Top 20 healthcare datasets for machine learning—free, diverse, and ready to train. Includes EHRs, X-rays, dialogues, audio, and commercial-grade data.

Why Healthcare Data Matters in ML
Medical data is messy, complex, and often high-stakes—exactly the kind of challenge machine learning was born to handle.
With the right training set, ML models can:
- flag anomalies on X-rays in milliseconds,
- predict ICU readmission days in advance,
- transcribe or translate physician-patient conversations,
- or even detect COVID from a simple cough recording.
But without clean, diverse, and context-rich datasets? Those same models collapse under bias, false positives, or clinical irrelevance. That’s why great healthcare ML begins not with modeling—but with data.
What Makes a Dataset “Good”?
Not all “free medical data” is worth your training cycles. Here's what sets great datasets apart:
Realistic
The best datasets reflect real-world noise: typos, missing fields, patient diversity, low-resolution images, regional coding. Clean is great—but not too clean.
Representative
Bias in healthcare kills. If your training data mostly includes young white males, your model will fail on everyone else. Good datasets represent age, sex, ethnicity, and geography.
Well-labeled
Whether it’s ICD codes, expert annotations on X-rays, or dialogue intents in transcripts—good labels mean better learning.
Legal to Use
All datasets in this list are free, with clear academic or commercial use licenses. No license? No training.
20 Best Free Healthcare Datasets (Ranked & Explained)
These 20 datasets are free to access, actively used in 2025, and sorted by relevance across five key categories: EHR, imaging, audio, dialogue, and surveys. Each one includes a direct use case for ML teams, from academic experiments to real-world deployments.
Electronic Health Records (EHR)
1. MIMIC-IV

Type: EHR, ICU
Format: Tabular + Clinical Notes
Volume: 40,000+ patients (2008–2019)
Access: Free (academic use only)
Use Case: Mortality prediction, time-series modeling, clinical NLP
The most cited clinical dataset in the world, combining ICU monitoring data, vitals, lab results, prescriptions, and de-identified clinical notes. It’s a go-to foundation for time-series forecasting and patient outcome prediction.
Dataset Spotlight (click to expand)
name: MIMIC-IV type: EHR, ICU format: Tabular + Clinical Notes volume: 40,000+ patients (2008–2019) access: Free (academic use only) use_case: Mortality prediction, time-series modeling, clinical NLP
2. EHRSHOT

Type: Longitudinal EHR
Format: Tabular
Volume: 6,739 patients, 41M events
Access: Free (academic use only)
Use Case: Few-shot training, foundation model pretraining, sequence modeling
Built by Stanford for benchmarking general-purpose EHR models, this dataset includes longitudinal patient timelines with diagnoses, labs, and medications. It’s structured to stress-test generalization and is ideal for prompt-based or cross-task transfer learning.
Medical Imaging
3. MIMIC-CXR-JPG

Type: Chest X-rays
Format: Image + Report
Volume: 377,000+ images
Access: Free (academic use only)
Use Case: Diagnostic classification, report generation, attention maps
One of the largest public chest radiograph datasets, sourced from real hospital systems and annotated with 14 common clinical findings (e.g., edema, effusion, infiltration). Comes with patient metadata and linked radiology reports.
Dataset Spotlight (click to expand)
name: MIMIC-CXR-JPG type: Chest X-rays format: Image + Report volume: 377,000+ images access: Free (academic use only) use_case: Diagnostic classification, report generation, attention maps
4. The Cancer Imaging Archive (TCIA)

Type: CT, MRI, PET
Format: DICOM + Segmentation
Volume: 100+ collections
Access: Free (academic use only)
Use Case: Tumor segmentation, radiomics, multi-modal training
TCIA hosts expertly curated datasets covering various cancer types, often with segmentation masks, genomic data, and clinical annotations. Frequently used for research into 3D segmentation, survival analysis, and image-genome alignment.
5. MedPix
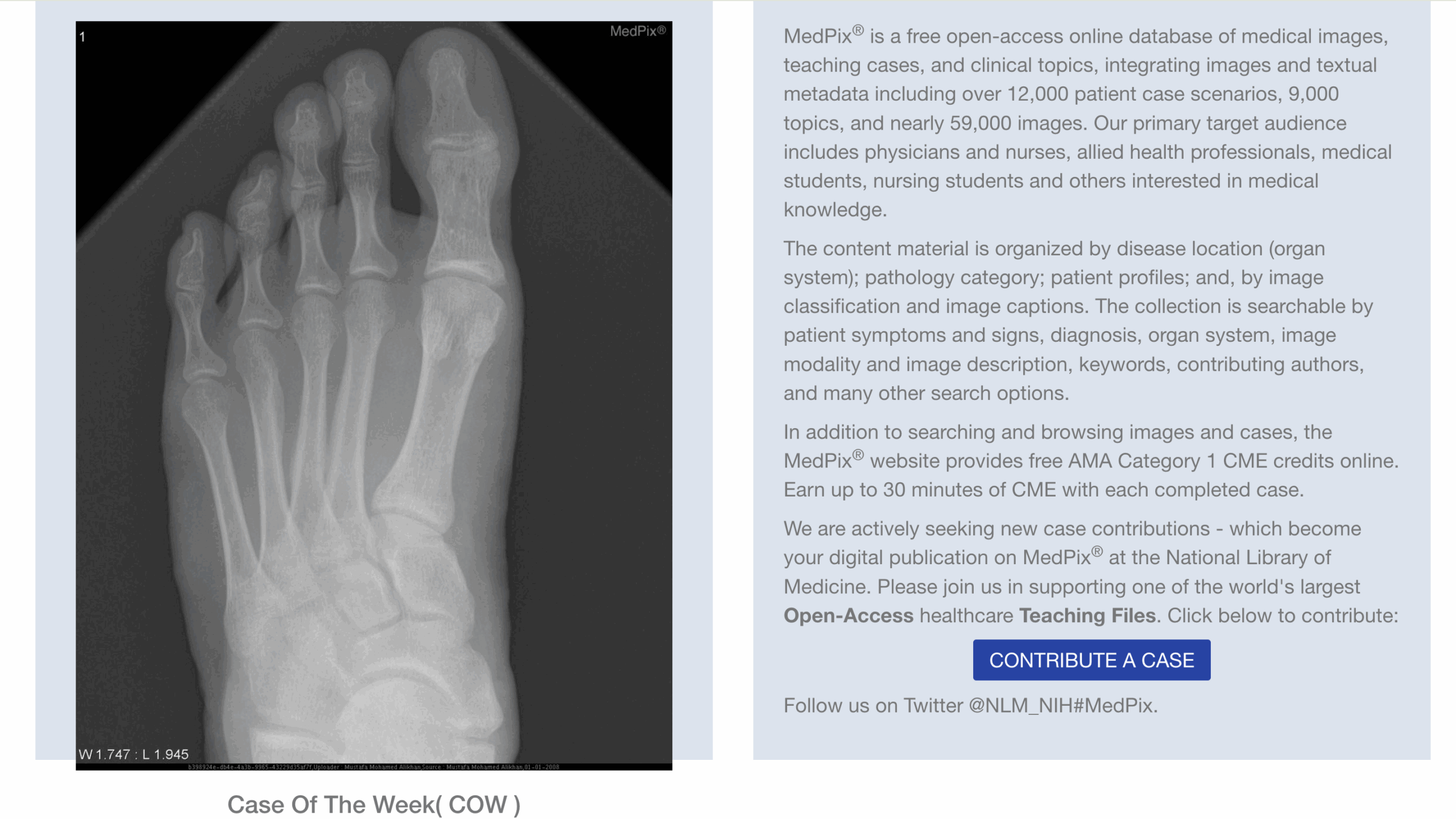
Type: Multimodal clinical imaging
Format: Photo + Metadata
Volume: 59,000+ diagnostic cases
Access: Free (open access)
Use Case: Cross-modal retrieval, medical image classification, education
This image-centric case library spans radiology, dermatology, and pathology, with rich metadata including diagnosis, history, and key image findings. Used for model pretraining and clinical decision support prototypes.
6. PatchCamelyon (PCam)
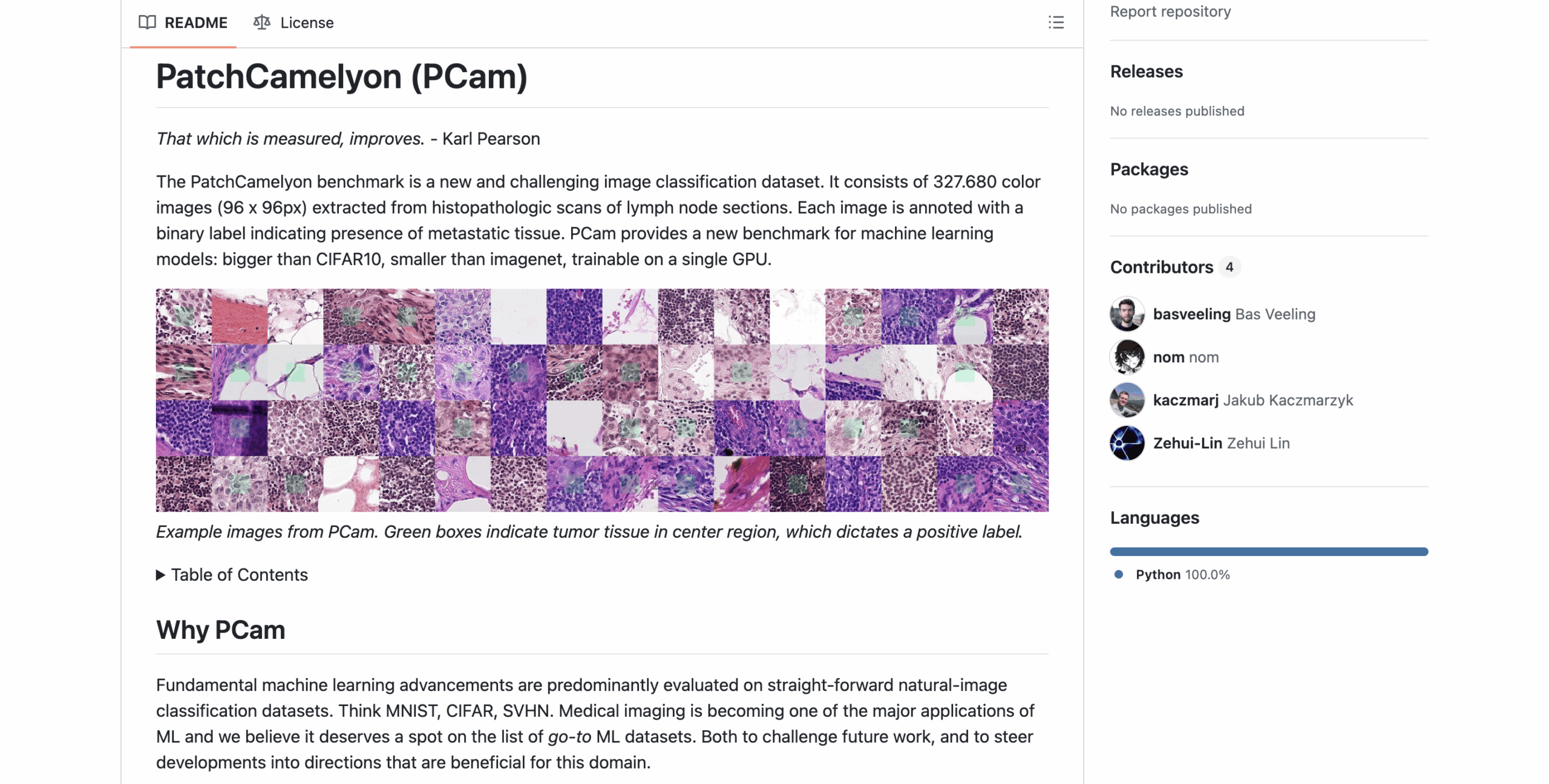
Type: Histopathology
Format: 96×96 image patches
Volume: 327,680 samples
Access: Free (open access)
Use Case: Binary classification, patch-based detection, fast prototyping
Derived from whole-slide scans of lymph node tissue, PCam offers a highly efficient benchmark for evaluating image classification architectures. Despite its compact size, it’s heavily used in real-world cancer detection tasks.
7. CAMELYON17
Type: Whole-slide histopathology
Format: WSI (DICOM) + Annotations
Volume: 100+ annotated slides from 5 hospitals
Access: Free (academic use only)
Use Case: Tumor segmentation, domain generalization, weak supervision
CAMELYON17 includes whole-slide lymph node scans with detailed labels for metastatic regions. Used in grand challenges, it’s become a benchmark for weakly supervised tumor detection across domains.
8. PAD-UFES-20

Type: Dermatology (mobile-acquired)
Format: Photo
Volume: 2,298 images, 6 disease classes
Access: Free (academic use only)
Use Case: Skin disease classification, fairness testing, mobile ML
Collected via smartphone in Brazilian clinics, this dataset emphasizes real-world variance: different lighting, skin tones, and resolutions. It’s great for building inclusive models or mobile apps targeting skin lesion triage.
9. LC25000
Type: Histopathology (lung and colon)
Format: Microscopy images
Volume: 25,000 images
Access: Free (academic use only)
Use Case: Cancer detection, visual diagnosis, 2D tissue classification
Includes balanced samples from benign and malignant lung and colon tissues. Clean, easy to preprocess, and widely adopted for training CNNs on microscopy data. Especially useful for model benchmarking or augmentation studies.
10. COVID-19 Radiography Dataset
Type: X-rays and CT scans
Format: Image + Metadata
Volume: 21,000+ images
Access: Free (open access)
Use Case: Infection detection, multi-class classification, public health modeling
Combines COVID, pneumonia, and healthy X-rays from multiple global sources, with clear class balance and metadata. Frequently used in rapid-response ML projects during the pandemic, it remains relevant for studying transfer learning and medical robustness.
Audio & Signal Data
11. COUGHVID
Type: Cough recordings
Format: Audio
Volume: 25,000+ samples
Access: Free (open access)
Use Case: Disease detection, acoustic modeling, mobile diagnostics
Collected via crowdsourcing and reviewed by clinicians, this dataset includes coughs from healthy and symptomatic individuals. It’s a benchmark for respiratory sound classification and real-time detection in telehealth settings.
Dataset Spotlight (click to expand)
name: COUGHVID type: Cough recordings format: Audio volume: 25,000+ samples access: Free (open access) use_case: Disease detection, acoustic modeling, mobile diagnostics
12. Coswara
Type: Speech, cough, and breath audio
Format: Audio + Metadata
Volume: Thousands of samples
Access: Free (open access)
Use Case: Voice biometrics, COVID screening, multilingual signal analysis
Designed for multilingual research, Coswara provides sustained phonation, breath cycles, and coughing from diverse Indian populations. Ideal for audio-based symptom detection, especially in noisy real-world conditions.
13. MedDialog (EN)
Type: Doctor–patient Q&A (English)
Format: Text (structured dialogues)
Volume: 300,000+ dialogues across 96 diseases
Access: Free (open access)
Use Case: Medical chatbot training, disease-specific Q&A, few-shot NLP
Originally in Chinese and machine-translated to English, this dataset contains over 300K doctor–patient dialogues covering 96 diseases. Each interaction follows a structured Q&A format, making it suitable for training domain-specific chatbots and building disease-focused dialogue agents.
Dataset Spotlight (click to expand)
name: MedDialog (EN) type: Doctor–patient Q&A (English) format: Text (structured dialogues) volume: 300,000+ dialogues across 96 diseases access: Free (open access) use_case: Medical chatbot training, disease-specific Q&A, few-shot NLP
14. MedDialog (CN)
Type: Doctor–patient Q&A (Chinese)
Format: Text (multi-turn dialogues)
Volume: 1.1 million+ dialogues
Access: Free (open access)
Use Case: Multilingual NLP, clinical NLU, cross-lingual benchmarking
The Chinese version of MedDialog contains anonymized patient consultations, making it ideal for training multilingual large language models for healthcare use cases in Chinese-speaking populations.
Population Surveys & Multimodal Panels
15. DHS Program
Type: Global household health surveys
Format: Tabular + Questionnaire
Volume: 90+ countries, thousands of indicators
Access: Free (open access)
Use Case: Epidemiological modeling, health equity, feature correlation
The Demographic and Health Surveys provide data on fertility, nutrition, HIV, and maternal health across the Global South. It’s ideal for public health prediction and regional analysis.
Dataset Spotlight (click to expand)
name: DHS Program type: Global household health surveys format: Tabular + Questionnaire volume: 90+ countries, thousands of indicators access: Free (open access) use_case: Epidemiological modeling, health equity, feature correlation
16. HINTS

Type: U.S. health communication survey
Format: Tabular
Volume: 5 major waves, 20+ years
Access: Free (open access)
Use Case: Behavioral modeling, patient tech adoption, segmentation
The Health Information National Trends Survey tracks how adults in the U.S. access and trust medical information. Valuable for training personalization engines and behavioral prediction tools.
17. MEPS
Type: U.S. medical expenditure survey
Format: Tabular
Volume: National sample, thousands of records
Access: Free (open access)
Use Case: Cost modeling, policy simulation, socioeconomic impact
This dataset tracks medical spending, insurance coverage, and service utilization in American households. Great for economic ML modeling and predictive healthcare cost estimation.
18. OpenSAFELY

Type: UK primary care + COVID records
Format: Tabular + Clinical codes
Volume: Millions of records (pseudonymized)
Access: Free (academic request required)
Use Case: Risk factor analysis, vaccine effectiveness, real-world evidence
Built for pandemic-time research, OpenSAFELY includes secure NHS-linked data on medications, diagnoses, and mortality. It supports statistical modeling and large-scale medical inference.
19. UK Biobank
Type: Multimodal biomedical cohort
Format: Genomic + Imaging + Tabular
Volume: 500,000+ participants
Access: Free (academic application required)
Use Case: Imaging-genetics fusion, biomarker discovery, LLM fine-tuning
Combines genomics, MRI, blood biomarkers, and lifestyle surveys. Widely used for multi-modal ML in aging, oncology, cardiology, and cognitive science. Requires academic application for access.
20. HealthData.gov
Type: Open U.S. government health data portal
Format: Tabular + Multiformat
Volume: Thousands of datasets
Access: Free (open access)
Use Case: Exploratory modeling, regional trend analysis, synthetic data
Aggregates open datasets on Medicare, hospital quality, opioid use, vaccine uptake, and more. A flexible source for feature engineering and cross-domain model development.
Commercial-Grade Datasets (For Production Use)
Free datasets are great for research—but production systems need more. At Unidata, we offer curated medical datasets built for real-world deployment: annotated CT scans, surgical video, and multimodal patient records from Eastern Europe.
Unidata Chest CT Collection
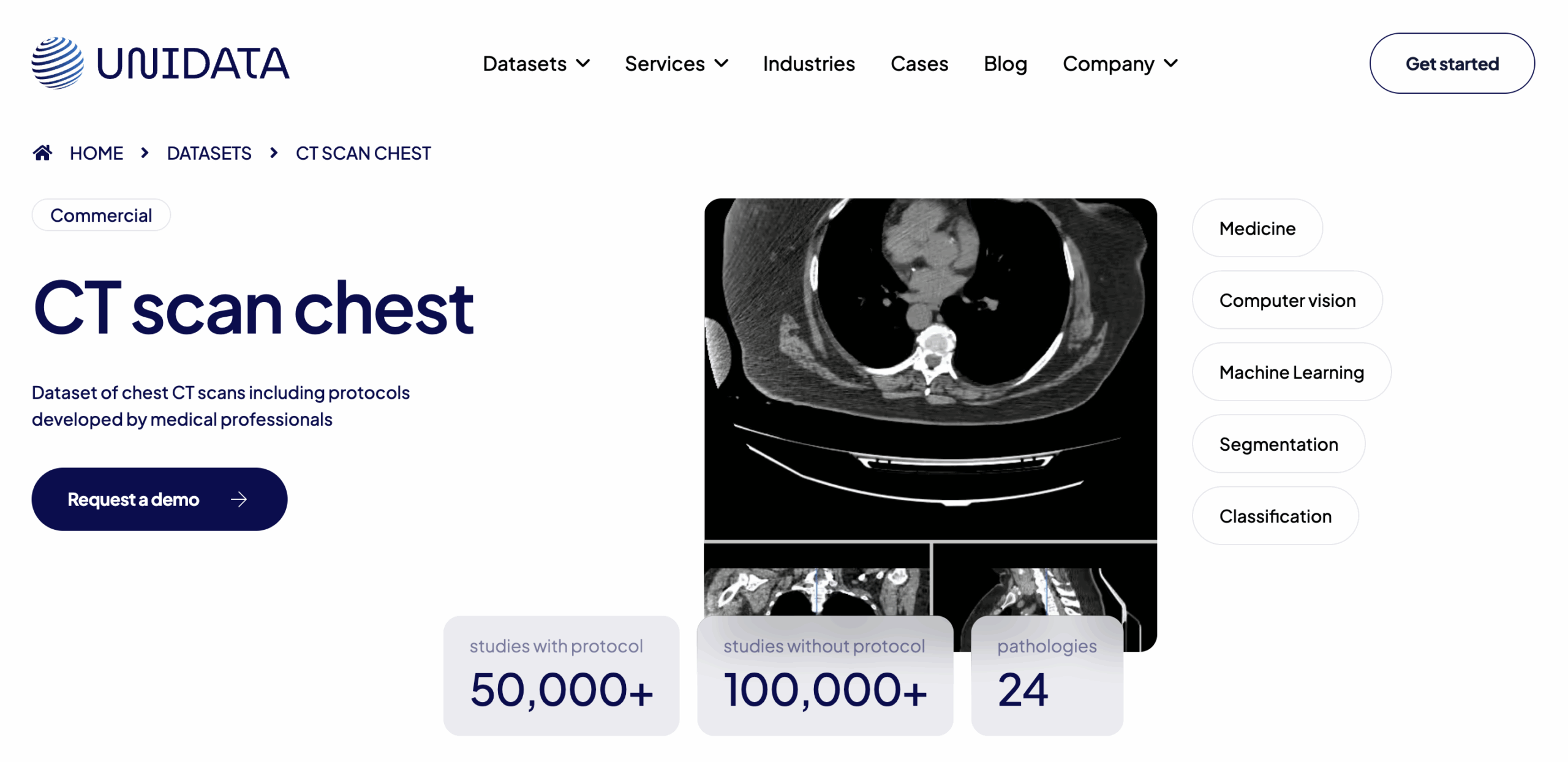
Type: Thoracic CT scans
Format: DICOM + XML annotations
Volume: 150,000+ slices (7,435 patients, 25 clinics)
Access: Paid (commercial license)
Use Case: Lung cancer detection, tuberculosis screening, segmentation model pretraining
A multi-institutional dataset of thoracic CT slices collected from 25 clinics across Eastern Europe and Central Asia. Contains over 150,000 manually annotated DICOM images labeled by radiologists for nodules, consolidations, cavities, and other pathologies. Includes scanner metadata and demographic details, making it ideal for domain adaptation and model
Dataset Spotlight (click to expand)
name: Unidata Chest CT Collection type: Thoracic CT scans format: DICOM + XML annotations volume: 150,000+ slices (7,435 patients, 25 clinics) access: Paid (commercial license) use_case: Lung cancer detection, tuberculosis screening, segmentation model pretraining url: https://unidata.pro/datasets/ct-scan-chest/
Unidata Brain MRI Collection
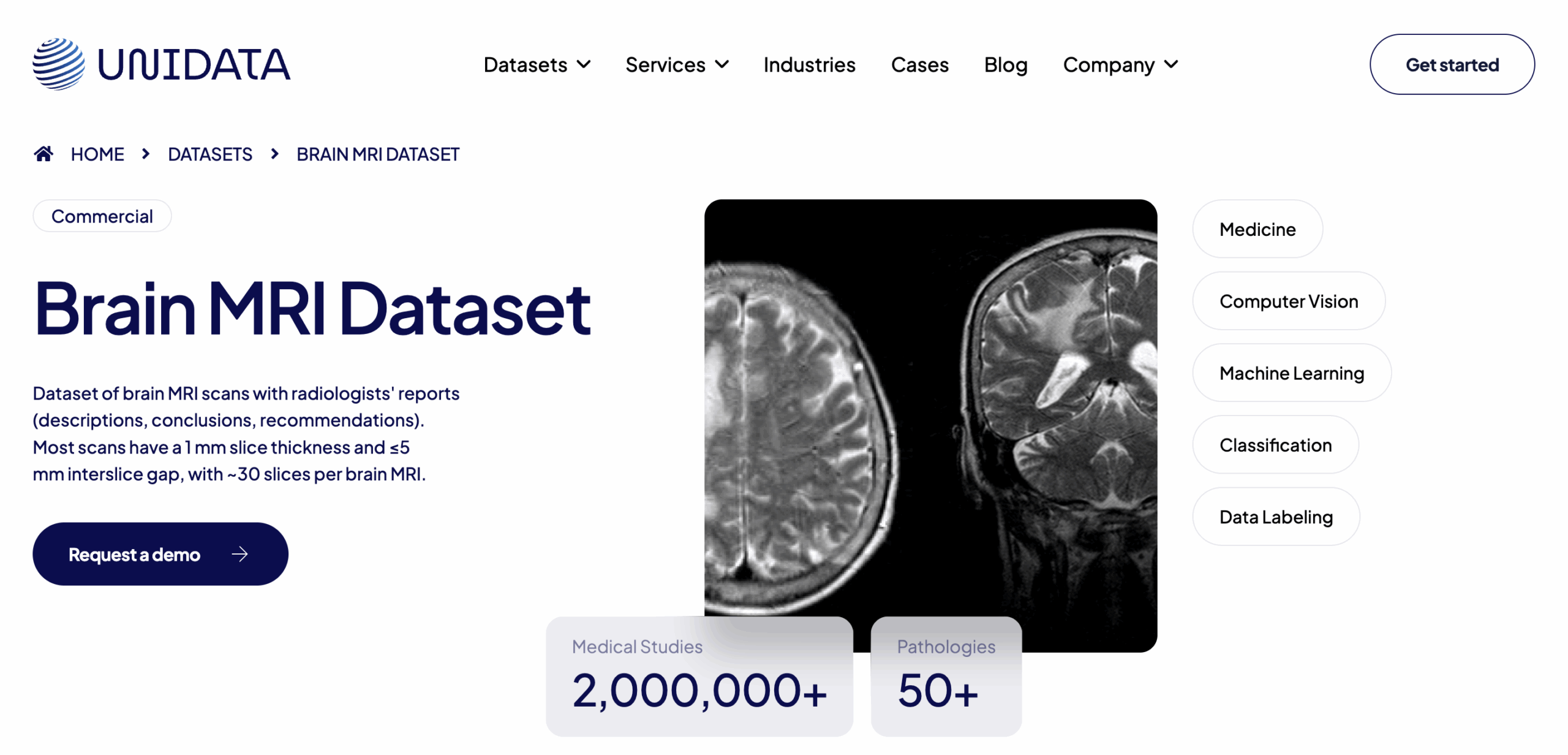
Type: Brain MRI scans
Format: DICOM + XML annotations
Volume: 2,000,000+ images across 50+ studies
Access: Paid (commercial license)
Use Case: Tumor segmentation, brain pathology detection, neuroimaging research
This dataset includes over 2 million DICOM images from 50+ detailed brain MRI studies collected across Eastern Europe. Each study features high-resolution scans in T1, T2, and FLAIR sequences with expert-created XML annotations highlighting tumors, lesions, and structural anomalies. Suitable for fine-grained segmentation models, tumor classification, and neuro-AI research requiring full DICOM fidelity.
Dataset Spotlight (click to expand)
name: Unidata Brain MRI Collection type: Brain MRI scans format: DICOM + XML annotations volume: 2,000,000+ images across 50+ studies access: Paid (commercial license) use_case: Tumor segmentation, brain pathology detection, neuroimaging research url: https://unidata.pro/datasets/brain-mri-image-dicom/
Unidata Spine MRI Collection
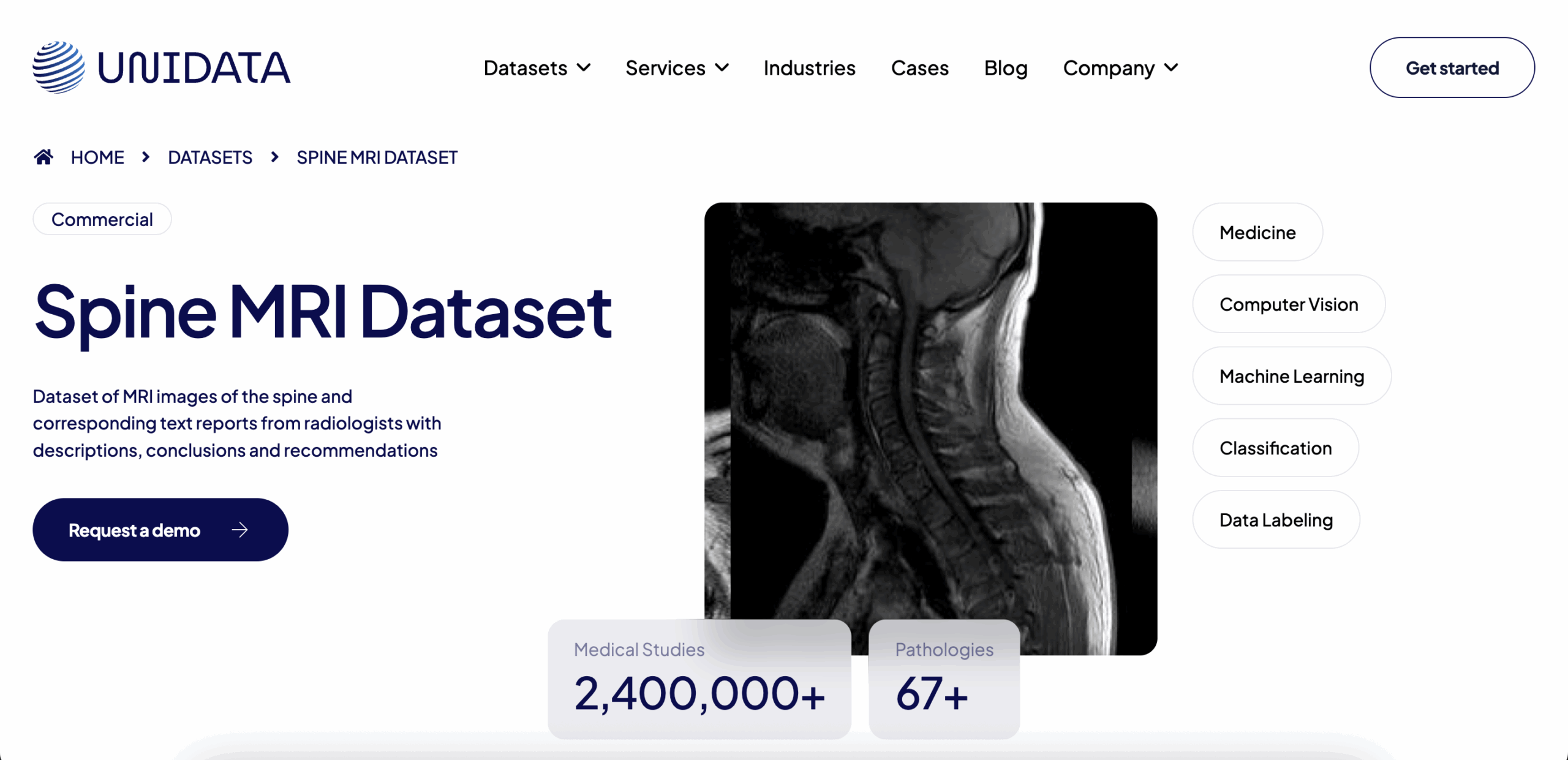
Type: Spine MRI scans
Format: DICOM + XML annotations
Volume: 2,400,000+ images across 67+ studies
Access: Paid (commercial license)
Use Case: Disc herniation detection, spinal alignment analysis, orthopedic model training
This collection contains over 2.4 million spine MRI images sourced from 67+ fully annotated studies. It covers cervical, thoracic, and lumbar regions, with pixel-level segmentation masks and diagnostic metadata. Designed to support ML pipelines in orthopedic imaging, including spinal abnormality classification and pretraining for radiology foundation models.
Dataset Spotlight (click to expand)
name: Unidata Spine MRI Collection type: Spine MRI scans format: DICOM + XML annotations volume: 2,400,000+ images across 67+ studies access: Paid (commercial license) use_case: Disc herniation detection, spinal alignment analysis, orthopedic model training url: https://unidata.pro/datasets/spine-mri-image-dicom/
Final Takeaways
Great healthcare AI starts with great data. Public datasets help you build fast and learn fast—but real-world performance needs real-world diversity.
Cheat Sheet: All 23 Healthcare Datasets
Use this list to find your baseline. When you're ready to scale, train on data that reflects the patients you serve.
Best Free Healthcare Datasets for Machine Learning (2025) (click to expand)
- name: MIMIC-IV type: EHR, ICU format: Tabular + Clinical Notes volume: 40,000+ patients (2008–2019) access: Free (academic use only) use_case: Mortality prediction, time-series modeling, clinical NLP - name: EHRSHOT type: Longitudinal EHR format: Tabular volume: 6,739 patients, 41M events access: Free (academic use only) use_case: Few-shot training, foundation model pretraining, sequence modeling - name: MIMIC-CXR-JPG type: Chest X-rays format: Image + Report volume: 377,000+ images access: Free (academic use only) use_case: Diagnostic classification, report generation, attention maps - name: The Cancer Imaging Archive (TCIA) type: CT, MRI, PET format: DICOM + Segmentation volume: 100+ collections access: Free (academic use only) use_case: Tumor segmentation, radiomics, multi-modal training - name: MedPix type: Multimodal clinical imaging format: Photo + Metadata volume: 59,000+ diagnostic cases access: Free (open access) use_case: Cross-modal retrieval, medical image classification, education - name: PatchCamelyon (PCam) type: Histopathology format: 96×96 image patches volume: 327,680 samples access: Free (open access) use_case: Binary classification, patch-based detection, fast prototyping - name: CAMELYON17 type: Whole-slide histopathology format: WSI (DICOM) + Annotations volume: 100+ annotated slides from 5 hospitals access: Free (academic use only) use_case: Tumor segmentation, domain generalization, weak supervision - name: PAD-UFES-20 type: Dermatology (mobile-acquired) format: Photo volume: 2,298 images, 6 disease classes access: Free (academic use only) use_case: Skin disease classification, fairness testing, mobile ML - name: LC25000 type: Histopathology (lung and colon) format: Microscopy images volume: 25,000 images access: Free (academic use only) use_case: Cancer detection, visual diagnosis, 2D tissue classification - name: COVID-19 Radiography Dataset type: X-rays and CT scans format: Image + Metadata volume: 21,000+ images access: Free (open access) use_case: Infection detection, multi-class classification, public health modeling - name: COUGHVID type: Cough recordings format: Audio volume: 25,000+ samples access: Free (open access) use_case: Disease detection, acoustic modeling, mobile diagnostics - name: Coswara type: Speech, cough, and breath audio format: Audio + Metadata volume: Thousands of samples access: Free (open access) use_case: Voice biometrics, COVID screening, multilingual signal analysis - name: MedDialog (EN) type: Doctor–patient Q&A (English) format: Text (structured dialogues) volume: 300,000+ dialogues across 96 diseases access: Free (open access) use_case: Medical chatbot training, disease-specific Q&A, few-shot NLP - name: MedDialog (CN) type: Doctor–patient Q&A (Chinese) format: Text (multi-turn dialogues) volume: 1.1 million+ dialogues access: Free (open access) use_case: Multilingual NLP, clinical NLU, cross-lingual benchmarking - name: DHS Program type: Global household health surveys format: Tabular + Questionnaire volume: 90+ countries, thousands of indicators access: Free (open access) use_case: Epidemiological modeling, health equity, feature correlation - name: HINTS type: U.S. health communication survey format: Tabular volume: 5 major waves, 20+ years access: Free (open access) use_case: Behavioral modeling, patient tech adoption, segmentation - name: MEPS type: U.S. medical expenditure survey format: Tabular volume: National sample, thousands of records access: Free (open access) use_case: Cost modeling, policy simulation, socioeconomic impact - name: OpenSAFELY type: UK primary care + COVID records format: Tabular + Clinical codes volume: Millions of records (pseudonymized) access: Free (academic request required) use_case: Risk factor analysis, vaccine effectiveness, real-world evidence - name: UK Biobank type: Multimodal biomedical cohort format: Genomic + Imaging + Tabular volume: 500,000+ participants access: Free (academic application required) use_case: Imaging-genetics fusion, biomarker discovery, LLM fine-tuning - name: HealthData.gov type: Open U.S. government health data portal format: Tabular + Multiformat volume: Thousands of datasets access: Free (open access) use_case: Exploratory modeling, regional trend analysis, synthetic data - name: Unidata Chest CT Collection type: Thoracic CT scans format: DICOM + XML annotations volume: 150,000+ slices (7,435 patients, 25 clinics) access: Paid (commercial license) use_case: Lung cancer detection, tuberculosis screening, segmentation model pretraining - name: Unidata Brain MRI Collection type: Brain MRI scans format: DICOM + XML annotations volume: 2,000,000+ images across 50+ studies access: Paid (commercial license) use_case: Tumor segmentation, brain pathology detection, neuroimaging research - name: Unidata Spine MRI Collection type: Spine MRI scans format: DICOM + XML annotations volume: 2,400,000+ images across 67+ studies access: Paid (commercial license) use_case: Disc herniation detection, spinal alignment analysis, orthopedic model training