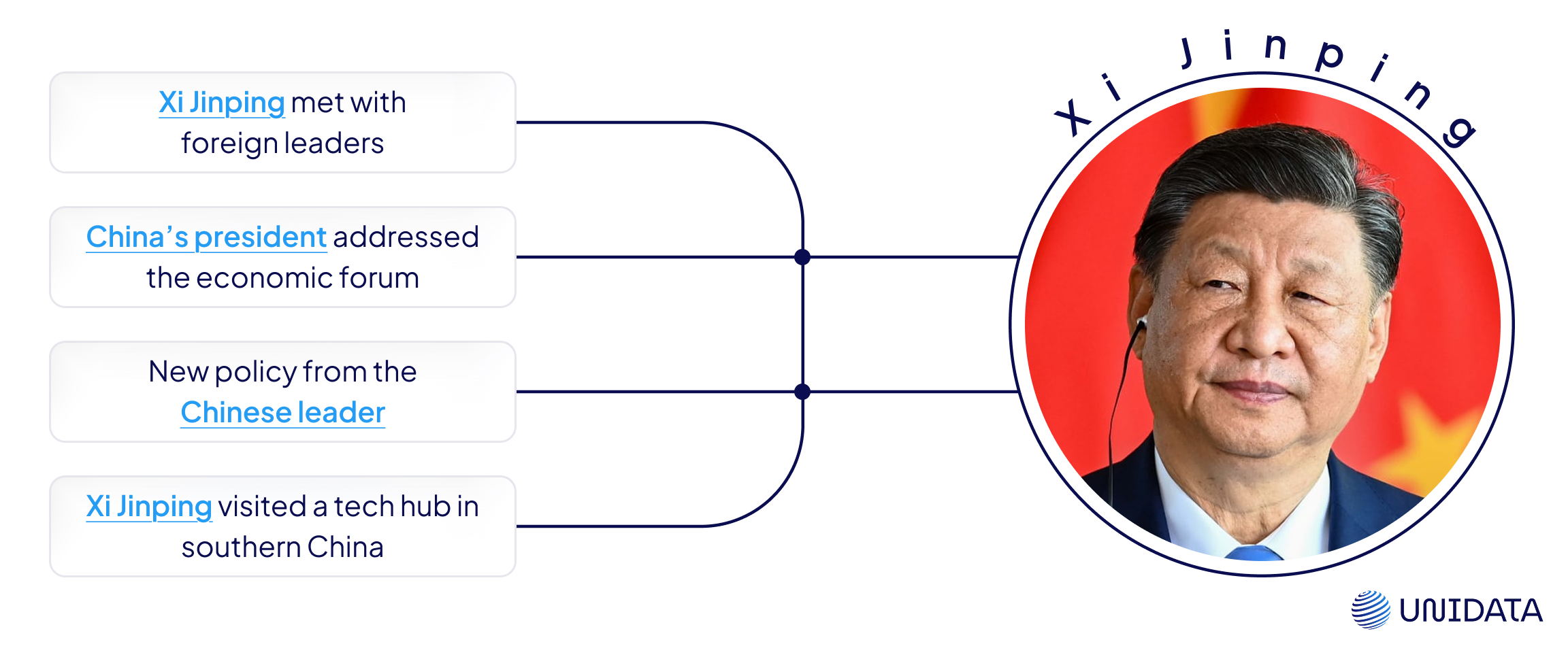
News aggregators link entities across stories for clustering, trend tracking, and alerting.
“Xi Jinping” in 5 headlines → one canonical node → alert triggers when sentiment shifts.
SEO Case Study: Boosting Click-Through with EL
By linking product mentions to real entities in structured data, one e‑commerce client saw:
- +12% CTR on rich snippets
- -18% duplicate content penalties
- Faster appearance in Google Knowledge Graph
Tools and APIs You Can Try
You don’t need to reinvent the wheel to get started with entity linking. There’s a growing ecosystem of tools — open-source, cloud-based, and everything in between.
Open-Source Options

- spaCy + add-ons – Not native EL, but extensions like scispacy or third-party wrappers enable linking on top of existing NLP pipelines.

- DeepPavlov – Comes with out-of-the-box NER and EL pipelines. Best suited for research or small-scale production.

- BLINK – Facebook’s open-domain EL model with strong multilingual support. Trained on Wikipedia; plug-and-play via HuggingFace.

- REL (Radboud Entity Linker) – Easy to integrate and optimized for both performance and clarity.
Cloud & Enterprise APIs

- Microsoft Azure Text Analytics – Part of their Cognitive Services suite; supports EL through linked entities with context.
- Google Cloud NLP – Offers entity linking for recognized entities but limited customization.
- ReFinED via HuggingFace or internal integration – Ideal for lightweight, zero-shot use cases.
Challenges and Limitations
Entity linking might sound neat and tidy — but real-world language is anything but. Ambiguity, edge cases, and incomplete data make it one of the toughest tasks in modern NLP.
Ambiguity and Polysemy
“Apple” can be a tech company, a fruit, or even a music label. Without enough context, models are forced to guess — and often get it wrong. This is especially tricky in short texts like tweets, headlines, or chat logs, where there’s not much to go on.
Name Variants and Abbreviations
Humans know that “B. Obama,” “Barack H. Obama,” and just “Obama” all point to the same person. Machines don’t — unless they’ve been trained to handle variants, nicknames, initials, and misspellings. Getting this wrong leads to fractured analytics and broken search.
Knowledge Base Gaps
If the entity doesn’t exist in your knowledge base, it can’t be linked — no matter how advanced your model is. This becomes a major blocker in niche domains (e.g. pharmaceuticals, regional politics) and in languages where resources are scarce.
Domain Adaptation
Most entity linking models are trained on open-domain data like Wikipedia. But transplant them into legal contracts or clinical notes, and accuracy drops fast. Adapting to a new field usually means re-labeling data, retraining models, and managing new edge cases — time-consuming, but essential for real-world reliability.
Latency and Scale
Linking a few mentions? Easy. Linking thousands per second in a live system? That’s where things get tough. Large models and cloud APIs add latency, which can bottleneck entire pipelines. Production systems need tight control over throughput, caching, and fallbacks.
When Humans Still Matter
Even the smartest models can’t handle every edge case. In sensitive domains, human-in-the-loop workflows still play a key role — especially when:
- Ambiguity is high
- Accuracy requirements are strict
- The knowledge base needs to evolve dynamically
This is common in legal review, clinical documentation, and any high-risk use case where a bad link could create downstream errors — or even liability.
Main Takeaways & How to Start
Entity linking isn’t just another NLP add-on — it’s the backbone of systems that actually understand what words refer to. It connects names to meaning, turns unstructured text into structured knowledge, and powers smarter search, cleaner analytics, and better SEO.
If you're building anything that needs context, clarity, or content enrichment — this is the layer that makes it all work. From product catalogs to news feeds to internal data lakes, entity linking is what keeps language grounded in reality.
Need help?
We build high-quality EL pipelines — from annotation to validation. Let's get your text talking to real-world knowledge.